mysql运维篇

运维篇
1.日志
1.错误日志(Error Log)
功能:
错误日志记录了 MySQL 服务器启动、停止以及运行过程中发生的所有严重错误。它是数据库管理员故障排查时最重要的工具。
位置:
- 默认存放路径:
/var/log/,日志文件名一般为mysqld.log。 - 可以通过以下命令查看当前的错误日志路径:
1 | show variables like '%log_error%' |
作用:
- 当 MySQL 服务器启动失败或发生严重错误时,错误日志会提供详细的信息,帮助管理员快速定位问题。
2.二进制日志(Binary Log)
介绍
二进制日志(BINLOG)记录了所有会修改数据的操作,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT、SHOW 等查询语句。二进制日志对灾难恢复和主从复制至关重要。
作用:
- 灾难恢复:当发生系统崩溃时,可以通过二进制日志来恢复数据。
- 主从复制:二进制日志用于主服务器向从服务器同步数据。
在MVSQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
1 | show variables like '%log_bin%' |
日志格式
MySQL服务器中提供了多种格式来记录二进制记录,具体格式及特点如下:
| 格式 | 含义 |
|---|---|
| statement | 基于 SQL 语句的日志记录,记录每个修改数据的 SQL 语句。 |
| row | 基于行的日志记录,记录每行数据的修改。 |
| mixed | 混合格式,默认使用 statement,在某些特殊情况下会切换为 row。 |
查看参数方式:
1 | show variables like '%binlog_format%'; |
日志查看
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
1 | mysqlbinlog[参数选项]logfilename |
日志删除
对于频繁更新的系统,二进制日志会很快占用大量磁盘空间。可以通过以下几种方式删除日志:
| 指令 | 含义 |
|---|---|
| reset master | 删除全部 binlog 日志,删除之后,日志编号,将从 binlog.000001重新开始 |
| purge master logs to ‘binlog.***’ | 删除 *** 编号之前的所有日志 |
| purge master logs before ‘yyyy-mm-dd hh24:mi:ss’ | 删除日志为”yyyy-mm-dd hh24:mi:ss”之前产生的所有日志 |
此外,也可以设置二进制日志的过期时间,自动清理过期日志:
1 | show variables like '%binlog_expire_logs_seconds%' |
3.查询日志(General Query Log)
查询日志记录了所有客户端发送的查询语句,默认情况下是关闭的。如果需要开启,可以通过配置文件设置。
修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
1 | #该选项用来开启查询日志,可选值:0或者1;0代表关闭,1代表开启 |
作用:
- 适用于需要审计或查看数据库所有查询的场景,但会增加性能开销,因此通常不建议在生产环境中长时间开启。
4.慢查询日志(Slow Query Log)
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于 min_examined_row_limit的所有的SQL语句的日志,默认未开启。long_query_time 默认为 10 秒,最小为0,精度可以到微秒。它是用来诊断数据库性能问题的重要工具,帮助开发者优化性能。
配置开启:
修改 /etc/my.cnf 文件:
1 | #慢查询日志 |
long_query_time:设置记录查询的最小执行时间(单位:秒),如long_query_time = 2表示记录执行超过 2 秒的查询。
额外配置
1 | #记录执行较慢的管理语句 |
作用:
慢查询日志帮助识别数据库中执行时间长、效率低的查询,从而进行优化,提高数据库性能。
5.日志 小结
MySQL 日志种类:
- 错误日志:记录启动、停止和运行中的严重错误。
- 二进制日志:记录所有修改数据的操作,支持主从复制和灾难恢复。
- 查询日志:记录所有查询操作,适用于审计和故障排查。
- 慢查询日志:记录执行时间超过指定阈值的查询,帮助分析和优化性能。
日志管理建议:
- 在生产环境中,应根据需要开启不同的日志类型,合理配置日志的存储位置和清理策略,避免日志文件占用过多磁盘空间。
- 定期监控日志,特别是慢查询日志,以便及时发现和优化性能瓶颈。
通过这些日志工具,管理员可以有效地监控和管理 MySQL 数据库的运行状态、诊断性能问题、确保数据安全。
2.主从复制
1 概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这
些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状
复制。
MySQL 复制的优点主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,以避免备份期间影响主库服务。
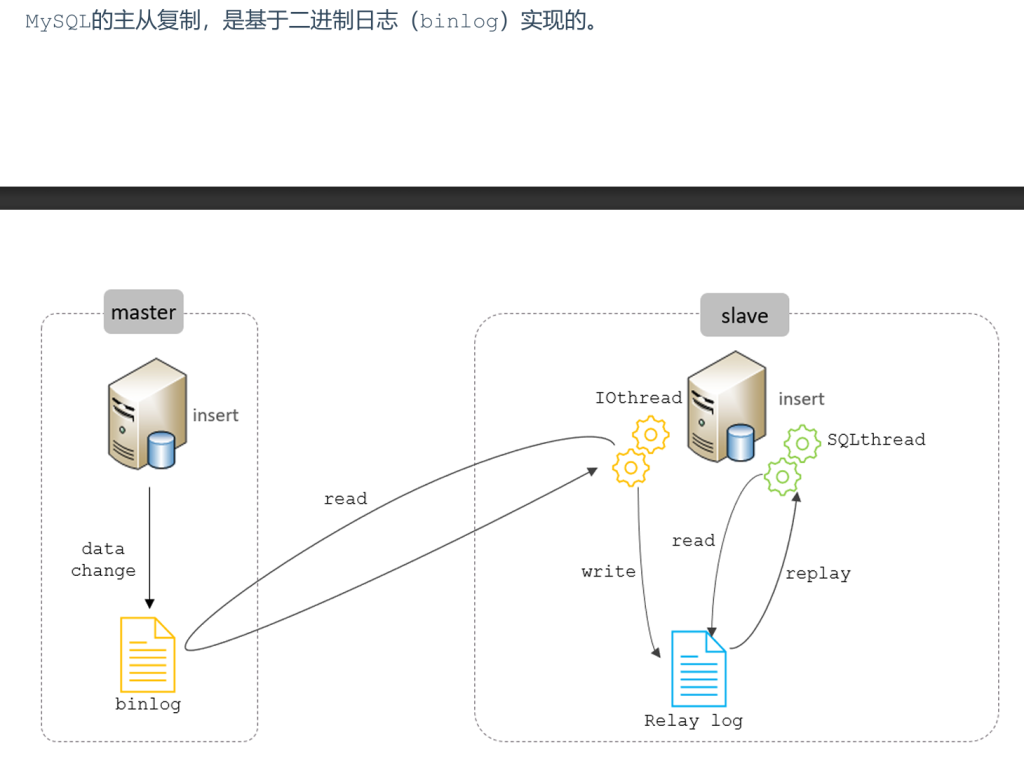
2 原理
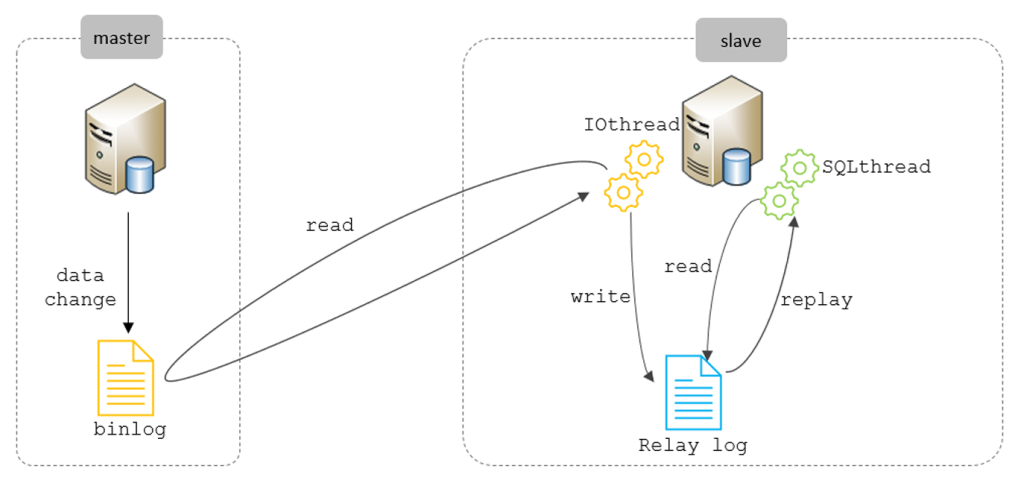
从上图来看,复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- slave重做中继日志中的事件,将改变反映它自己的数据。
3.搭建实现
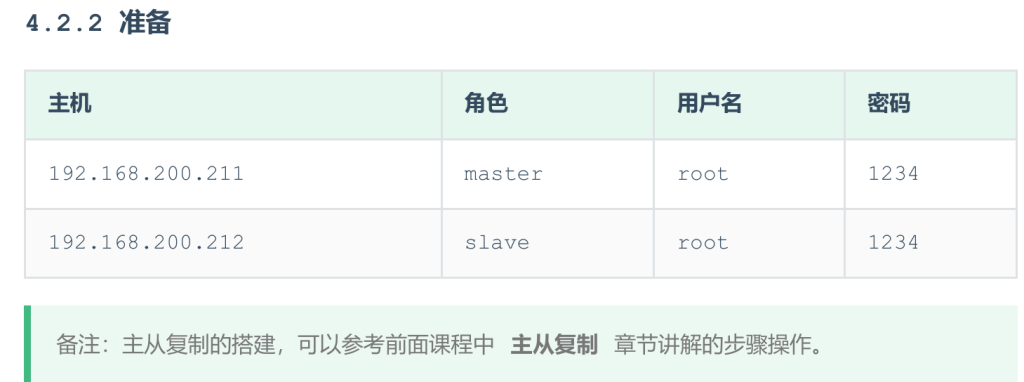
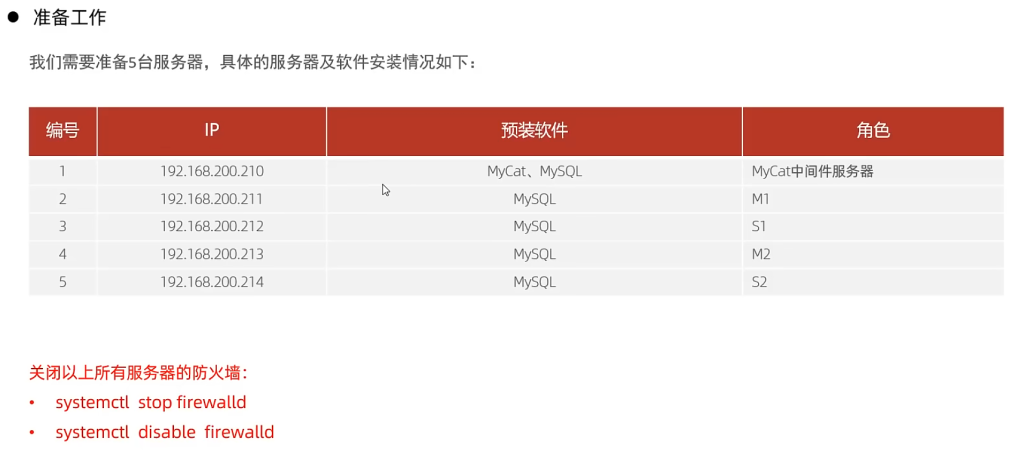
准备

