前言
了解单体架构,集群架构,分布式架构
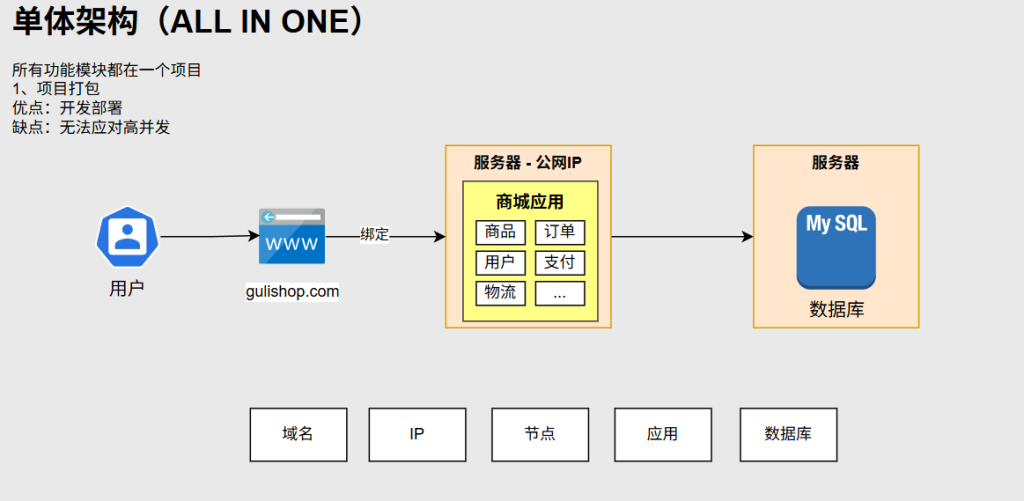
单体架构
域名:IP地址好记的名字
IP:在互联网上任何设备都是通过IP进行访问的
节点:一个服务器代表一个节点
在服务器节点上可以部署我们开发的应用与数据库
单体架构
优点:开发部署简单
缺点:单体架构性能有限,无法应对高并发
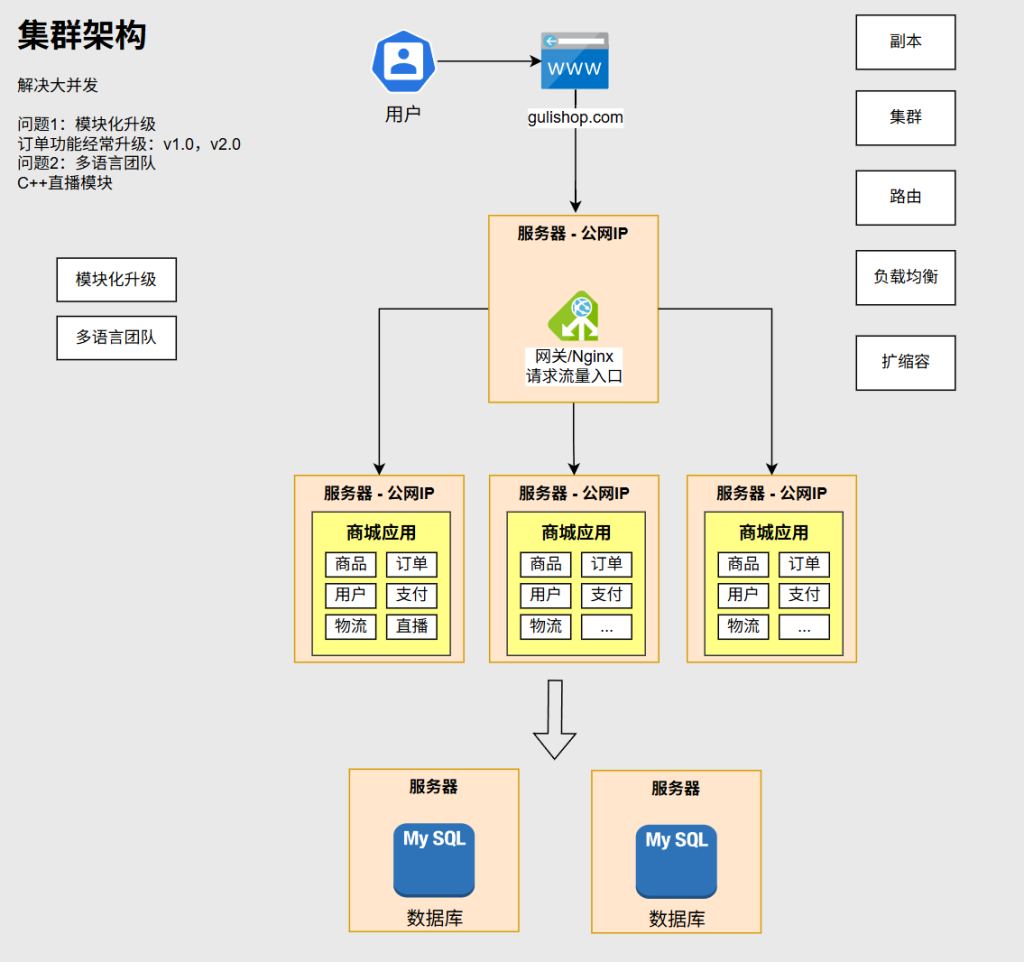
集群架构
副本:是项目的复制品
集群:多个节点服务器构成了集群
网关(Nginx):网关并不能真正的处理业务请求,它的作用是把收来的所有请求转给下边真正能处理业务的服务器,网关是所有请求流量的入口
路由:网关要完成的功能
负载均衡:网关路由时通过负载均衡的算法,把请求的流量均摊给这些服务器
数据库请求多了一个数据库也是扛不住的,因此也需要数据库集群
扩容与缩容:如果并发流量继续增大,就可以对服务器再进行扩容。如果大并发访问已经过去了,多购买的服务器可以释放掉,节省资源,这便是缩容。
集群架构是解决大并发问题
集群架构存在的问题?
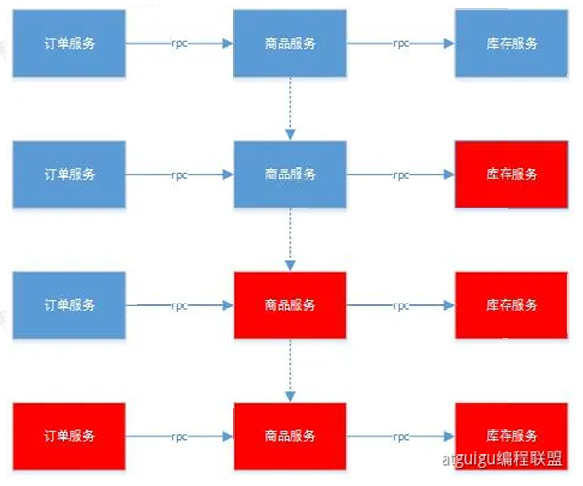
1.模块化升级问题–例如一个订单功能,我们经常需要升级,即V1.0,V2.0,V3.0,如果想要把新的订单版本部署到服务器就需要对整个项目重新打包,然后把所有服务器的这些项目全部下线,然后重新部署。也就是说模块化升级会导致牵一发而动全身
2.多语言团队问题–有一天我们在这个项目中引入了直播功能,直播功能需要流媒体相关技术,而Java语言在这方面不专长,要用C++来开发,因此直播功能的调用就不能像以前java项目那样搞一个jar包来掉它的方法,这涉及到了多语言团队如何分工协作的问题
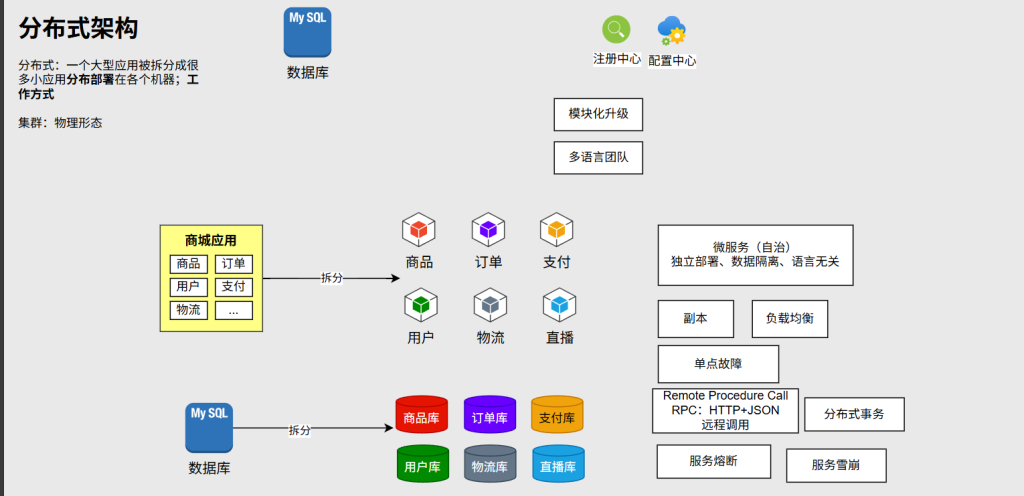
分布式架构
微服务:将项目应用拆分出来的每一个小应用称为微服务,每一个微服务可以独立部署
不仅应用可以拆分,数据库也可以,每一个微服务要做自己的业务只需要连接上对应的数据库即可,这样就做到了每一个微服务还能数据隔离,同时做到了每一个微服务是与语言无关的, 不同的小应用可以用不用的语言来开发。独立部署,数据隔离,语言无关 ,这便体现出微服务的自治(自己治理自己,自己管理自己)
分布式架构下每一个服务器不再部署完整的应用,而是部署应用拆分出来的每一个微服务
不推荐把所有的副本文件部署到同一个服务器中,容易出现单点故障 ,当这个服务器宕机,整个应用将无法提供完整的服务(鸡蛋不能放在一个篮子里)
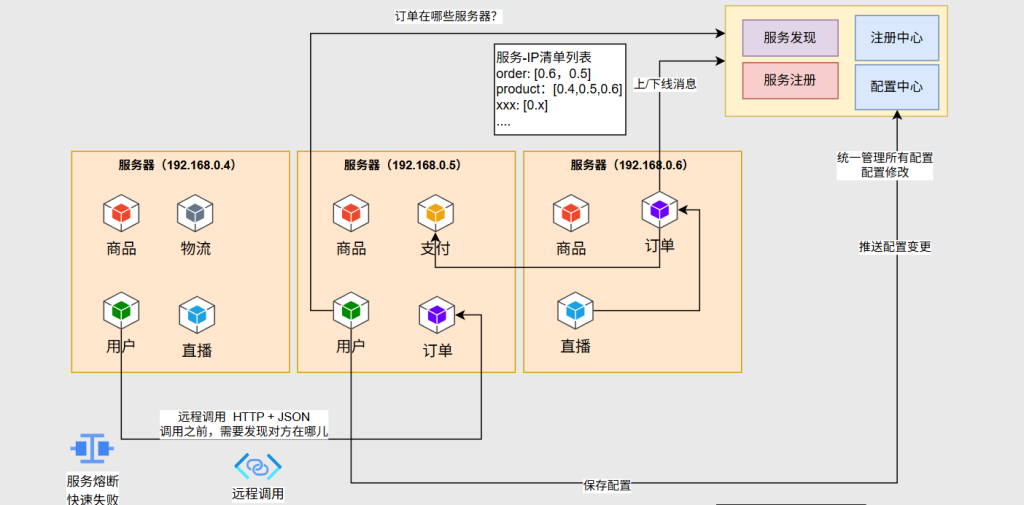
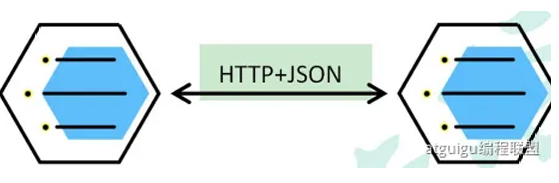
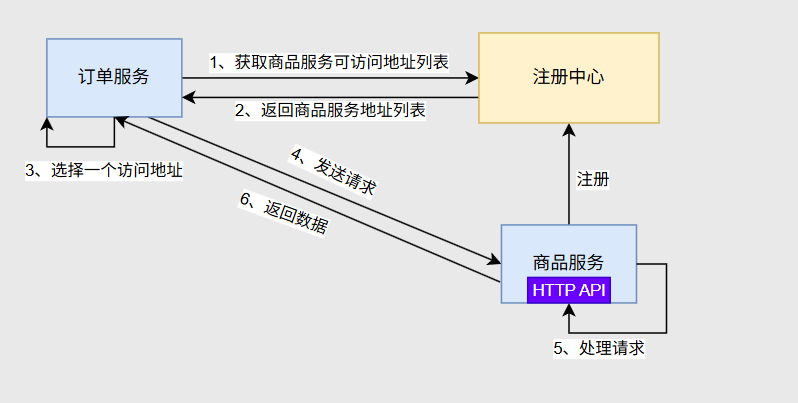
远程调用:如果用户需要调用订单请求,但由于它们不是在同一台服务器中,这时候用户需要发送一个HTTP请求,订单给用户返回JSON数据,即远程调用 (Remote Procedure Call 简称RPC),HTTP+JSON只是RPC的一种方式
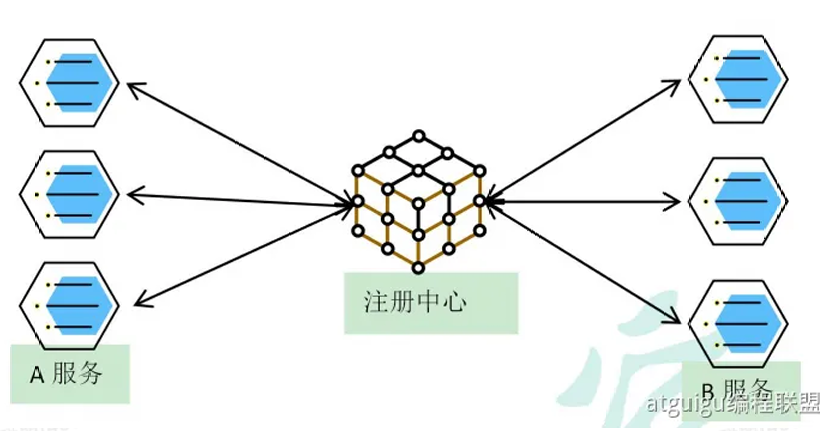
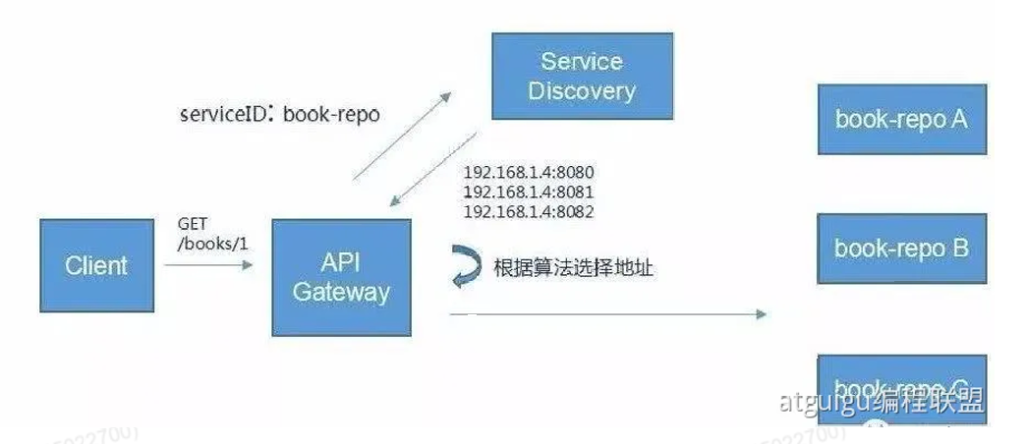
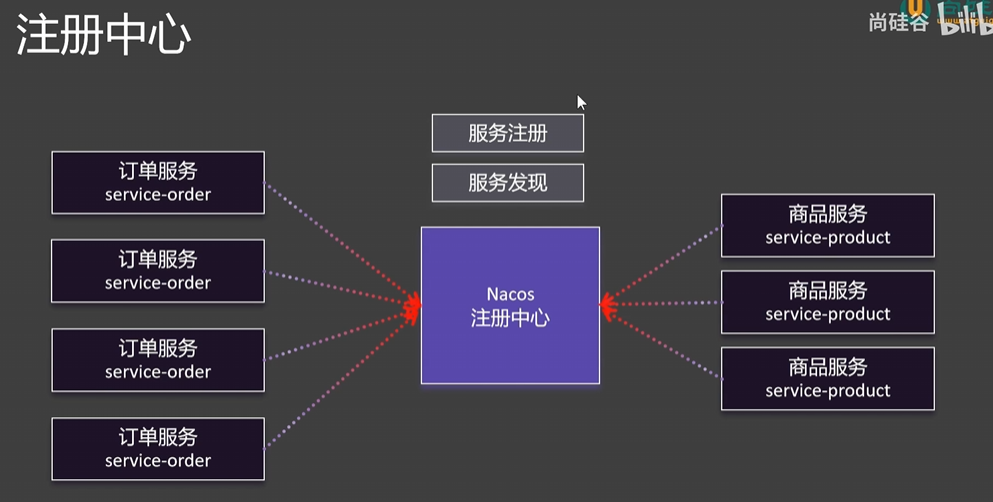
用户是如何知道0.6服务器里有订单业务,如果哪天0.6服务器宕机了,用户又如何知道0.5服务器也有订单业务并重连0.5服务器呢,这便要基于两个机制:服务发现与服务注册 ,这两个功能一般由一个组件叫注册中心 来提供
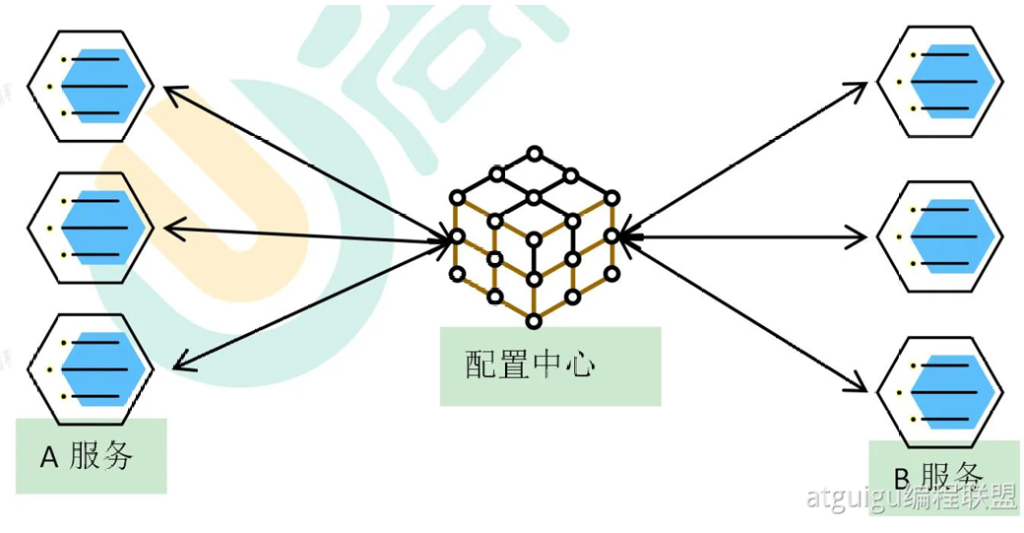
服务注册:如果某一个微服务部署到服务器上线了,它就会连上注册中心把自己的信息提供给注册中心(上下线消息)
服务发现:在远程调用之前,需要发现对方在哪,注册中心根据服务注册的清单给发起者返回信息告诉它对方在哪个服务器中
经过了服务发现后,发起者知道了需求的业务在哪些服务器中,就可以利用负载均衡的思想,把请求分摊给不同的服务器中
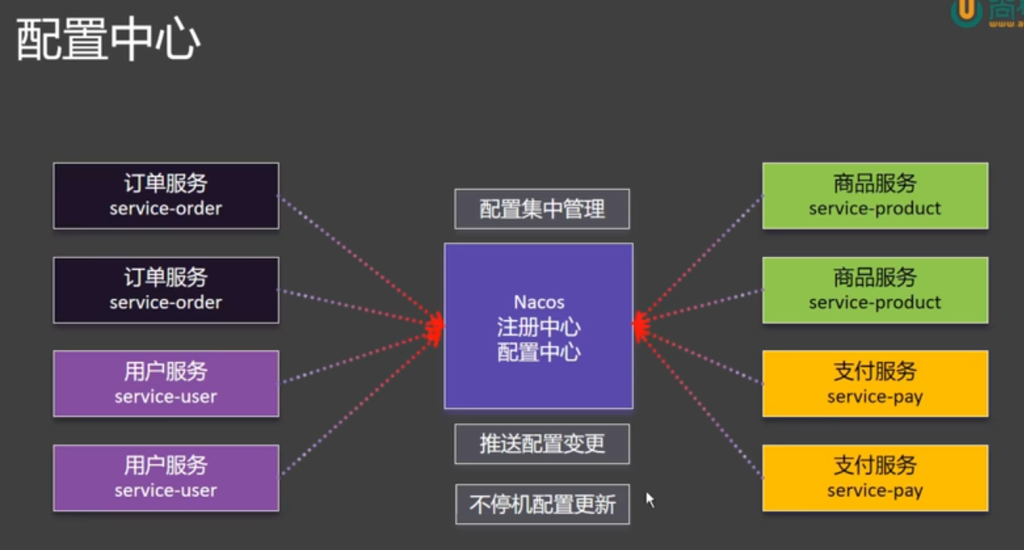
配置中心:一般的注册中心还有另一个功能,可以作为配置中心,我们希望每一个微服务可以将自己的配置保存到配置中心里边来,由配置中心统一管理这些配置,这样一来,改配置时,只需在配置中心里修改,修改后的配置由配置中心主动推送给指定的这个微服务(推送配置的变更)
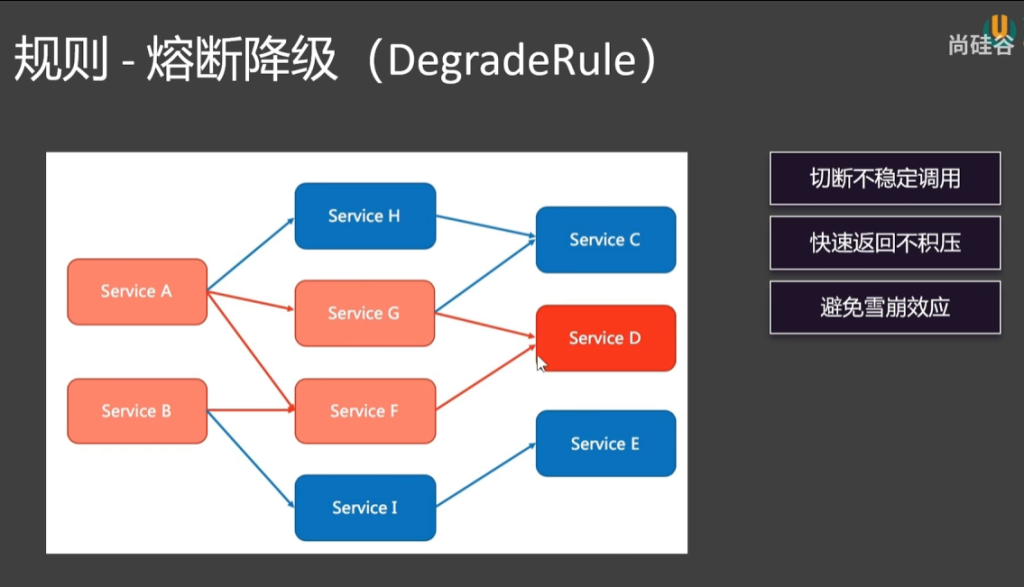
服务熔断:一个微服务的卡顿会导致整个调用链的卡顿,一个人的卡顿导致百万的并发请求全部积压到这个卡顿的服务器,请求量持续加大导致服务器资源耗尽,最终导致服务雪崩 ,要解决服务雪崩的问题就需要引入服务熔断
服务熔断是一种快速失败机制,快速失败及时释放掉这些资源,就不会导致服务器资源耗尽
理解一下什么是分布式?
答:一个大型应用被拆分成很多小应用分步部署在各个机器;每个服务器里边都跑一点小模块,最终形成了一个整体应用
区别一下分布式和集群的概念?
