-- 年龄等于30 select * from employee where age = 30; -- 年龄小于30 select * from employee where age < 30; -- 小于等于 select * from employee where age <= 30; -- 没有身份证 select * from employee where idcard isnullor idcard = ''; -- 有身份证 select * from employee where idcard; select * from employee where idcard isnotnull; -- 不等于 select * from employee where age != 30; -- 年龄在20到30之间 select * from employee where age between20and30; select * from employee where age >= 20and age <= 30; -- 下面语句不报错,但查不到任何信息 select * from employee where age between30and20; -- 性别为女且年龄小于30 select * from employee where age < 30and gender = '女'; -- 年龄等于25或30或35 select * from employee where age = 25or age = 30or age = 35; select * from employee where age in (25, 30, 35); -- 姓名为两个字 select * from employee wherenamelike'__'; -- 身份证最后为X select * from employee where idcard like'%X';
聚合查询(聚合函数)
常见聚合函数:
函数
功能
count
统计数量
max
最大值
min
最小值
avg
平均值
sum
求和
1 2 3 4
语法: SELECT 聚合函数(字段列表) FROM 表名; 例: SELECTcount(id) from employee where workaddress = "广东省";
分组查询
1 2
语法: SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUPBY 分组字段名 [ HAVING 分组后的过滤条件 ];
-- 根据性别分组,统计男性和女性数量(只显示分组数量,不显示哪个是男哪个是女) select count(*) from employee group by gender; -- 根据性别分组,统计男性和女性数量 select gender, count(*)from employee groupby gender; -- 根据性别分组,统计男性和女性的平均年龄 select gender, avg(age) from employee groupby gender; -- 年龄小于45,并根据工作地址分组 select workaddress, count(*) from employee where age < 45 group by workaddress; -- 年龄小于45,并根据工作地址分组,获取员工数量大于等于3的工作地址 select workaddress, count(*) address_count from employee where age < 45groupby workaddress having address_count >= 3;
排序查询
1 2
语法: SELECT 字段列表 FROM 表名 ORDERBY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
ASC: 升序(默认)
DESC: 降序
例子:
1 2 3 4 5
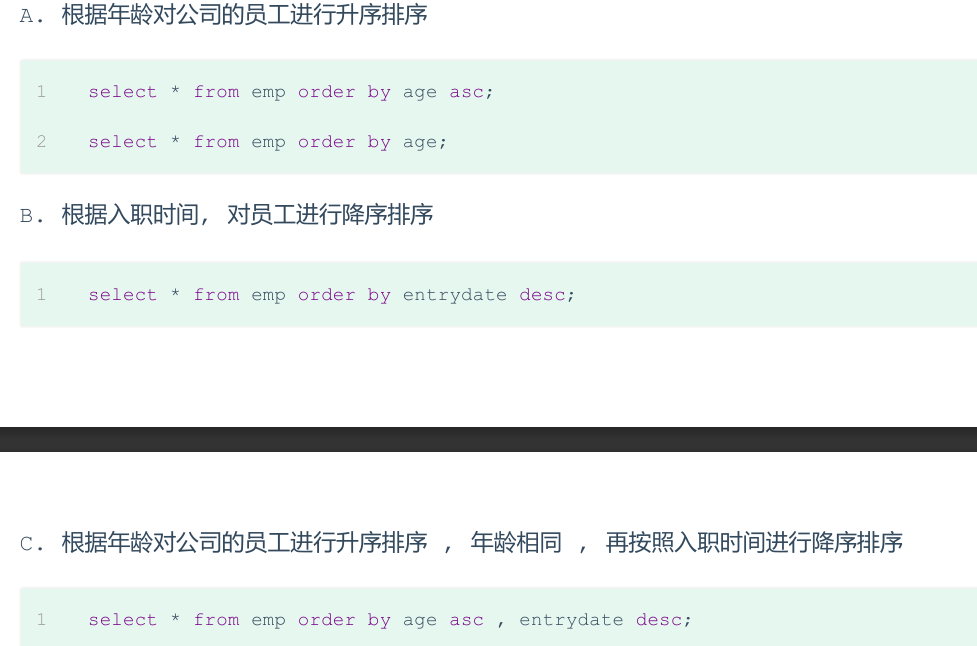
-- 根据年龄升序排序 SELECT * FROM employee ORDERBY age ASC; SELECT * FROM employee ORDERBY age; -- 两字段排序,根据年龄升序排序,入职时间降序排序 SELECT * FROM employee ORDERBY age ASC, entrydate DESC;
注意事项
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
1 2
语法: SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
例子:
1 2 3 4
-- 查询第一页数据,展示10条 SELECT * FROM employee LIMIT0, 10; -- 查询第二页 SELECT * FROM employee LIMIT10, 10;