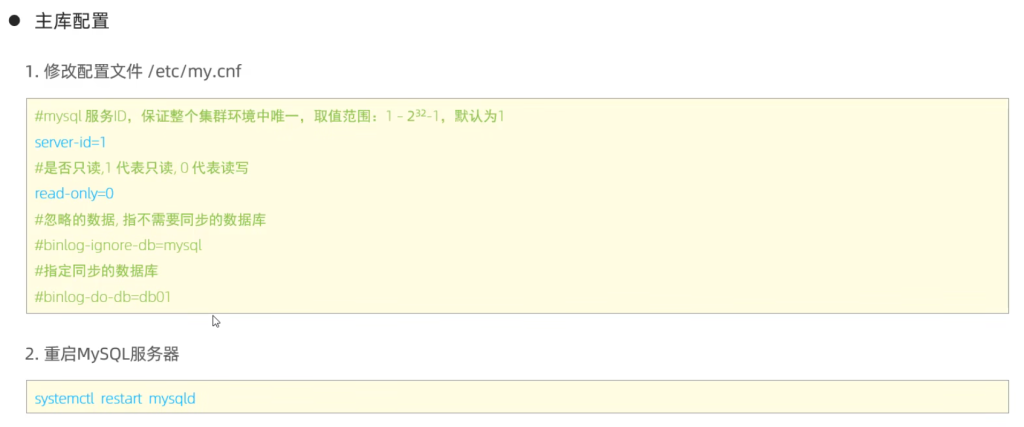
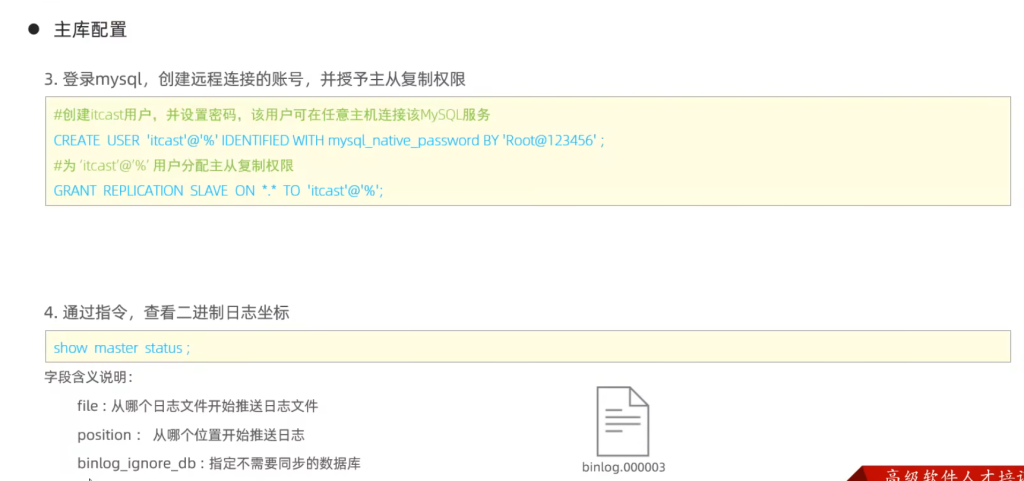
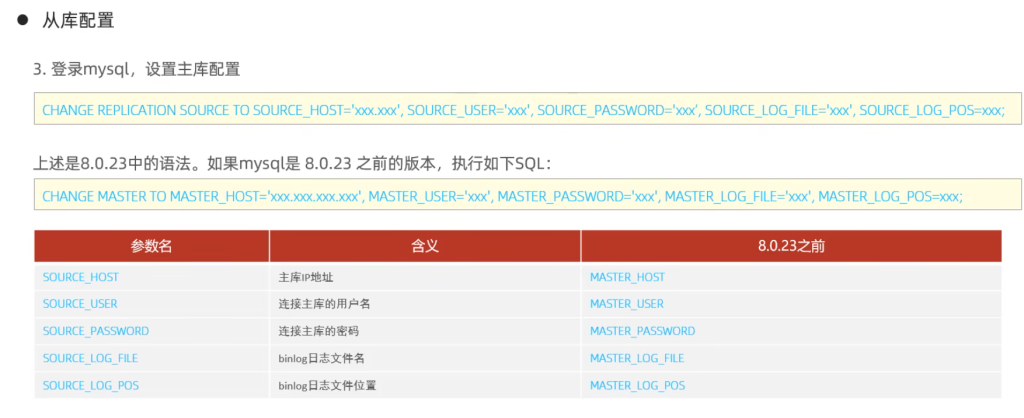
主库配置
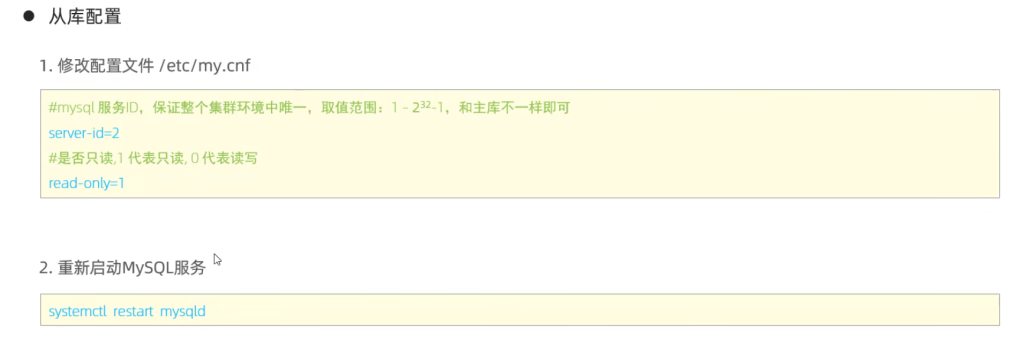
从库配置
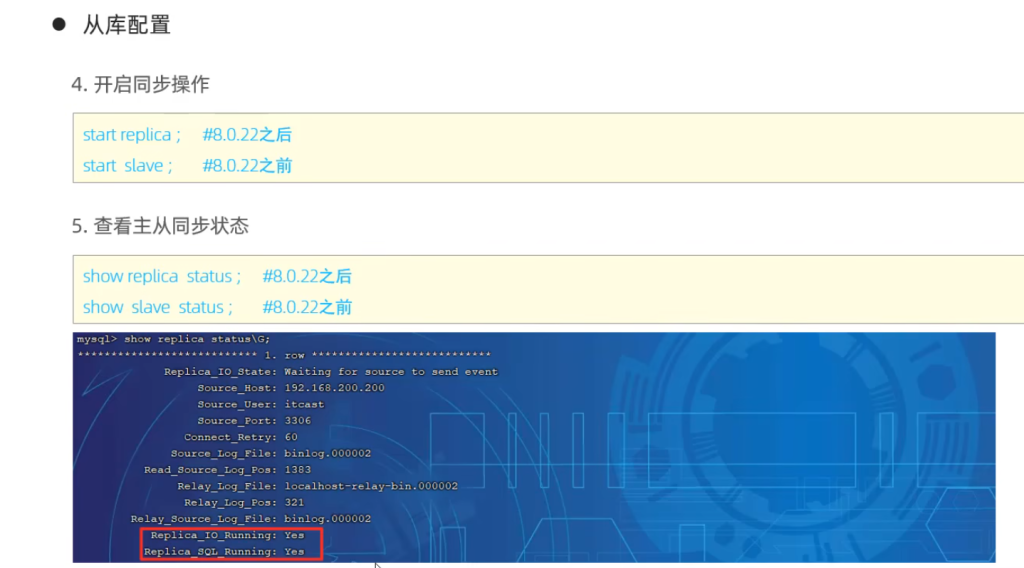
测试
1、在主库上创建数据库、表,并插入数据
1 | create database db01; |
2、在从库中查询数据,验证主从是否同步。
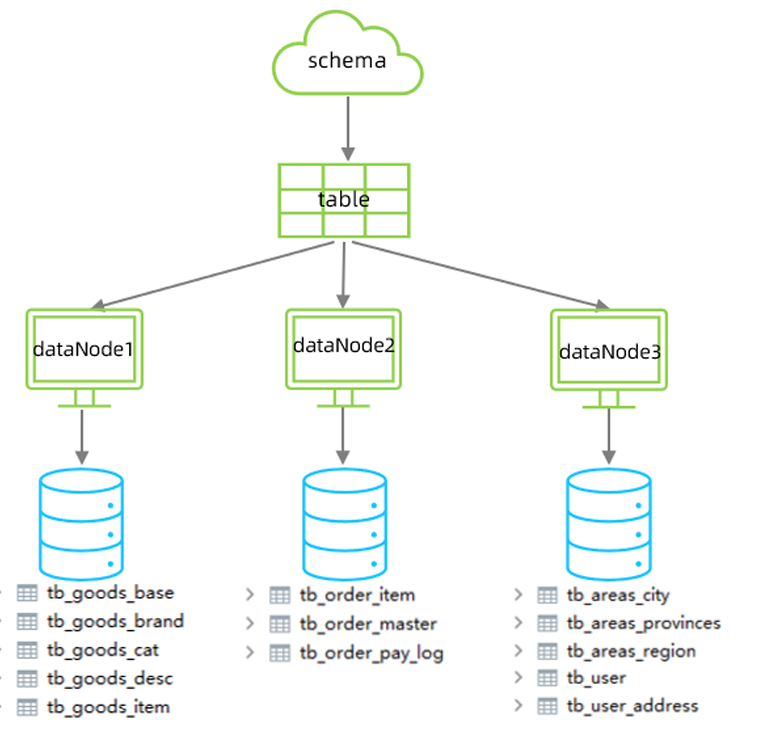
3.分库分表
1.介绍
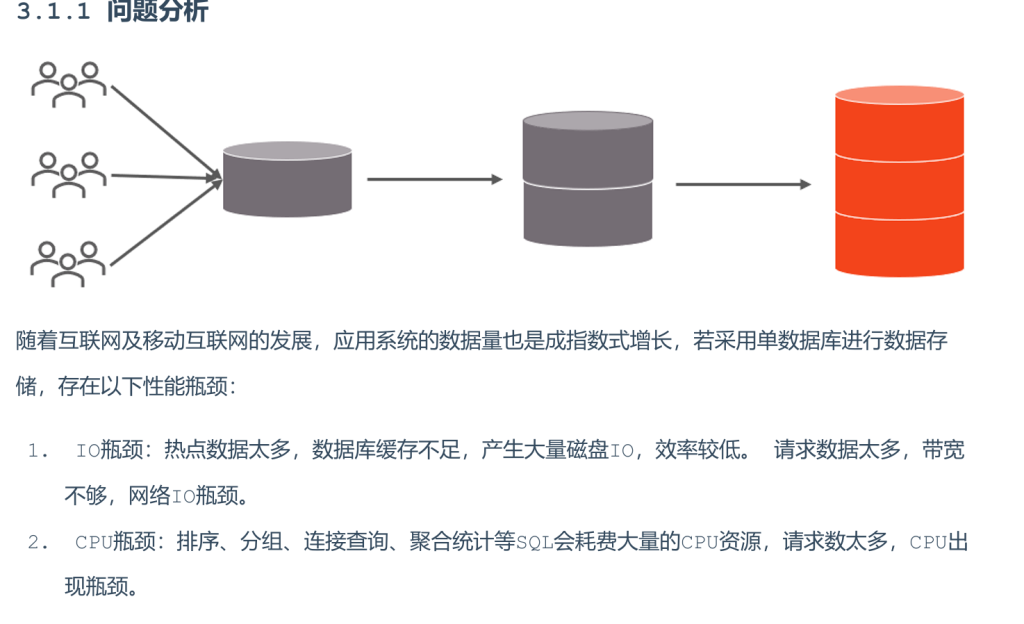
为了解决上述问题,我们需要对数据库进行分库分表处理。
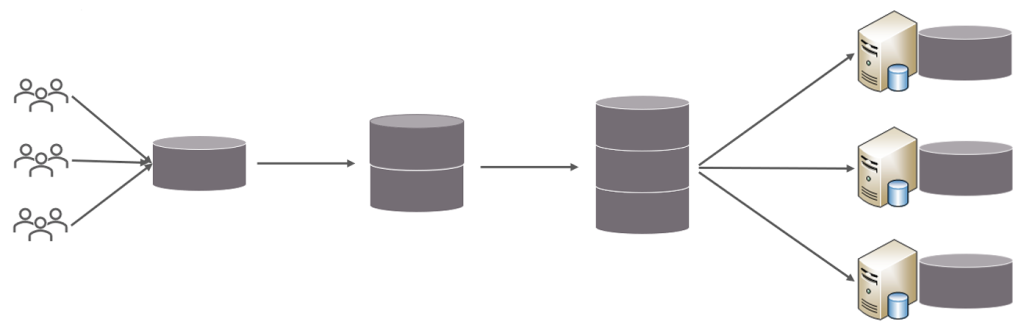
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能
问题,从而达到提升数据库性能的目的。
2.拆分策略
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组
成的拆分策略最终如下:
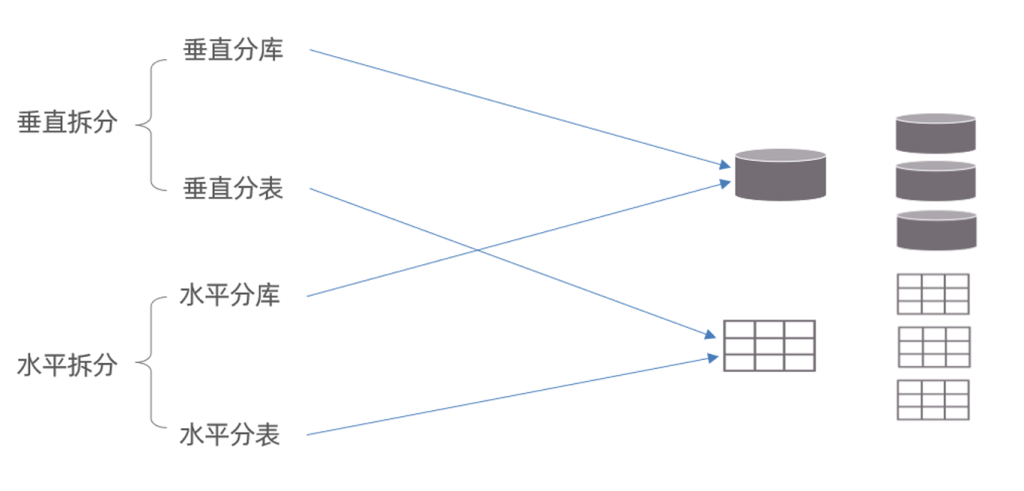
垂直拆分
1.垂直分库
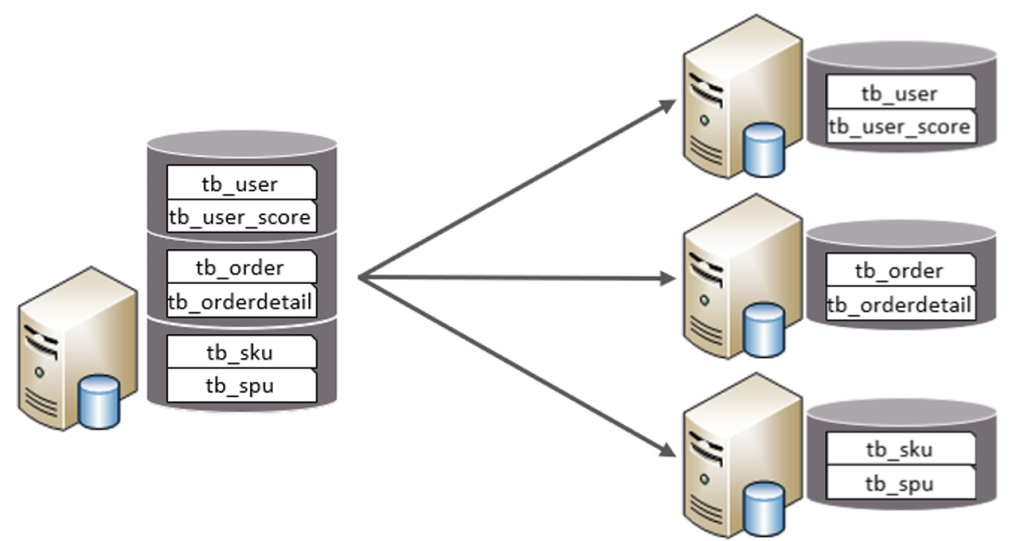
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
- 每个库的表结构都不一样。
- 每个库的数据也不一样。
- 所有库的并集是全量数据。
2.垂直分表
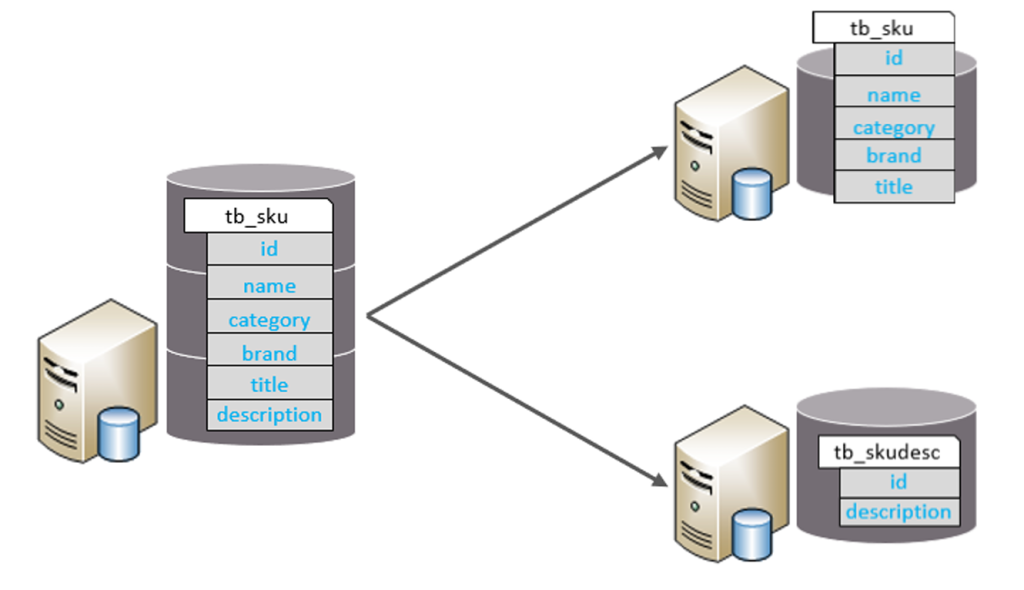
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点:
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
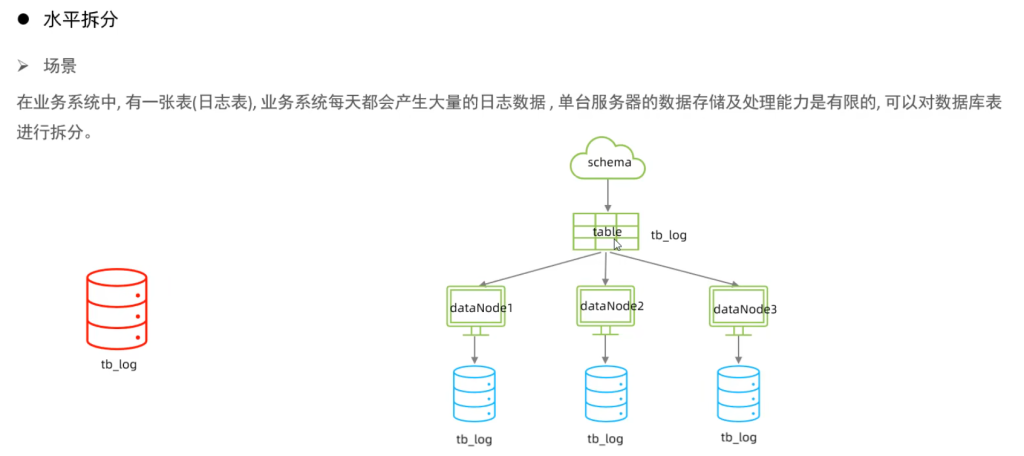
水平拆分
1.水平分库
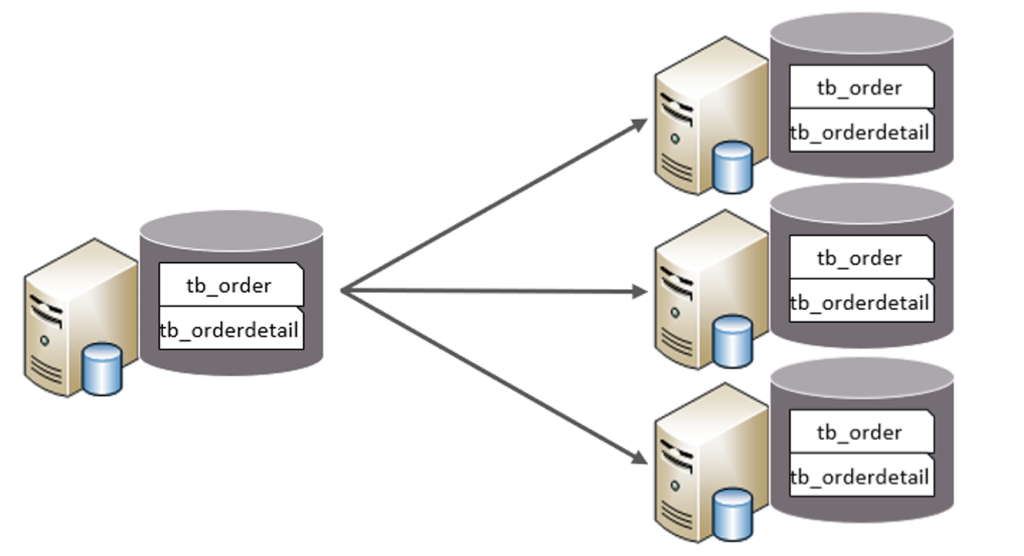
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
特点:
- 每个库的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全量数据。
2.水平分表
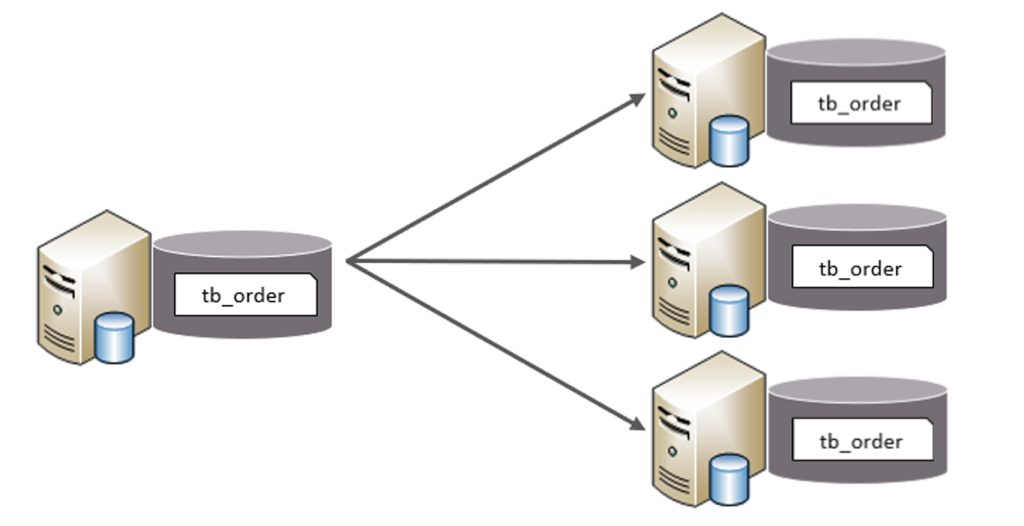
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
特点:
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分
库,还是分表,都需要根据具体的业务需求具体分析。
实现技术
- shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
- MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
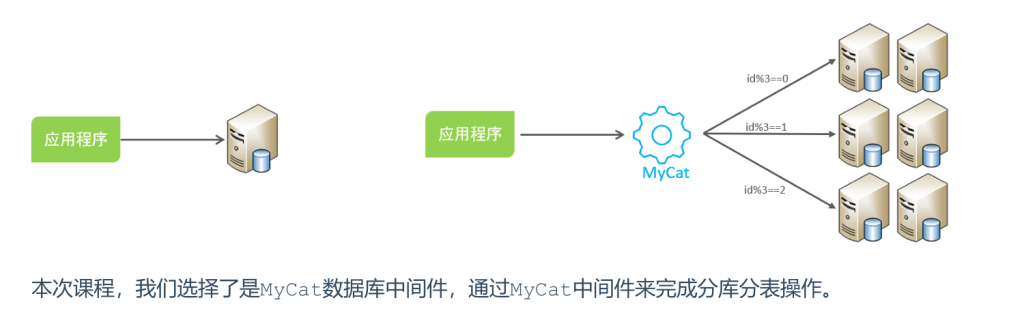
3.MyCat概述
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用
mycat,对于开发人员来说根本感觉不到mycat的存在
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数
据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。
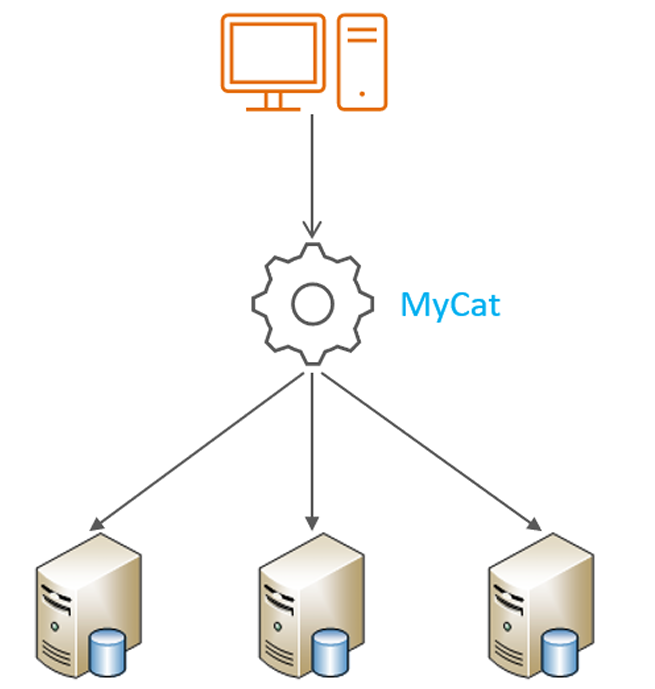
优势:
- 性能可靠稳定
- 强大的技术团队
- 体系完善
- 社区活跃
下载
安装
Mycat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境,下面介绍
MyCat的Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
- MySQL
- JDK
- Mycat
目录介绍
bin : 存放可执行文件,用于启动停止mycat
conf:存放mycat的配置文件
lib:存放mycat的项目依赖包(jar)
logs:存放mycat的日志文件
概念介绍
在MyCat的整体结构中,分为两个部分:上面的逻辑结构、下面的物理结构。
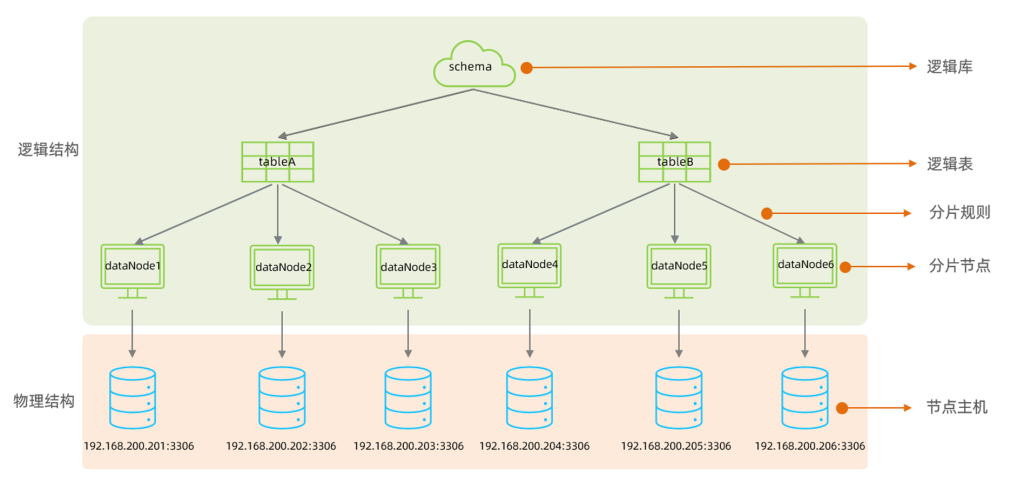
在MyCat的逻辑结构主要负责逻辑库、逻辑表、分片规则、分片节点等逻辑结构的处理,而具体的数据
存储还是在物理结构,也就是数据库服务器中存储的。
在后面讲解MyCat入门以及MyCat分片时,还会讲到上面所提到的概念。
4.MyCat入门
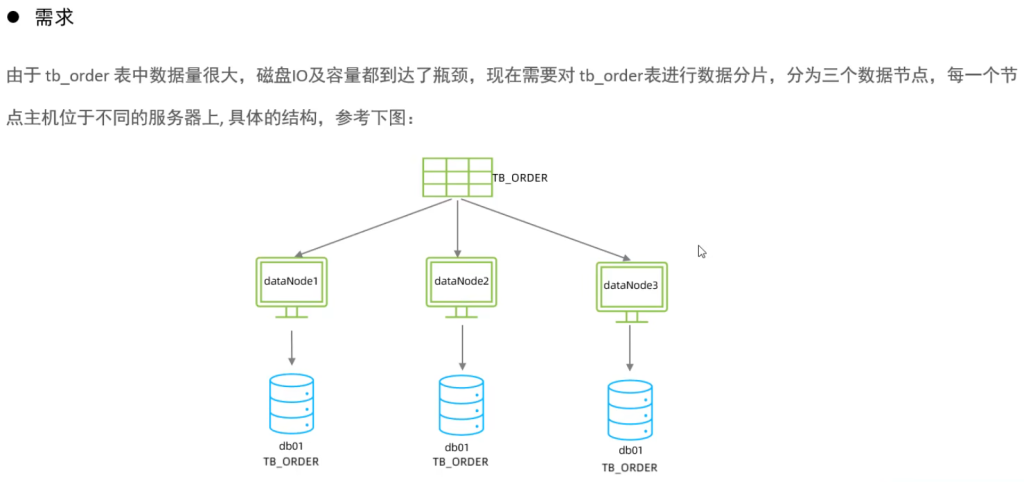
环境准备
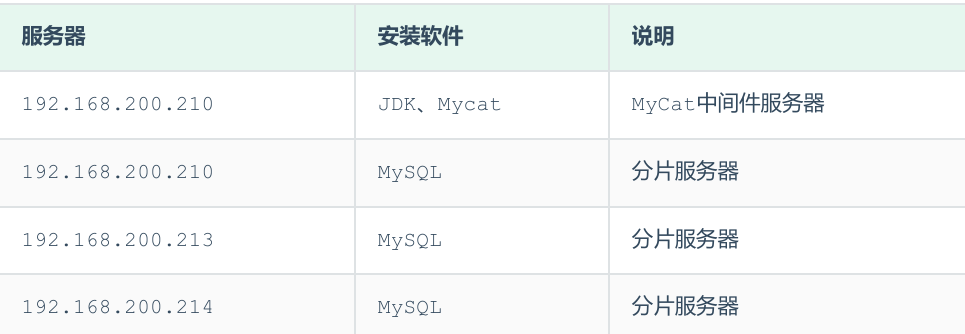
准备3台服务器:
192.168.200.210:MyCat中间件服务器,同时也是第一个分片服务器。
192.168.200.213:第二个分片服务器。
192.168.200.214:第三个分片服务器
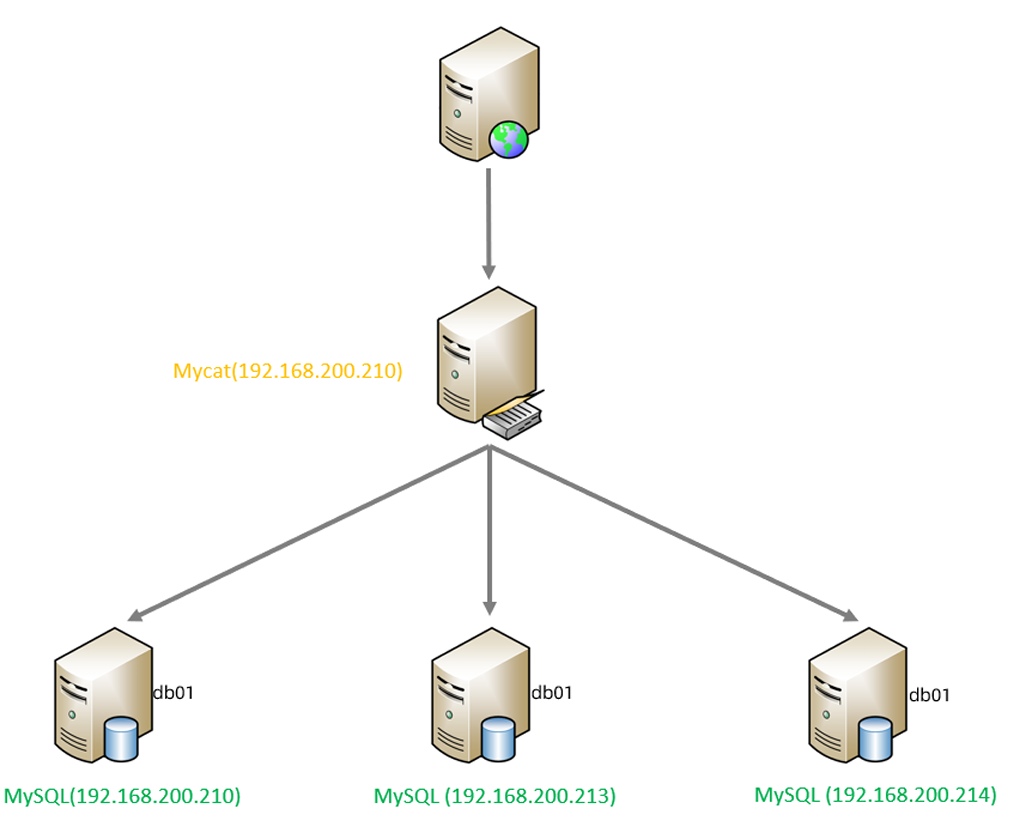
并且在上述3台数据库中创建数据库 db01 。
配置