答:
分布式是把大应用拆分为小应用,分步部署在各个机器,各个机器上的小应用可能不同,分布式是一种工作方式/架构方式
集群:只要是一堆机器我们都可以叫集群,这一堆机器干的是同一件事,部署的是同一个应用,集群是一种物理形态
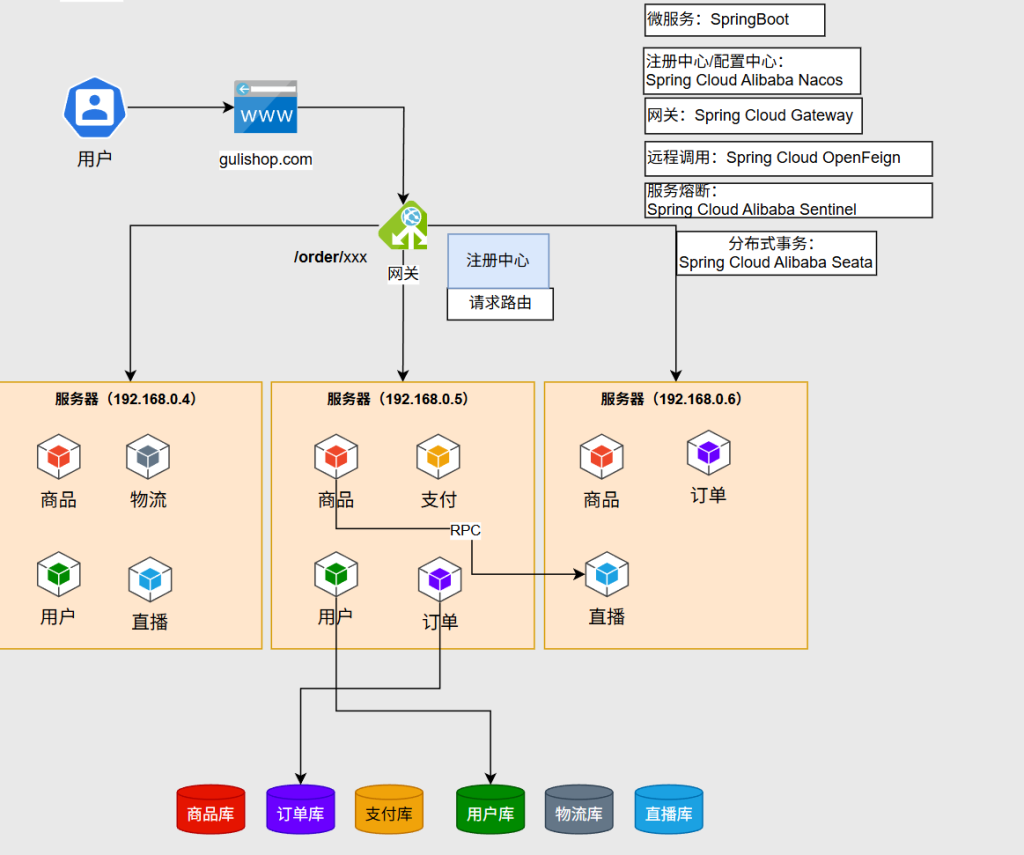
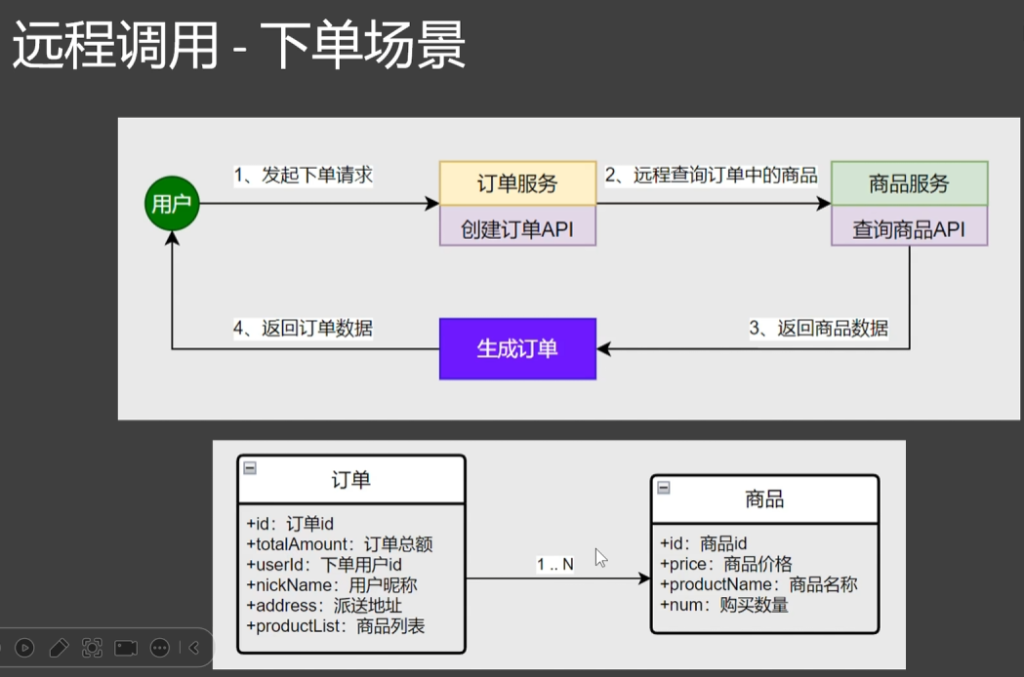
流程介绍:如果用户需要查询订单的业务,网关配置了一个规则查询/order开头的业务,网关就会把这个请求转给和订单所在的服务器,但网关自己不知道订单在哪些服务器,因此在请求之前网关会问注册中心订单在哪,知道在哪后才会把请求往下转,转下去的请求由微服务自行处理即可,处理期间要操作数据库,就连上自己的数据库去操作,但操作时可能出现一个问题:例如用户下单物品成功后会加积分,订单存在订单库,积分存在用户库,这两个操作涉及到了事务,只有下单成功了才加积分,但在分布式架构中牵扯到多个数据库,每一个数据库都可能在不同服务器,在分布式里还要解决一个常见的问题:分布式事务
总结:
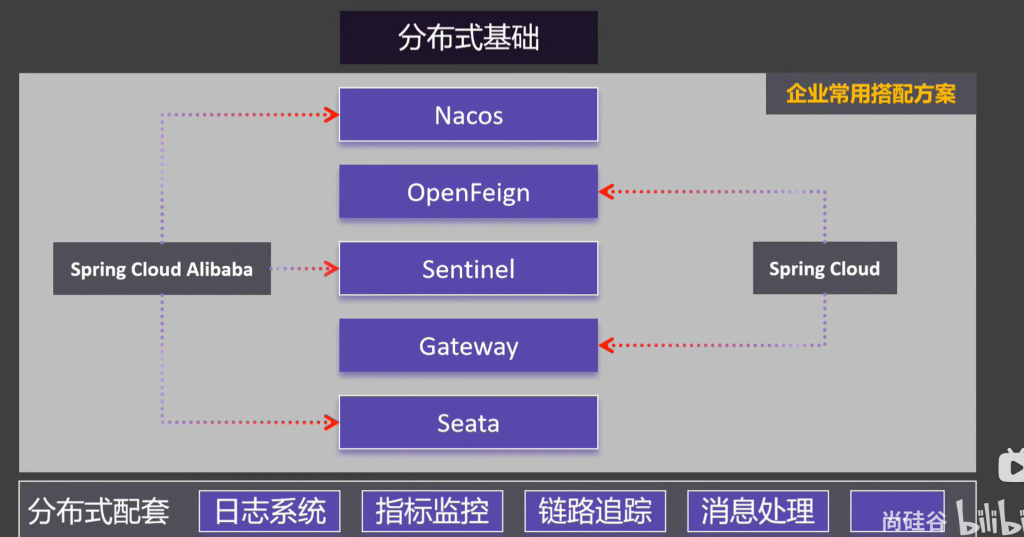
要做微服务可以用SpirngBoot快速创建出一个微服务,要做注册中心和配置中心,就用Spring Cloud Alibaba Nacos ,网关的实现用Spring Cloud Gateway,远程调用就要用到Spring Cloud OpenFeign这个组件,服务熔断就要用Spring Cloud Alibaba Sentinel,分布式事务就要用到Spring Cloud Alibaba Seata
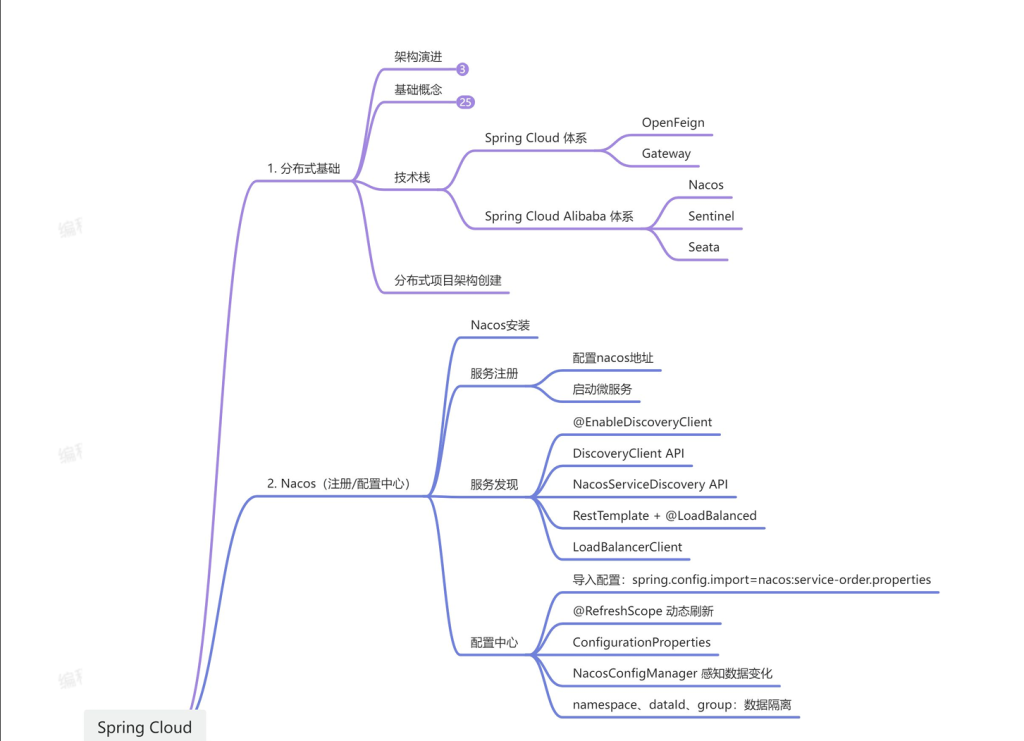
1.分布式基础
1.1微服务
微服务架构⻛格,就像是把⼀个单独的应⽤程序开发为⼀套⼩服务,每个⼩服务运⾏在⾃⼰的进程
1.2.集群&分布式&节点
集群是个物理形态,分布式是个⼯作⽅式。
《分布式系统原理与范型》定义:
“分布式系统是若⼲独⽴计算机的集合,这些计算机对于⽤户来说就像单个相关系统”
分布式系统(distributed system)是建⽴在⽹络之上的软件系统。
分布式是指将不同的业务分布在不同的地⽅。
集群指的是将⼏台服务器集中在⼀起,实现同⼀业务。
例如:京东是⼀个分布式系统,众多业务运⾏在不同的机器,所有业务构成⼀个⼤型的业务集群。
1.3远程调⽤
在分布式系统中,各个服务可能处于不同主机,但是服务之间不可避免的需要互相调⽤,我们称为远程调⽤。 SpringCloud 中使⽤ HTTP+JSON 的⽅式完成远程调⽤
1.4.负载均衡
介绍:分布式系统中,A 服务需要调⽤ B 服务,B 服务在多台机器中都存在,A 调⽤任意⼀个服务器均可完成功能。 为了使每⼀个服务器都不要太忙或者太闲,我们可以负载均衡的调⽤每⼀个服务器,提升⽹站的健壮性。
常⻅的负载均衡算法:
轮询:为第⼀个请求选择健康池中的第⼀个后端服务器,然后按顺序往后依次选择,直到最后
最⼩连接:优先选择连接数最少,也就是压⼒最⼩的后端服务器,在会话较⻓的情况下可以考
散列:根据请求源的 IP 的散列(hash)来选择要转发的服务器。这种⽅式可以⼀定程度上保
1.5服务注册/发现&注册中⼼
A 服务调⽤ B 服务,A 服务并不知道 B 服务当前在哪⼏台服务器有,哪些正常的,哪些服务已经
如果某些服务下线,我们其他⼈可以实时的感知到其他服务的状态,从⽽避免调⽤不可⽤的服务
1.6配置中⼼
每⼀个服务最终都有⼤量的配置,并且每个服务都可能部署在多台机器上。我们经常需要变更配
1.7服务熔断&服务降级
在微服务架构中,微服务之间通过⽹络进⾏通信,存在相互依赖,当其中⼀个服务不可⽤时,有可能会造成雪崩效应 。要防⽌这样的情况,必须要有容错机制来保护服务
1)、服务熔断
1.8API ⽹关
在微服务架构中,API Gateway 作为整体架构的重要组件,它抽象了微服务中都需要的公共功能,同时提供了客户端负载均衡,服务⾃动熔断,灰度发布,统⼀认证,限流流控,⽇志统计等丰富的功能,帮助我们解决很多 API 管理难题。
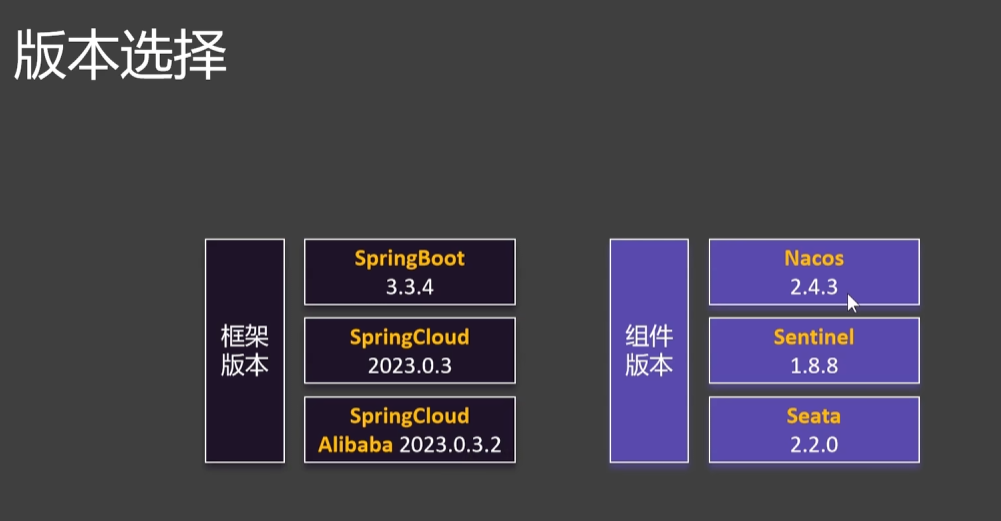
2.创建一个Spring Cloud项目
本次课程选择:
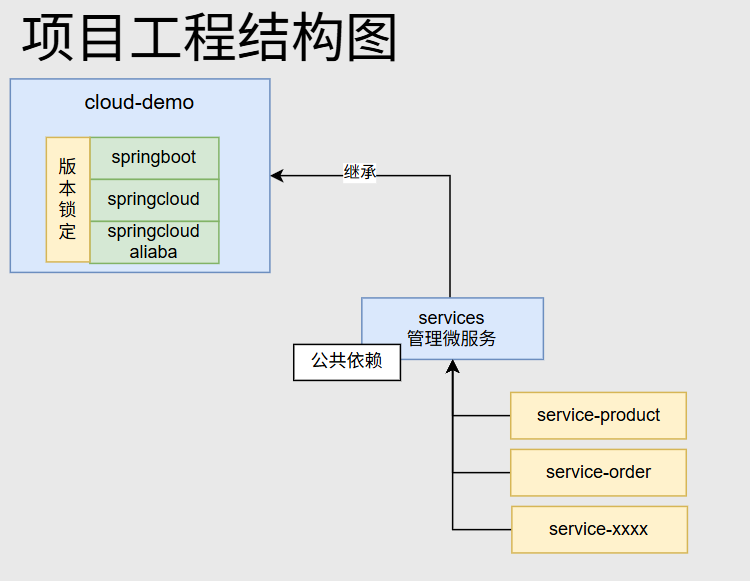
项目结构如图:
idea结构如下:
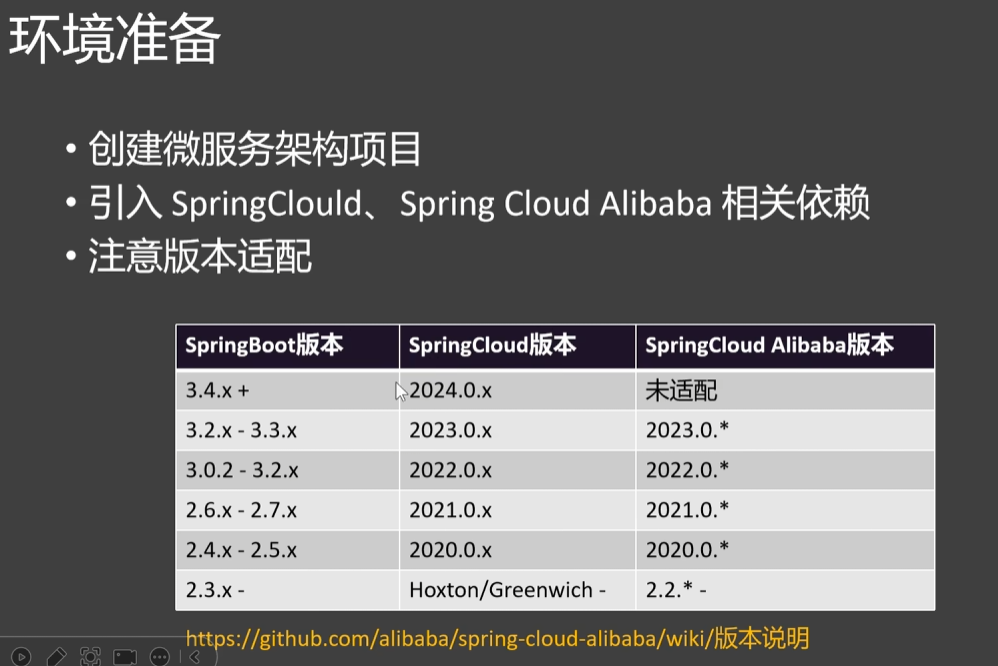
创建⽗项⽬引⼊公共依赖(cloud-demo下的pom)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 3.3.4</version > <relativePath /> </parent > <packaging > pom</packaging > <modules > <module > services</module > </modules > <groupId > com.geqian</groupId > <artifactId > cloud-demo</artifactId > <version > 0.0.1-SNAPSHOT</version > <name > cloud-demo</name > <description > cloud-demo</description > <properties > <maven.compiler.source > 17</maven.compiler.source > <maven.compiler.target > 17</maven.compiler.target > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <spring-cloud.version > 2023.0.3</spring-cloud.version > <spring-cloud-alibaba.version > 2023.0.3.2</spring-cloud-alibaba.version > </properties > <dependencyManagement > <dependencies > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-dependencies</artifactId > <version > $ {spring-cloud.version} </version > <type > pom</type > <scope > import</scope > </dependency > <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-alibaba-dependencies</artifactId > <version > $ {spring-cloud-alibaba.version} </version > <type > pom</type > <scope > import</scope > </dependency > </dependencies > </dependencyManagement > <build > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > </plugin > </plugins > </build > </project >
在service文件夹下的pom导入公共依赖测试
1 2 3 4 5 6 7 8 9 10 11 12 <dependencies > <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-discovery</artifactId > </dependency > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-openfeign</artifactId > </dependency > </dependencies >
公共依赖成功被子包继承
3.Nacos-注册中心&配置中心
3.1注册中心基础入门
3.1.1安装
官⽹:https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html
Docker 安装
1 2 docker run -d -p 8848 :8848 -p 9848 :9848 -e MODE=standalone --name nacos nacos /nacos-server:v2.4 .3
下载软件包:
nacos-server-2.4.3.zip
启动命令:startup.cmd -m standalone
访问:http://localhost:8848/nacos 可以看到服务已经注册上来;
3.1.2服务注册
在微服务项目中引入依赖:(这里以service-order为例,其他的微服务操作一样)
1 2 3 4 5 6 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > </dependencies >
nacos依赖在service.pom已经引入
在application.properties中配置如下
1 2 3 4 spring.application.name =service-orderserver.port =8000 spring.cloud.nacos.server-addr =127.0 .0.1 :8848
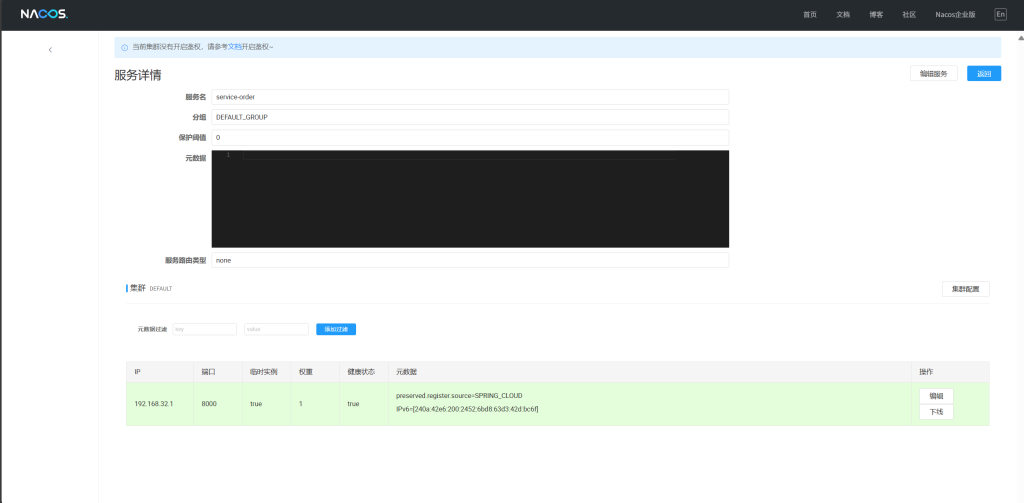
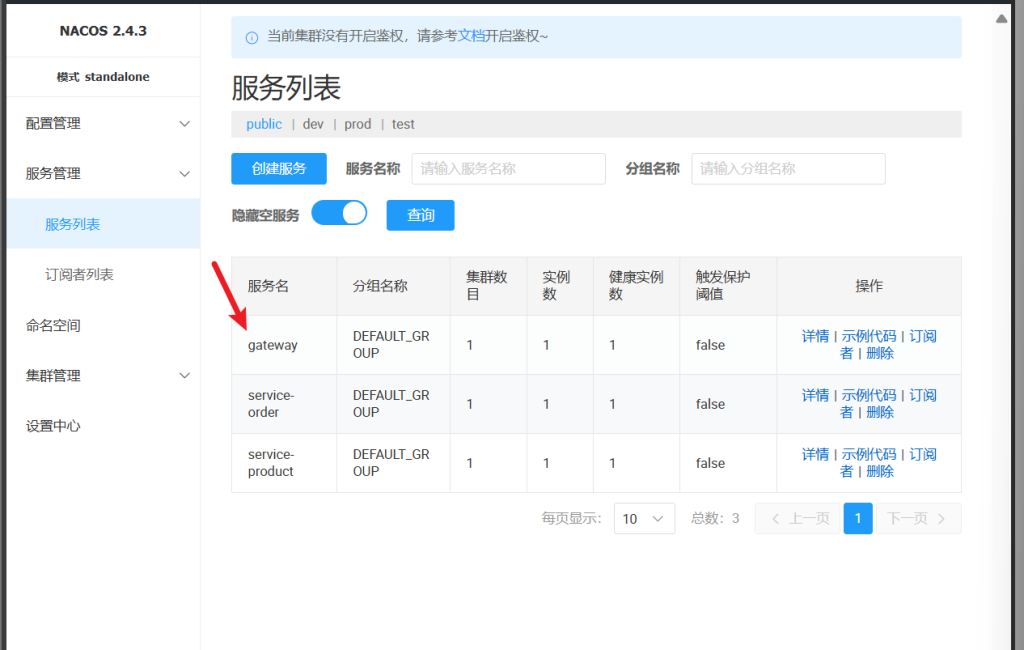
启动主启动类,进入nacos中发现这个service-order已经注册上来了,我们可以点进去看看
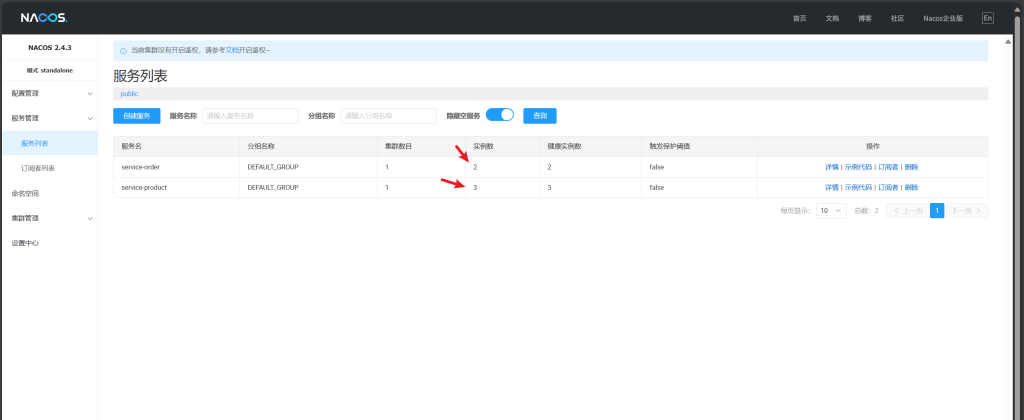
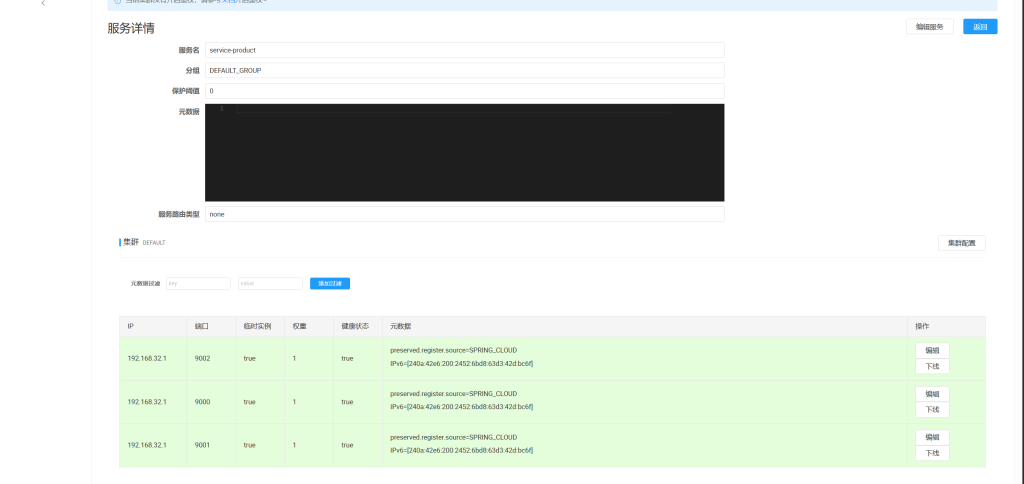
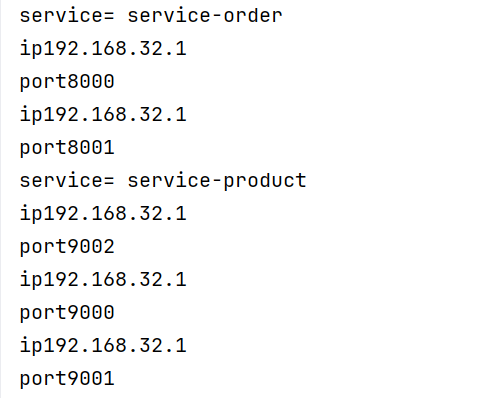
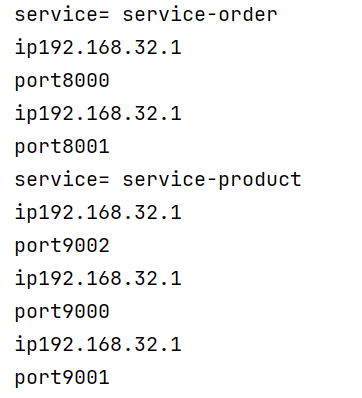
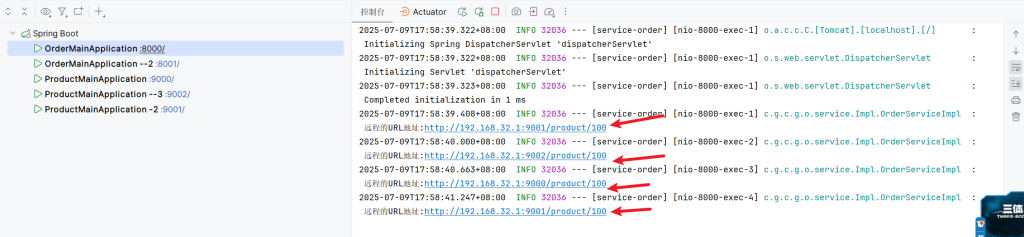
模拟集群为order复制1份,product复制2份再全部启动
进入nacos可以看到实例数
3.1.3服务发现
以商品服务为例
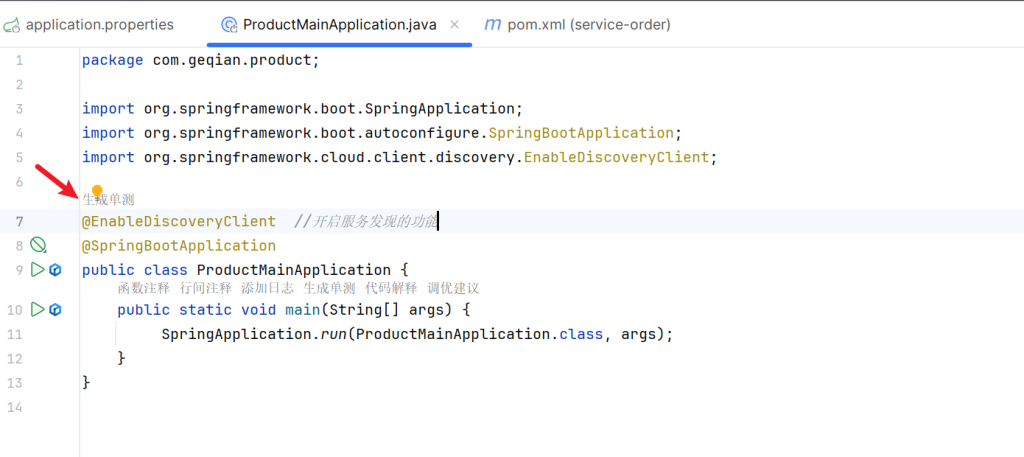
1.添加@EnableDiscoveryClient注解
2.测试DiscoveryClient
3.测试NacosServiceDiscovery
DiscoveryClient和NacosServiceDiscovery区别
一个是Spring官方提供的一个是Nacos自己提供的
3.1.4远程调⽤
远程调用-基本流程
创建对应的controller,bean,service及其实现类
1.order中
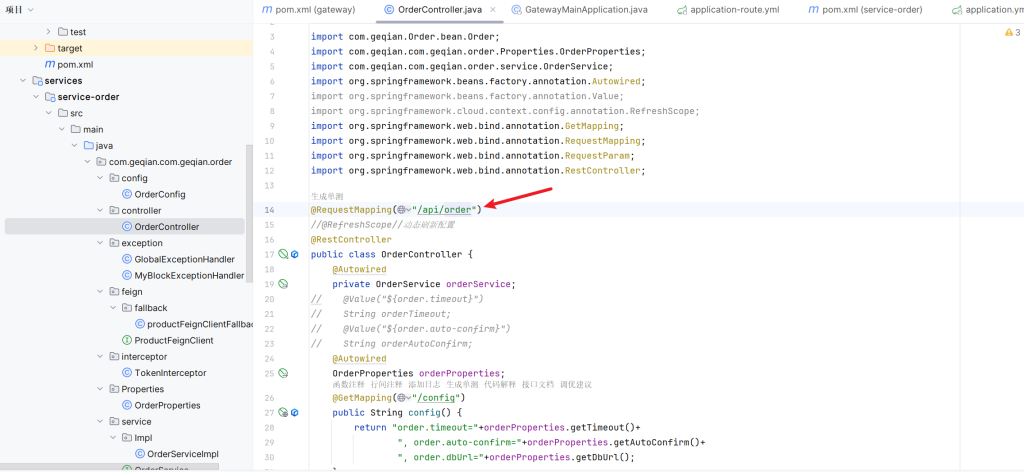
OrderController
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.geqian.com.geqian.order.controller;import com.geqian.com.geqian.order.bean.Order;import com.geqian.com.geqian.order.service.OrderService;import org.springframework.beans.factory.annotation .Autowired;import org.springframework.web.bind.annotation .GetMapping;import org.springframework.web.bind.annotation .RequestParam;import org.springframework.web.bind.annotation .RestController;@RestController public class OrderController { @Autowired private OrderService orderService; @GetMapping("/create" ) public Order createOrder(@RequestParam("userId" ) Long userId, @RequestParam("productId" ) Long productId) { Order order = orderService.createOrder(productId, userId); return order; } }
Order实体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.geqian.com.geqian.order.bean;import lombok.Data;import java.math.BigDecimal;import java.util.List;import java.util.Objects;@Data public class Order { private Long id; private BigDecimal totalAmount; private Long userId; private String nickName; private String address; private List<Object>productList; }
OrderService
1 2 3 4 5 6 7 package com.geqian.com.geqian.order.service;import com.geqian.com.geqian.order.bean.Order;public interface OrderService { Order createOrder(Long productId, Long userId); }
及其实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.geqian.com.geqian.order.service.Impl;import com.geqian.Order.bean.Order;import com.geqian.Product.bean.Product;import com.geqian.com.geqian.order.service.OrderService;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.cloud.client.ServiceInstance;import org.springframework.cloud.client.discovery.DiscoveryClient;import org.springframework.stereotype.Service;import org.springframework.web.client.RestTemplate;import java.math.BigDecimal;import java.util.Arrays;import java.util.List;@Slf4j @Service public class OrderServiceImpl implements OrderService { @Autowired DiscoveryClient discoveryClient; RestTemplate restTemplate; @Override public Order createOrder (Long productId, Long userId) { Product product = getProductFromRemote(productId); Order order = new Order (); order.setId(1L ); order.setTotalAmount( product.getPrice().multiply(new BigDecimal (product.getNum()))); order.setUserId(userId); order.setNickName("zhangsan" ); order.setAddress("beijing" ); order.setProductList(Arrays.asList(product)); return order; } private Product getProductFromRemote (Long productId) { List<ServiceInstance> instances = discoveryClient.getInstances("service-product" ); ServiceInstance instance = instances.get(0 ); String url = "http://" +instance.getHost() + ":" + instance.getPort()+"/product/" +productId; log.info("远程的URL地址:{}" ,url); Product product = restTemplate.getForObject(url, Product.class); return product; } }