注意事项
起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
案例
DQL执行顺序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
7.DCL(数据控制语言)
用来管理数据库用户、控制数据库的访问权限。
管理用户
查询用户:
1 2 3 4 5 6 7 8
USE mysql; SELECT * FROMuser; 创建用户: CREATEUSER'用户名'@'主机名' IDENTIFIED BY'密码'; 修改用户密码: ALTERUSER'用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY'新密码'; 删除用户: DROPUSER'用户名'@'主机名';
CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END
如果val1为true,返回res1,… 否则返回default默认值
CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END
如果expr的值等于val1,返回res1,… 否则返回default默认值
1 2 3 4 5 6 7 8 9 10
select id, name, (casewhen math >= 85then'优秀'when math >=60then'及格'else'不及格'end ) '数学', end ) '英语', end ) '语文' (casewhen english >= 85then'优秀'when english >=60then'及格'else'不及格' (casewhen chinese >= 85then'优秀'when chinese >=60then'及格'else'不及格' from score;
createtableuser( id intprimary key auto_increment, namevarchar(10) notnullunique, age intcheck(age > 0and age < 120), status char(1) default'1', gender char(1) );
合并查询(笛卡尔积,会展示所有组合结果): select * from employee, dept;
笛卡尔积:两个集合A集合和B集合的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
1 2
消除无效笛卡尔积: select * from employee, dept where employee.dept = dept.id;
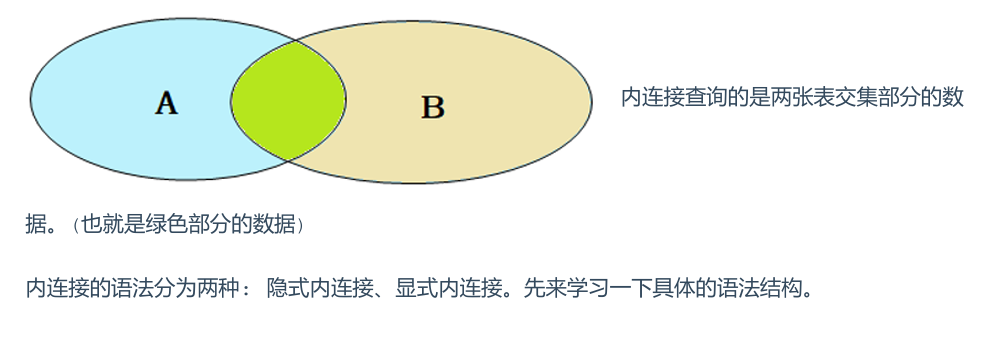
3.内连接查询
内连接查询的是两张表交集的部分
1 2 3 4
隐式内连接: SELECT 字段列表 FROM 表1, 表2WHERE 条件 ...; 显式内连接: SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2ON 连接条件 ...;
显式性能比隐式高
例子:
1 2 3 4 5
-- 查询员工姓名,及关联的部门的名称 -- 隐式 select e.name, d.name from employee as e, dept as d where e.dept = d.id; -- 显式 select e.name, d.name from employee as e innerjoin dept as d on e.dept = d.id;
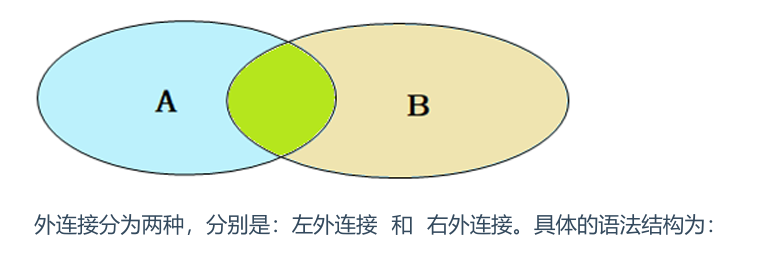
-- 左 selecte.*, d.name from employee aseleftouterjoin dept as d one.dept = d.id; select d.name, e.* from dept d leftouterjoin emp eone.dept = d.id; -- 这条语句与下面的语句效果一样 -- 右 select d.name, e.* from employee aserightouterjoin dept as d one.dept = d.id;
左连接可以查询到没有dept的employee,右连接可以查询到没有employee的dept
5.自连接查询
当前表与自身的连接查询,自连接必须使用表别名
1 2
语法: SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
自连接查询,可以是内连接查询,也可以是外连接查询
例子:
1 2 3 4
-- 查询员工及其所属领导的名字 select a.name, b.name from employee a, employee b where a.manager = b.id; -- 没有领导的也查询出来 select a.name, b.name from employee a left join employee b on a.manager = b.id;