启动服务
分片测试
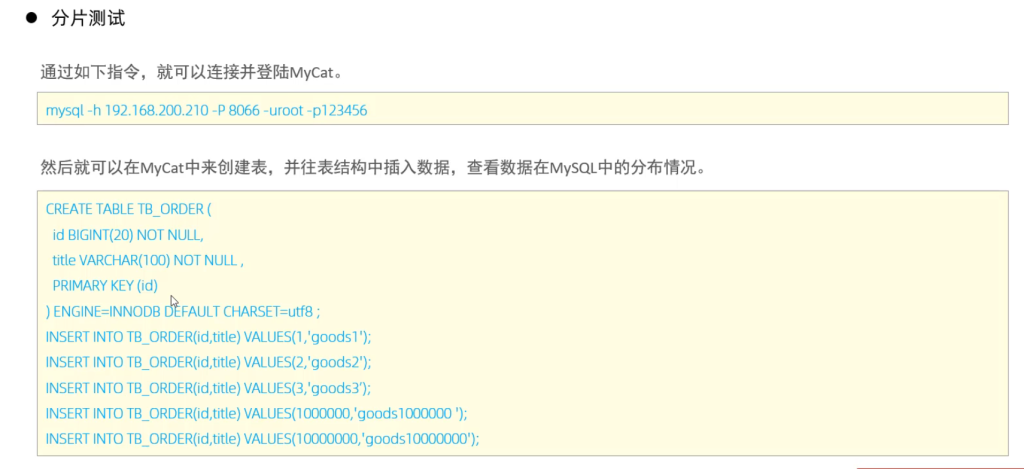
经过测试,我们发现,在往 TB_ORDER 表中插入数据时:
如果id的值在1-500w之间,数据将会存储在第一个分片数据库中。
如果id的值在500w-1000w之间,数据将会存储在第二个分片数据库中。
如果id的值在1000w-1500w之间,数据将会存储在第三个分片数据库中。
如果id的值超出1500w,在插入数据时,将会报错。
为什么会出现这种现象,数据到底落在哪一个分片服务器到底是如何决定的呢? 这是由逻辑表配置时
的一个参数 rule 决定的,而这个参数配置的就是分片规则,关于分片规则的配置,在后面的课程中
会详细讲解
5.MyCat配置
schema.xml
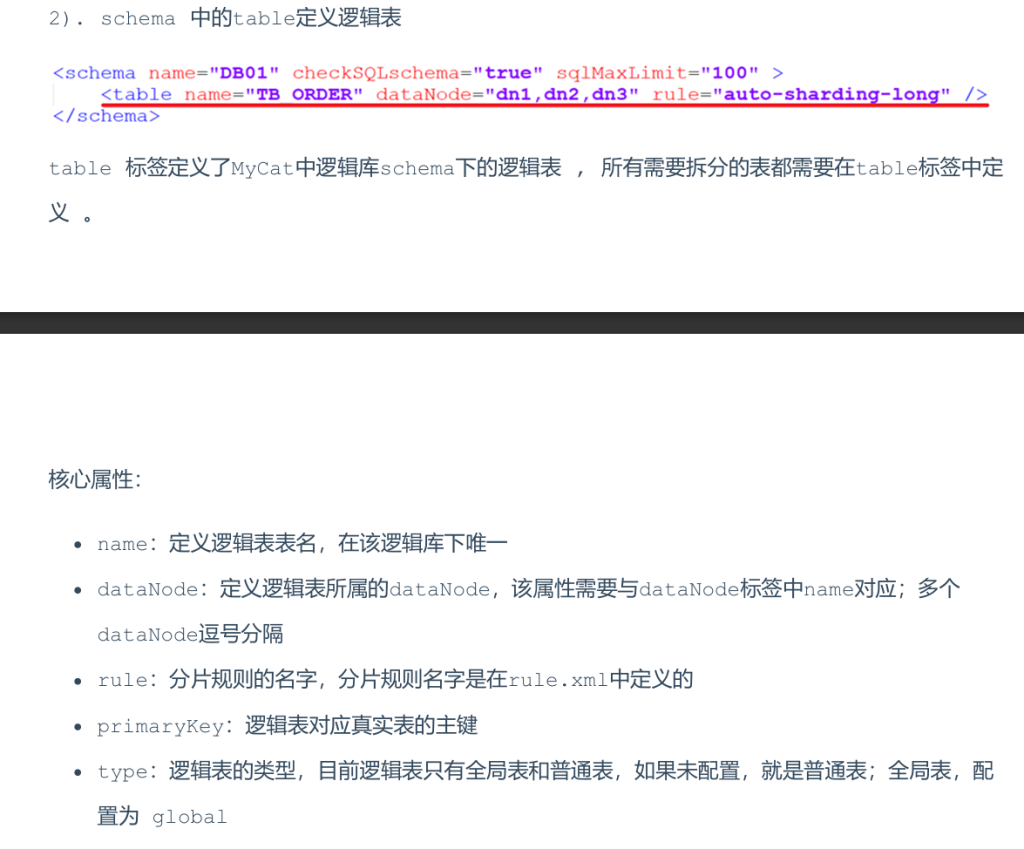
schema.xml作为MyCat中最重要的配置文件之一,涵盖了MyCat的逻辑库 、逻辑表 、分片规则、分片节点及数据源的配置.
主要包含以下三组标签:
- schema标签
- datanode标签
- datahost标签