2.Product中
ProductController
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.geqian.product.controller;import com.geqian.product.bean.Product;import com.geqian.product.service.ProductService;import org.springframework.beans.factory.annotation .Autowired;import org.springframework.web.bind.annotation .GetMapping;import org.springframework.web.bind.annotation .PathVariable;import org.springframework.web.bind.annotation .RestController;@RestController public class ProductController { @Autowired private ProductService productService; @GetMapping("/product/{id}" ) public Product getProduct(@PathVariable("id" ) Long productId) { Product product = productService.getProductById(productId); return product; } }
Product实体
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.geqian.product .bean; import lombok.Data ;import java.math.BigDecimal;@Data public class Product { private Long id; private String productName; private BigDecimal price; private int num; }
ProductService
1 2 3 4 5 6 7 package com.geqian.product .service; import com.geqian.product .bean.Product ;public interface ProductService { Product getProductById(Long productId); }
及其实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.geqian.product.service.impl;import com.geqian.Product.bean.Product;import com.geqian.product.service.ProductService;import org.springframework.stereotype.Service;import java.math.BigDecimal;@Service public class ProductServiceImpl implements ProductService { @Override public Product getProductById (Long productId) { Product product = new Product (); product.setId(productId); product.setPrice(new BigDecimal ("6999.00" )); product.setProductName("苹果" +productId); product.setNum(2 ); return product; } }
新建model模块存放order和product的bean,之后再service下的pom中导入lombok确保model包下的bean中@Data注解能生效
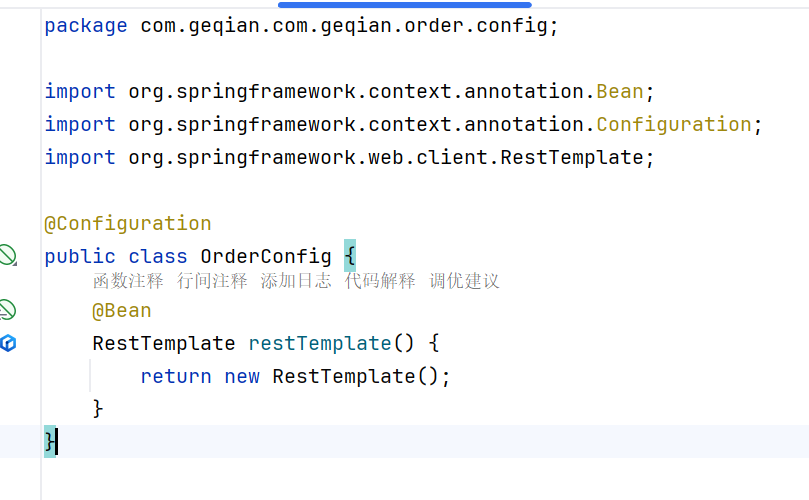
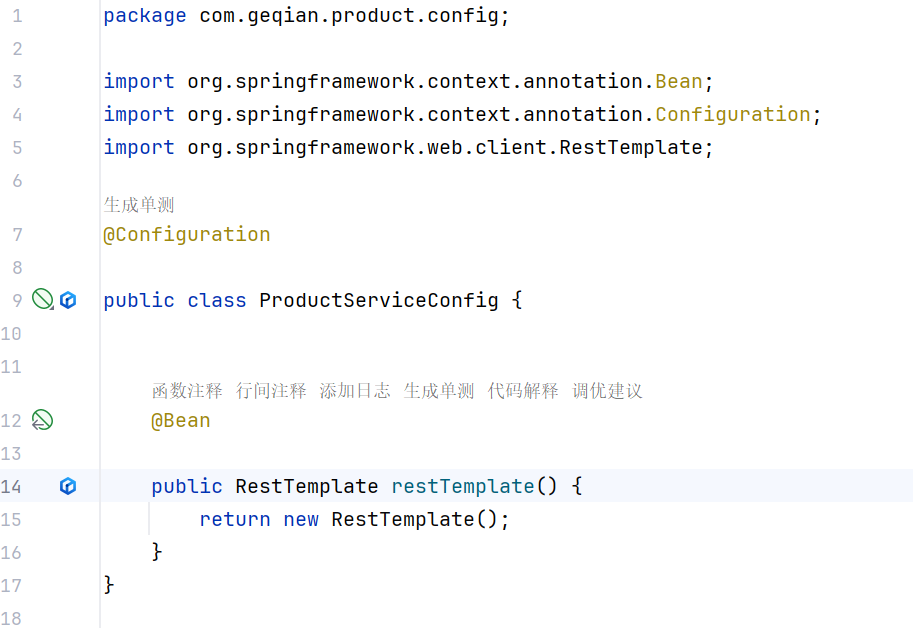
首先要注入
在order和product下分别建config包,里面写相关的配置项,这里我们把RestTemplate写在里面,方便远程调用不用再new一个新的
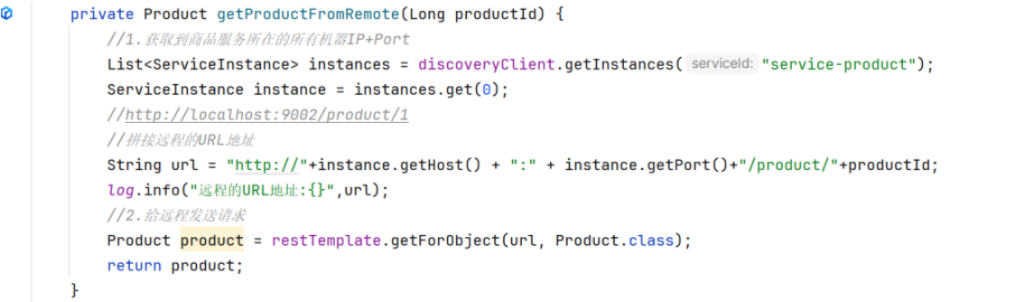
看看远程调用的方法
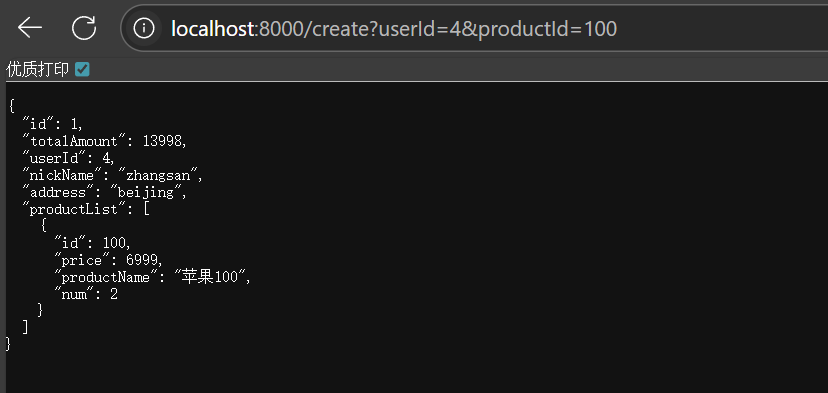
测试
再看8000端口的控制台
⼩结
使⽤ RestTemplate 可以获取到远程数据
必须精确指定地址和端⼝
如果远程宕机将不可⽤
期望:可以负载均衡调⽤,不⽤担⼼远程宕机
3.1.5负载均衡需求
1.依赖导⼊到order下的pom
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-loadbalancer</artifactId > </dependency >
2.编写一个测试类
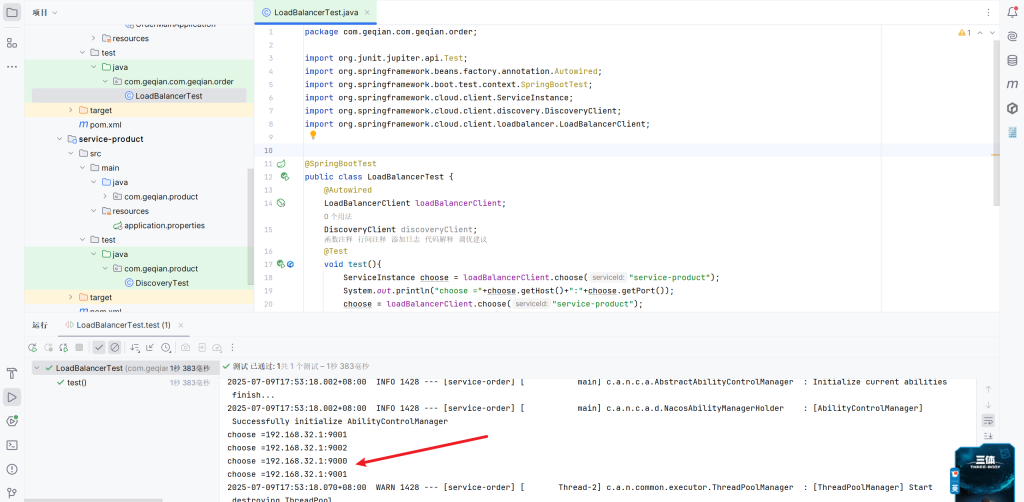
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.geqian.com.geqian.order;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation .Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.cloud.client.ServiceInstance;import org.springframework.cloud.client.discovery.DiscoveryClient;import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;@SpringBootTest public class LoadBalancerTest { @Autowired LoadBalancerClient loadBalancerClient; DiscoveryClient discoveryClient; @Test void test(){ ServiceInstance choose = loadBalancerClient.choose("service-product" ); System.out .println("choose =" +choose.getHost()+":" +choose.getPort()); choose = loadBalancerClient.choose("service-product" ); System.out .println("choose =" +choose.getHost()+":" +choose.getPort()); choose = loadBalancerClient.choose("service-product" ); System.out .println("choose =" +choose.getHost()+":" +choose.getPort()); choose = loadBalancerClient.choose("service-product" ); System.out .println("choose =" +choose.getHost()+":" +choose.getPort()); } }
3.LoadBalancerClient
1 2 3 4 5 6 7 8 9 10 11 private Product getProductFromRemoteWithLoadBalancer(Long productId) { ServiceInstance choose = loadBalancerClient.choose ("service-product" ); String url = "http://" +choose .getHost() + ":" + choose .getPort()+"/product/" +productId; log .info("远程的URL地址:{}" ,url); Product product = restTemplate.getForObject(url, Product.class); return product; }
测试localhost:8000/create?userId=4&productId=100 多刷新几次
去控制台查看,发现每一次远程的URL地址都有变化,即负载均衡
4.注解方式负载均衡
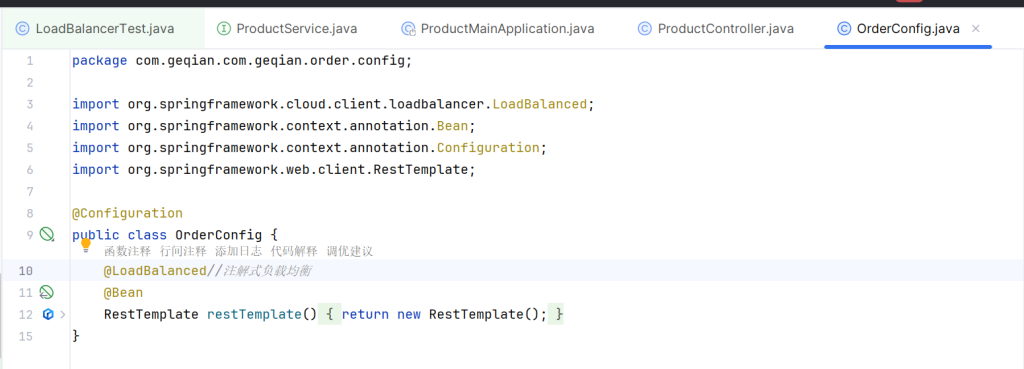
Spring自带一个注解 @LoadBalanced,只要把它标在配置类上就会自动负载均衡
1 2 3 4 5 6 7 8 9 //进阶3 基于注解的负载均衡 private Product getProductFromRemoteWithLoadBalancerAnnotation(Long productId) { String url = "http://service-product/product/" +productId; log .info("远程的URL地址:{}" ,url); //2. 给远程发送请求 service-product 会被动态替换为真实的IP+Port Product product = restTemplate.getForObject(url, Product .class ); return product ; }
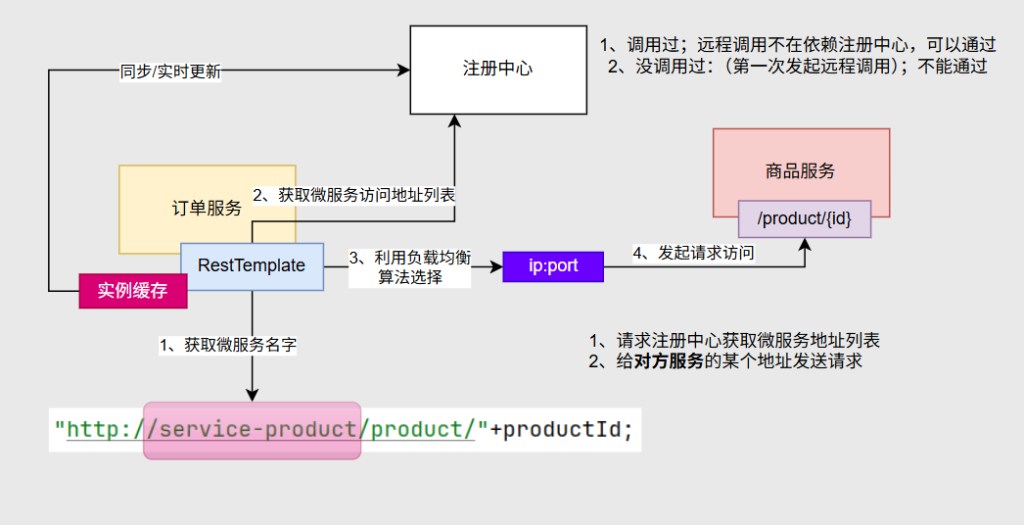
3.1.6面试题:如果注册中心宕机,远程调用还能使用吗?
先看看远程调用的流程
当第一次发请求时需要依赖注册中心,并把信息保存到实例缓存中,当下一次调用时不再依赖注册中心从实例缓存中拿,注册中心的数据会实时同步到实例缓存
因此如果注册中心宕机,远程调用还能使用吗?
分两种情况:1.以前调用:此时有了实例缓存,就算注册中心宕机了,它只影响了同步更新的作用,但是以前的这些IP地址和端口号大概率依然能访问。即调用过的情况下,远程调用不再依赖注册中心
2.以前没有调用:第一次发起远程调用,就必须去注册中心要到微服务的地址列表,就不能通过
3.2配置中心基础入门
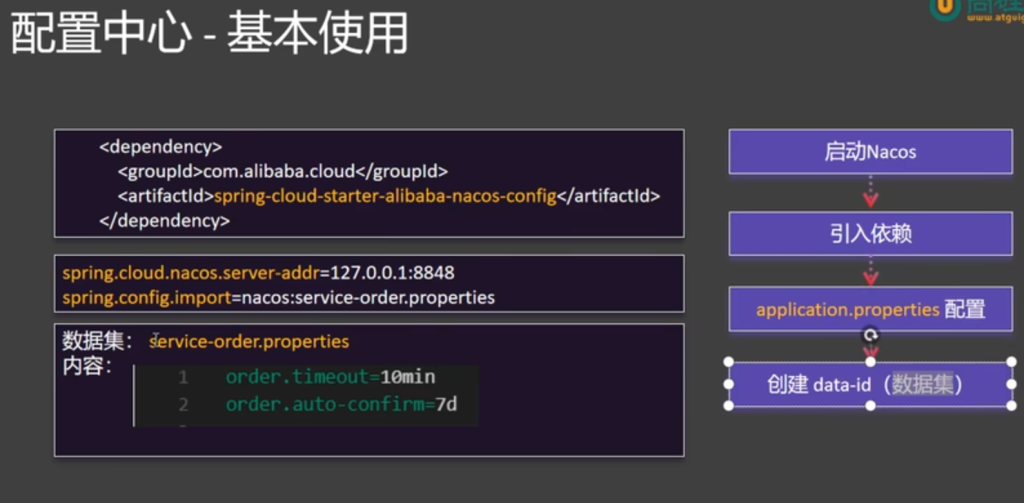
3.2.1基础配置
1.引入依赖(service的pom下)
1 2 3 4 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-config</artifactId > </dependency >
2.配置⽂件
application.properties
1 2 3 spring.cloud.nacos.server-addr =localhost:8848 spring.config.import =nacos:service-order.properties
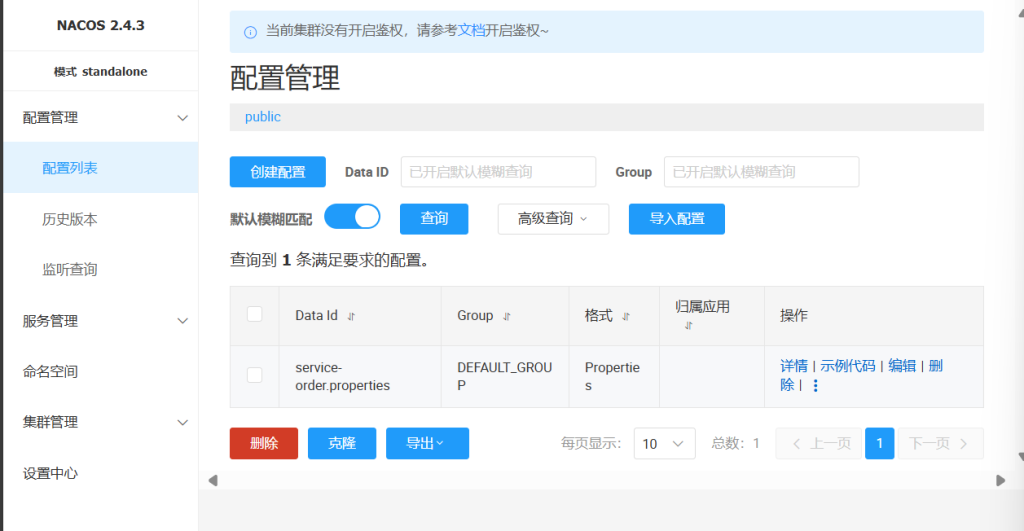
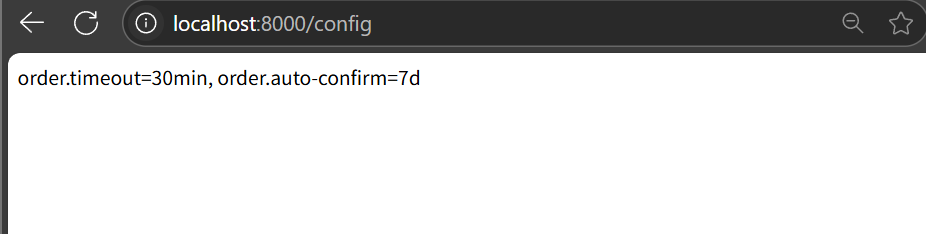
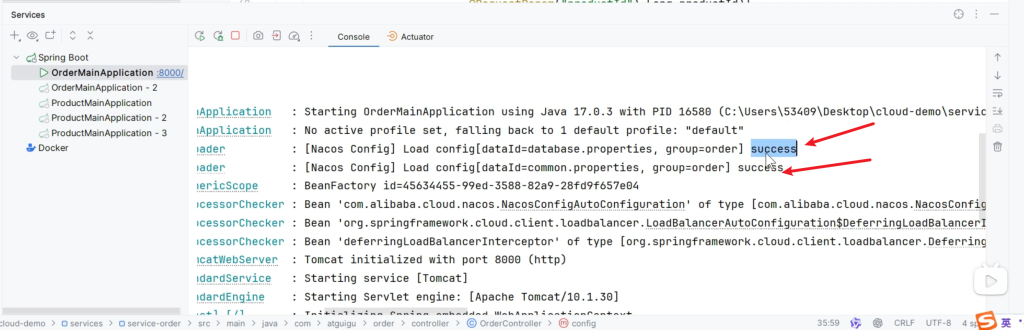
在ordercontroller中测试一下这两个配置是否被加载
成功从配置中心拿到数据
3.2.2动态刷新
@RefreshScope
当我们在配置中心改变这两个配置刷新页面发现,页面的数据并没有改变,这是因为我们缺少了一个激活动态刷新的注解,加上这个注解就可以了
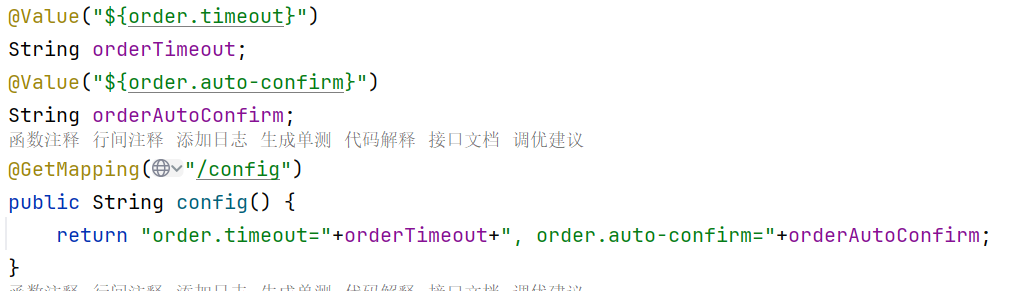
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @RefreshScope @RestController public class OrderController { @Autowired private OrderService orderService; @Value("${order.timeout} " ) String orderTimeout; @Value("${order.auto-confirm} " ) String orderAutoConfirm; @GetMapping("/config" ) public String config() { return "order.timeout=" +orderTimeout+", order.auto-confirm=" +orderAutoConfirm; } @GetMapping("/create" ) public Order createOrder(@RequestParam("userId" ) Long userId, @RequestParam("productId" ) Long productId) { Order order = orderService.createOrder(productId, userId); return order; } }
注:如果nacos配置中心作为公共依赖导入但目前用不上,需要在application.properties中加入
1 2 spring.cloud.nacos.config.import-check.enabled =false
否则项目将无法启动
@ConfigurationProperties(推荐)
nacos兼容springboot中的动态更新
把属性提取到properties包下的OrderProperties中
1 2 3 4 5 6 7 8 @Component @ConfigurationProperties (prefix = "order" ) @Data public class OrderProperties { String timeout ; String autoConfirm ; }
改造ordercontroller原本的方法
1 2 3 4 5 6 7 8 9 10 @Autowired OrderProperties orderProperties; @GetMapping ("/config" ) public String config ( return "order.timeout=" +orderProperties.getTimeout ()+", order.auto-confirm=" +orderProperties.getAutoConfirm (); }
@NacosConfigManager监听配置变化
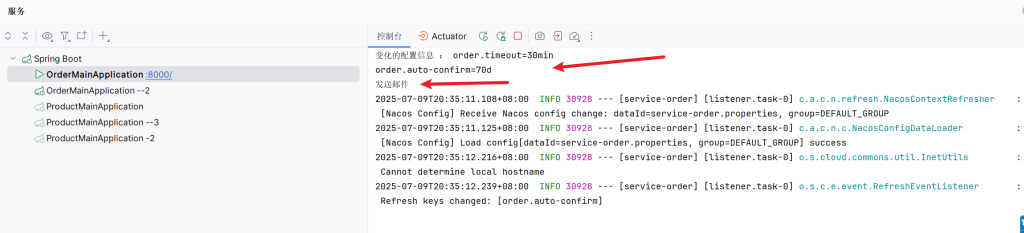
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Bean ApplicationRunner applicationRunner (NacosConfigManager nacosConfigManager return args -> { ConfigService configService = nacosConfigManager.getConfigService (); configService.addListener ("service-order.properties" , "DEFAULT_GROUP" , new Listener () { @Override public Executor getExecutor ( return Executors .newFixedThreadPool (4 ); } @Override public void receiveConfigInfo (String configInfo System .out .println ("变化的配置信息 : " + configInfo); System .out .println ("发送邮件" ); } } ); System .out .println ("=======================" ); }; } }
测试:
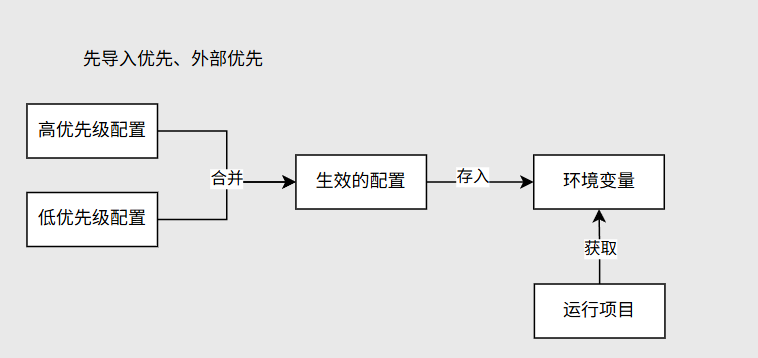
3.2.3面试题:Nacos中的数据集和application.properties有相同的配置项,哪个生效?