注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底是哪一张表的字段。
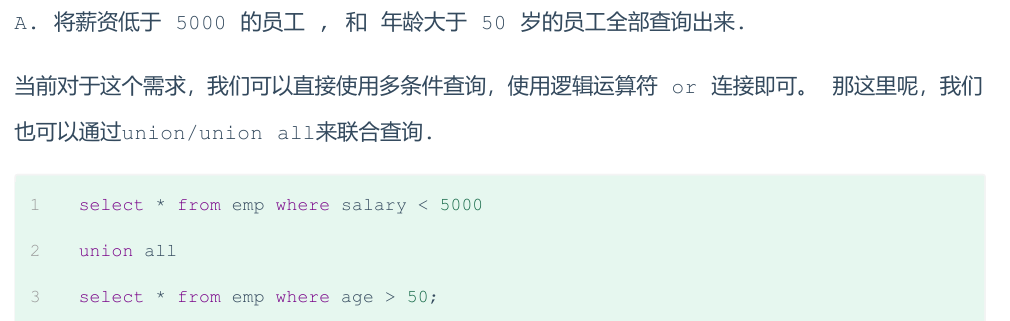
6.联合查询 union, union all
把多次查询的结果合并,形成一个新的查询集
语法:
1 2 3
SELECT 字段列表 FROM 表A ... UNION [ALL] SELECT 字段列表 FROM 表B ...
注意事项
UNION ALL 会有重复结果,UNION 不会
联合查询比使用or效率高,不会使索引失效
7.子查询
SQL语句中嵌套SELECT语句,称谓嵌套查询,又称子查询。 SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2); 子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个
根据子查询结果可以分为:
标量子查询(子查询结果为单个值)
列子查询(子查询结果为一列)
行子查询(子查询结果为一行)
表子查询(子查询结果为多行多列)
根据子查询位置可分为:
WHERE 之后
FROM 之后
SELECT 之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等)。
常用操作符:- < > > >= < <=
例子:
1 2 3 4 5 6 7 8 9
-- 查询销售部所有员工 select id from dept wherename = '销售部'; -- 根据销售部部门ID,查询员工信息 select * from employee where dept = 4; -- 合并(子查询) select * from employee where dept = (select id from dept wherename = '销售部');
-- 查询xxx入职之后的员工信息 select * from employee where entrydate > (select entrydate from employee wherename = 'xxx');
列子查询
返回的结果是一列(可以是多行)。
常用操作符:
操作符
描述
IN
在指定的集合范围内,多选一
NOT IN
不在指定的集合范围内
ANY
子查询返回列表中,有任意一个满足即可
SOME
与ANY等同,使用SOME的地方都可以使用ANY
ALL
子查询返回列表的所有值都必须满足
例子:
1 2 3 4 5 6
-- 查询销售部和市场部的所有员工信息 select * from employee where dept in (select id from dept wherename = '销售部'orname = '市场部'); -- 查询比财务部所有人工资都高的员工信息 select * from employee where salary > all(select salary from employee where dept = (select id from dept wherename = '财务部')); -- 查询比研发部任意一人工资高的员工信息 select * from employee where salary > any (select salary from employee where dept = (select id from dept wherename = '研发部'));
行子查询
返回的结果是一行(可以是多列)。
常用操作符:=, <, >, IN, NOT IN
例子:
1 2 3
-- 查询与xxx的薪资及直属领导相同的员工信息 select * from employee where (salary, manager) = (12500, 1); select * from employee where (salary, manager) = (select salary, manager from employee wherename = 'xxx');
表子查询
返回的结果是多行多列
常用操作符:IN
例子:
1 2 3 4
-- 查询与xxx1,xxx2的职位和薪资相同的员工 select * from employee where (job, salary) in (select job, salary from employee where name = 'xxx1'or name = 'xxx2'); -- 查询入职日期是2006-01-01之后的员工,及其部门信息 selecte.*, d.* from (select * from employee where entrydate > '2006-01-01') aseleftjoin dept as d one.dept = d.id;