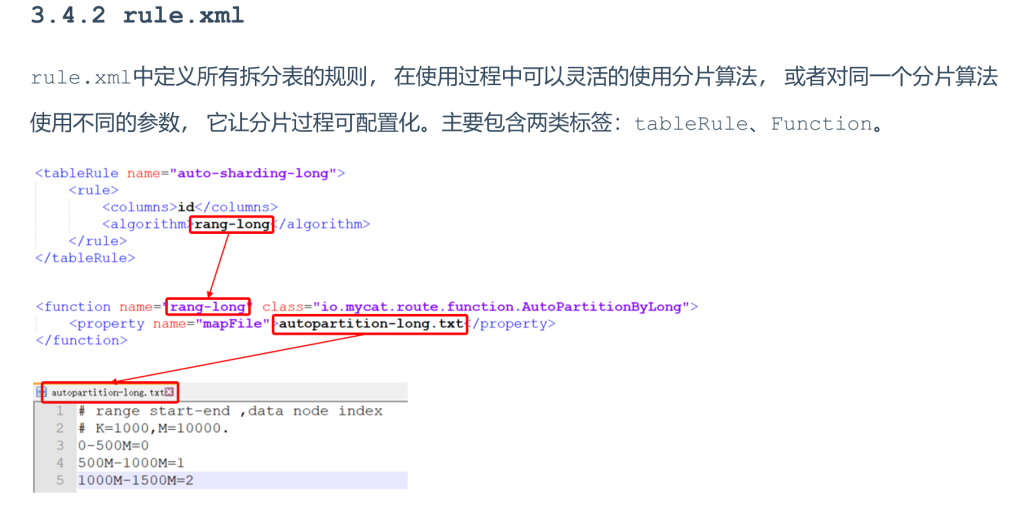
rule.xml
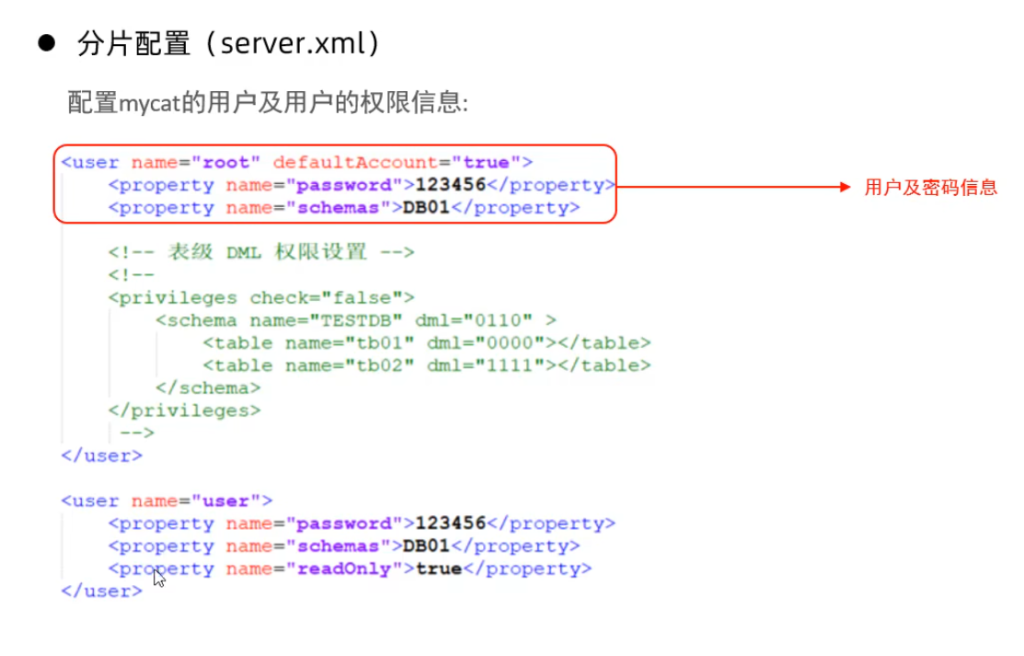
server.xml