答:是以配置中心为准(先导入/先声明优先、外部优先)
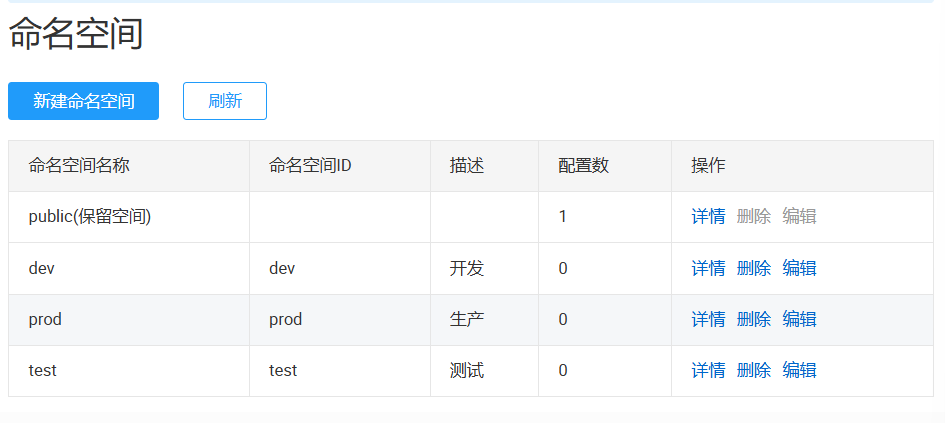
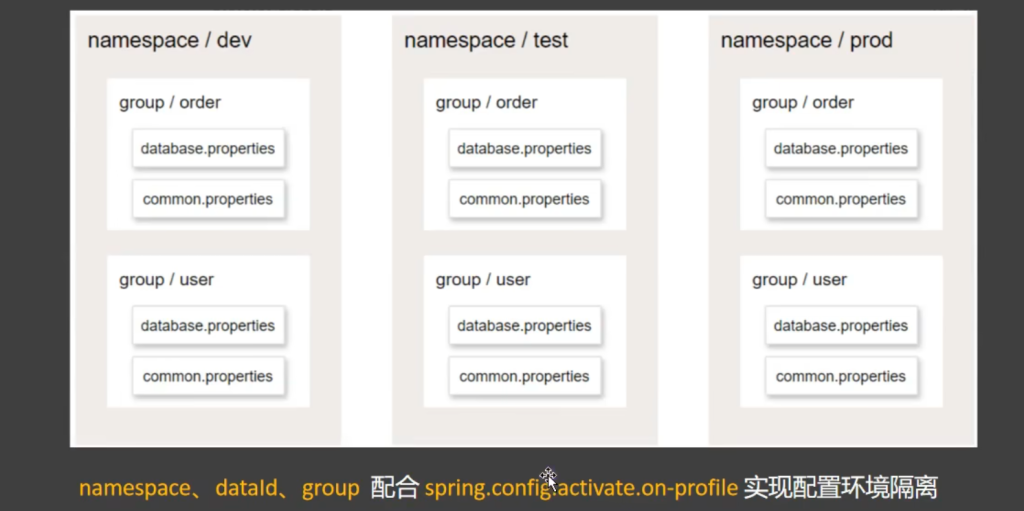
3.2.4数据隔离
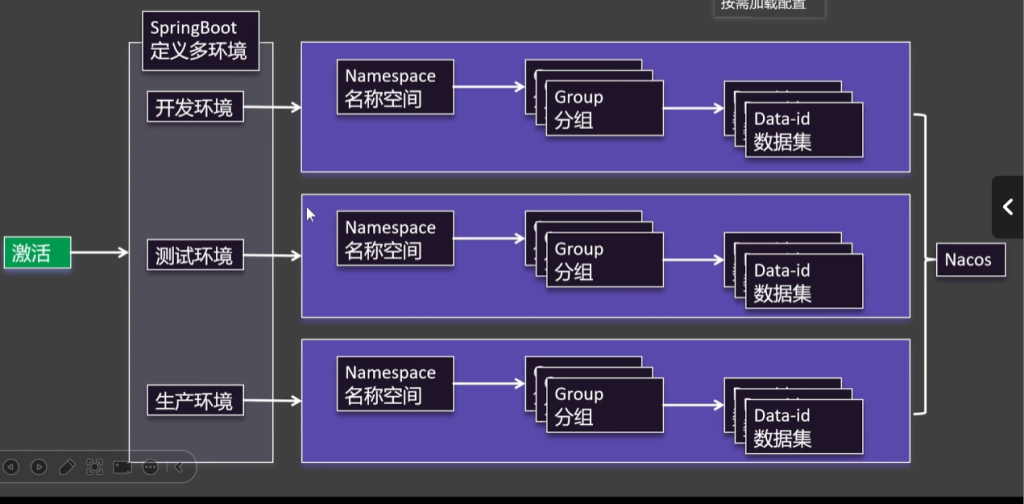
开发环境绑定开发的名称空间,测试环境绑定测试的名称空间,生产环境绑定生产的名称空间,想要让它们生效只需在项目启动时激活某一个环境
总结:用名称空间区分多套环境,用分组区分多种微服务,用数据集区分多种配置,用SpringBoot激活指定环境,激活这套配置
名称空间
groupId
按需加载
创建一个新的application.yml文件把新配置放在这里面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 server : port : 8000 spring : application : name : service-order cloud : nacos : server-addr : 127.0.0.1:8848 config : namespace : dev//在这里切换环境 config : import : - nacos:common.properties?group=order - nacos:database.properties?group=order
改造yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 server: port: 8000 spring: profiles: active: dev//在这里更改激活什么环境 application: name: service-order cloud: nacos: server-addr: 127.0 .0 .1 :8848 config: namespace: ${spring.profiles.active:public} --- spring: config: import: - nacos:common.properties?group=order - nacos:database.properties?group=order activate: on-profile: dev --- spring: config: import: - nacos:common.properties?group=order - nacos:database.properties?group=order - nacos:redis.properties?group=order activate: on-profile: test --- spring: config: import: - nacos:common.properties?group=order - nacos:database.properties?group=order - nacos:redis.properties?group=order activate: on-profile: prod
3.3Nacos总结
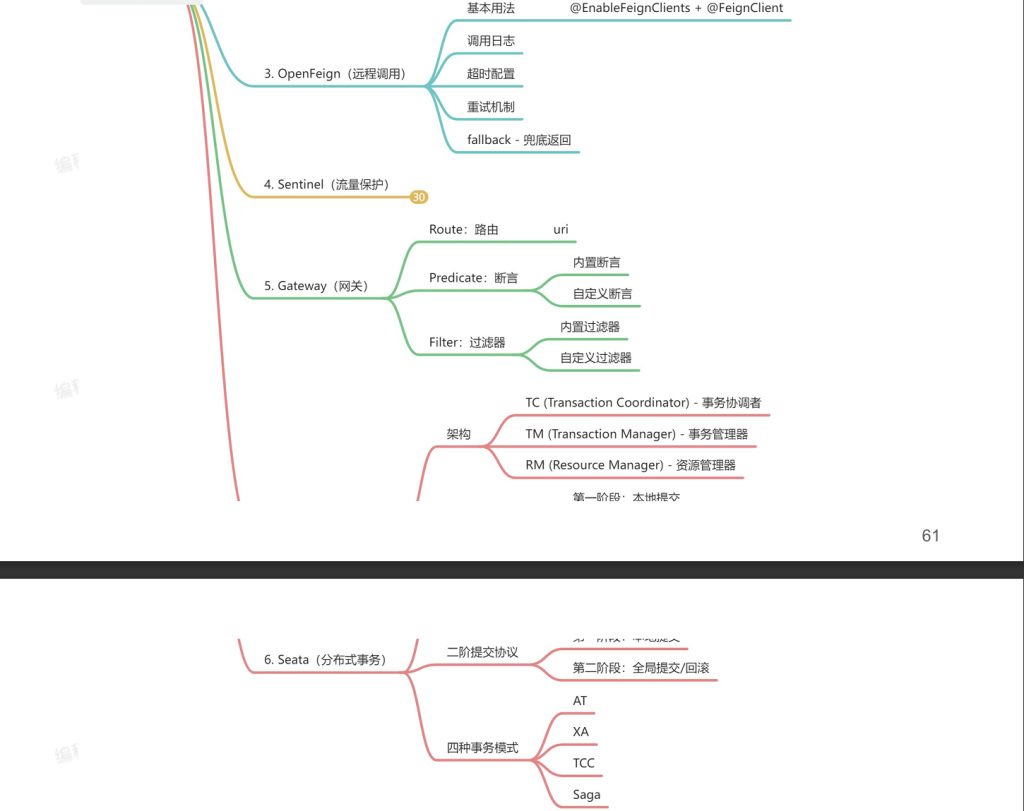
4.OpenFeign-远程调用
4.1基础入门
官网:Spring Cloud OpenFeign Features :: Spring Cloud Openfeign
介绍:OpenFeign 是⼀个声明式 远程调⽤客户端;
声明式对比编程式的好处就是用注解代替代码
4.1.1引入依赖
在service包下引入公共依赖
1 2 3 4 5 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-openfeign</artifactId > </dependency >
4.1.2开启OpenFeign远程调用功能
1 2 3 4 5 6 7 @EnableFeignClients @EnableDiscoveryClient @SpringBootApplication public class OrderMainApplication { public static void main (String[] args) { SpringApplication .run (OrderMainApplication.class, args); }
4.1.3远程调用(这个远程调用是自动负载均衡的)
编写ProductFeignClient接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.geqian.com.geqian.order.feign;import com.geqian.Product.bean.Product;import org.springframework.cloud.openfeign.FeignClient;import org.springframework.web.bind.annotation .GetMapping;import org.springframework.web.bind.annotation .PathVariable;@FeignClient(value = "server-product" ) public interface ProductFeignClient { @GetMapping("/product/{id}" ) Product getProductById(@PathVariable("id" ) Long id); }
在OrderServiceImpl中注入并调用
1 2 3 4 @Autowired ProductFeignClient productFeignClient; Product product = productFeignClient.getProductById(productId);
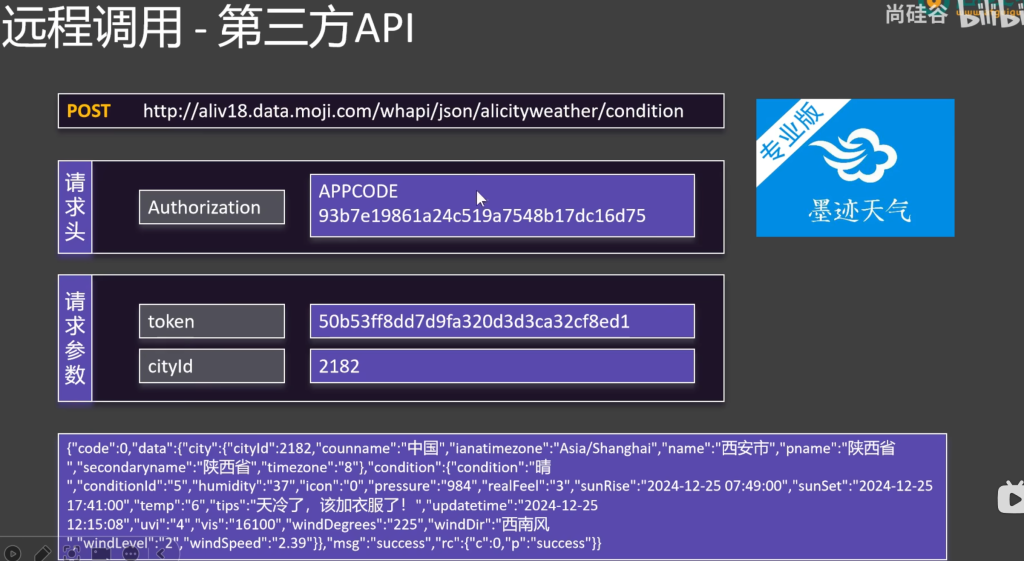
4.1.4远程调用第三方API
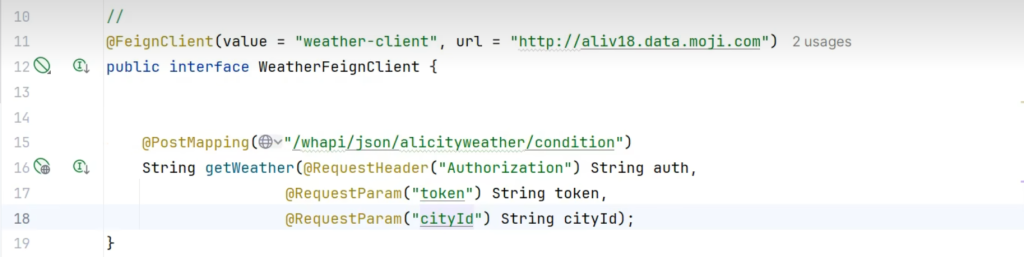
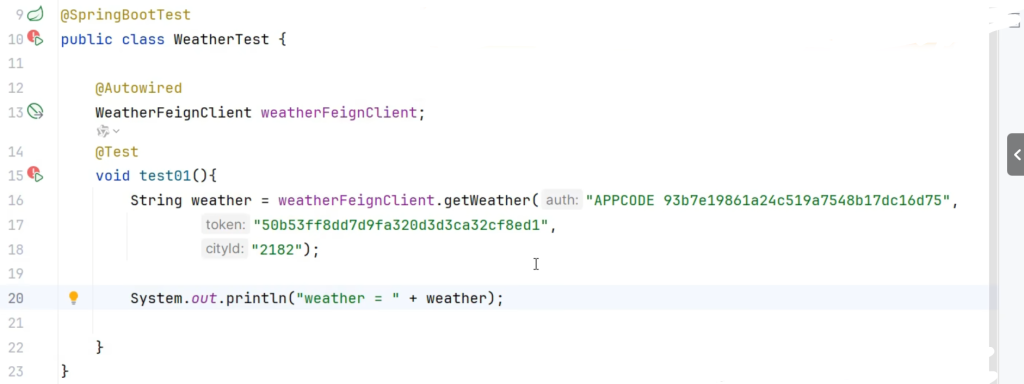
WeatherFeignClient
编写测试类
4.1.5小技巧与面试题
小技巧
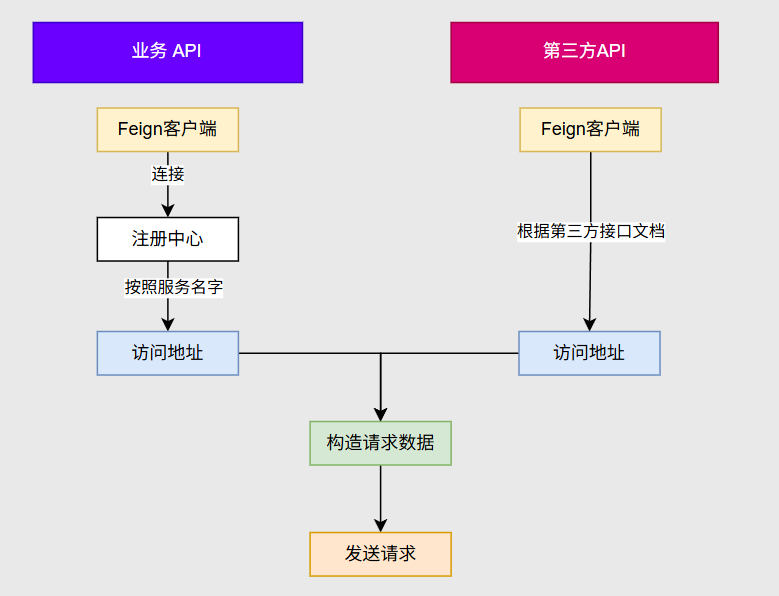
FeignClient远程调用自己写的业务API方法参数与Controller层方法参数一样,直接复制即可
如果调用第三方API参考第三方API文档
面试题:客户端负载均衡与服务端负载均衡区别
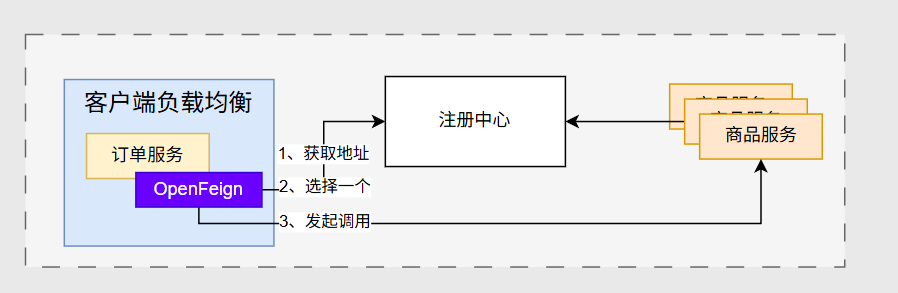
客户端负载均衡
发起调用的这一端,自己根据负载均衡算法,选择一个对方的服务进行调用,负载均衡发生在了客户端的位置我们就叫做客户端负载均衡
总结:客户端要有能力和责任来选择服务实例,负载均衡发生在调用发起方。
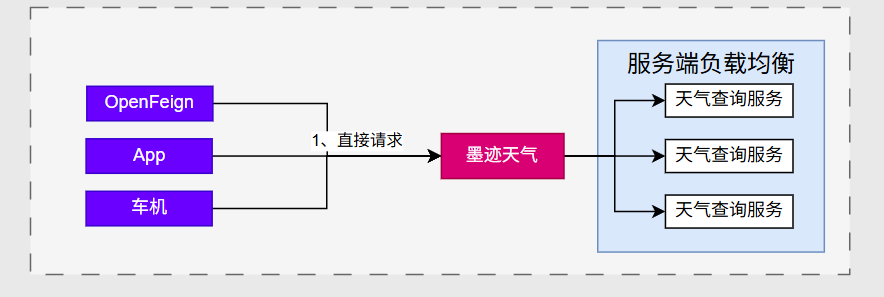
服务端负载均衡
客户端直接把请求发给某个服务(如墨迹天气)。
墨迹天气服务作为“入口”,在服务端做负载均衡 ,它会:
根据配置或注册中心信息,将请求转发给后端的具体“天气查询服务”实例之一。
客户端无需感知有多少个后端实例,只需请求入口服务 。
服务端来统一做流量调度。
代表性工具:Nginx、Kong、Zuul、Gateway、负载均衡的 API 网关等。
总结:服务端接收到请求后进行转发,负载均衡发生在服务提供方的入口。
对比点
客户端负载均衡
服务端负载均衡
负载均衡位置
调用方(客户端)
服务方(入口服务)
客户端是否感知服务实例
是
否
灵活性
高(可自定义算法)
中(由网关或代理控制)
典型工具
OpenFeign + Ribbon / LoadBalancer
Nginx、API Gateway 等
网络路径
直接请求目标服务
通过代理/网关转发
4.2进阶配置
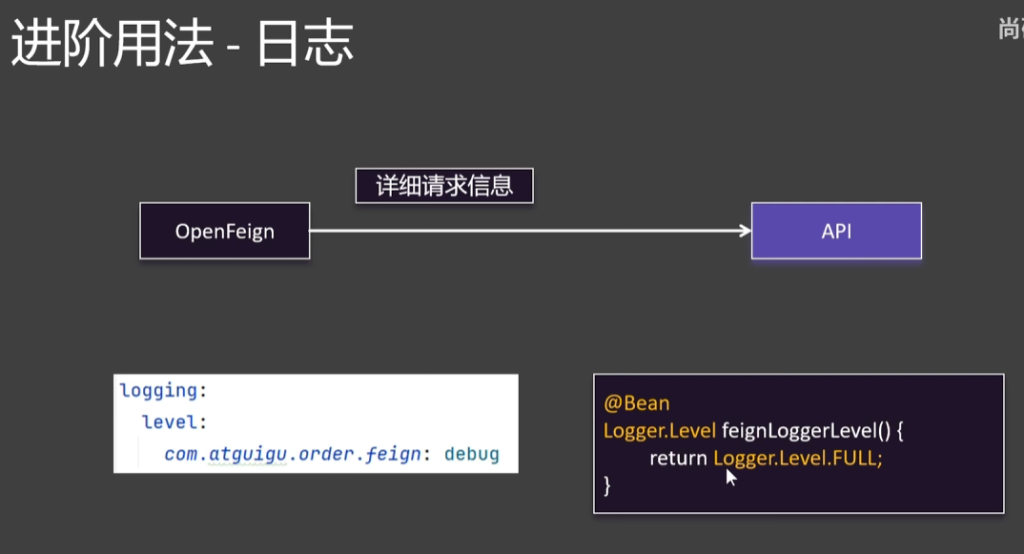
4.2.1.开启日志
在application.yml中
1 2 3 logging : level : com.geqian.order.feign : debug
在orderConfig中
1 2 3 4 @Bean Logger.Level feignLoggerLevel() { return Logger.Level .FULL ; }
重启项目时控制台就会打印远程调用时的日志了
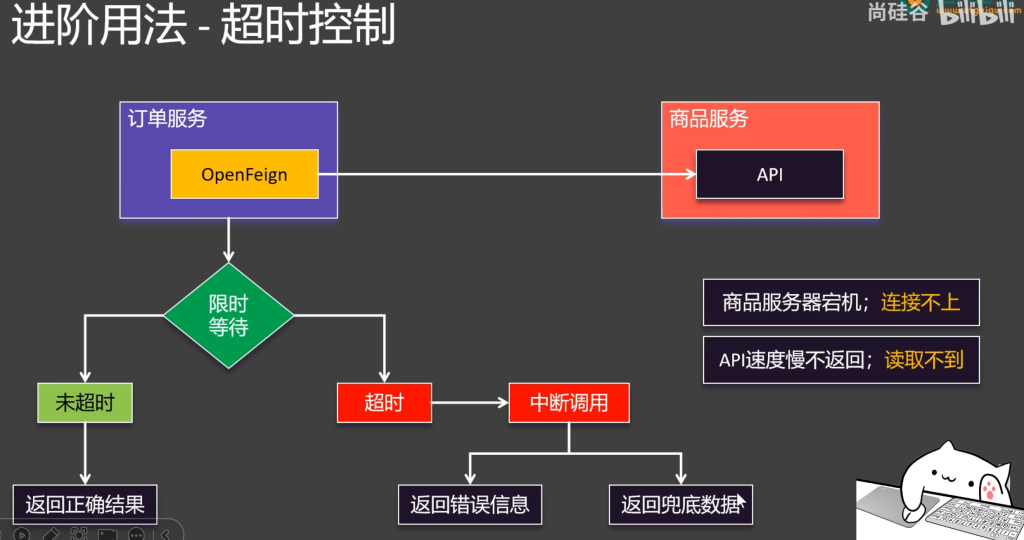
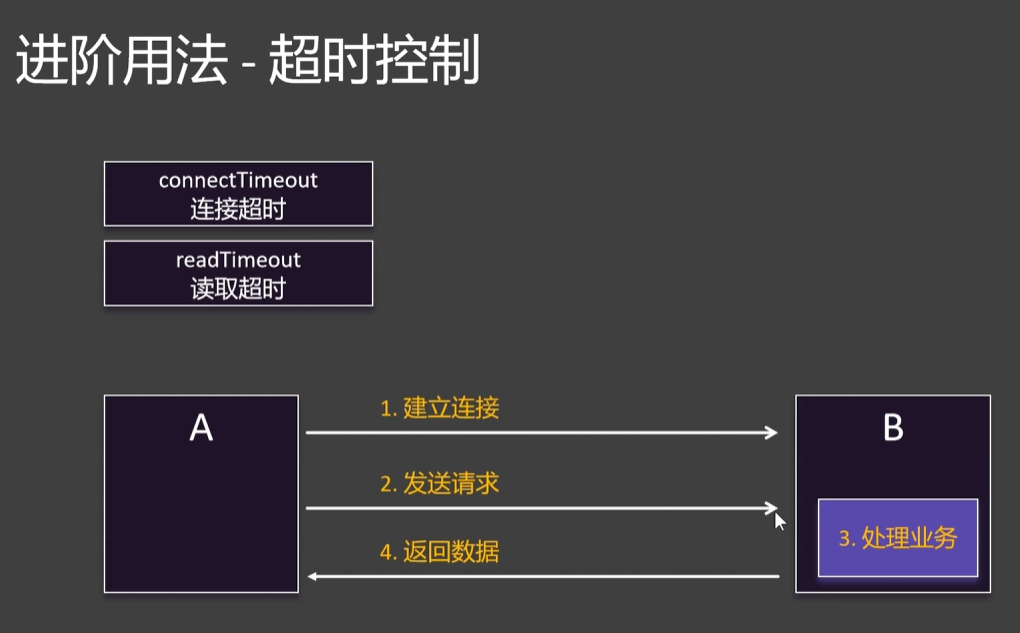
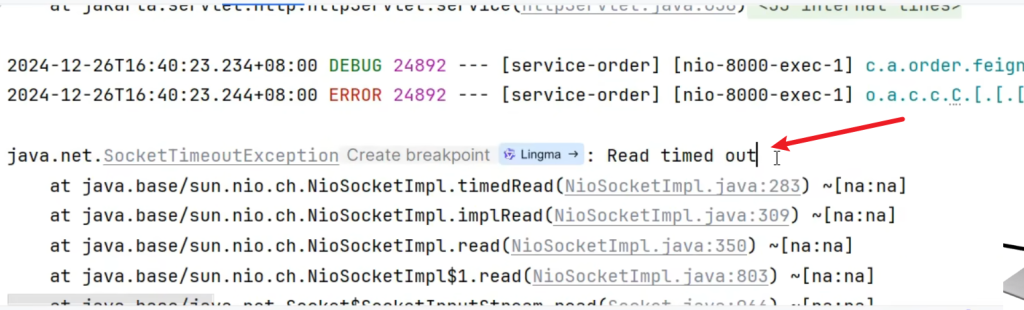
4.2.2超时控制
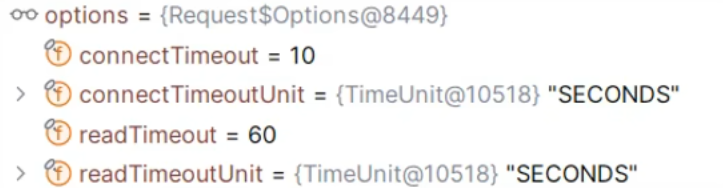
openFeign的默认连接超时和读取超时
超过时间控制台返回默认信息
在applicationfeign.yml中
1 2 3 4 5 6 7 8 9 10 11 12 13 spring: cloud: openfeign: client: config: default: logger-level: full connect-timeout: 1000 read-timeout: 2000 service-product: logger-level: full connect-timeout: 3000 read-timeout: 5000
4.2.3重试机制
默认重试器:间隔100ms,最大间隔1s,最大尝试次数5次
在orderConfig中
1 2 3 4 @Bean Retryer retryer ( return new Retryer .Default (); }
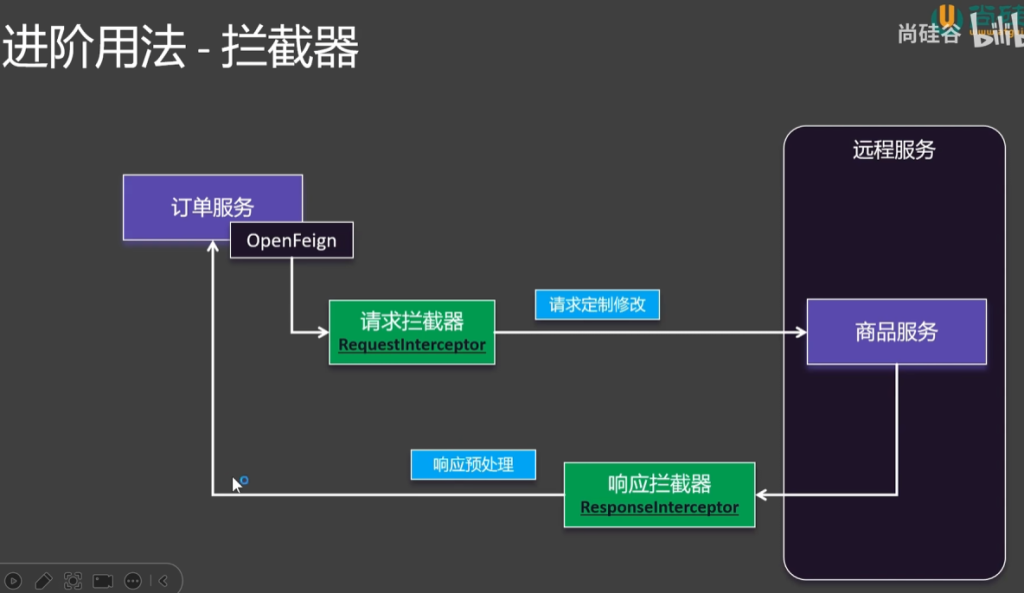
4.2.4拦截器
请求拦截器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.geqian.com.geqian.order.interceptor;import feign.RequestInterceptor;import feign.RequestTemplate;import java.util.UUID;@Component public class TokenInterceptor implements RequestInterceptor { @Override public void apply (RequestTemplate template) { template.header("X-token" , UUID.randomUUID().toString()); } }
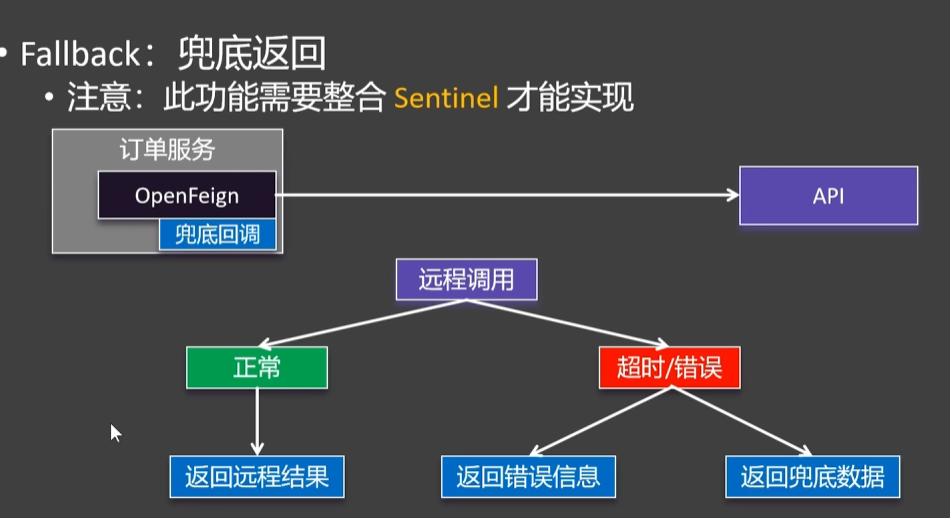
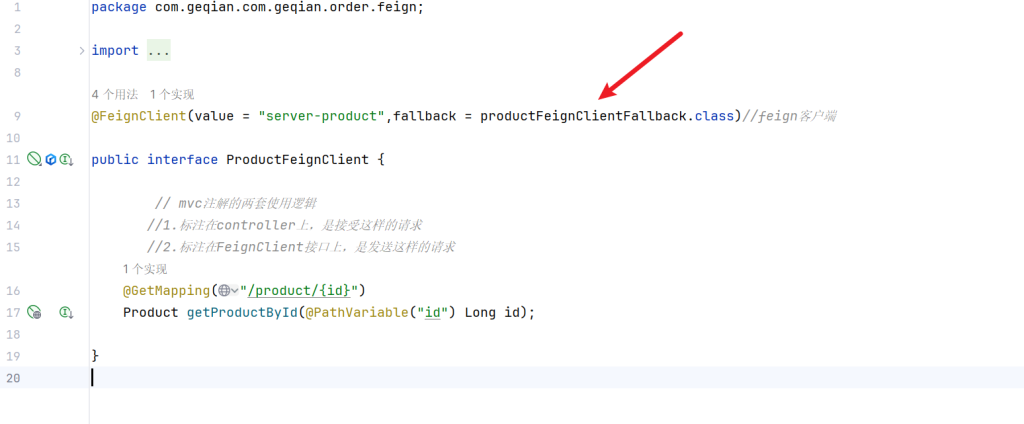
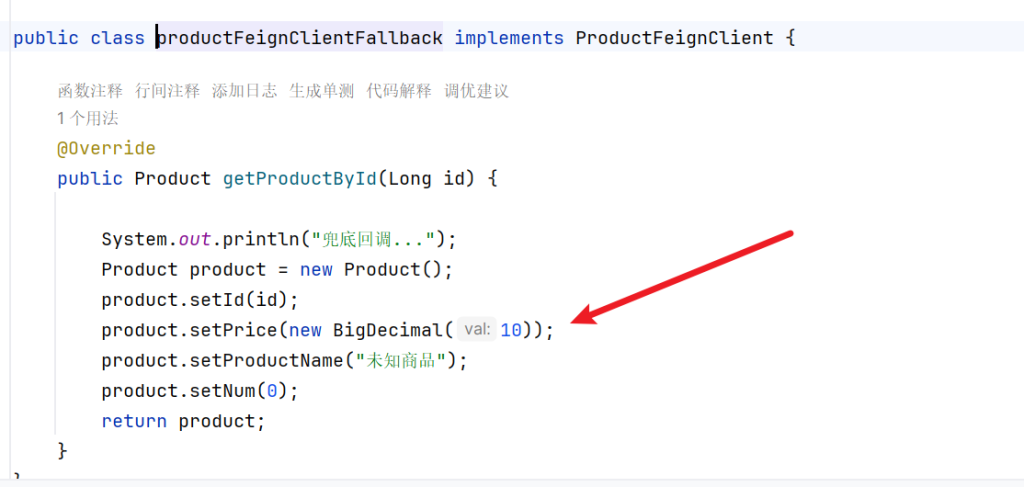