6.MyCat分片
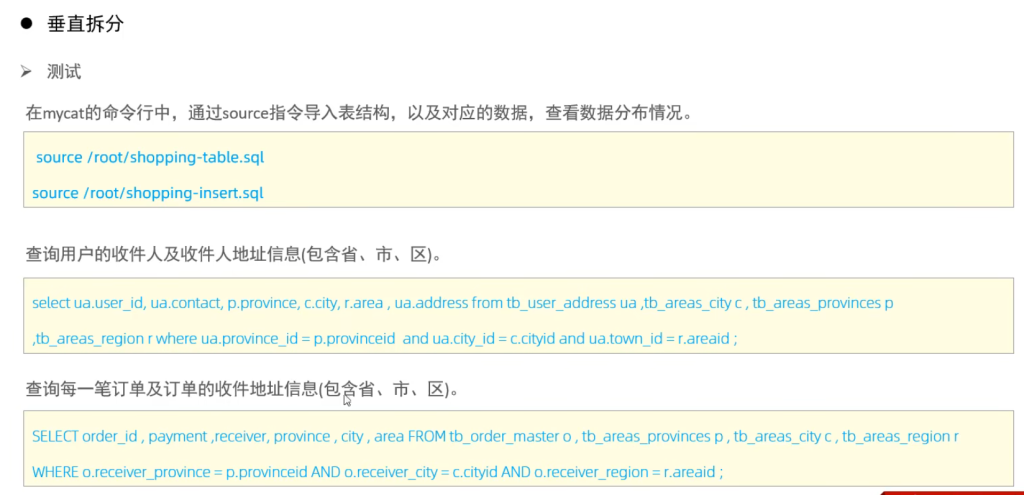
垂直拆分



水平拆分
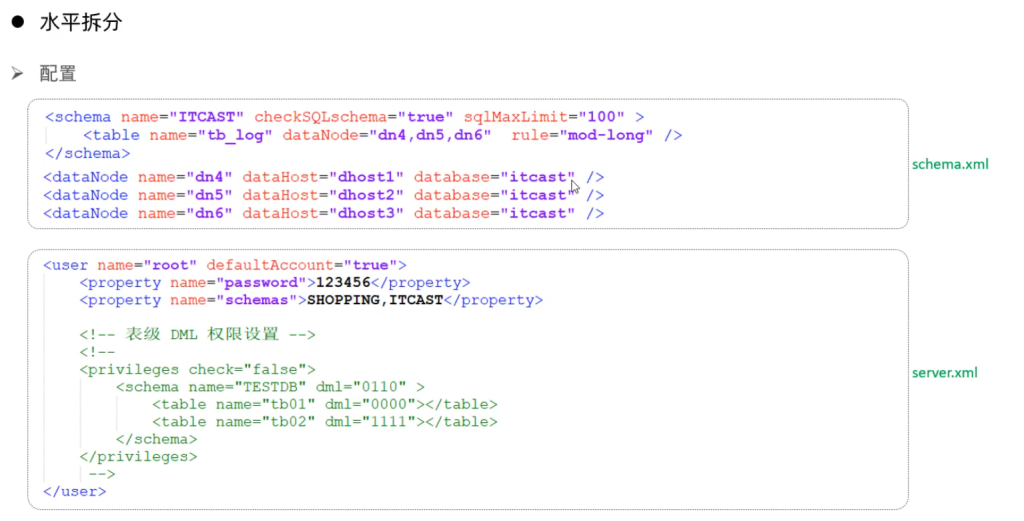

分片规则
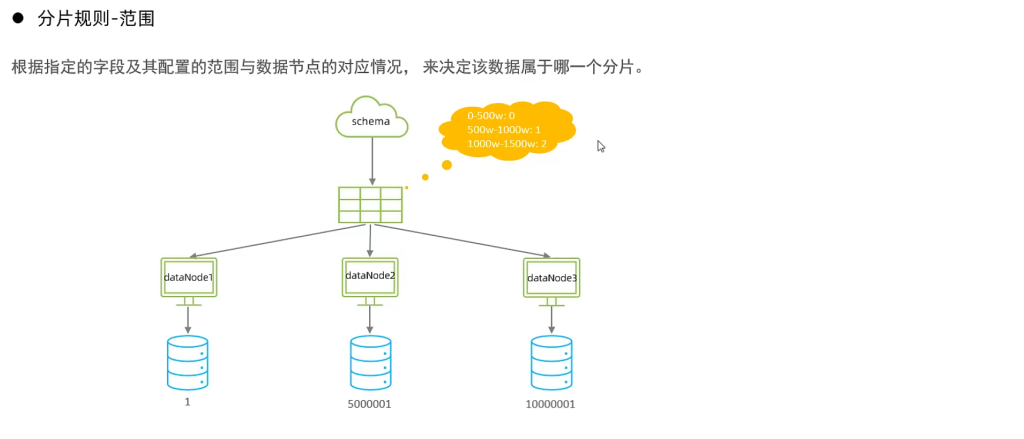
1.范围分片
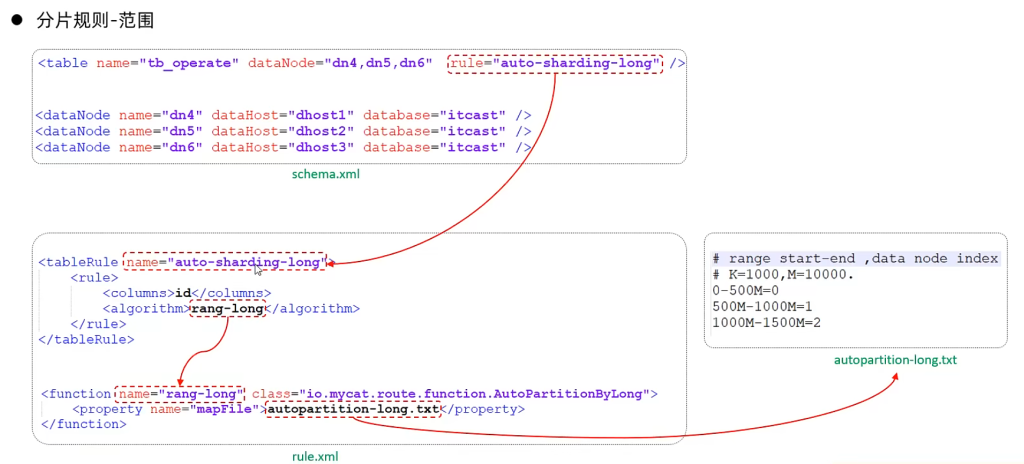
rule.xml中:
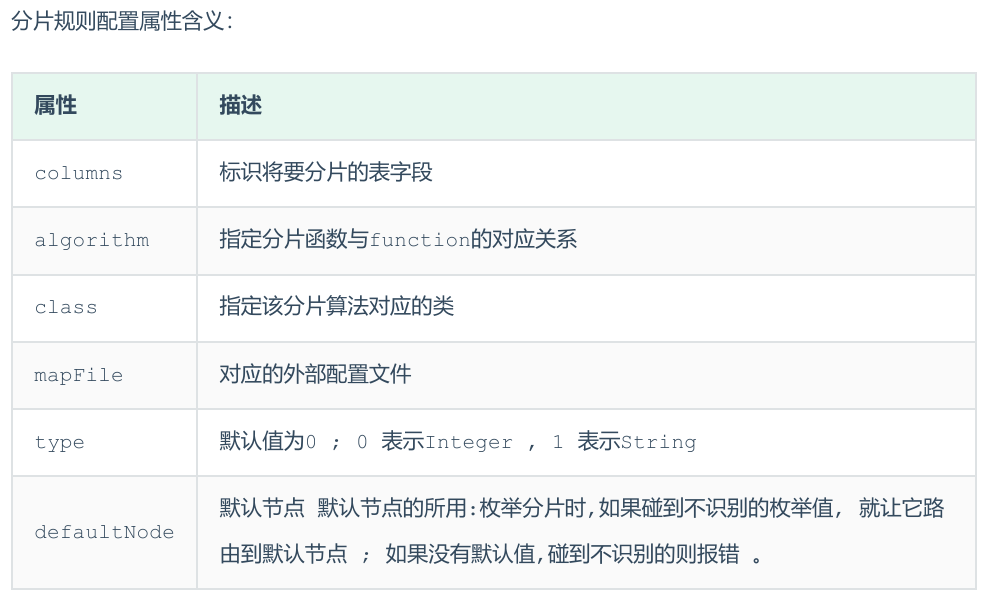
autopartition-long.txt中:含义:0-500万之间的值,存储在0号数据节点(数据节点的索引从0开始) ; 500万-1000万之间的数据存储在1号数据节点 ; 1000万-1500万的数据节点存储在2号节点 ;
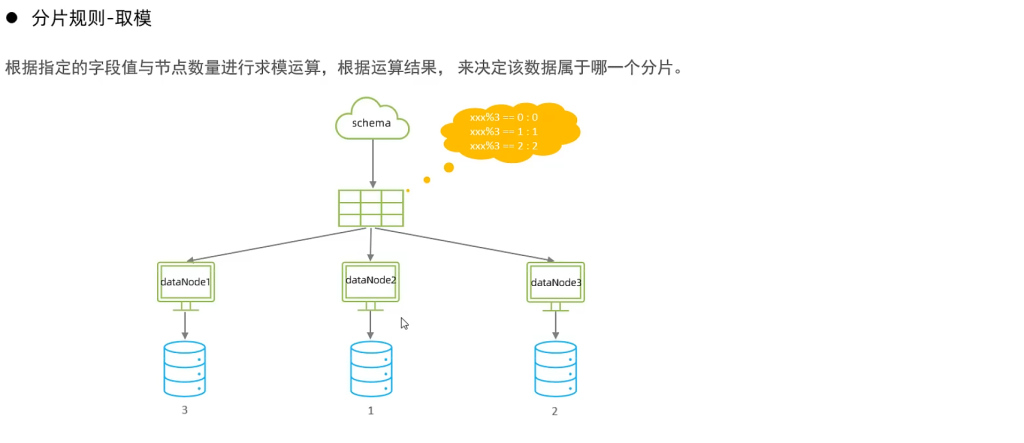
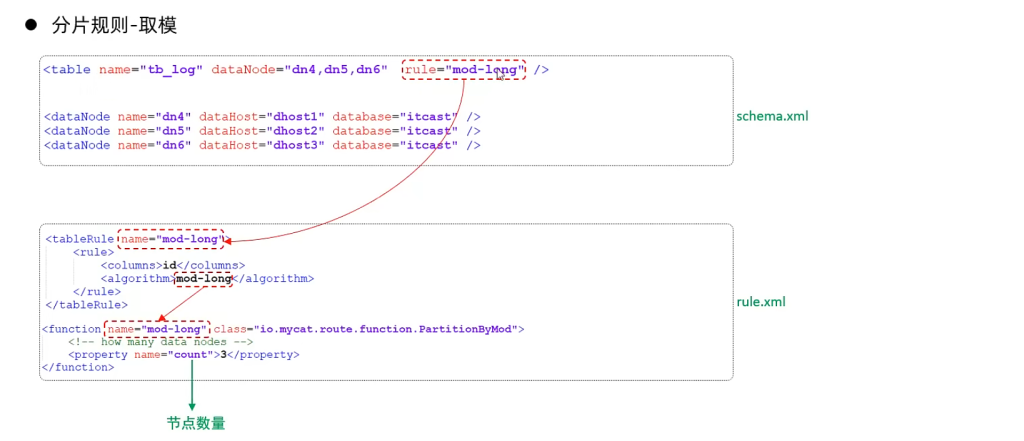
2.取模分片

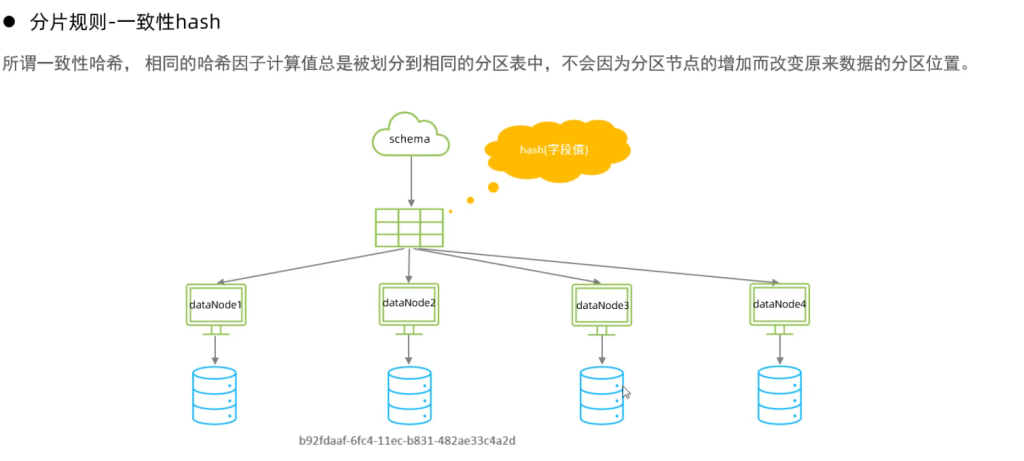
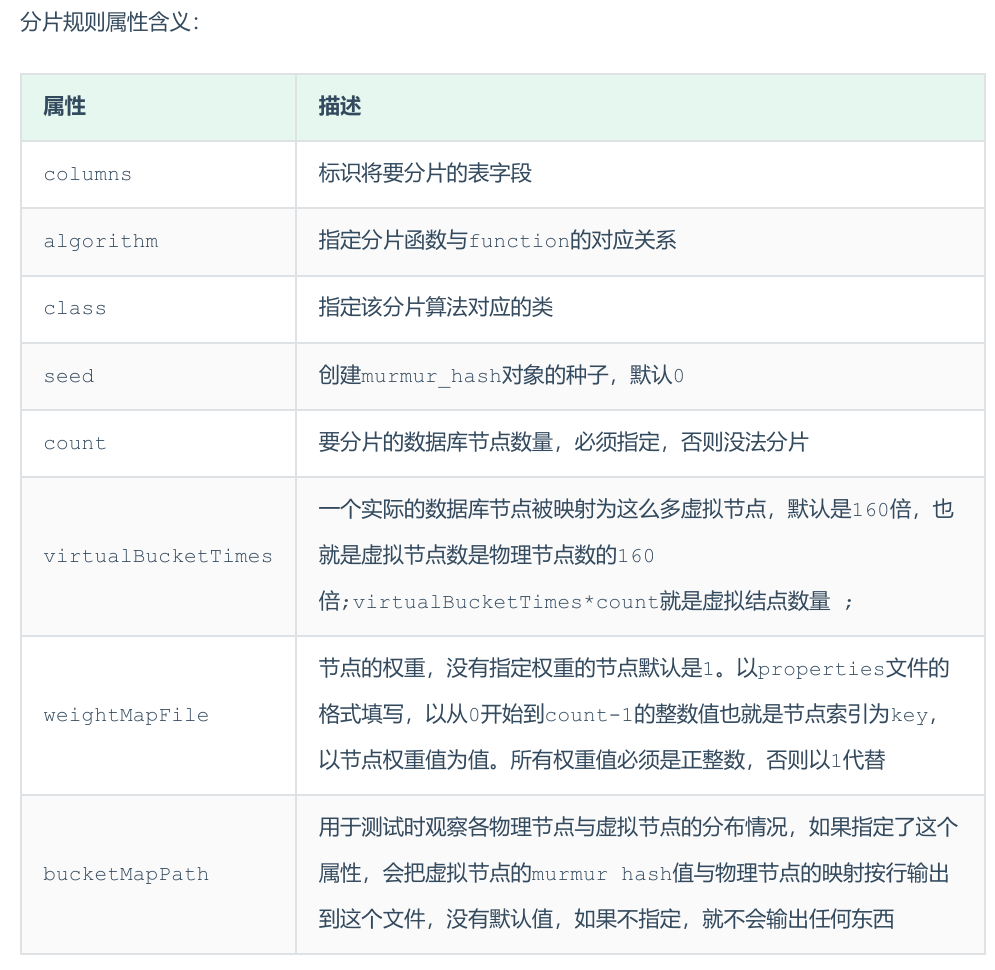
3.一致性hash分片

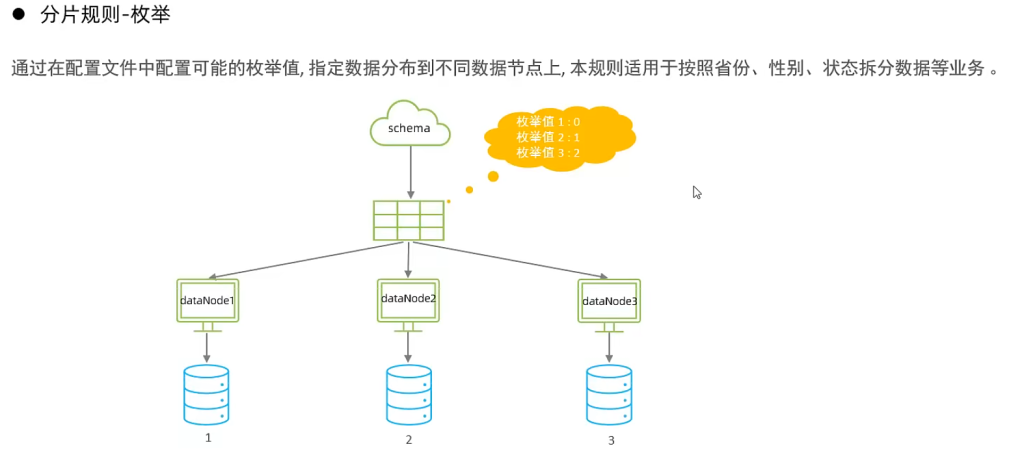
4.枚举分片


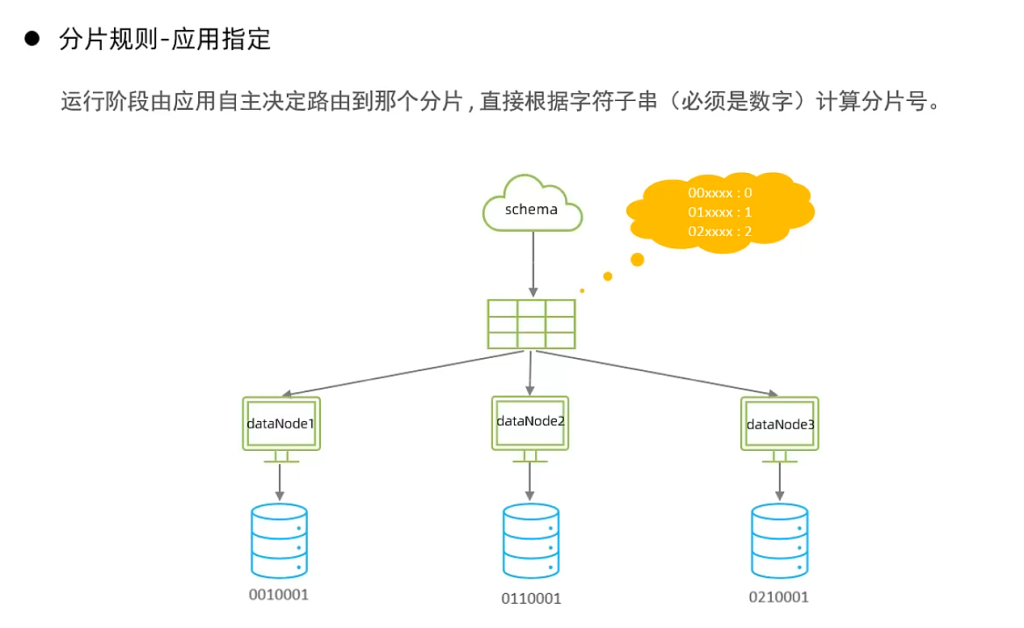
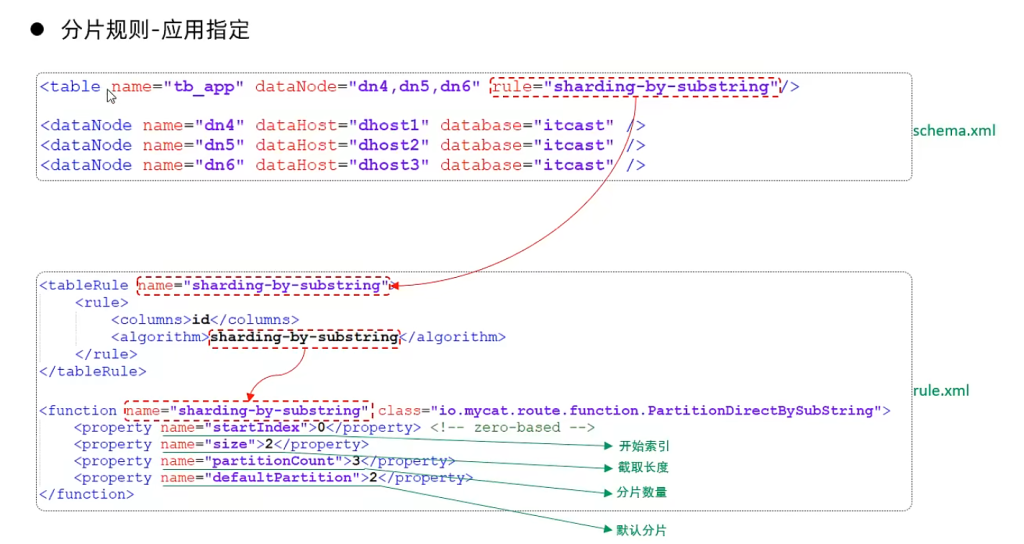
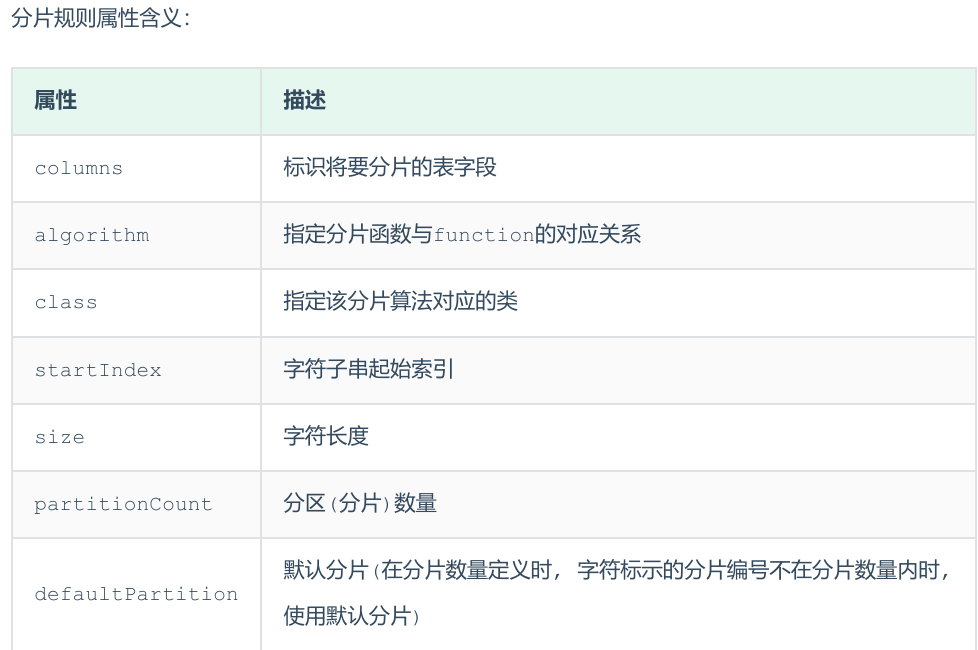
5.应用指定算法
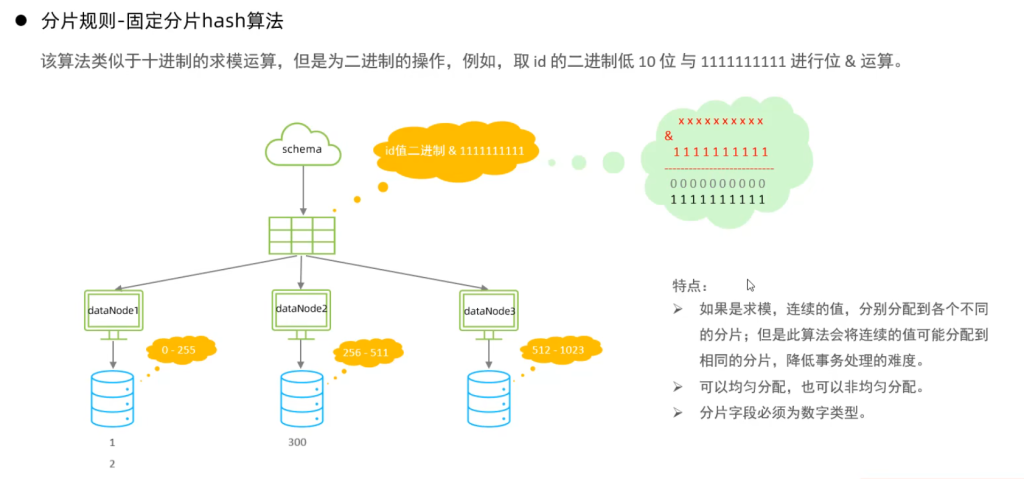
6.固定hash算法
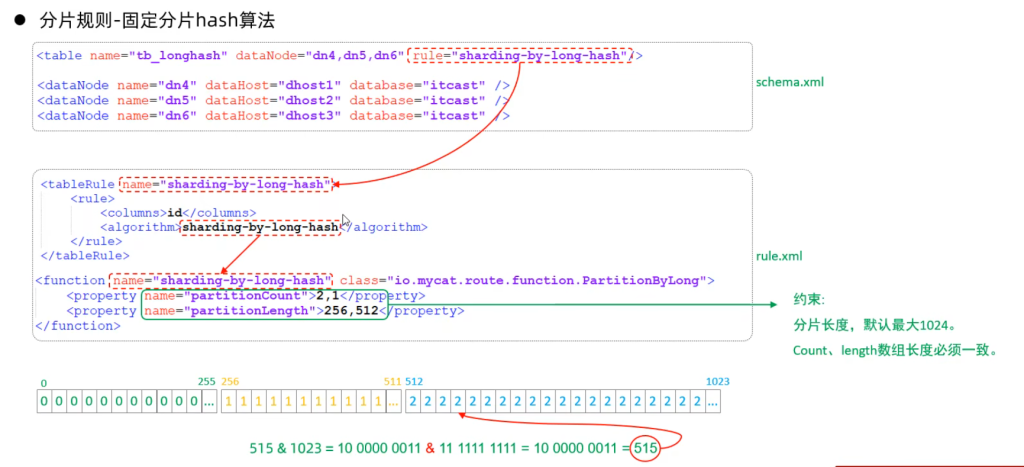
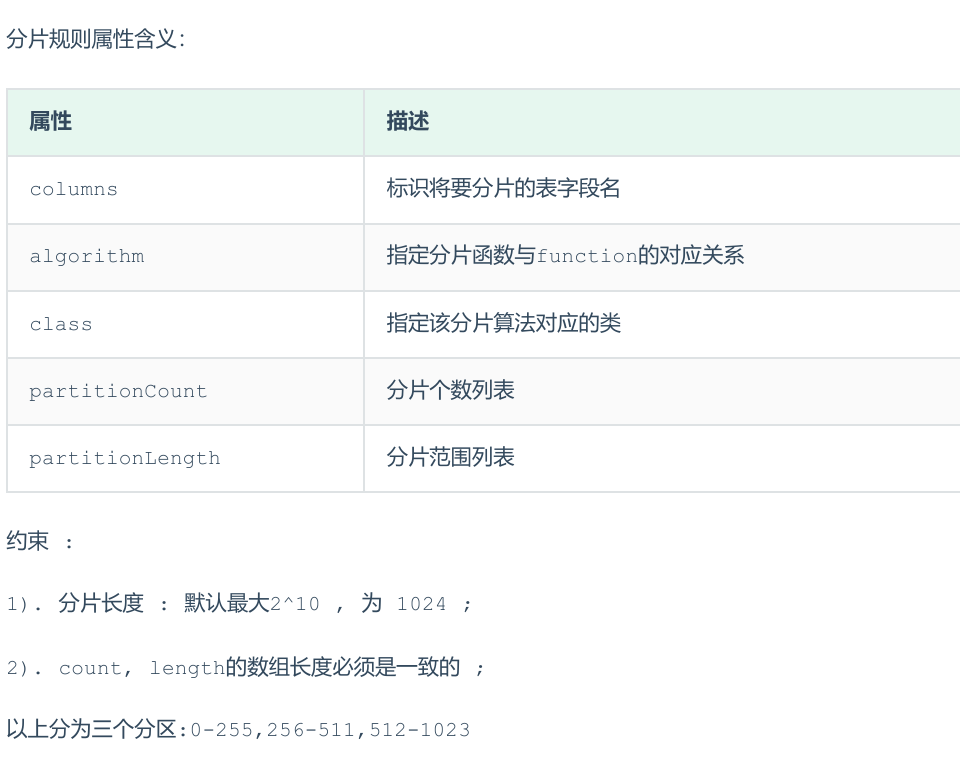
7.字符串hash解析算法
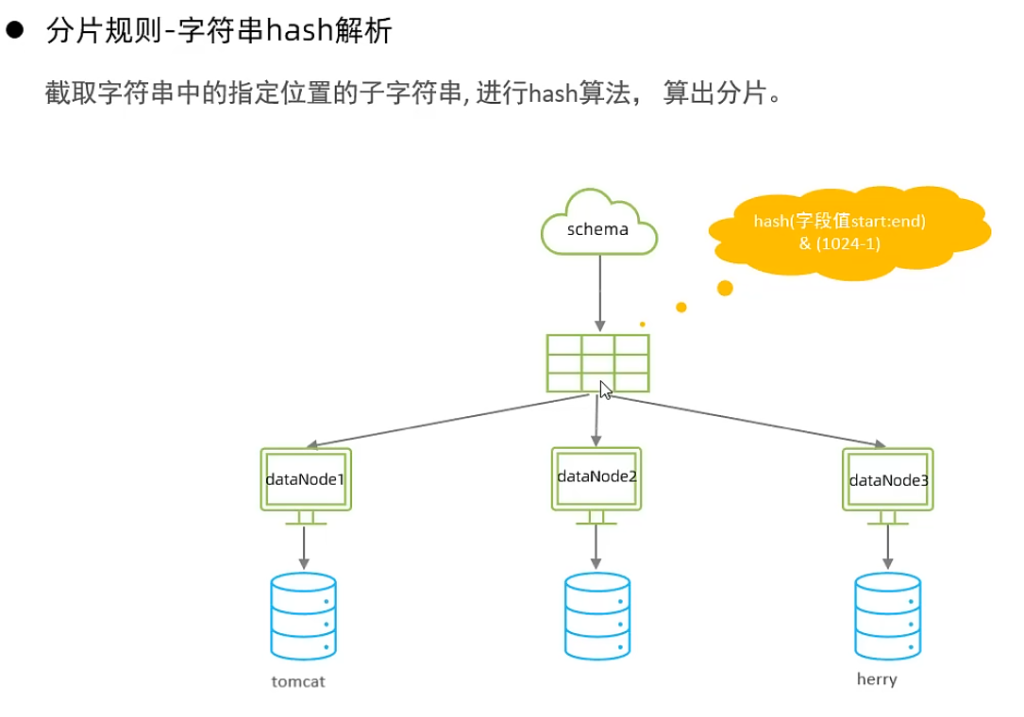
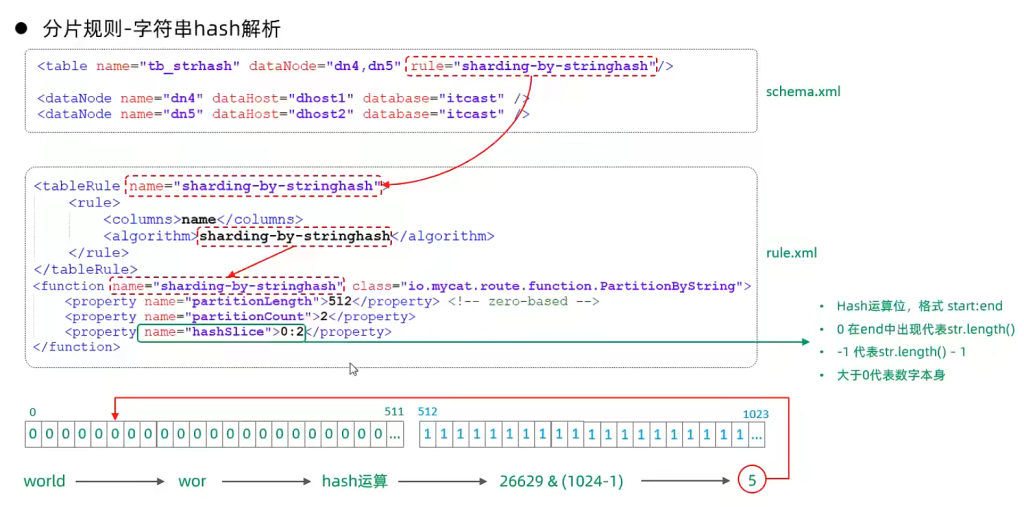