4.2.5.fallback - 兜底返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.geqian.com.geqian.order.feign.fallback;import com.geqian.Product.bean.Product;import com.geqian.com.geqian.order.feign.ProductFeignClient;import org.springframework.stereotype.Component;import java.math.BigDecimal;@Component public class productFeignClientFallback implements ProductFeignClient { @Override public Product getProductById (Long id) { System.out.println("兜底回调..." ); Product product = new Product (); product.setId(id); product.setPrice(new BigDecimal (10 )); product.setProductName("未知商品" ); product.setNum(0 ); return product; } }
在productFeignClient加入这个兜底回调
导入sentinel的依赖
1 2 3 4 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-sentinel</artifactId > </dependency >
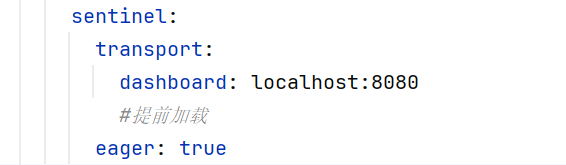
application-feign.yml:
1 2 3 feign: sentinel: enabled: true
4.3总结
5.Sentinel-流量保护
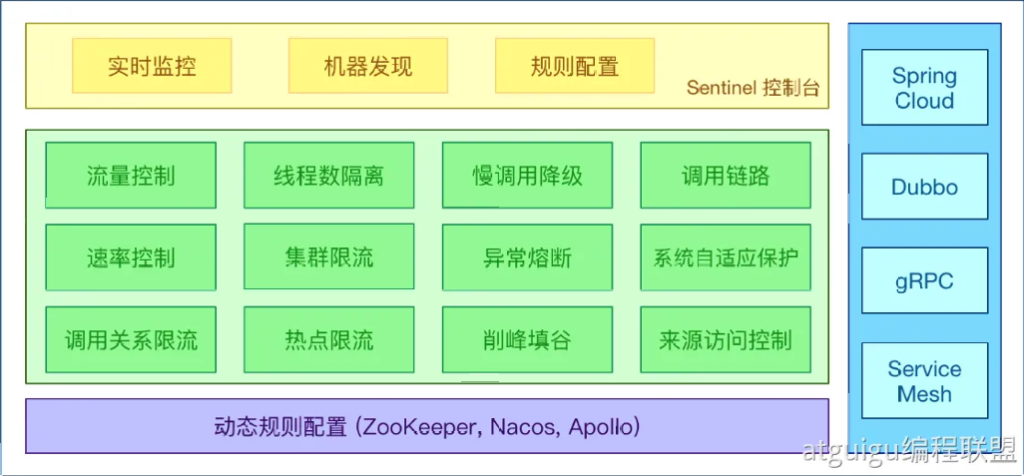
5.1介绍
官⽹:https://sentinelguard.io/zh-cn/index.html
wiki:https://github.com/alibaba/Sentinel/wiki
丰富的应⽤场景:Sentinel 承接了阿⾥巴巴近 10 年的双⼗⼀⼤促流量的核⼼场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填⾕、集群流量控制、实时熔断下游不可⽤应⽤等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接⼊应⽤的单台机器秒级数据,甚⾄ 500 台以下规模的集群的汇总运⾏情况。
⼴泛的开源⽣态:Sentinel 提供开箱即⽤的与其它开源框架/库的整合模块,例如与 SpringCloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引⼊相应的依赖并进⾏简单的配置即可快速地接⼊ Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语⾔的原⽣实现。
完善的 SPI 扩展机制:Sentinel 提供简单易⽤、完善的 SPI 扩展接⼝。您可以通过实现扩展接⼝来快速地定制逻辑。例如定制规则管理、适配动态数据源等
5.2架构原理
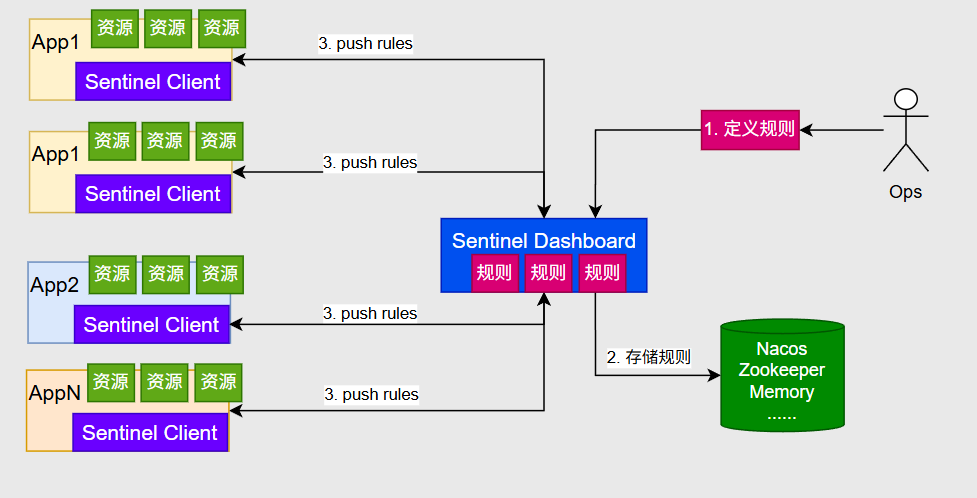
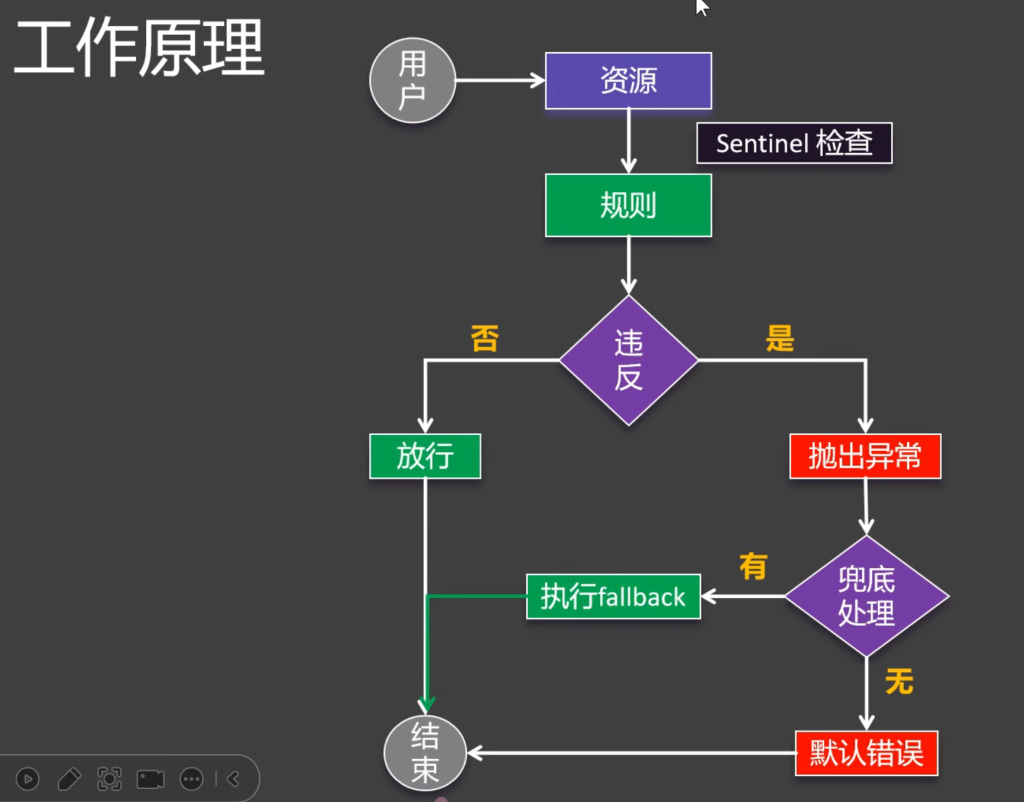
假设一个应用里有很多微服务,每一个微服务里面有很多的资源需要我们保护,我们只需要引入sentinel的客户端,这些客户端就可以连上sentinel的控制台sentinel Dashboard ,在控制台里面可以对每一种资源的规则进行定义(限流规则,熔断降级规则,黑白名单…),定义的规则可以存到nacos,zookeeper这些配置中心,存到内存里也可以(只是重启时就失效了),如果这些规则发生了变更,sentinel的控制台还可以把这些规则实时推送给每一个微服务,我们每次访问资源时,sentinel客户端就会来检查每一种资源的规则是否违背了规则,没有违背就放行,违背了就拒绝服务
5.2.1资源
定义资源 :
主流框架⾃动适配 (Web Servlet、Dubbo、Spring Cloud、gRPC、Spring WebFlux、Reactor);所有Web接⼝均为资源
编程式 :SphU API声明式 :@SentinelResource
5.2.2规则
定义规则 :
流量控制规则
熔断降级规则
系统保护规则
来源访问控制规则
热点参数规则
5.2.3工作原理
5.3sentinel整合
java -jar启动
打开localhost:8080 默认账号密码都为sentinel
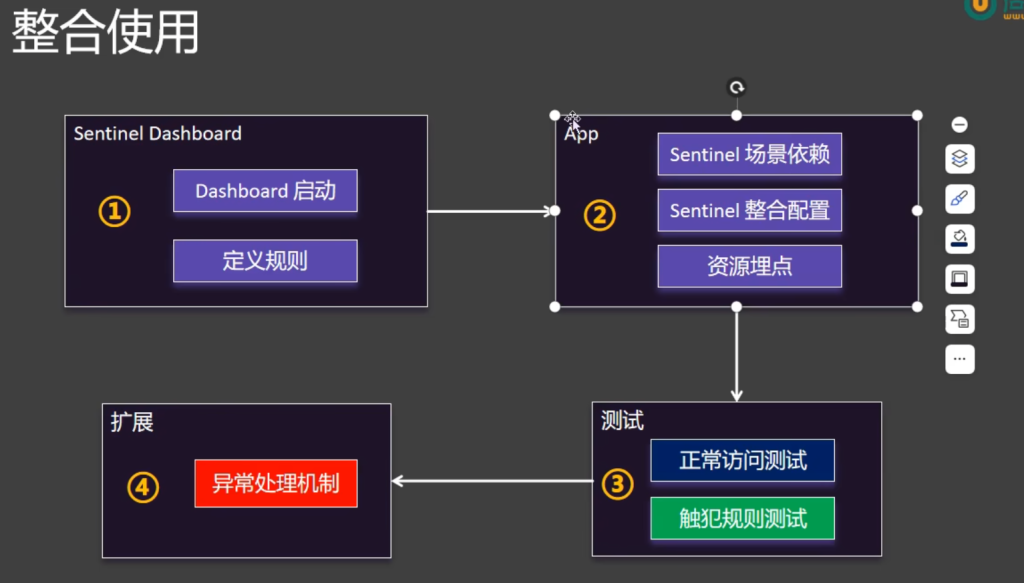
5.4.环境搭建
5.4.1.依赖
1 2 3 4 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-sentinel</artifactId > </dependency >
5.4.2配置连接
连接成功
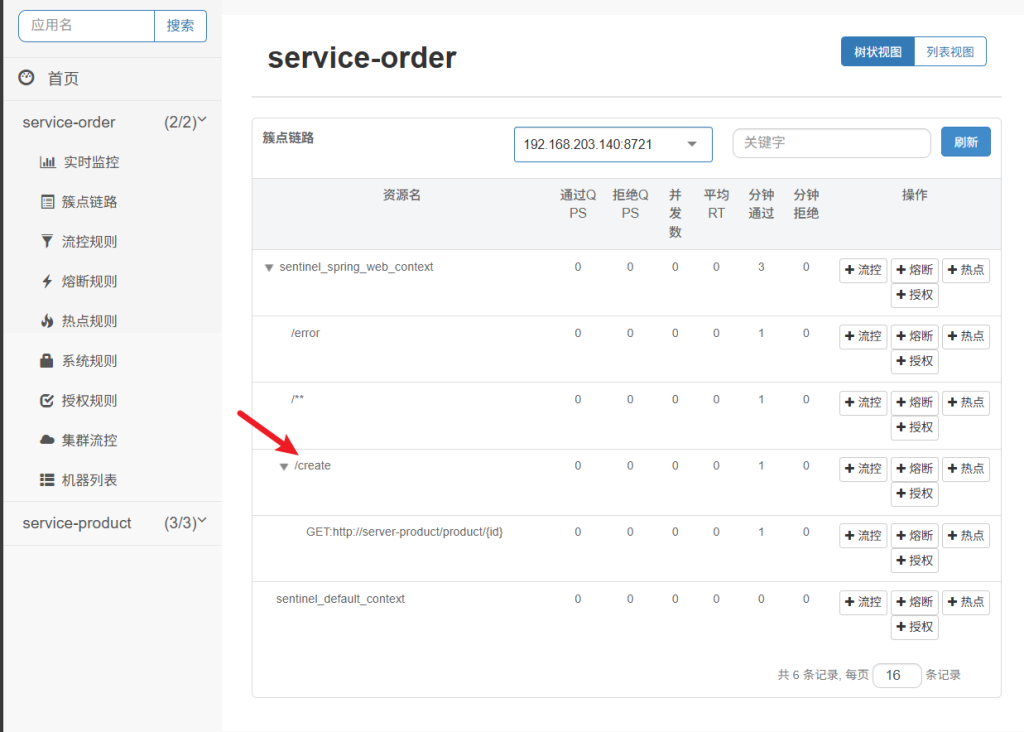
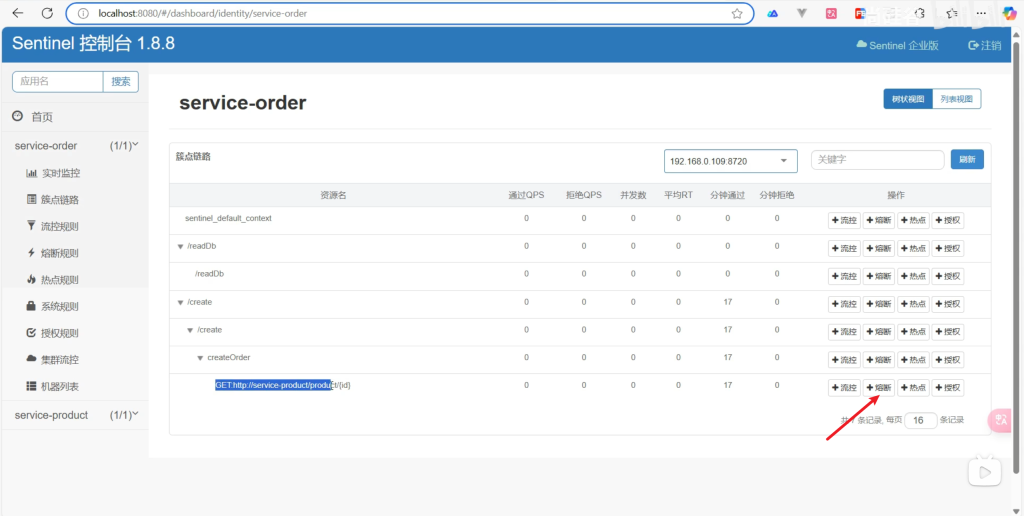
5.4.3对指定方法进行保护
我们发送请求后
在控制台就可以看到
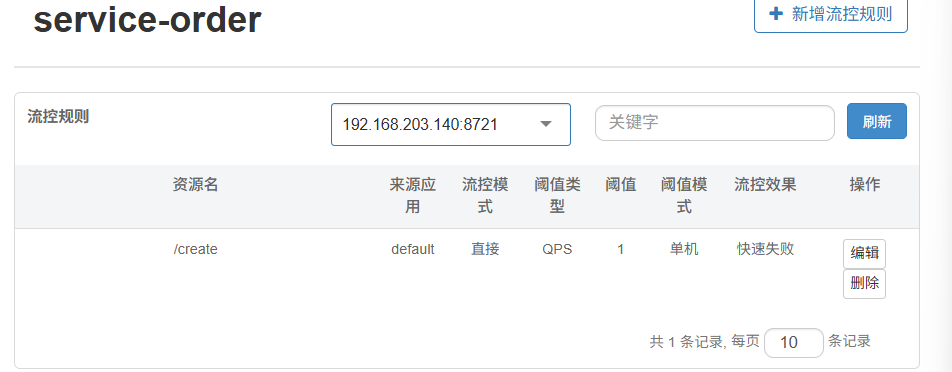
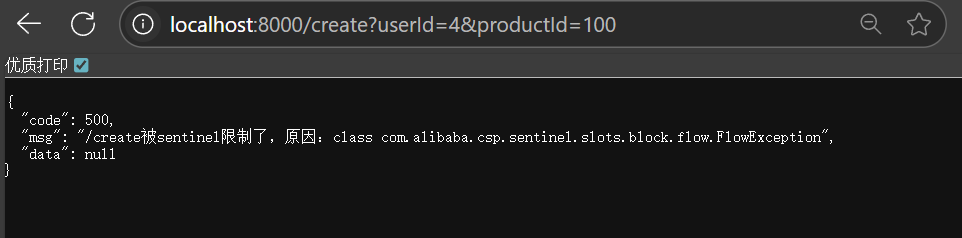
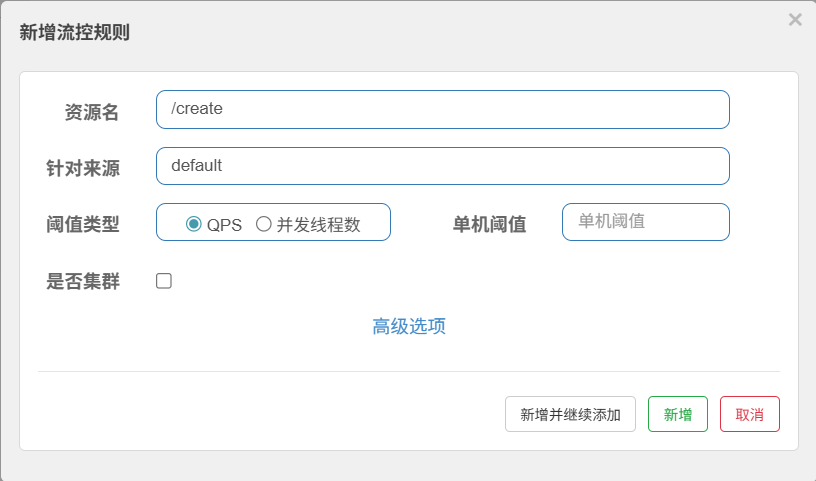
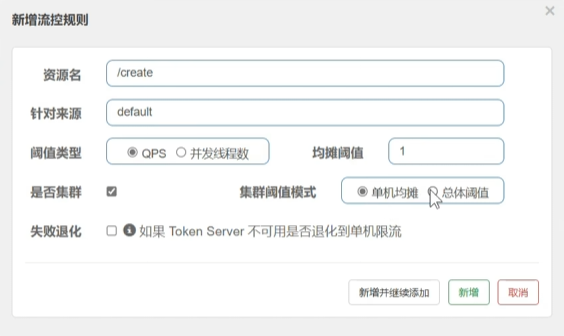
给create方法创建一个流控规则
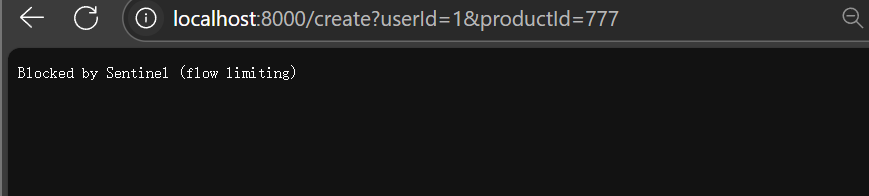
当我快速访问时会显示流量被sentinel限制了(规则生效了)
如何给前端返回这样的数据?
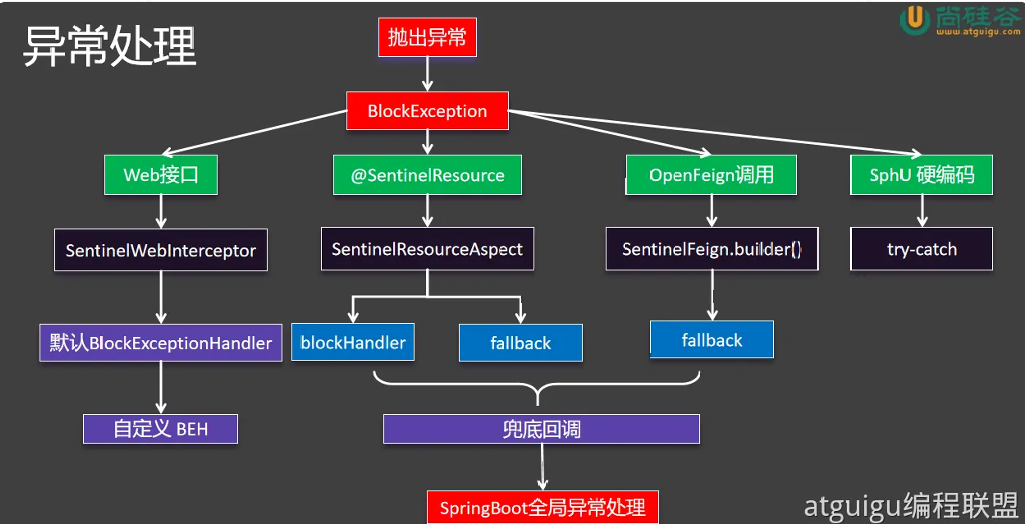
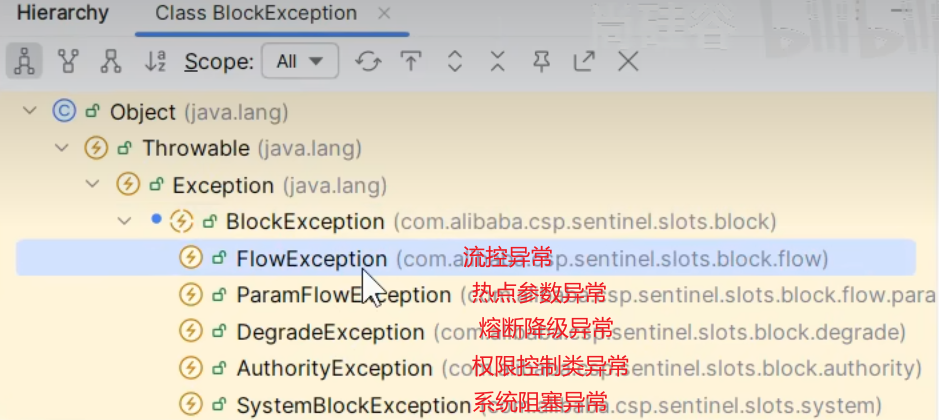
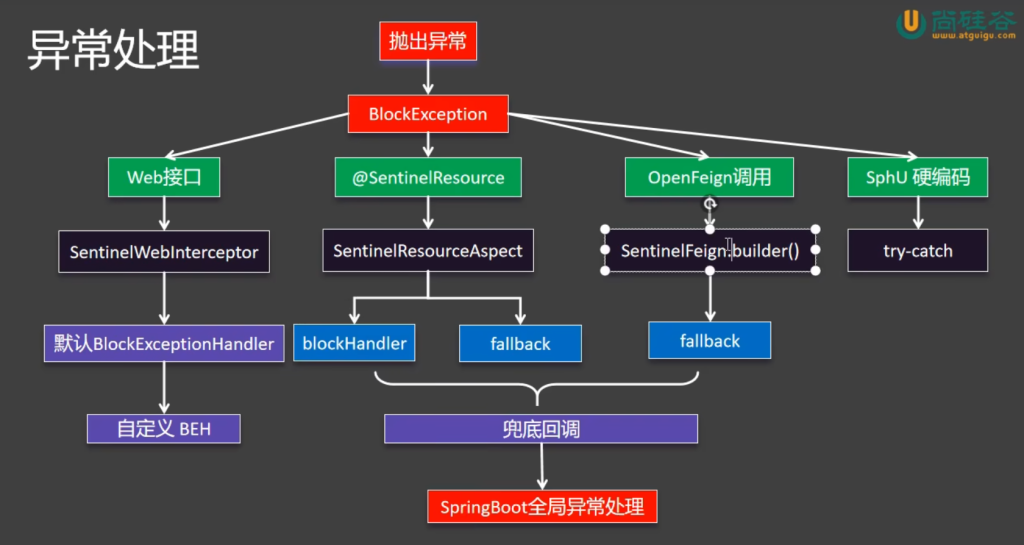
这牵扯到sentinel的异常处理机制(自定义BEN )
5.5异常处理机制
违背某一种规则就会抛出对应的异常
我们先看web接口方面的异常
5.5.1⾃定义 BlockExceptionHandle
回归到这个问题
如何给前端返回这样的数据?
这牵扯到sentinel的异常处理机制(自定义BEN ),需要我们自定义BlockExceptionHandle。
首先在model层创建一个统一相应模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.geqian .common ; import lombok.Data ;@Data public class R { private Integer code; private String msg; private Object data; public static R ok ( R r = new R (); r.setCode (200 ); return r; } public static R ok (String msg, Object data R r = new R (); r.setCode (200 ); r.setMsg (msg); r.setData (data); return r; } public static R error ( R r = new R (); r.setCode (500 ); return r; } public static R error (Integer code, String msg R r = new R (); r.setCode (code); r.setMsg (msg); return r; } }
在自定义的MyBlockExceptionHandler中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.geqian.com.geqian.order.exception;import com.alibaba.csp.sentinel.adapter.spring.webmvc_v6x.callback.BlockExceptionHandler;import com.alibaba.csp.sentinel.slots.block.BlockException;import com.fasterxml.jackson.databind.ObjectMapper;import com.geqian.common.R;import jakarta.servlet.http.HttpServletRequest;import jakarta.servlet.http.HttpServletResponse;import org.springframework.stereotype.Component;import java.io.PrintWriter;@Component public class MyBlockExceptionHandler implements BlockExceptionHandler { private ObjectMapper objectMapper = new ObjectMapper (); @Override public void handle (HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, String resourceName, BlockException e) throws Exception { httpServletResponse.setContentType("application/json;charset=utf-8" ); PrintWriter writer = httpServletResponse.getWriter(); R error = R.error(500 ,resourceName+"被sentinel限制了,原因:" +e.getClass()); String json = objectMapper.writeValueAsString(error); writer.write(json); writer.flush(); writer.close(); } }
自定义BEN完成
5.5.2处理@SentinelResource的异常
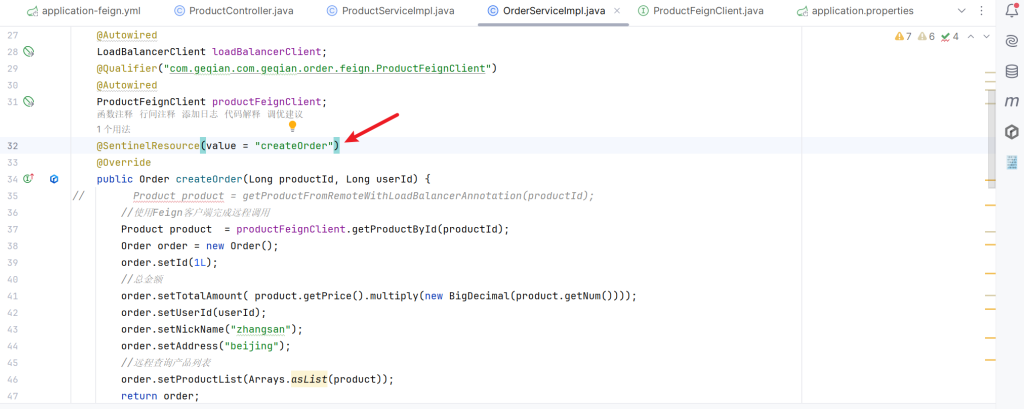
为create-order新增流控规则,删除之前/create的规则
当多次刷新发现会报500错误
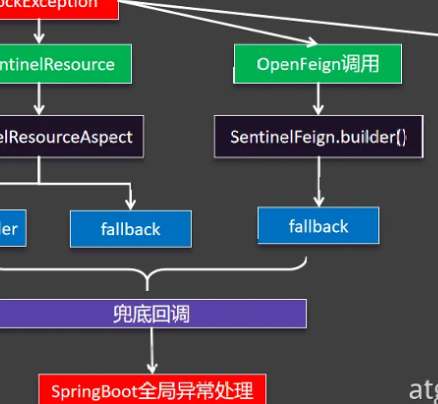
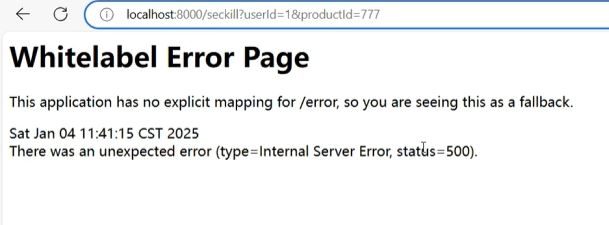
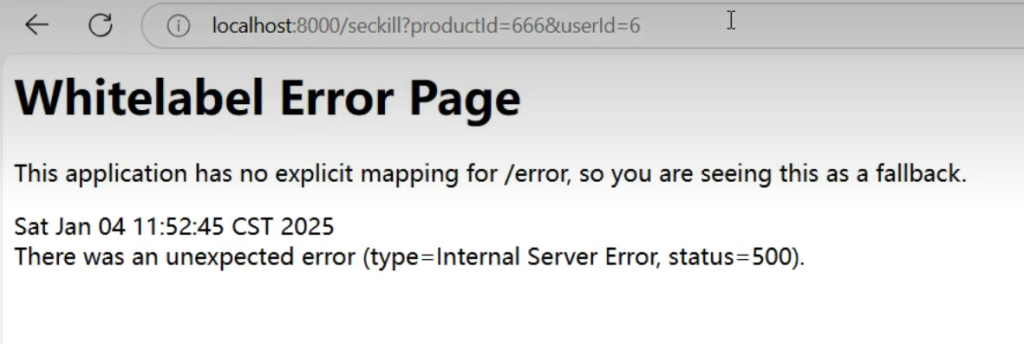
这个页面怎么来的?