8.按天分片
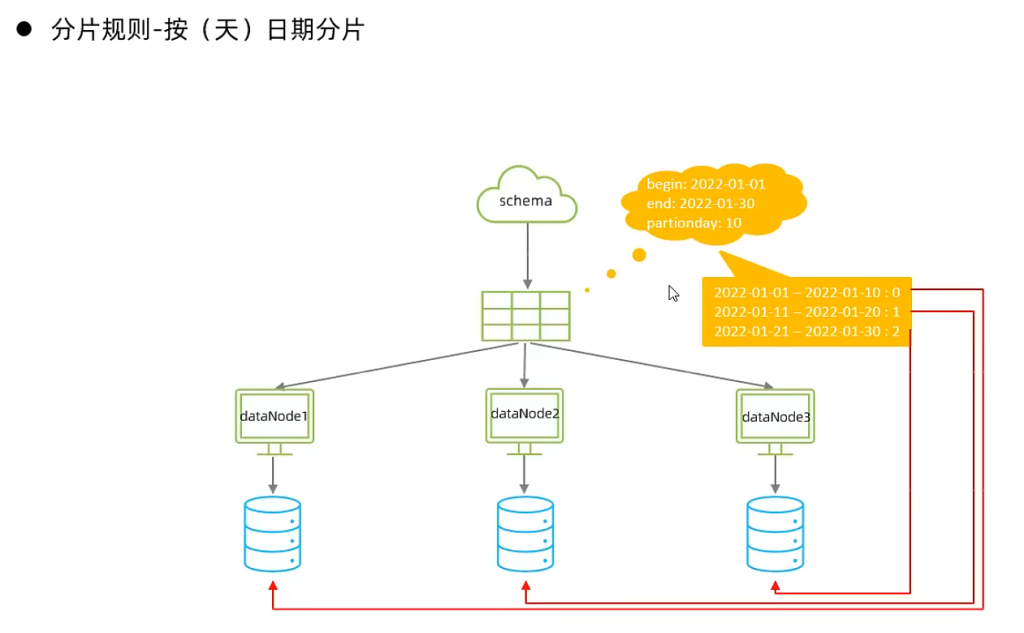

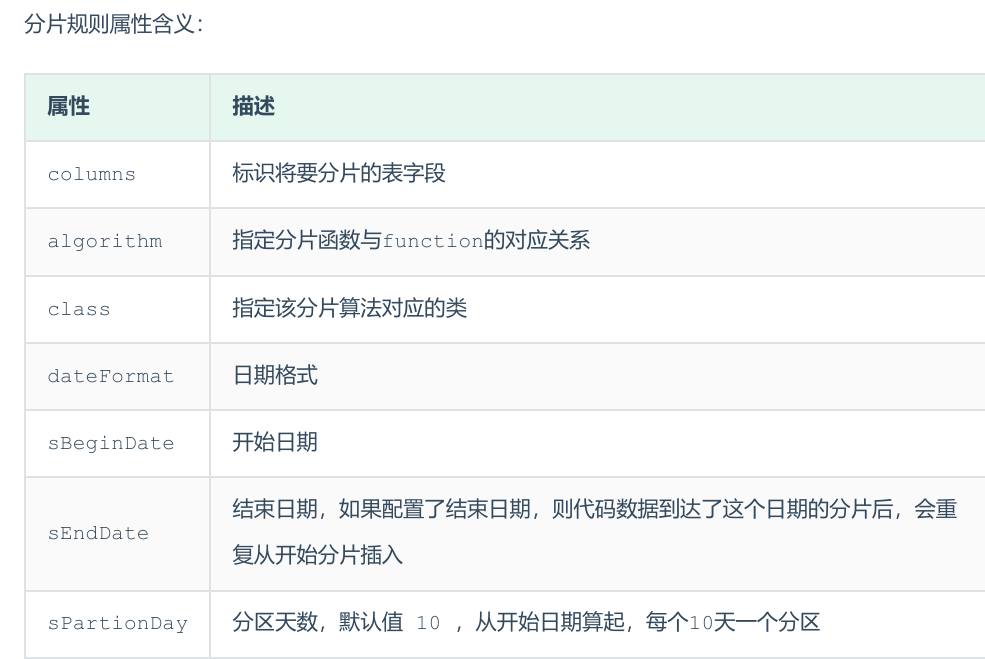
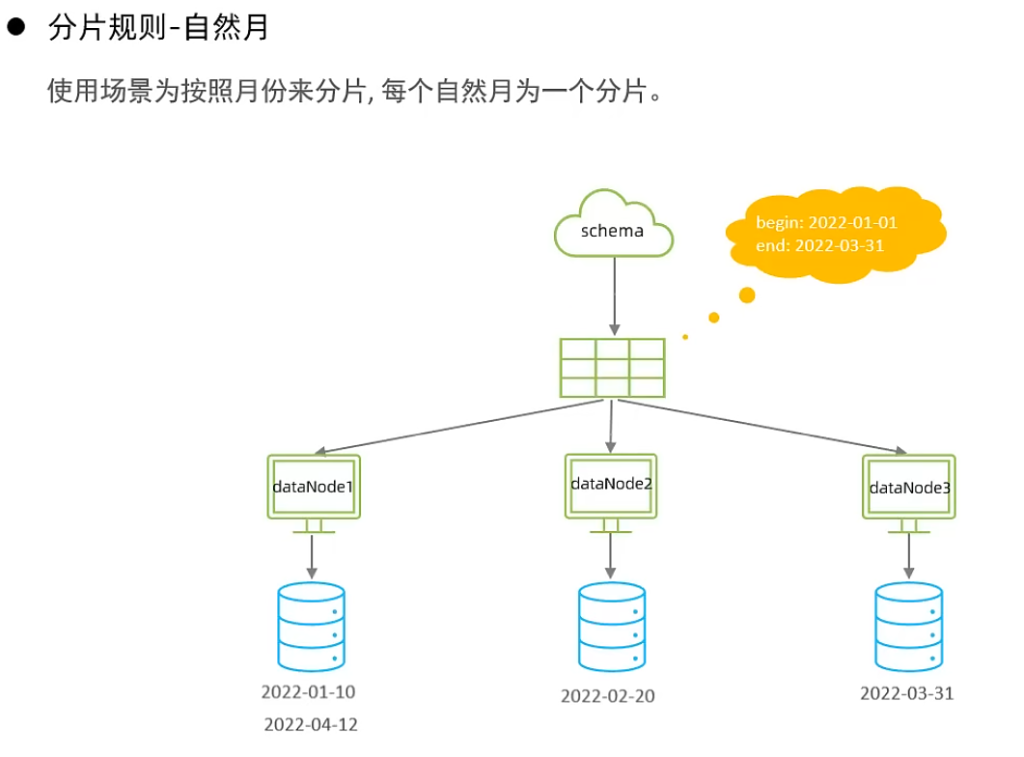
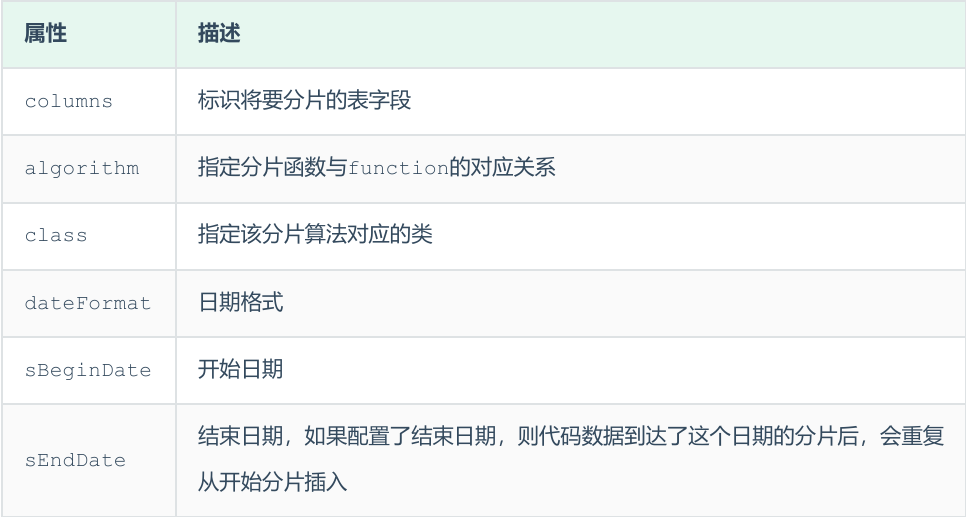
9.按自然月分片

7.MyCat管理及监控
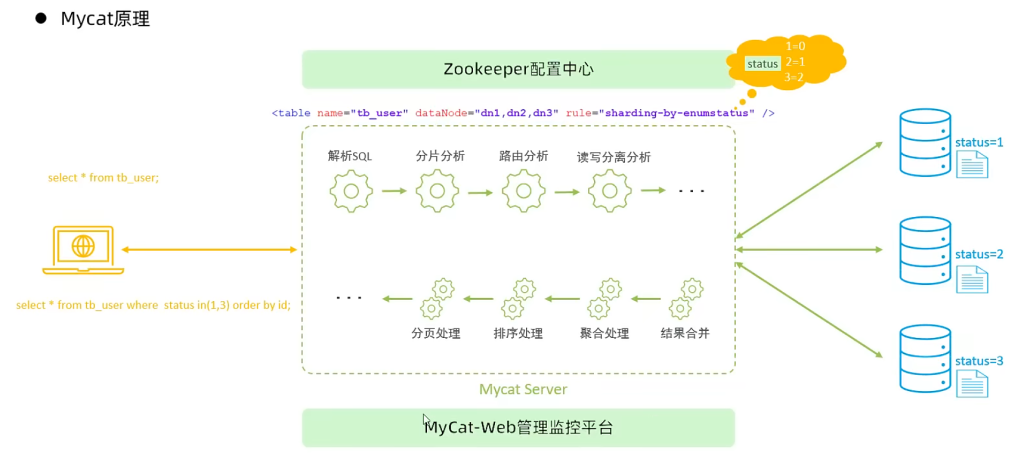
在MyCat中,当执行一条SQL语句时,MyCat需要进行SQL解析、分片分析、路由分析、读写分离分析
等操作,最终经过一系列的分析决定将当前的SQL语句到底路由到那几个(或哪一个)节点数据库,数据
库将数据执行完毕后,如果有返回的结果,则将结果返回给MyCat,最终还需要在MyCat中进行结果合
并、聚合处理、排序处理、分页处理等操作,最终再将结果返回给客户端。
而在MyCat的使用过程中,MyCat官方也提供了一个管理监控平台MyCat-Web(MyCat-eye)。
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat
分担统计任务和配置管理任务。Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节
点。Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮
件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据。


访问
http://192.168.200.210:8082/mycat
配置
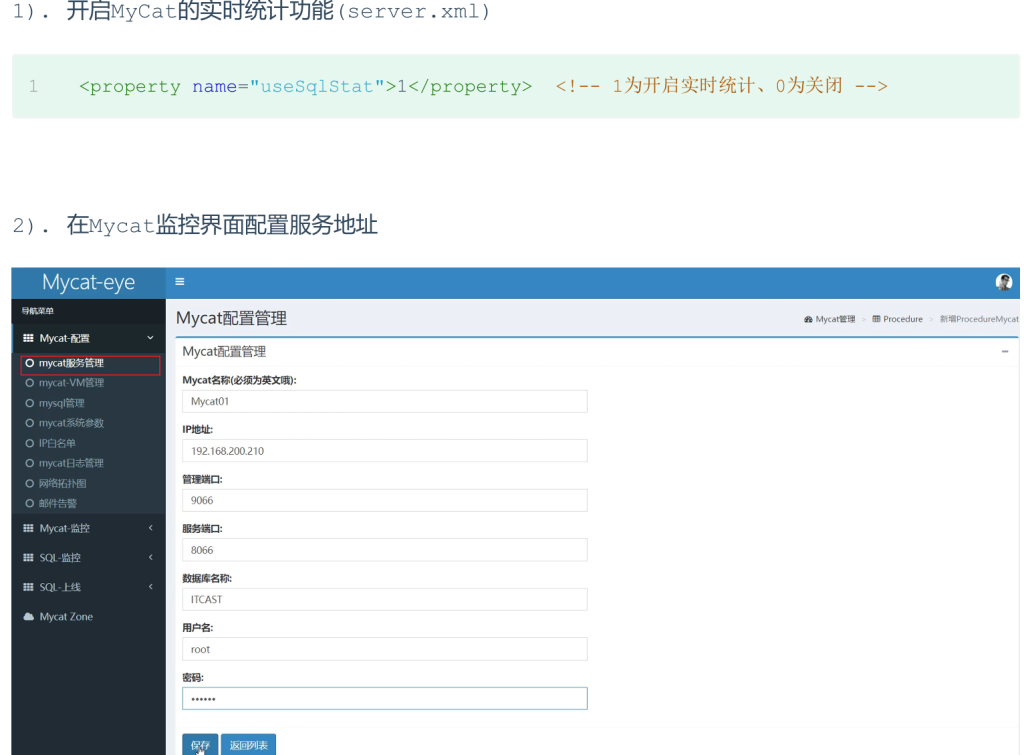
测试
配置好了之后,我们可以通过MyCat执行一系列的增删改查的测试,然后过一段时间之后,打开
mycat-eye的管理界面,查看mycat-eye监控到的数据信息。
性能监控、物理节点、SQL统计、SQL表分析、SQL监控、高频SQL
8.分库分表 小结
4.读写分离
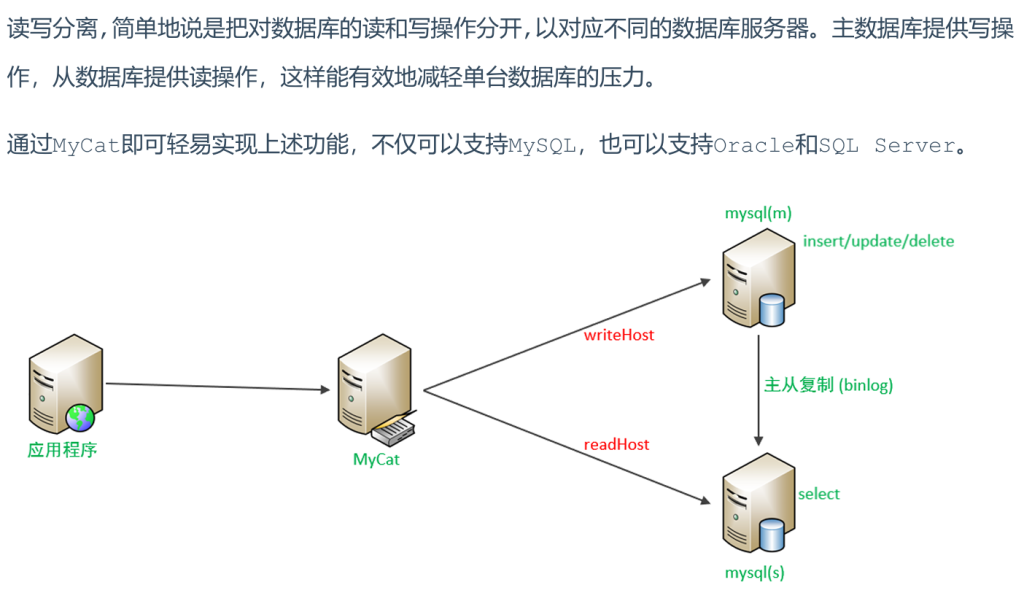
1.介绍
2.一主一从
3.一主一从读写分离
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控
制。
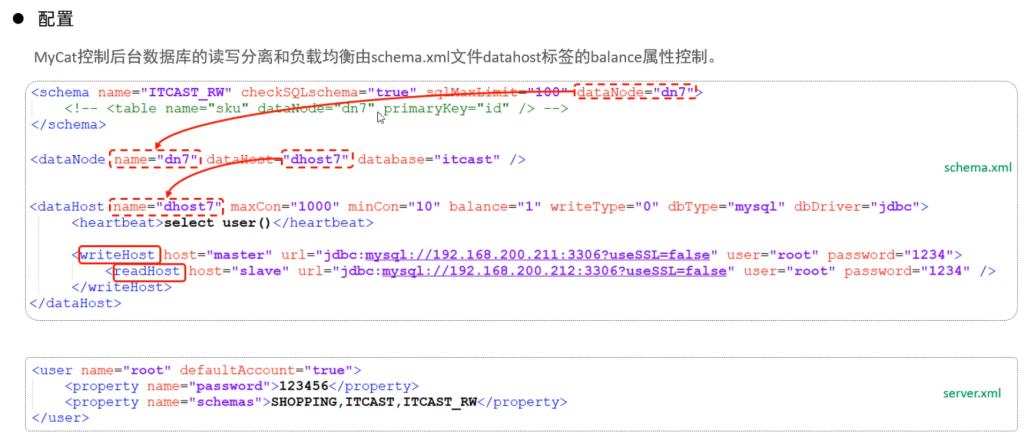