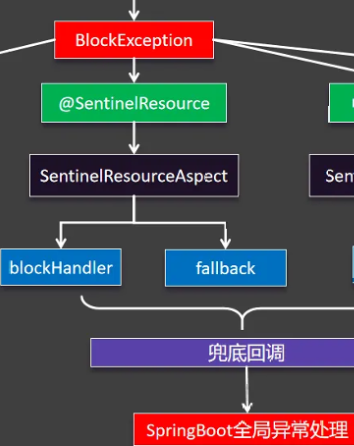
从这个流程可以看出,我们只是标了@SentinelResource这个注解只给资源起了名,blockHandler,fallback和defaultFallback都没有,异常不断往上跑最后由SpringBoot全局异常处理来给出这个异常页面,这便是这个页面的由来
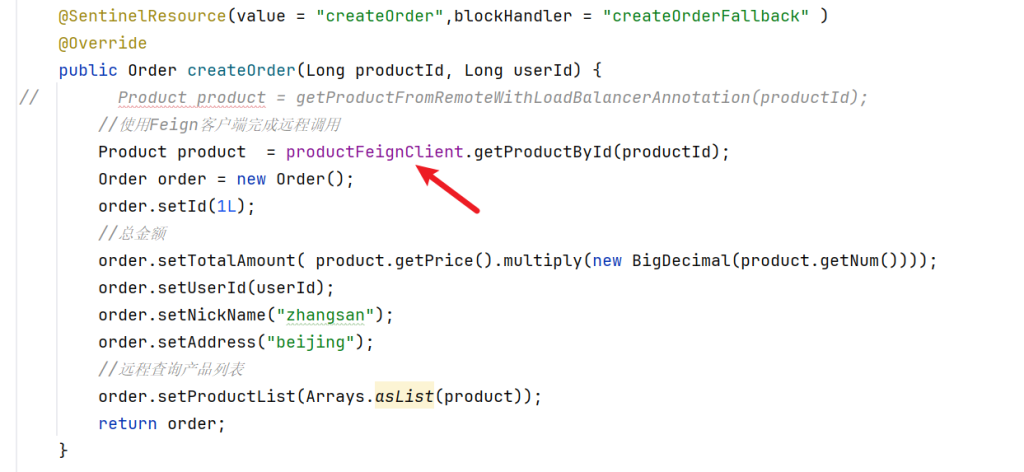
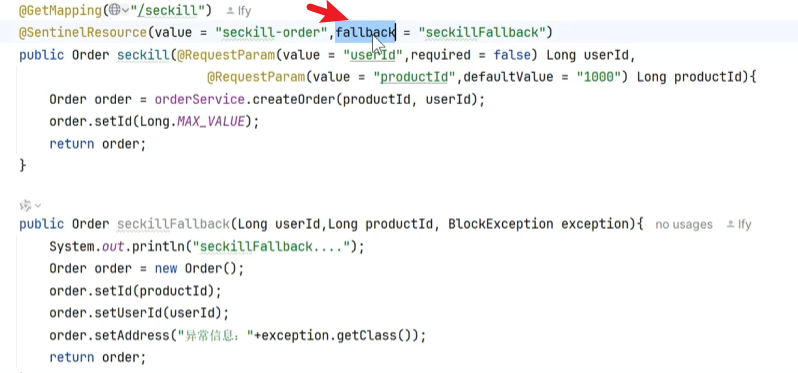
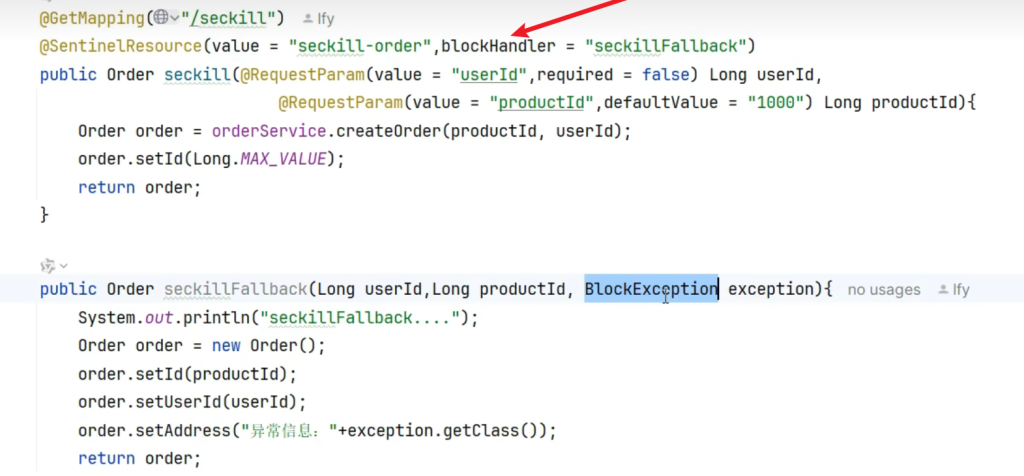
我们需要在注解上加上blockHandler
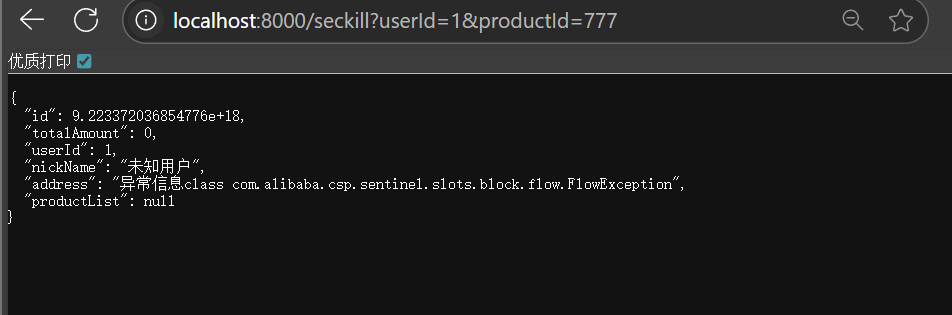
并补上兜底回调的方法
1 2 3 4 5 6 7 8 9 10 11 public Order createOrderFallback(Long productId, Long userId, BlockException e) { Order order = new Order(); order .setId(0 L); order .setTotalAmount(new BigDecimal(0 )); order .setUserId(userId); order .setNickName("未知用户" ); order .setAddress("异常信息" +e.getClass()); return order ; }
流程:当资源没有违背规则,会直接走OpenFeign远程调用商品信息
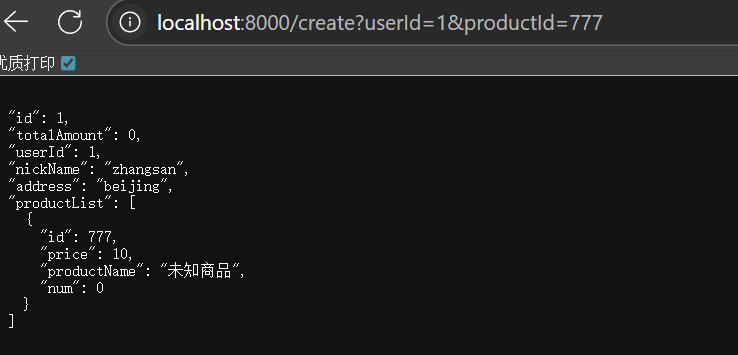
当资源违背规则,则调用兜底回调
重新刷新后不走Springboot的全局异常处理了,返回的是我们设置的兜底回调
总结:@SentinelResource一般标注在非controller的这些层,想要给哪些方法加上保护就加上这个注解,一旦违背规则,由blockHandler指定兜底回调,没有兜底回调和其他fallback则有Springboot全局处理器处理
5.5.3针对OpenFeign远程调用的异常处理
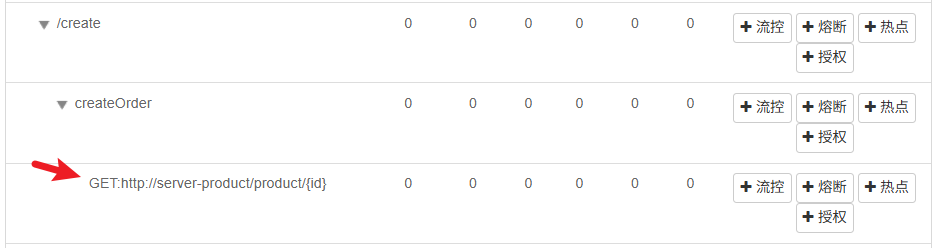
sentinel探测到了OpenFeign的远程调用
当我们给这个请求加上流控规则,在进行测试如图
OpenFeign只要远程调用失败了,它有fallback兜底回调,因此调用了它的兜底回调,如果它没有兜底回调,最终也会由Springboot的全局异常处理器来抛出异常页面
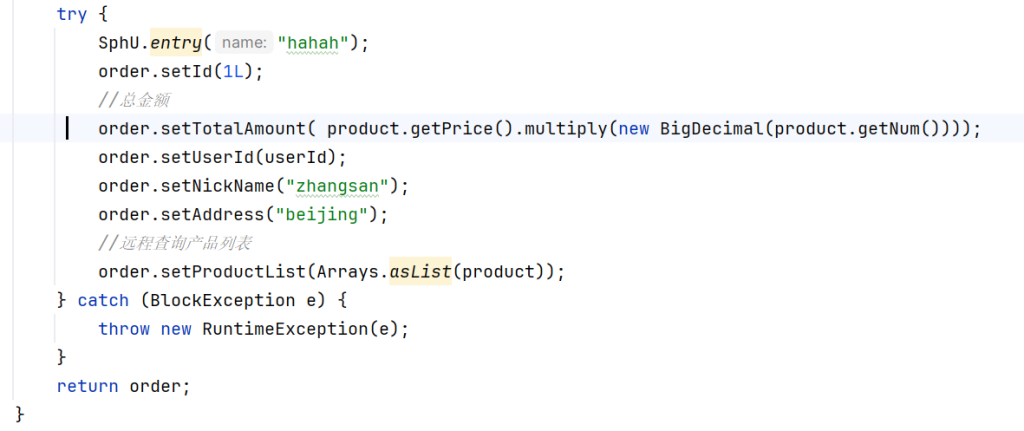
5.5.4SphU硬编码异常处理(了解即可)
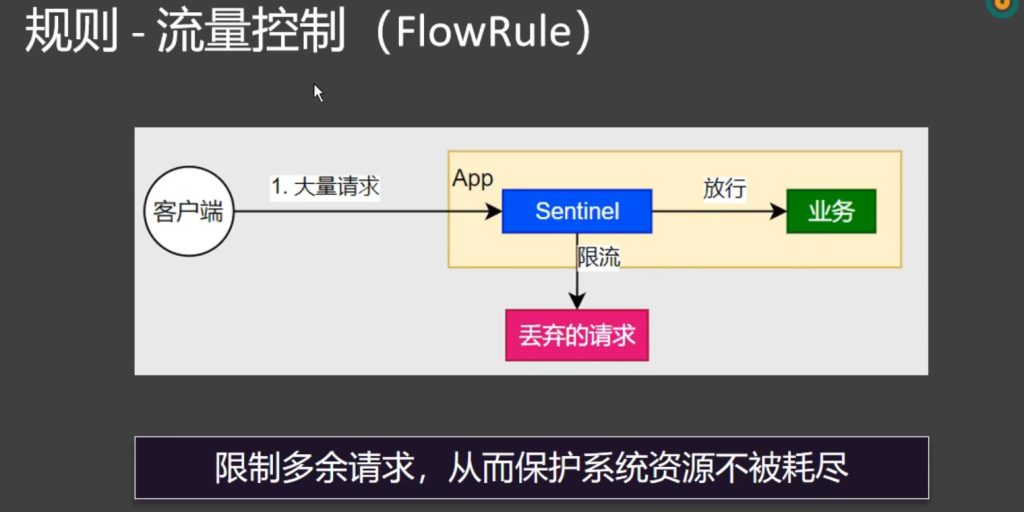
5.6.规则 - 流量控制
QPS:统计每秒请求数 (推荐)
并发线程数:统计并发线程数,引入线程池,容易出现线程问题,性能比较低下
单机阈值写1表示每秒通过一个请求
当点击是否集群,就会有集群的设置
单机均摊:每一个节点,每秒最多都只能放行一个请求
总体阈值:每秒所有的节点合起来只能处理一个请求
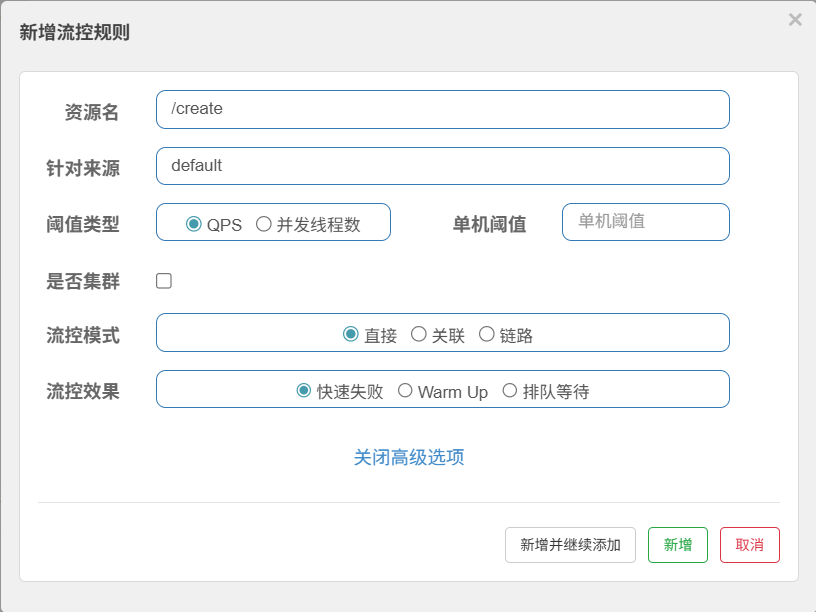
5.6.1流控模式
调用关系包括调用方,被调用方;一个方法又可能会调用其他方法,形成一个调用链路的层次关系;有了调用链路的统计信息,我们可以衍生出多种流量控制手段。
直接策略
对某个资源直接控制
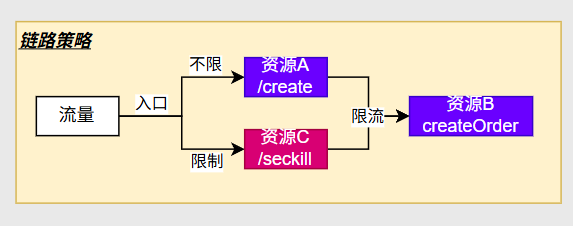
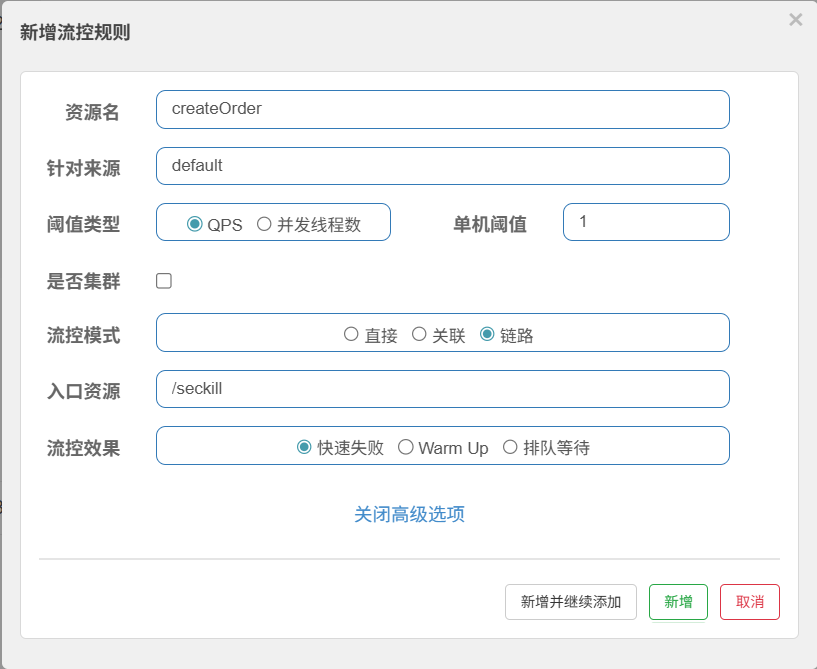
链路策略
根据不同的调用量来限制某一个调用量(比如下图对秒杀场景进行限流)
当一秒内访问过快就会开启限制
总结:这种规则仅对于某一路径下的访问生效
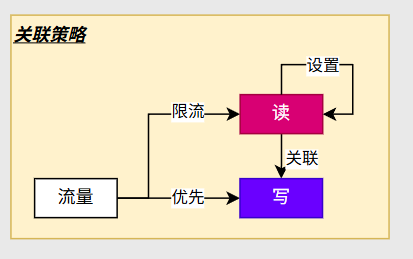
关联策略
在数据库中,读写请求都操作数据库的同一个资源,我们希望当订单的写比较大时,我们对读进行一个限流,实现一个优先写,这便叫关联策略。仅在写的请求量比较大时读的限流才会触发
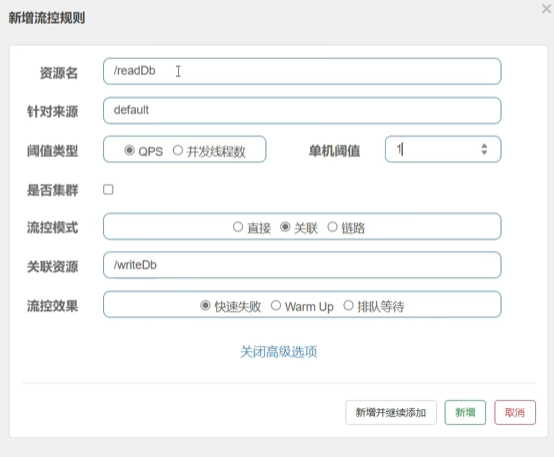
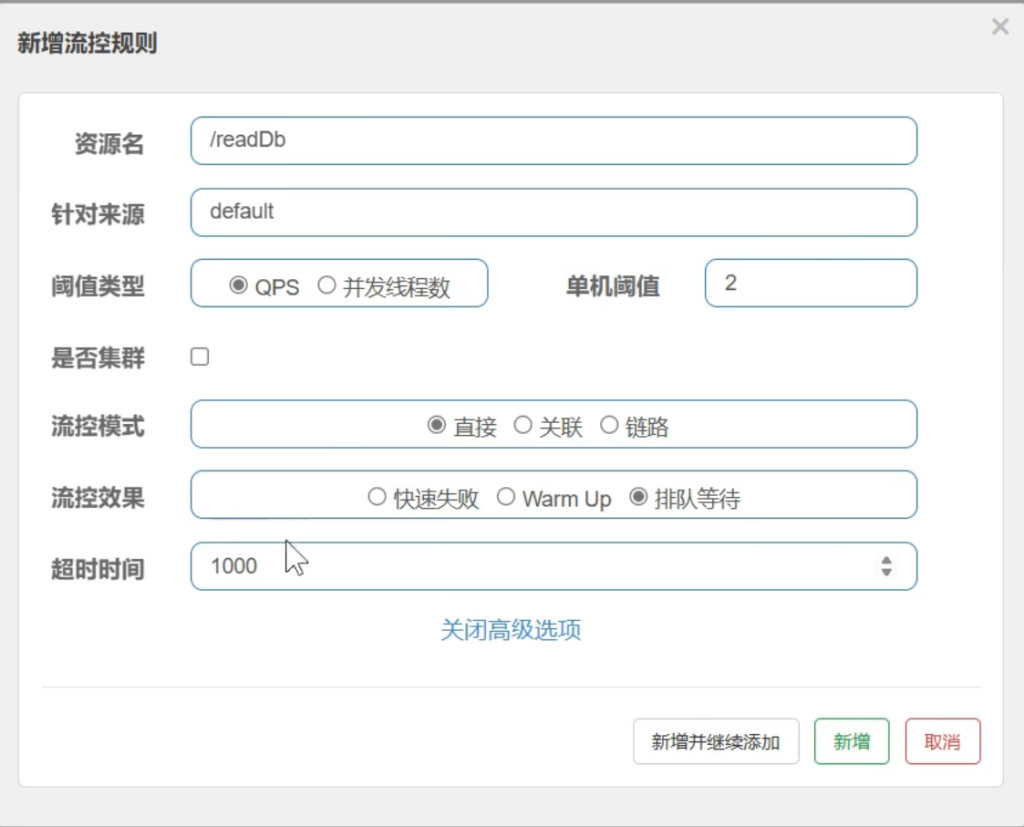
我们给readDb加一个流控规则,并关联到writeDb
我们频繁访问readDb,没有问题
当频繁访问writeDb时,再去访问readDb立马就被限制住了
总结:资源竞争用关联策略
5.6.2流控效果
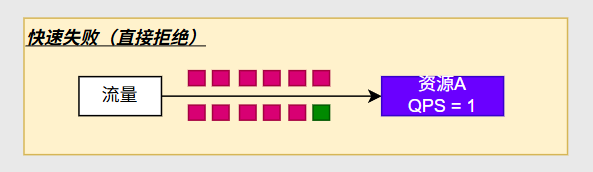
快速失败
快速失败的意思是如果没有超过这个阈值,则交给业务进行处理,如果超出了每秒一个,多余的请求直接会抛出一个block exception异常,这个异常由于我们做了处理,我们自定义的MyBlockExceptionHandler会返回给一个自定义的JSON数据
每秒多于的请求都会响应出这个错误的JSON数据
我们自定义429响应码(MyBlockExceptionHandler中)便于一会压力测试
1 httpServletResponse.set Status(429) ;//to many requests
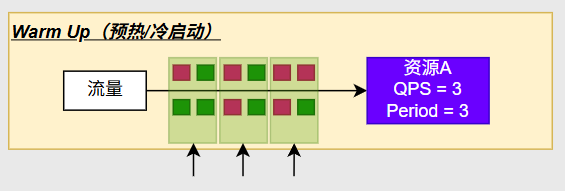
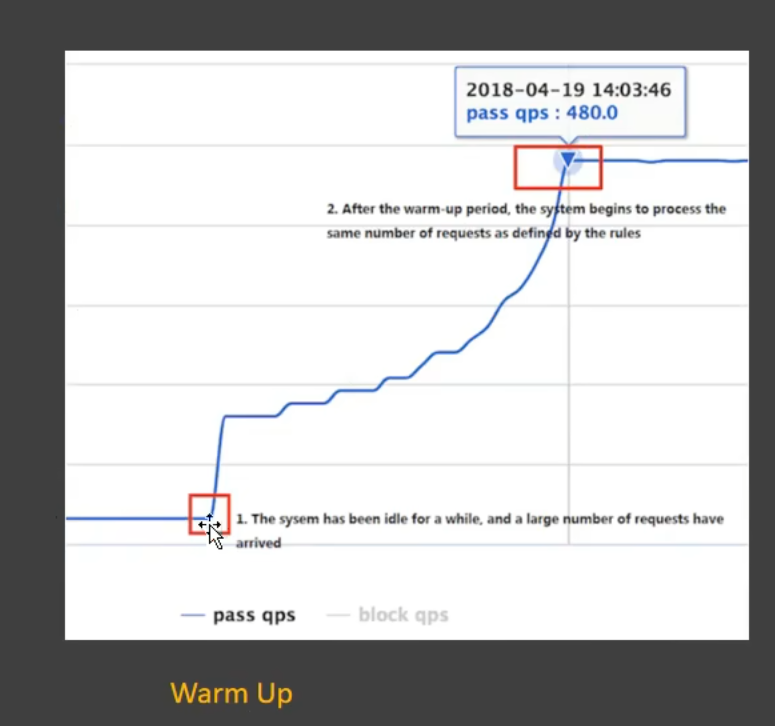
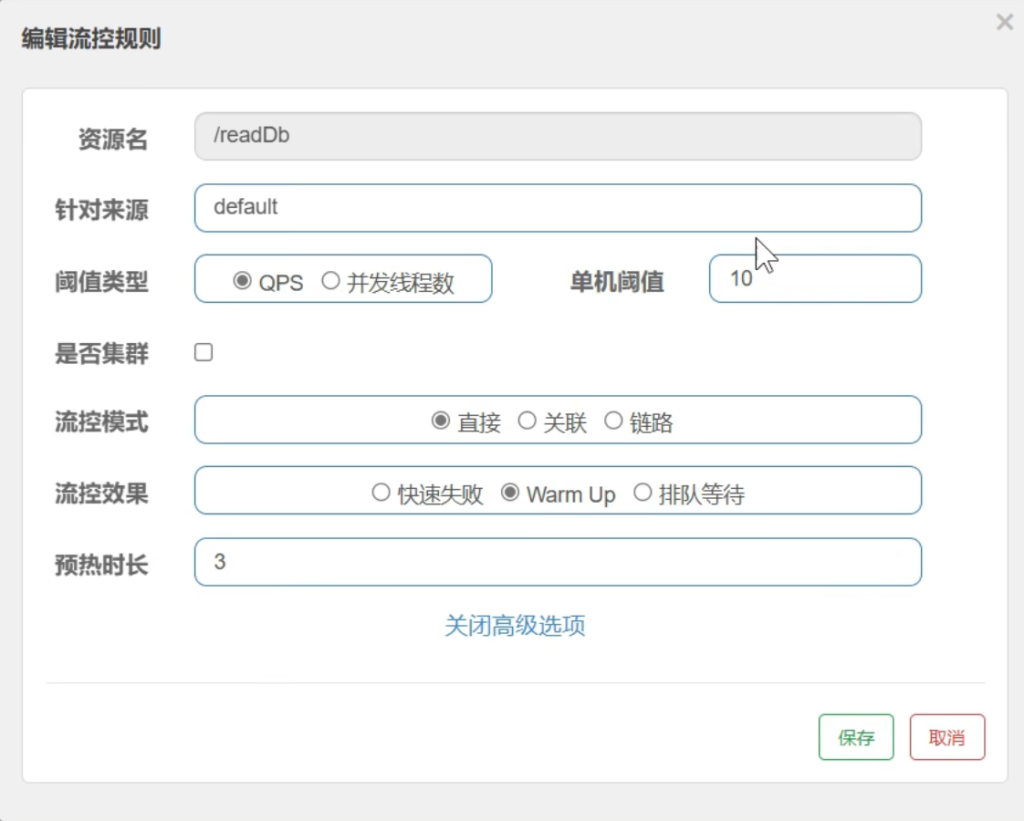
Warm Up
让系统逐步的增加自己处理的能力,以适应突然来的高峰请求
Warm Up的设置有两个;第一个是QPS–你想让每秒通过几个请求;Period–冷启动的周期是几秒
比如Period是3,它先会从1/3处开始冷启动,也就是第一秒我先放一个请求过来,剩下三个丢弃,第二秒逐步增加变为2个,第三秒接受3个到达了你的峰值QPS,以后再来稳定的处理3个请求
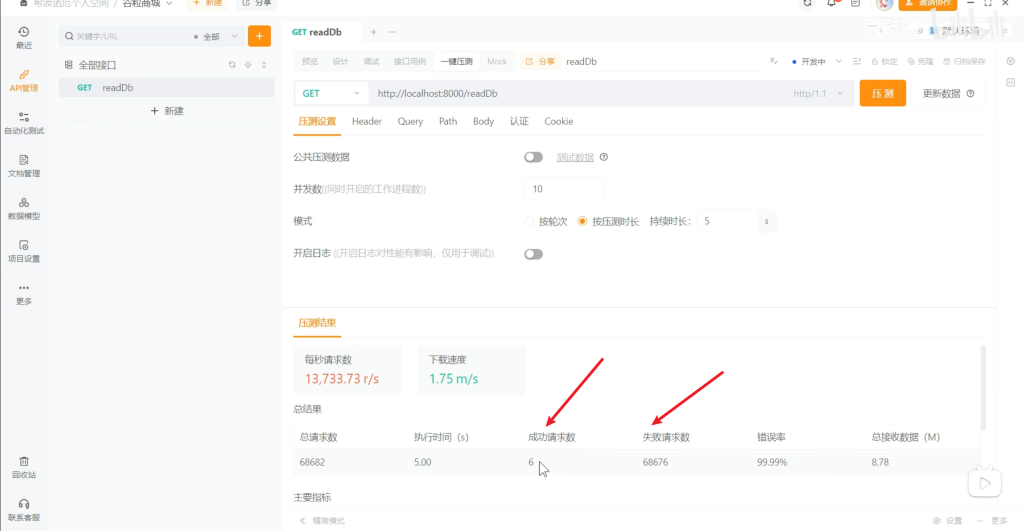
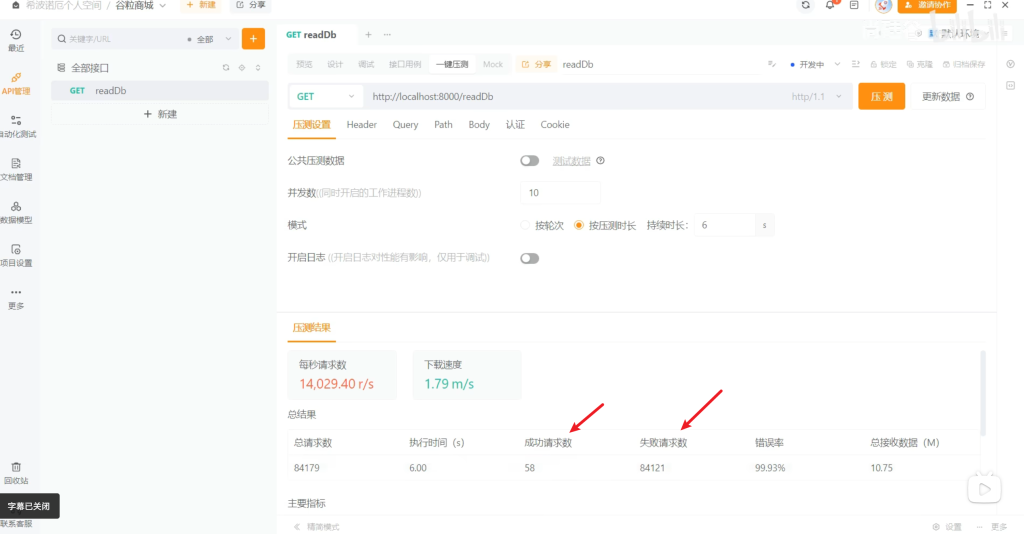
压测测试5秒,10个并发数
这58个有啥规律呢
从一开始的4个下一秒的5个再下一秒的10个,之后稳定10个
总结:Warm Up类似于踩油门,速度慢慢向上,最后稳定在顶峰
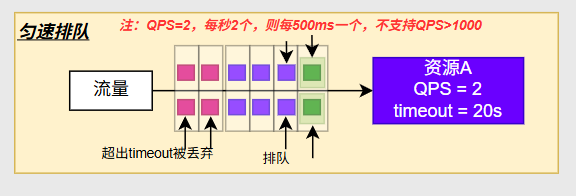
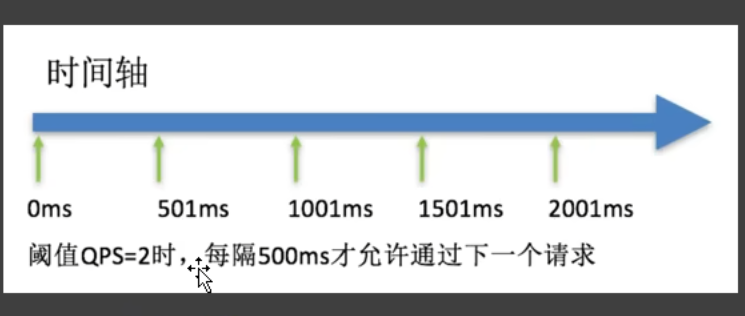
匀速排队
QPS=2,每秒放两个,多余的请求以前会丢在,但在匀速排队下会在这排队,等这两个请求过去了,下播再来两个,有一个最大等待时间,如果超出了最大等待时间就排队失败被丢弃
相当于去排队看病,医生每10十分钟看2个,没排到的排队,最大等待时间相当于医生的下班时间,超过了下班时间,没排上队的就撤了
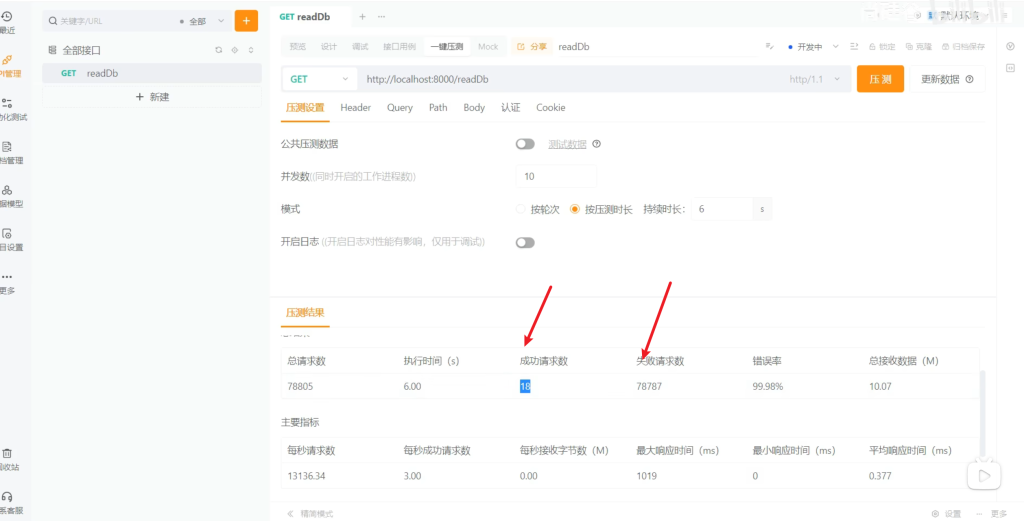
压测
成功18个,去控制台看到的效果是每500毫秒一个,相当于每秒2个,没排上队的超过最大等待时间就会被丢弃了
5.7规则-熔断规则
5.7.1断路器工作原理
死道友不死频道
熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置
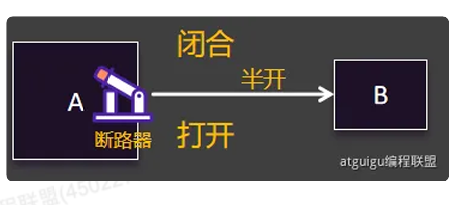
断路器
熔断降级去保护系统稳定性的工作原理(依靠断路器):
如果服务B是稳定的,调用就应该通过,所以断路器的默认状态是闭合状态,此时所有的远程调用都会通过。如果某一天B服务炸了,我们断路器就可以打开,一打开我们的调用就不会通过,A就不会真正的发起远程调用,当A发请求时断路器开着,会快速得到一个错误返回,快速返回保证了请求积压不了,系统就具有很强的稳定性。
那么B如果哪天恢复了,A怎么知道B恢复了呢?断路器有种状态就半开,会先放请求试一试就能知道B是否恢复了
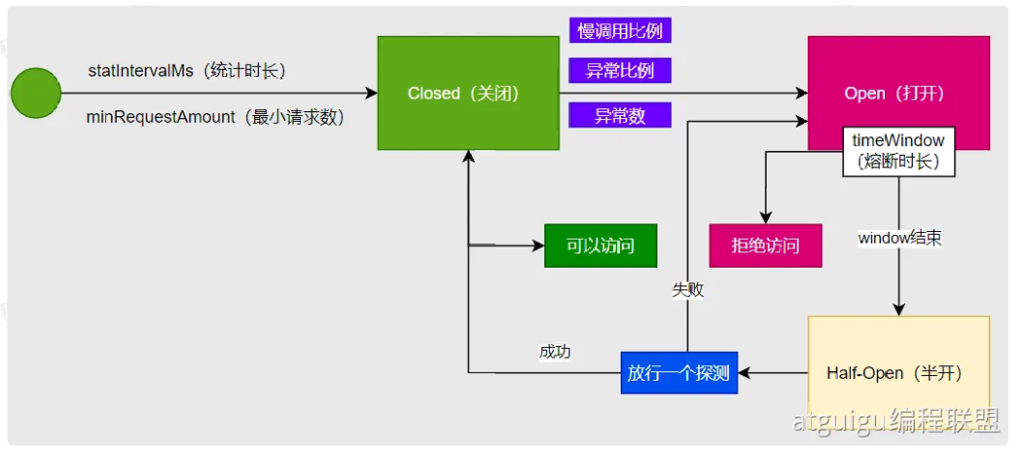
断路器的工作原理:
断路器有 三种状态 :
Closed(关闭) :Open(打开) :Half-Open(半开) :
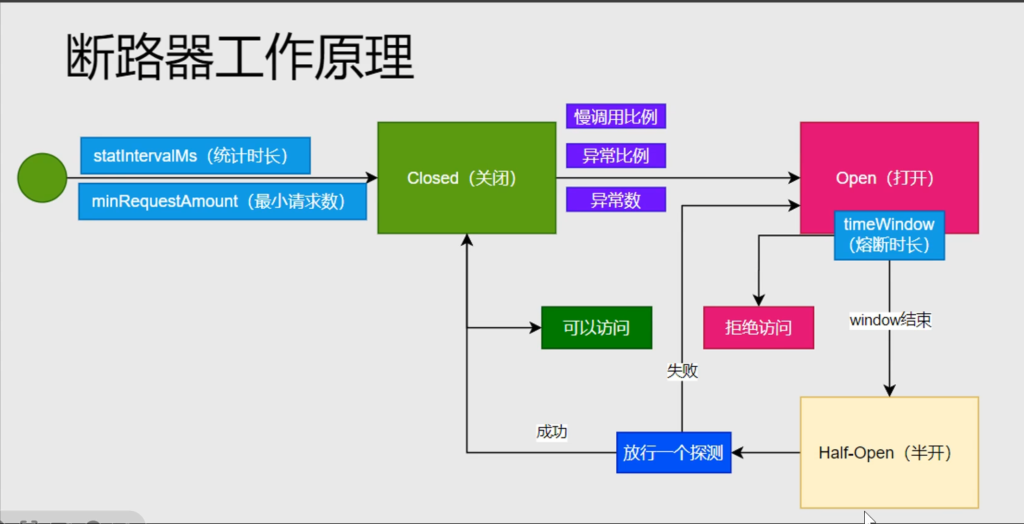
断路器的触发条件:
在 关闭状态 下,会监控一些指标:
慢调用比例 (比如:超过1秒才响应的请求)异常比例 异常请求数
只有满足两个条件才会触发统计:
达到设定的 统计时长 (如5秒)
达到 最小请求数 (如5个请求)
举例:
如果在5秒内有100个请求,其中70个超过了“慢调用阈值”,就认为慢调用比例是70%;
如果这个比例超过设定的阈值(如70%),断路器就“打开 ”。
打开(Open)状态行为:
一旦进入 Open 状态,所有对B的请求都被拒绝(快速失败);
会保持打开一段 熔断时长 (如30秒);
在这段时间内,不会再尝试调用服务B。
半开(Half-Open)状态行为:
熔断时长结束后,断路器会进入半开状态;
只允许一个请求
过去试探服务B是否恢复;
如果成功 :断路器变回关闭状态,恢复正常调用;
如果失败 :断路器再次进入打开状态,继续熔断30秒。
循环机制:
断路器会在 “关闭 → 打开 → 半开 → 关闭/打开” 之间循环:
成功 → 回到正常(关闭)
失败 → 再次熔断(打开)
而且即便是关闭状态,也会继续统计指标。如果又超过阈值,就会重新触发熔断。
总结一句话:
断路器是一个防止雪崩 的机制,当调用方A发现被调服务B表现不佳(比如慢响应/出错),就会暂时停止调用,等服务恢复后再恢复正常调用。
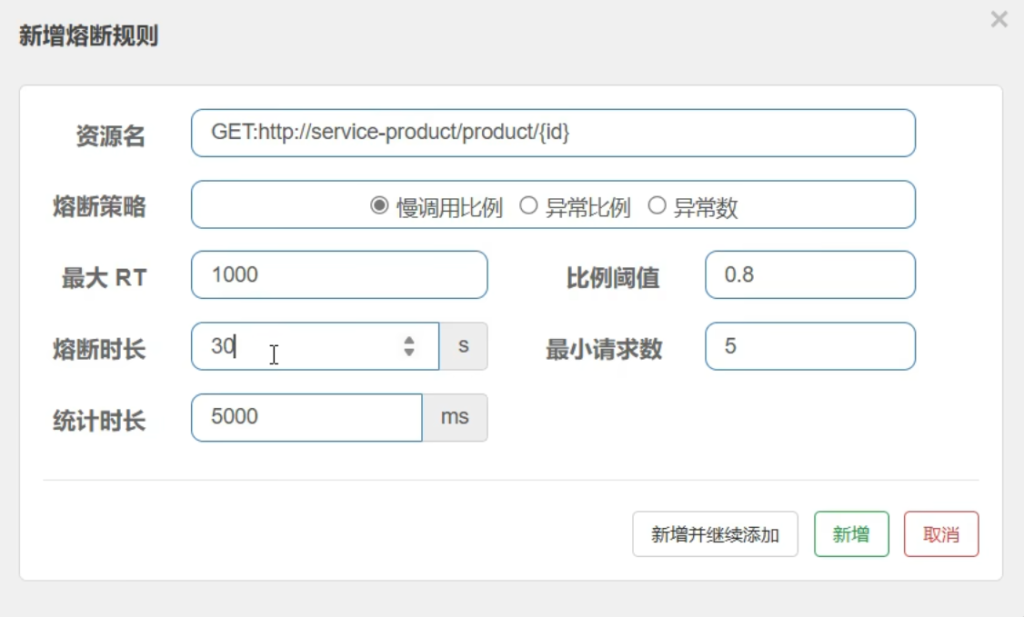
5.7.2熔断策略-慢调用比例
给远程调用配置慢调用比例
RT:response time 响应时间
5秒内如果有80%的请求响应时间超过最大响应时间1s就是慢调用,一旦发生了慢调用我们就开启熔断,熔断时长30s(断路器打开30s),这30s内的所有请求都不会发给远程服务,最小请求数为5表示至少发五个以上的请求,样本量先上去才有统计的必要
测试一下慢调用比例规则
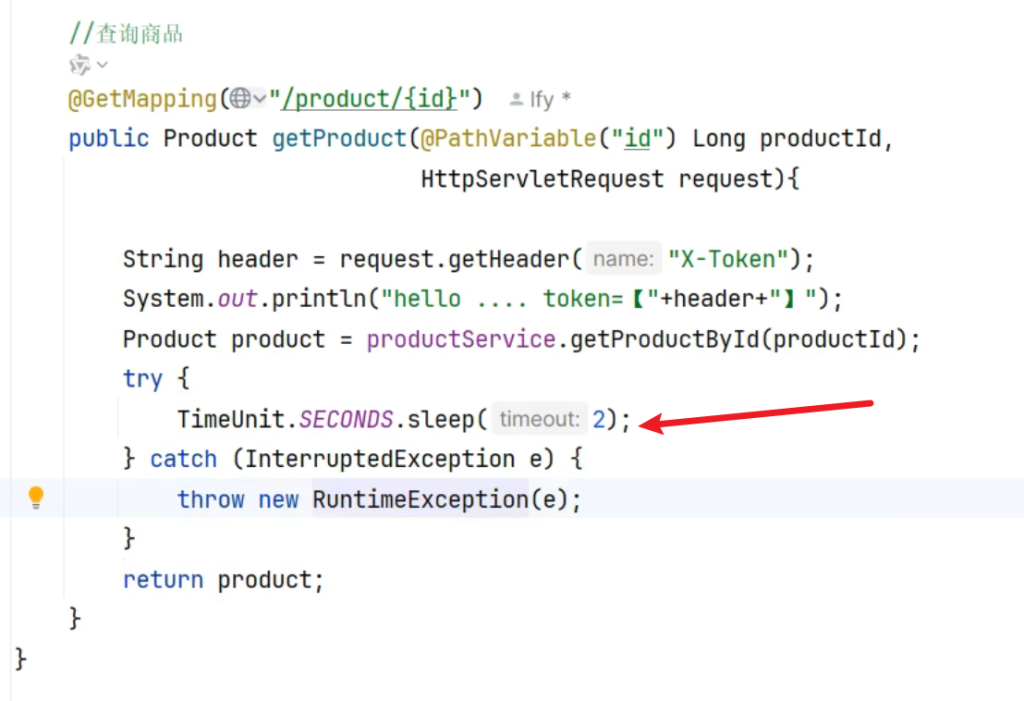
修改一下ProductController,让它休眠两秒再返回数据,这样便于测试
这样几乎每一个接口都会超出最大响应时间,便于我们检测熔断规则是否有效
当熔断后返回兜底数据
5.7.3熔断策略-异常比例
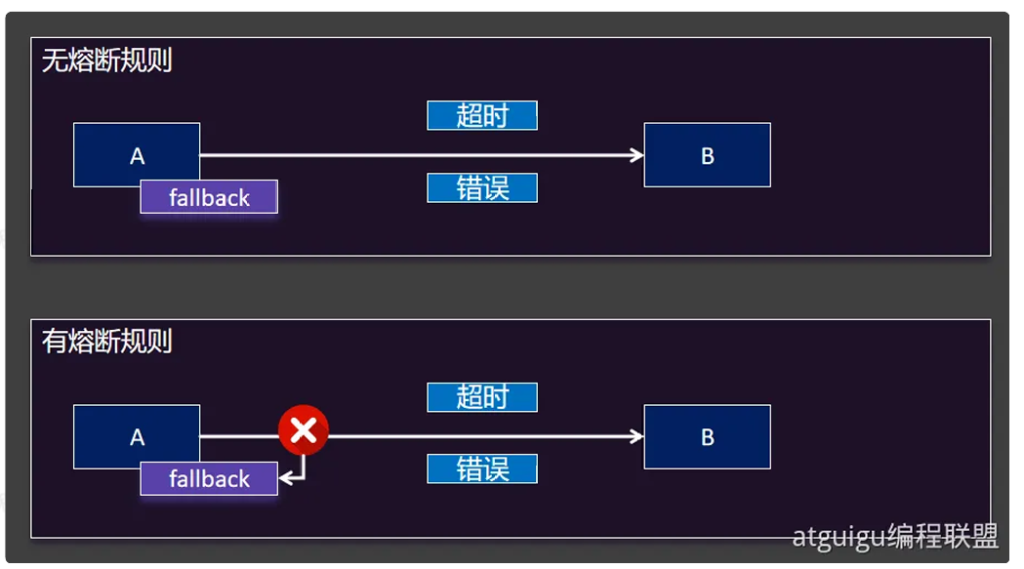
无熔断规则和有熔断规则的相同点在于远程一旦有问题都会执行兜底回调,但是有熔断规则的好处在于远程出问题,会有一段时间就不理远程了,不给远程发请求,这样就节约了远程调用时间,节约了很多的资源。
所以虽然没有熔断的情况下,还能正常兜底回调,但是配了熔断系统更快,在分布式系统中,只有更快,雪崩才跟不上你
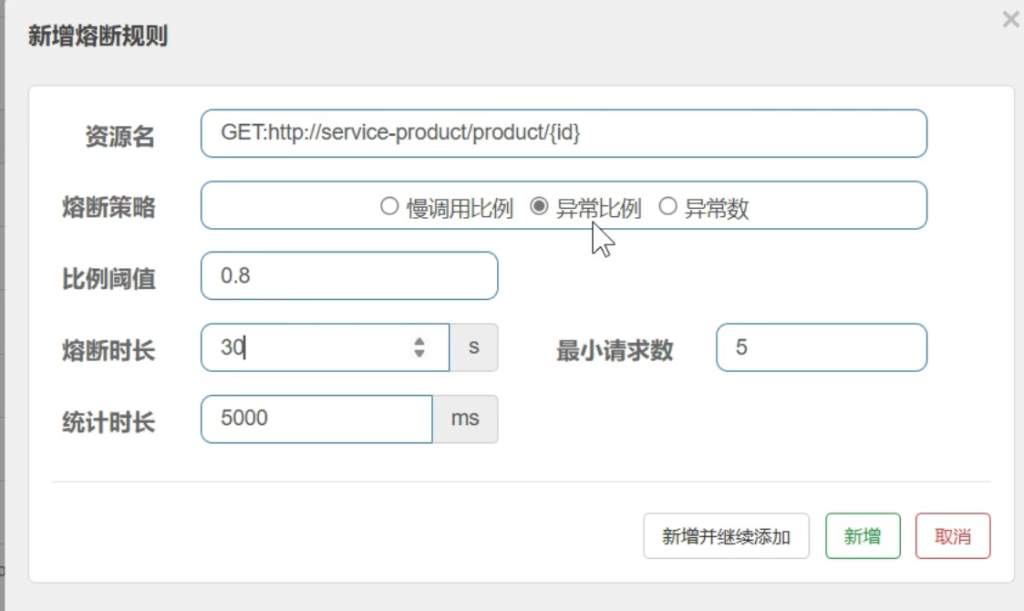
接下来给远程调用配置异常比例
5秒内至少5个请求才开始统计,当5s内的请求80%都出现了远程调用异常,熔断30s
触发熔断规则,熔断30s,返回兜底数据
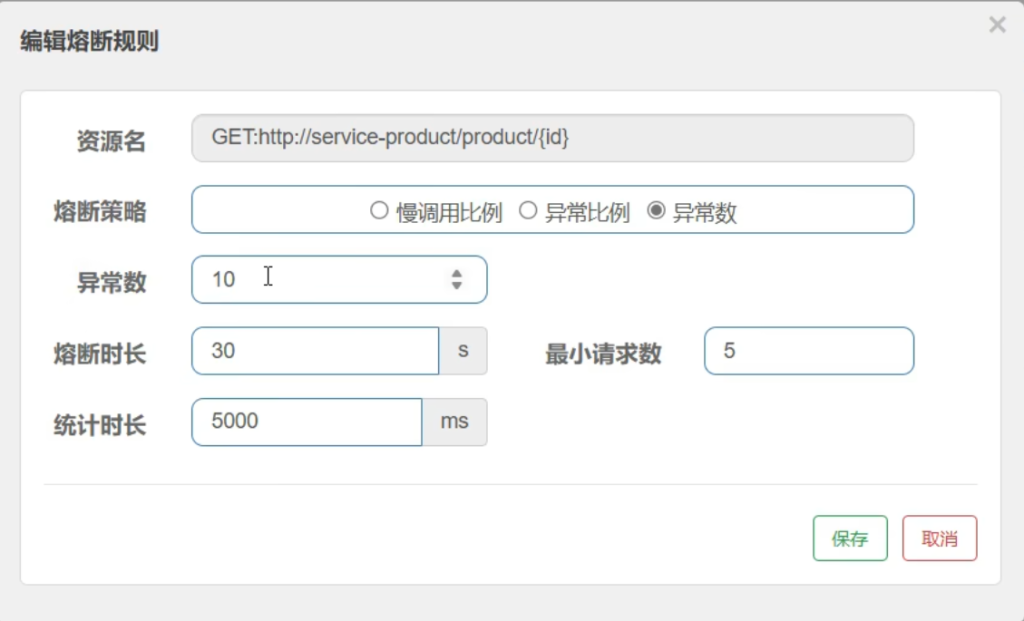
5.7.4熔断策略-异常数
类似于异常比例,这是这里把比例换成了具体的数字
效果与上面一样,这里就不做测试了
5.8规则-热点规则
5.8.1搭建环境
在热点规则里边,我们可以精确到访问这个资源的时候,比如带了5个参数,我对哪些参数满足什么规则以后我进行限制,相当于一个更细致的限流规则
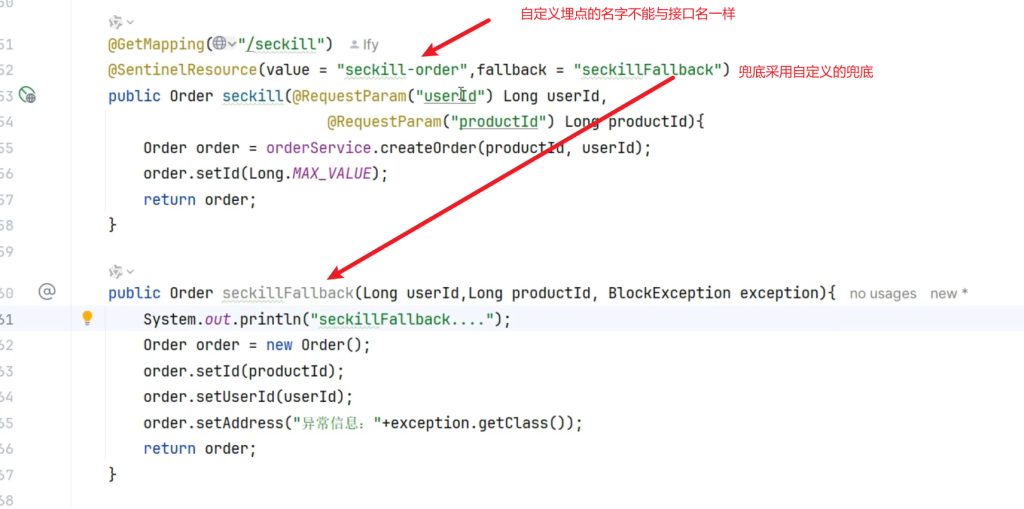
这里的Web指的是我们在Controller中写的接口,如果非要在Web接口上启用热点参数限流规则需要自定义埋点,自定义埋点的资源名不能和接口名重复
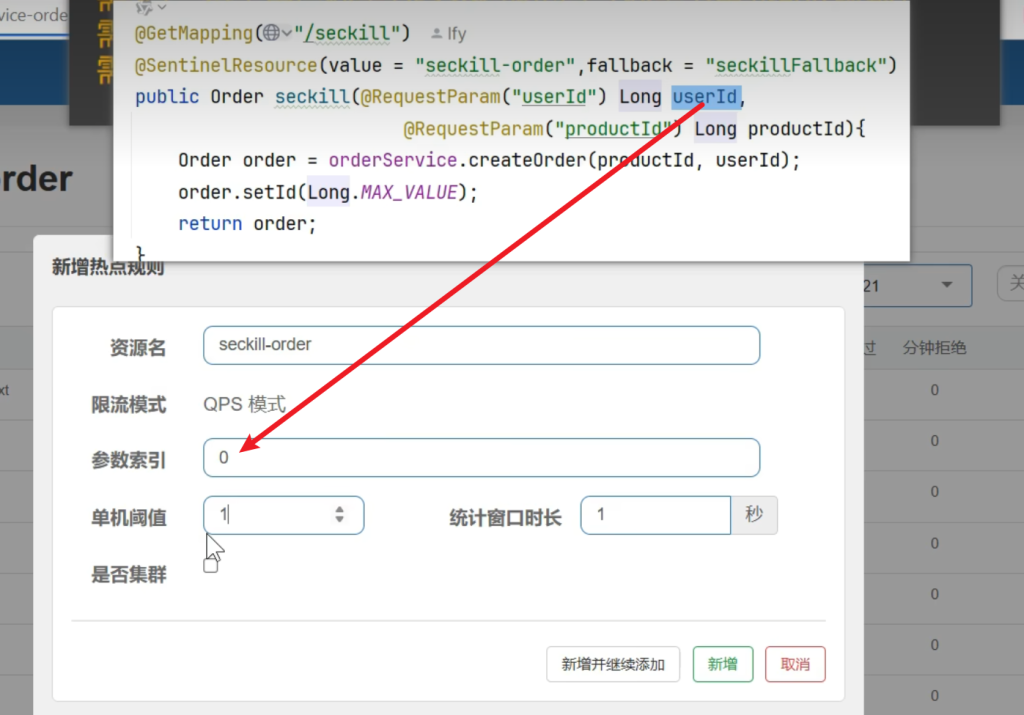
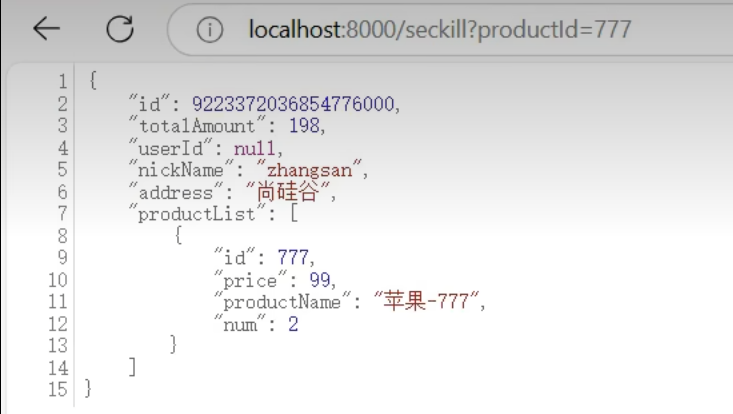
5.8.2为秒杀创建订单添加热点参数规则
需求一
把useId作为参数索引,单机阈值设为1,我无论你userId是几,你每秒都只能有一个
测试需求一
1号用户刷快了被流控
不带userId疯狂刷新不被流控,
总结:需求一,携带此参数的参与流控,不携带不流控
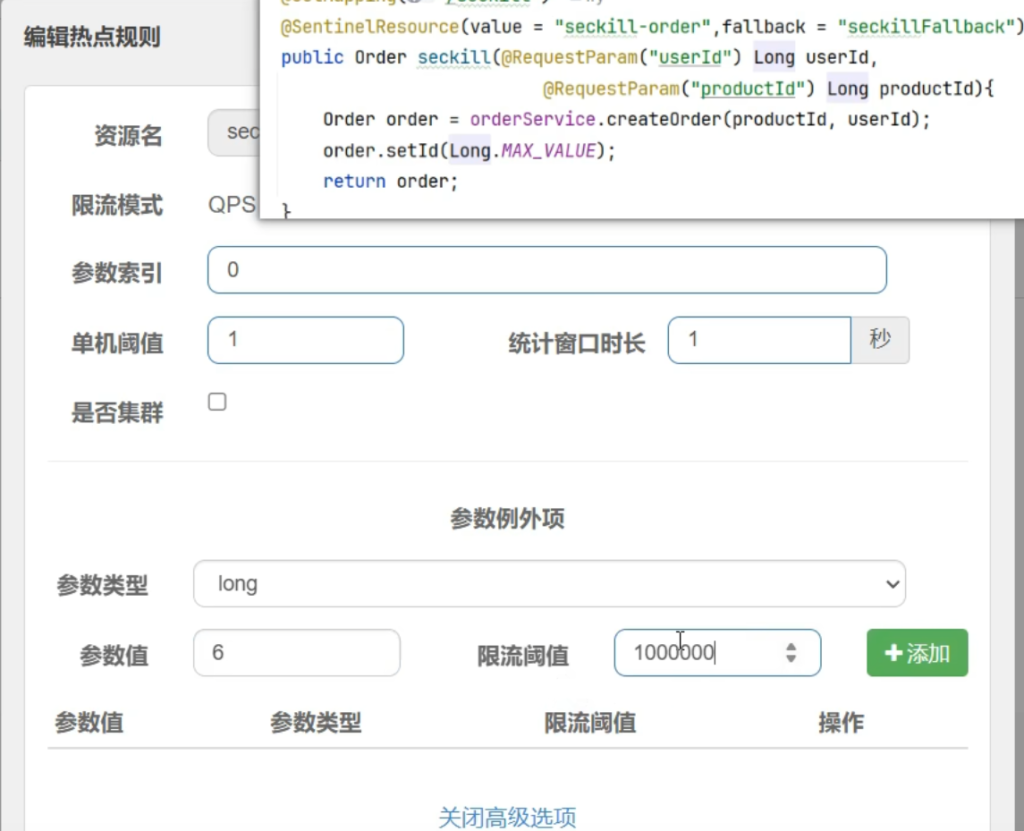
需求二(不限制6号用户)
把6号用户加到参数例外项中
测试需求二:
6号疯狂刷新不被限流
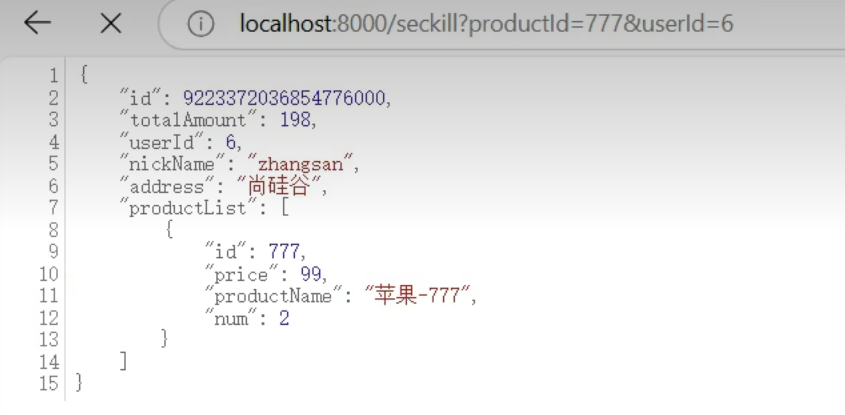
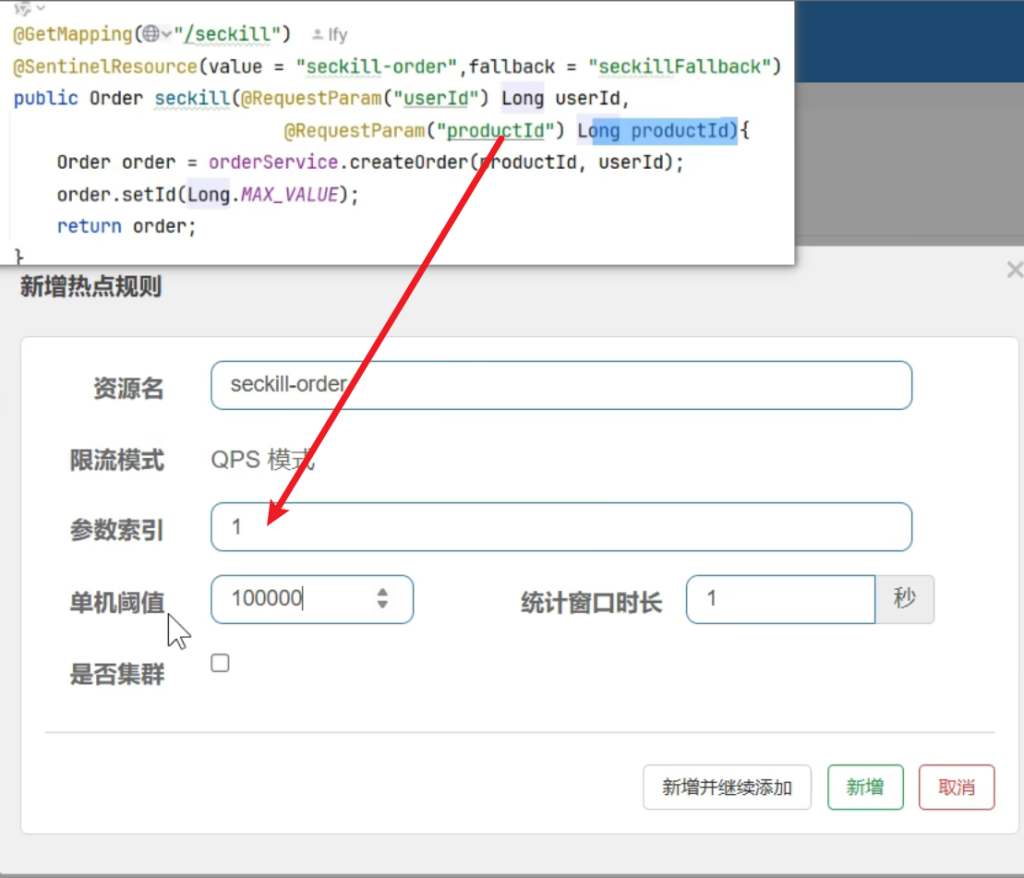
需求三(666号商品下架了,不允许访问)
因为商品ID是第二个参数,这时候我们不能修改以前的热点规则我们只能再创一个热点规则
再编辑这个热点规则,把666号商品ID加到例外项中即可
测试需求三,规则生效,666号商品无法访问,被流控
补充
我们写了兜底回调却没有回调,却返回了默认的错误页面,原因在于兜底回调有两种写法,BlockHandler这个可以专门处理被流控的异常
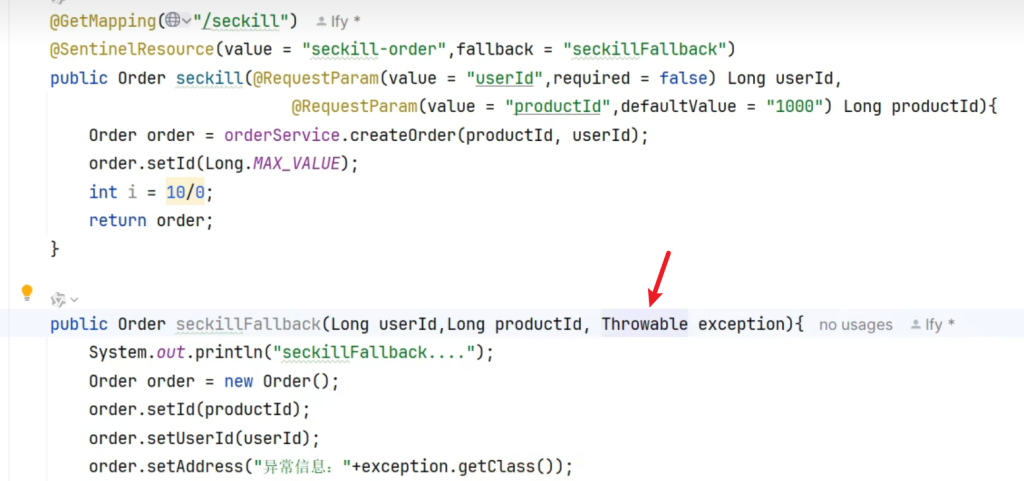
改为blockHandler就可以了
之前我们讲过SentinelResource处理异常的规则是有Block优先用Block,没有指定Block才走fallback,fallback比Block的最大好处就是它还处理业务异常,比如业务期间出现了int i = 10/0,这样的话它就不属于block exception的这种情况我们只需改一下方法签名,就可以处理所有的异常
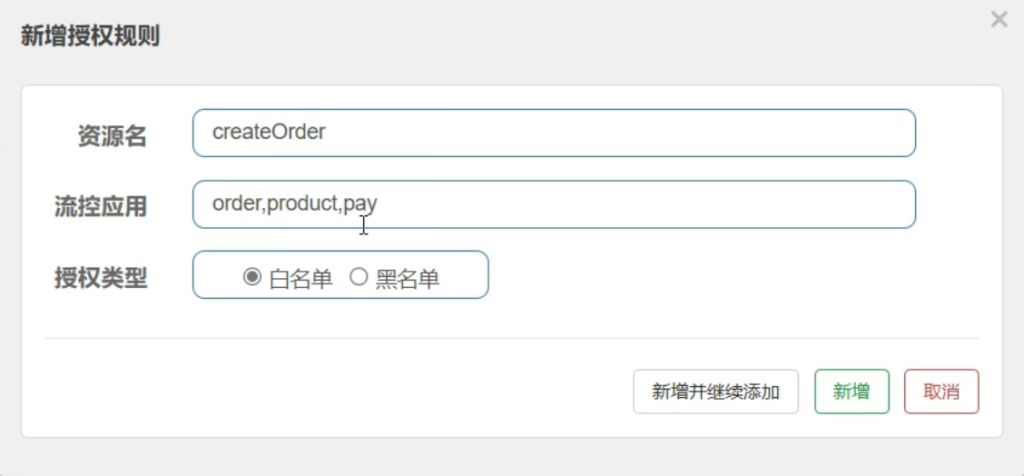
5.9规则-授权规则(很少使用)
指定哪个应用才能访问createOrder这个资源,白名单指仅我列出的可以访问,黑名单相反
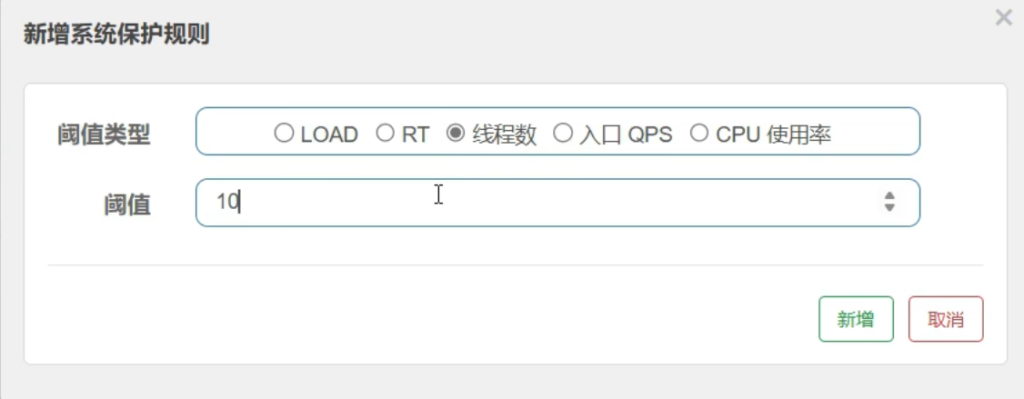
5.10规则-系统规则(很少使用)
举个例子
整个系统后台线程超过10个以后,新来的请求就限制住了
LOAD:系统负载
5.11总结
怎么保证重启规则还在 ?