writeHost代表的是写操作对应的数据库,readHost代表的是读操作对应的数据库。 所以我们要想
实现读写分离,就得配置writeHost关联的是主库,readHost关联的是从库。
而仅仅配置好了writeHost以及readHost还不能完成读写分离,还需要配置一个非常重要的负责均衡
的参数 balance,取值有4种
所以,在一主一从模式的读写分离中,balance配置1或3都是可以完成读写分离的。
4.双主双从
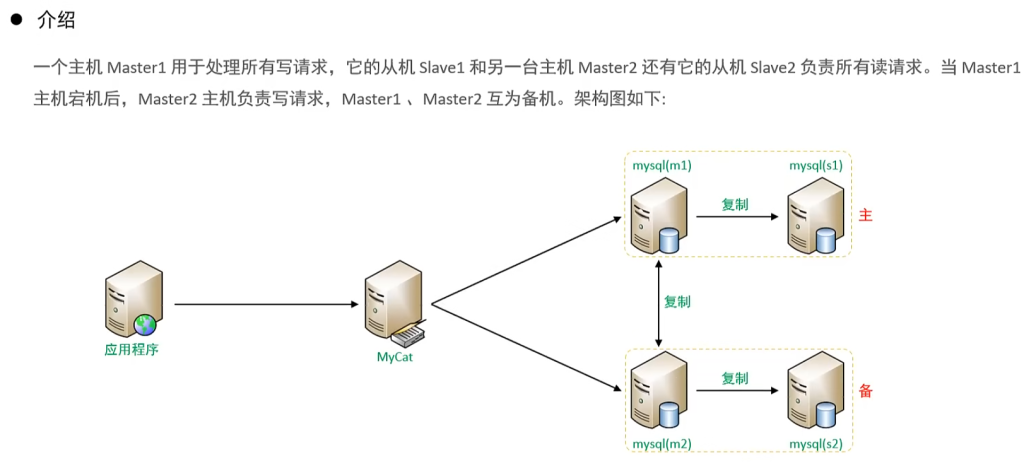
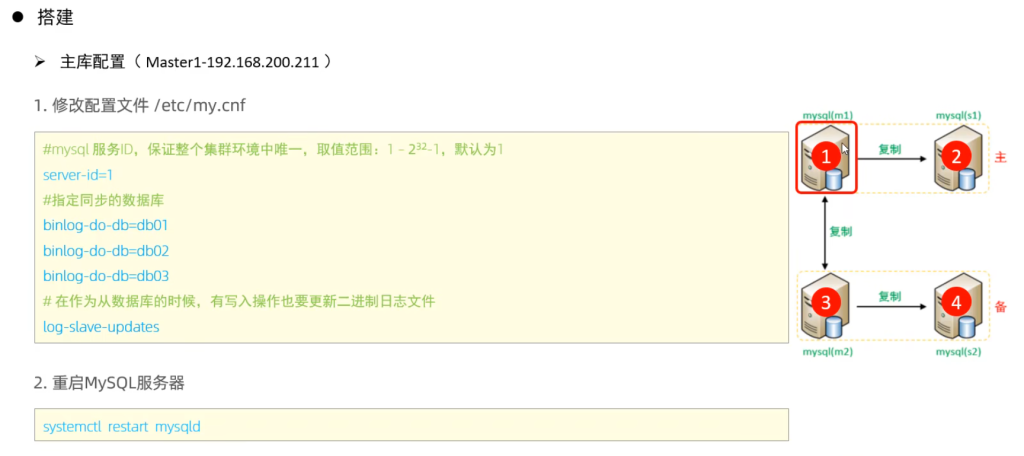
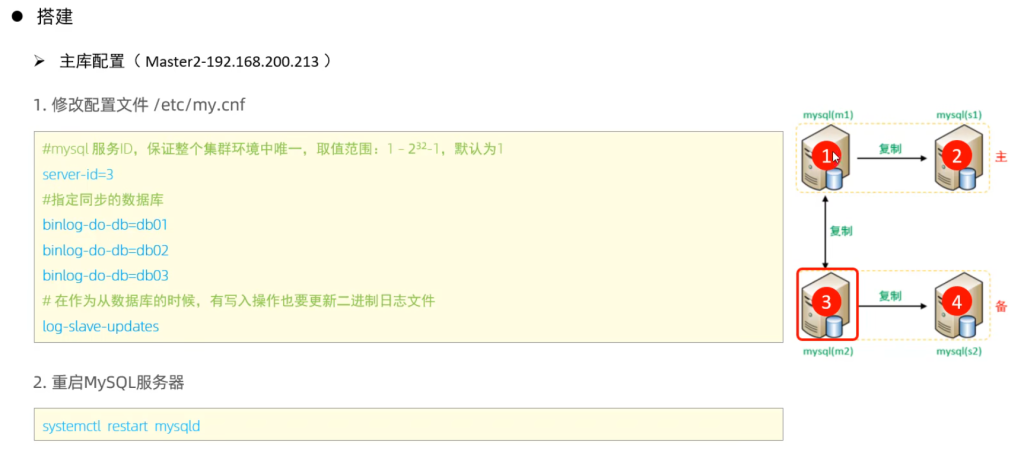
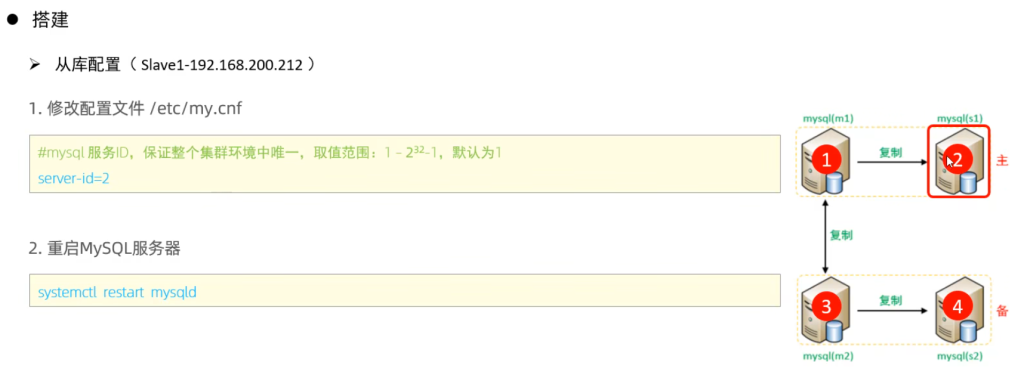
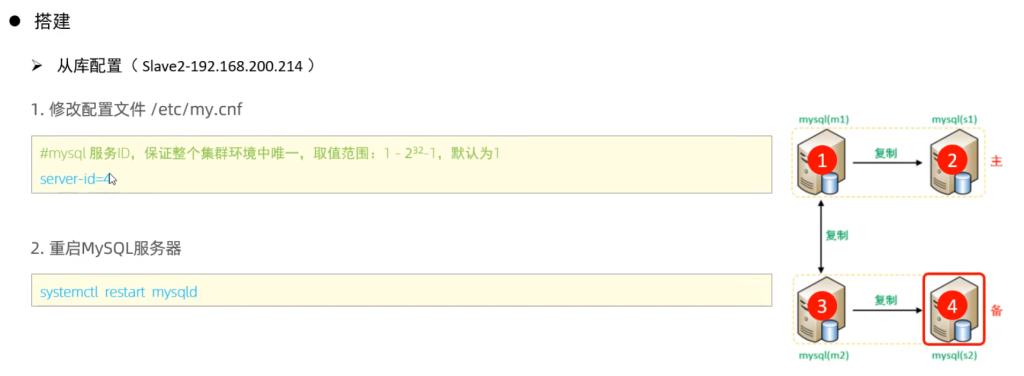
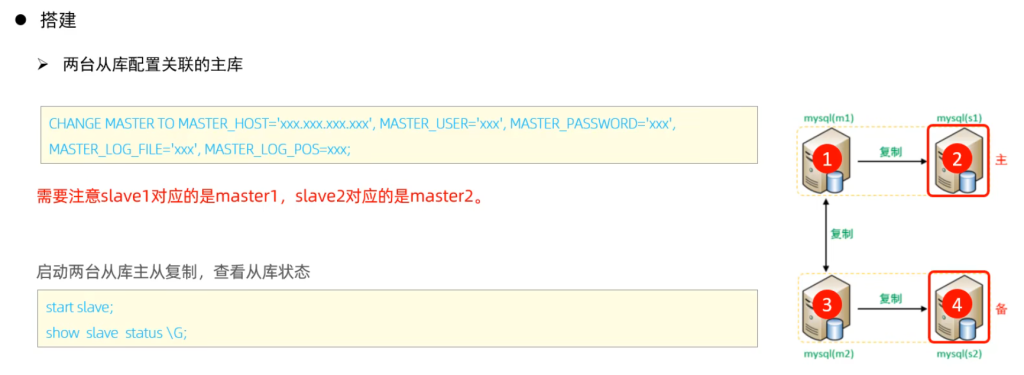
分别在两台主库Master1、Master2上执行DDL、DML语句,查看涉及到的数据库服务器的数据同步情况。
1 | create database db01; |
- 在Master1中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中。
- 在Master2中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中。
完成了上述双主双从的结构搭建之后,接下来,我们再来看看如何完成这种双主双从的读写分离。
5.双主双从读写分离
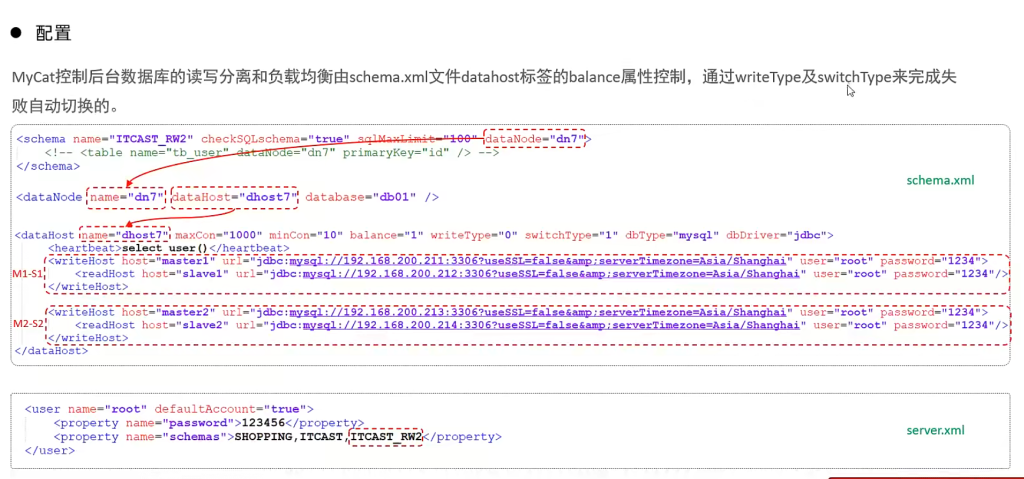
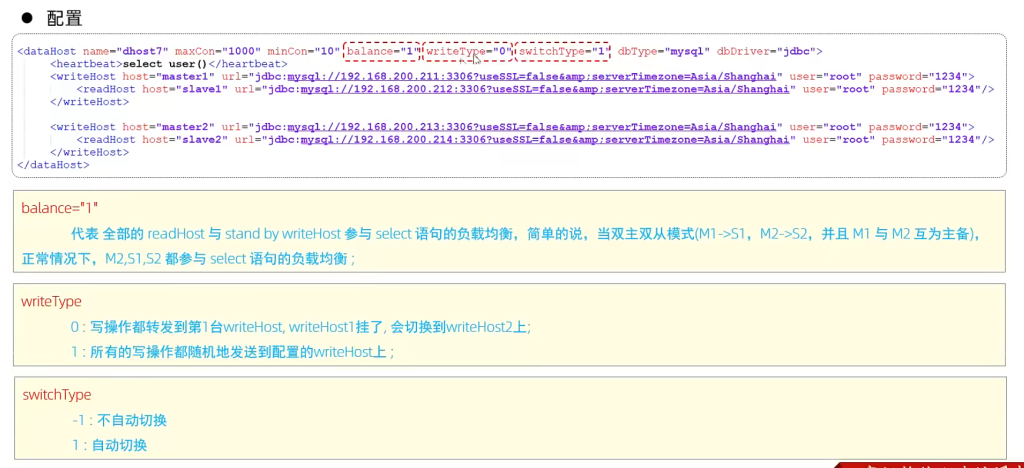
测试:
登录MyCat,测试查询及更新操作,判定是否能够进行读写分离,以及读写分离的策略是否正确。
当主库挂掉一个之后,是否能够自动切换。
6.读写分类 小结

5.运维篇小结