我们在测试过程中发现我们配的规则一重启就失效,因为Sentinel并没有对这些规则做持久化,数据都是存在内存里边而且是伴随着每一个应用自己存储自己的规则,所以未来Sentinel可以结合Nacos把这些规则配置以后让它存到Nacos,而Nacos又可以连上MySQL数据库,把这些规则最终持久化,最终实现我们配置的规则重启也不丢失
6.Gateway-网关
6.1网关功能
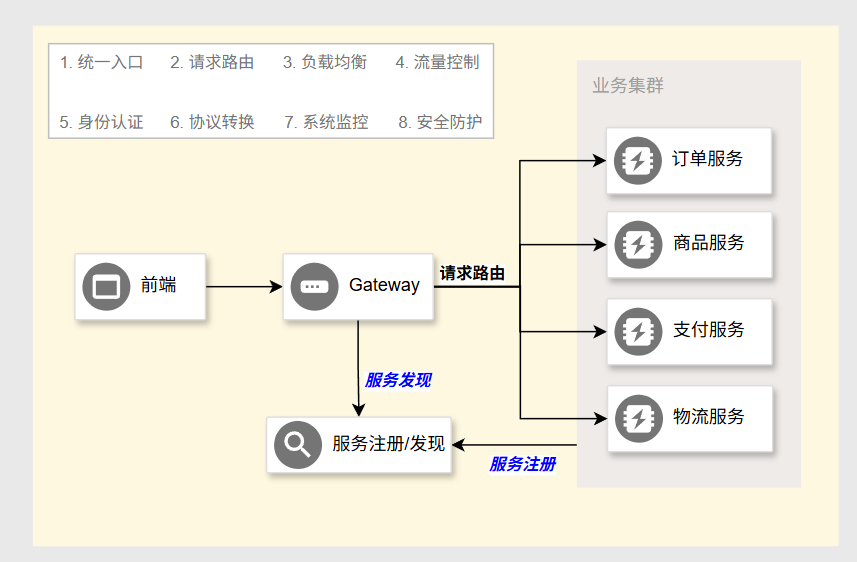
网关在分布式系统中扮演者非常重要的角色,它可以完成众多功能。第一,统一入口,所有请求的流量入口全部都是网关,它就像我们地铁站的安检闸机入口一样。第二,网关可以完成请求路由,交给网关的请求网关会自动判断该给谁,第三,在路由的时候网关也可以融入负载均衡算法,去来均衡集群中每一个服务器的负载量。第四,网关还能做流量控制,像我以前学习的sentinel可以融合到每一个微服务里面去控制微服务的QPS而且它还可以融入网关,由于网关是统一入口,所以一旦跟网关整合以后,可以在入口处对全局的QPS等进行统一限流。第五,网关也可以做一些身份认证,有请求过来以后,网关发现这个是未登录的用户,而我们将要访问你的资源必须登录,那我就可以把这个请求打回,让他重新登录,或者这是一些非法攻击请求,那么就把这些不往后台转了。第六,它也能完成协议转换,比如前端给网关发的请求,带的数据是一个JSON,后台微服务远程调用又需要用到GRPC协议,那网关就可以把这个JSON数据转换为GRPC通用的数据模型再往下转。第七,网关能完成系统监控,由于所有的入口都在这,那我就可以监控每一个请求从收到到结束处理了多长时间去来统计全局的慢请求,去来统计当天的访问总量等等。第八,网关还可以做安全防护,从网关层我们可以配置上一些防止跨站请求伪造,跨站脚本攻击,SQL注入等这些常见的安全问题等等
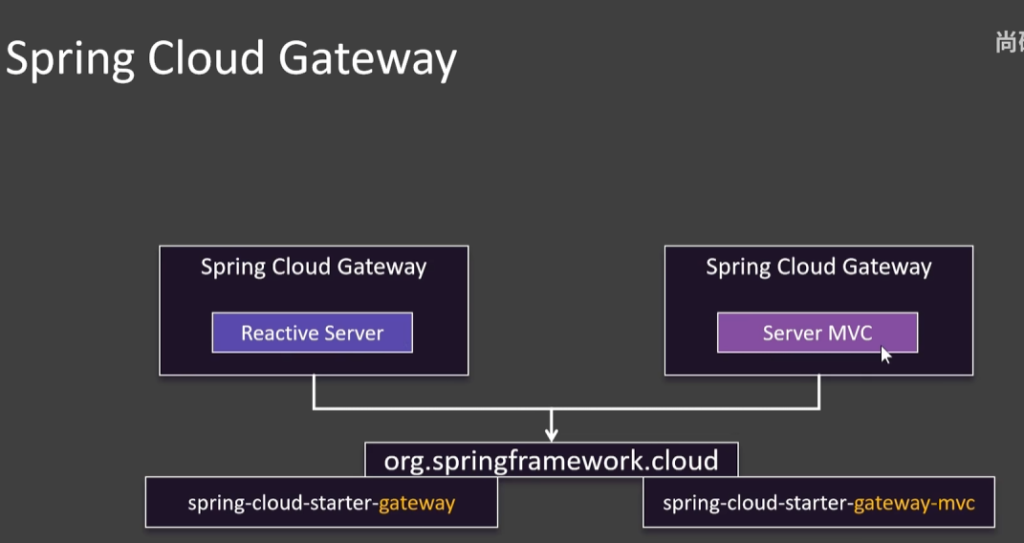
接下来看看Spring Cloud提供的网关
分为两个版本,第一个是基于响应式编程做的网关,它可以占用少量资源,就能实现高并发。第二个是个传统的网关,用的是以前serverlet API这一套,一般后来推荐第一种
6.2创建网关
6.2.1创建项目
6.2.2引入依赖
1 2 3 4 5 6 7 8 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-gateway</artifactId > </dependency > <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-discovery</artifactId > </dependency >
为什么要引入nacos注册中心?
根据网关的原理要做路由转发还需要用到注册中心
6.2.3创建Main方法
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.geqian .gateway ; import org.springframework .boot .SpringApplication ;import org.springframework .boot .autoconfigure .SpringBootApplication ;@EnableDiscoveryClient @SpringBootApplication public class GatewayMainApplication { public static void main (String [] args SpringApplication .run (GatewayMainApplication .class , args); } }
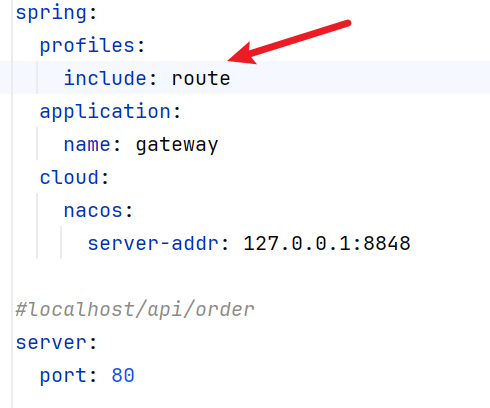
配置application.yml
1 2 3 4 5 6 7 8 9 10 spring : application : name : gateway cloud : nacos : server-addr : 127.0.0.1:8848 server : port : 80
网关在nacos里面已经注册上来了
6.3网关配置规则
两种方式:1.在配置文件里配置 2使用编码的方式编写路由规则 这里我们演示第一种
用配置文件配置规则
重新建一个application-route.yml,记得在application.yml引入
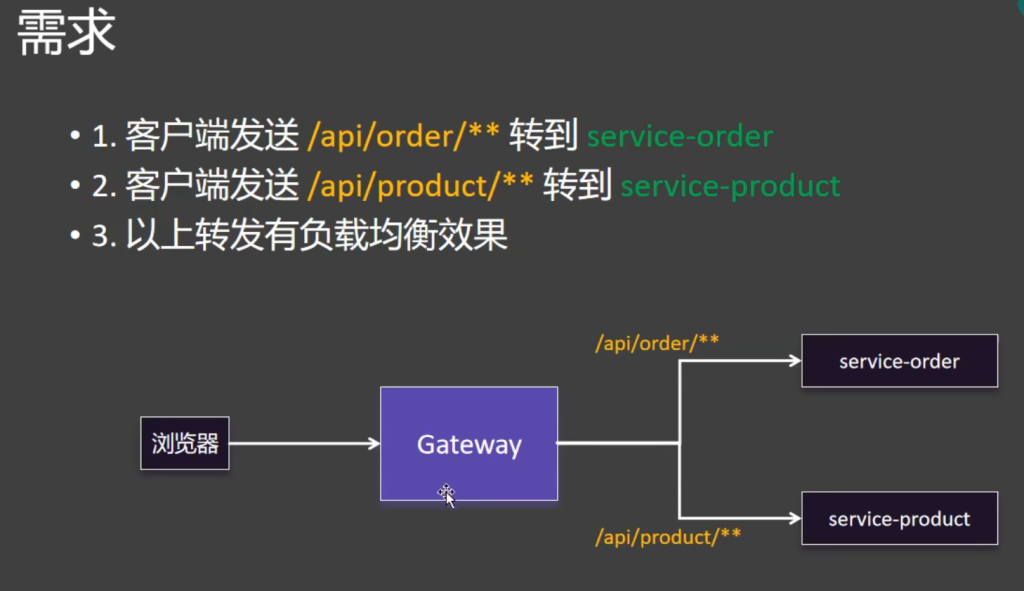
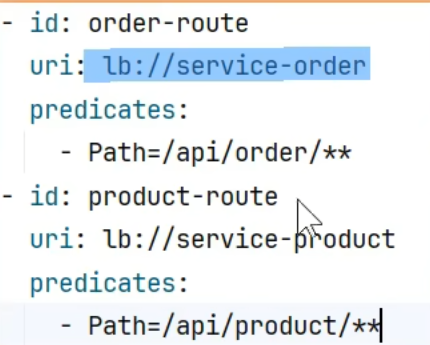
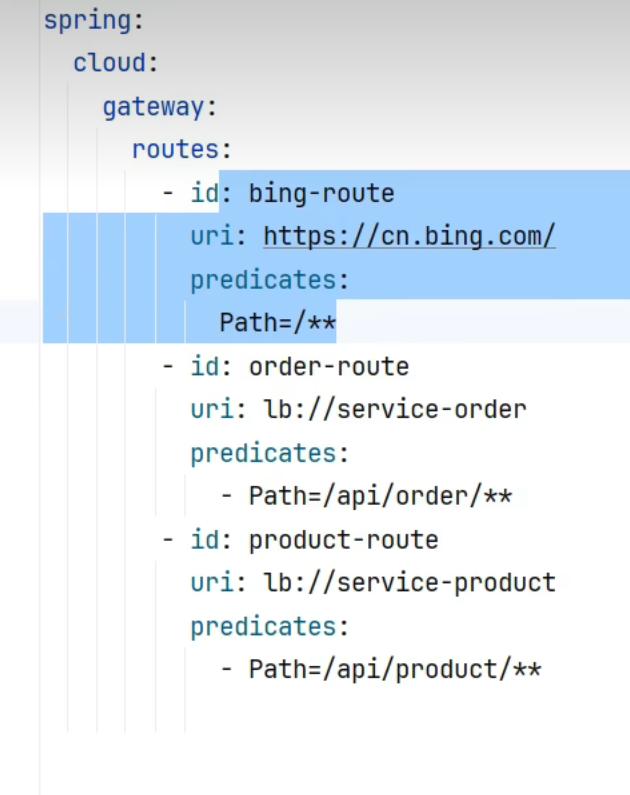
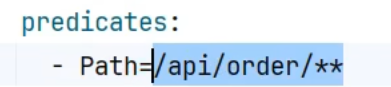
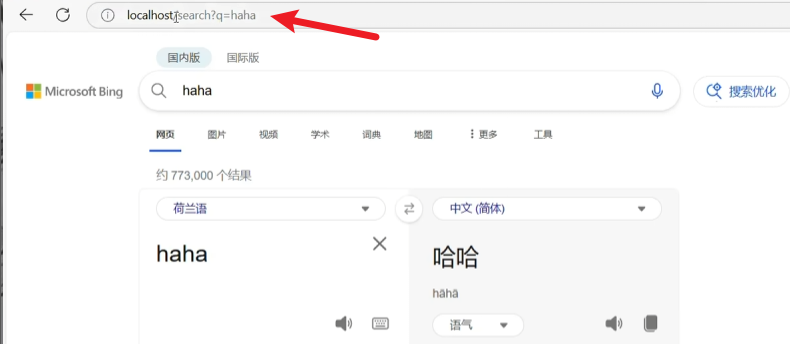
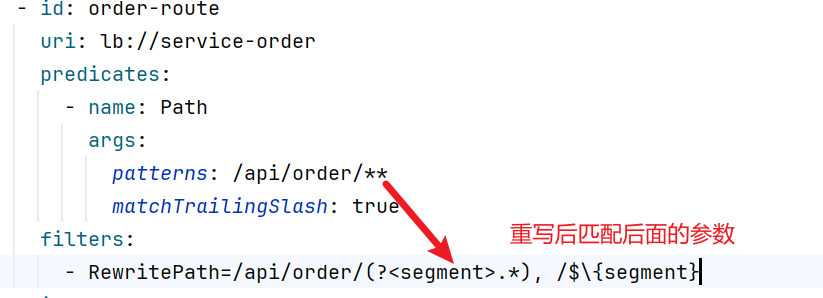
1 2 3 4 5 6 7 8 9 10 11 12 spring : cloud : gateway : routes : - id: order-route uri : lb://service-order predicates : - Path=/api/order/** - id: product-route uri : lb://service-product predicates : - Path=/api/product/**
id就是给这个路由起个名字就叫order-route
uri,要把请求转给哪里 lb是load balancer的缩写代表着负载均衡,也就是接下来负载均衡的转给service-order(微服务名)
predicates(断言)定义了你遵循哪个规则时转
第一规则叫路径,如果你以api/order请求开头的所有请求我都转个server-order这个微服务
这里是可以写的更多的扩展配置
注意一个坑点:由于SpringCloud新版将负载均衡单独抽取了出来,因此还要单独引入负载均衡的依赖
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-loadbalancer</artifactId > </dependency >
在OrderController加入@RequestMapping(“/api/order”),代表这个类以后所有请求都以api/order开始,同样的商品服务和ProductFeignClient都加上@RequestMapping(“/api/product”)
我们刷新4次,发现8000端口调用2次,8001端口调用2次,符合负载均衡的要求
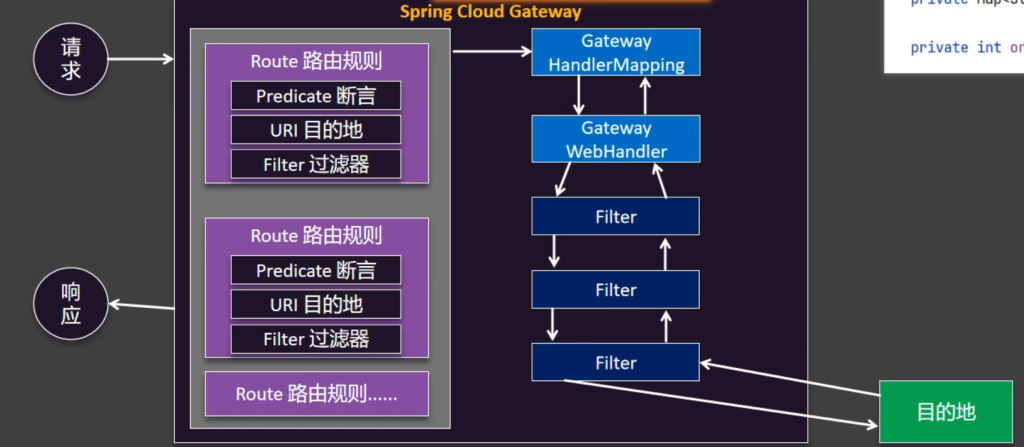
6.4路由的基础原理
简述一下流程:当请求交给网关,网关先在它的路由表规则里边使用断言机制进行匹配,匹配到哪个规则就按照这个规则把请求准备转给指定的目的地,但是在转之前,它再会拿到这个规则配置的所有Filter,底层是通过这两个组件进行配合,网关里边有一个Handler Mapping 称为请求映射,在Handler Mapping 里边它知道某些规则要转给哪,但是怎么转它又会使用一个WebHandler叫处理器,处理器就会调用整个Filter链路把请求挨个转下去,因为请求和响应是一个双向关系,所以请求往下转的时候先经过Filter的前置方法转给目的地,目的地处理完了以后把响应交给网关,再倒序经过每一个Filter最终把响应交给指定的客户端
🔁 Spring Cloud Gateway 的请求处理流程梳理:
1️⃣ 请求进入网关
客户端发出请求,请求首先被 Spring Cloud Gateway 接收到。
2️⃣ 网关根据路由规则匹配请求
网关内部维护了一张 路由规则表 (Route):
每条规则包含三部分:
Predicate(断言) :判断请求是否匹配,比如路径是否是 /user/**URI(目的地) :匹配成功后请求要转发到哪里Filter(过滤器) :请求经过的拦截处理器,比如鉴权、日志、限流等
✅ 匹配成功后,网关准备把请求转发到目的地。
3️⃣ HandlerMapping 与 WebHandler 协作处理
这两个是网关的底层组件:
HandlerMapping :根据请求匹配路由规则WebHandler :根据匹配的规则执行请求转发和过滤器调用
4️⃣ 请求流经 Filter 链(过滤器链)
Filter 有两个阶段:
前置处理(pre) :在转发前做事情(如鉴权、限流、修改请求头等)后置处理(post) :响应返回时再做事(如日志、加密响应数据等)
整个过程像“洋葱模型”一样包裹处理:
请求流经所有 Filter → 到达目的服务;
响应回来时,再反向流经所有 Filter → 返回客户端。
5️⃣ 响应返回客户端
目的服务处理完请求,返回响应,经过 Filter 链倒序处理,最后交回给客户端。
总结一句话:
Spring Cloud Gateway 会先匹配路由规则 → 执行过滤器链 → 将请求转发到目标服务 ,响应回来的时候再倒序通过过滤器 返回给客户端。
理解一下拦截器的作用
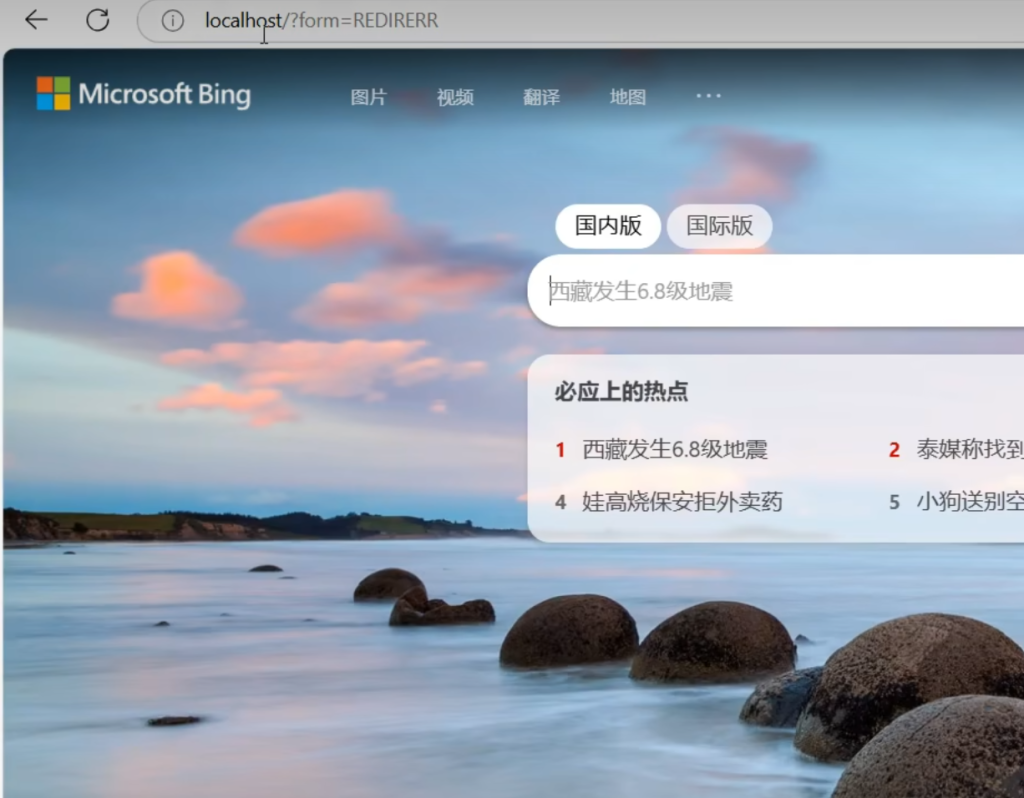
由于是按照顺序匹配,即使此时我们给订单发请求,也会被第一个规则所拦截,直接访问到了第一个bing的目的地
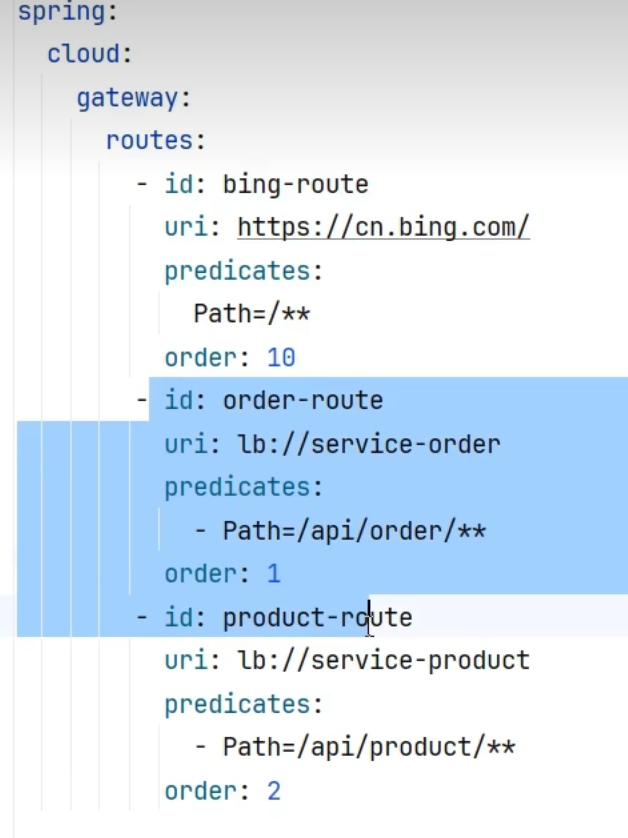
为了解决顺序这个问题我们可以加入order这个项,order越小优先级越高
此时请求就又能转给Db了
6.5断言
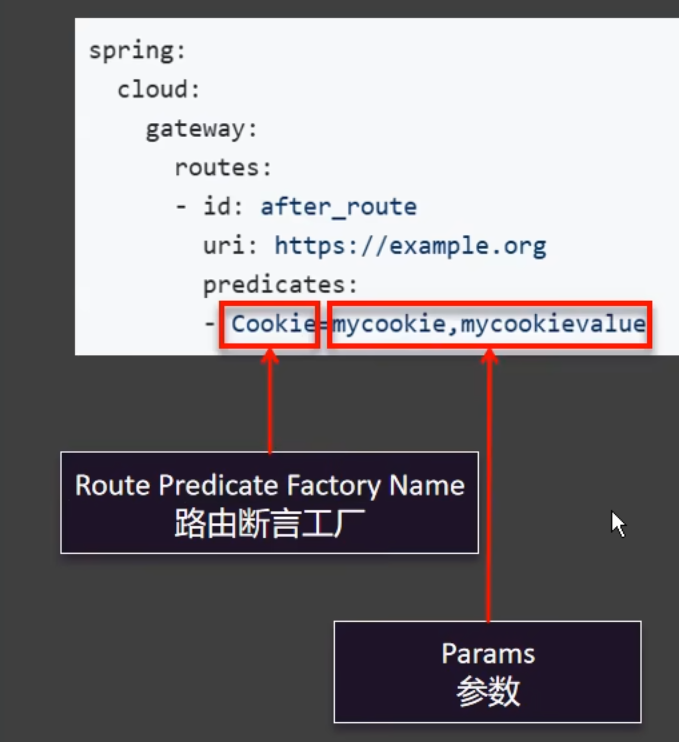
6.5.1断言的写法
断言的写法有两种短写法和全写法
短写法:
全写法:
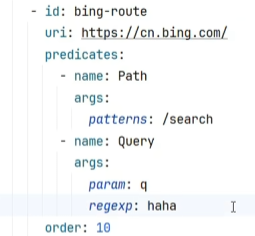
把短写法改造为全写法
1 2 3 4 5 6 - Path=/api/order/** predicates : - name: Path args : patterns : /api/order/** matchTrailingSlash : true
pattern:规则,满足什么规则?
matchTrailingSlash:默认为true,表示匹配后面的/,例如/red/1和/red/1/是同一个路径,当false时表示是不同的路径
6.5.2断言规则
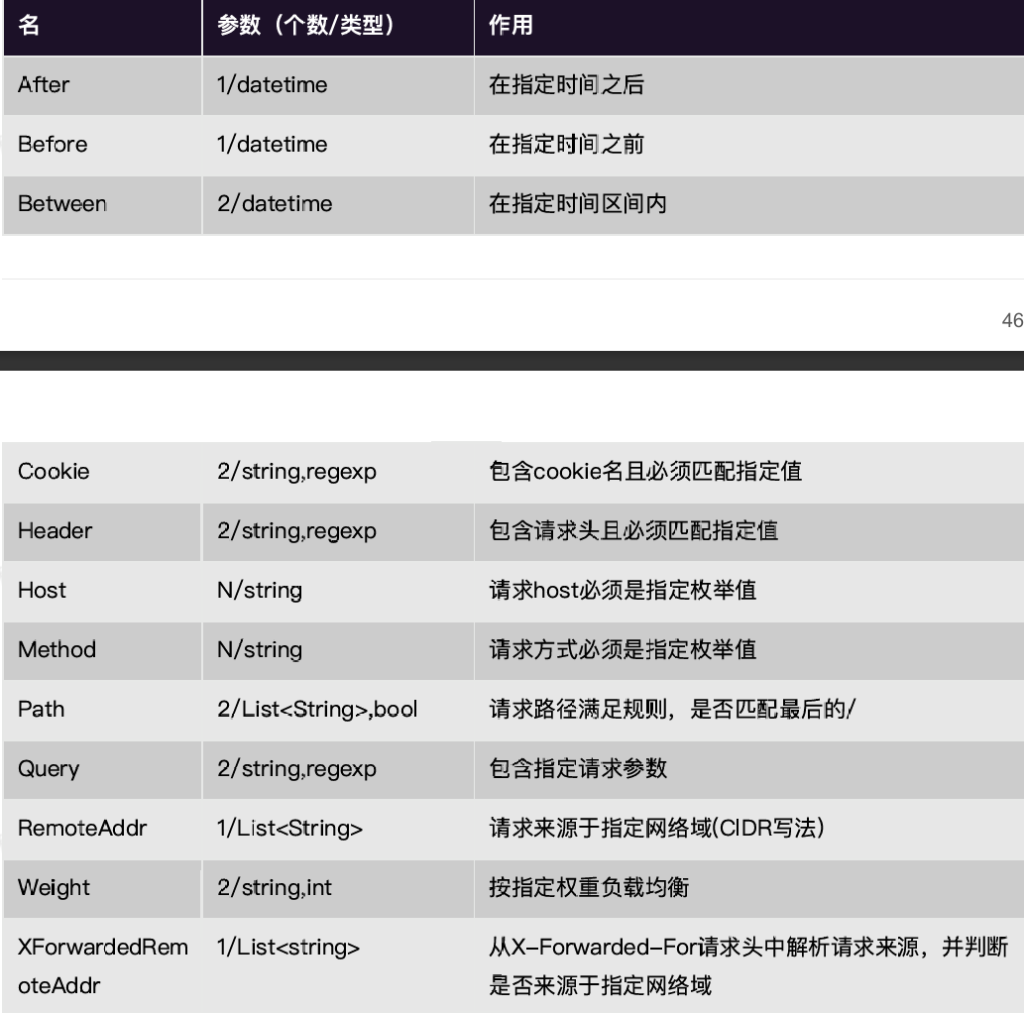
有多少种断言机制?
每一个在官方文档都有详细的示例,这里只演示一个Query
当每个规则都匹配时网关才能把请求转给bing
6.5.3自定义断言工厂
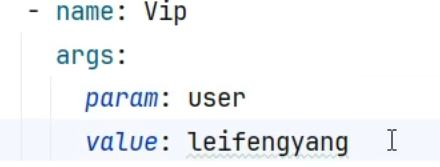
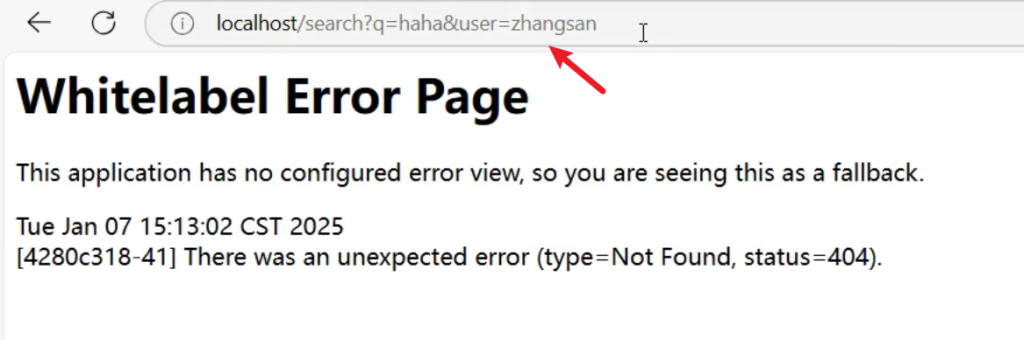
需求:Vip 用户才能访问
代码仿照原有的断言源码(用AI写)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package com.atguigu .gateway .predicate ; import jakarta.validation .constraints .NotEmpty ;import org.springframework .cloud .gateway .handler .predicate .AbstractRoutePredicateFactory ;import org.springframework .cloud .gateway .handler .predicate .GatewayPredicate ;import org.springframework .cloud .gateway .handler .predicate .QueryRoutePredicateFactory ;import org.springframework .http .server .reactive .ServerHttpRequest ;import org.springframework .stereotype .Component ;import org.springframework .util .StringUtils ;import org.springframework .validation .annotation .Validated ;import org.springframework .web .server .ServerWebExchange ;import java.util .Arrays ;import java.util .List ;import java.util .function .Predicate ;@Component public class VipRoutePredicateFactory extends AbstractRoutePredicateFactory <VipRoutePredicateFactory .Config > { public VipRoutePredicateFactory () { super (Config .class ); } @Override public Predicate <ServerWebExchange > apply (Config config return new GatewayPredicate () { @Override public boolean test (ServerWebExchange serverWebExchange ServerHttpRequest request = serverWebExchange.getRequest (); String first = request.getQueryParams ().getFirst (config.param ); return StringUtils .hasText (first) && first.equals (config.value ); } }; } @Override public List <String > shortcutFieldOrder ( return Arrays .asList ("param" , "value" ); } @Validated public static class Config { @NotEmpty private String param; @NotEmpty private String value; public @NotEmpty String getParam ( return param; } public void setParam (@NotEmpty String param this .param = param; } public @NotEmpty String getValue ( return value; } public void setValue (@NotEmpty String value this .value = value; } } }
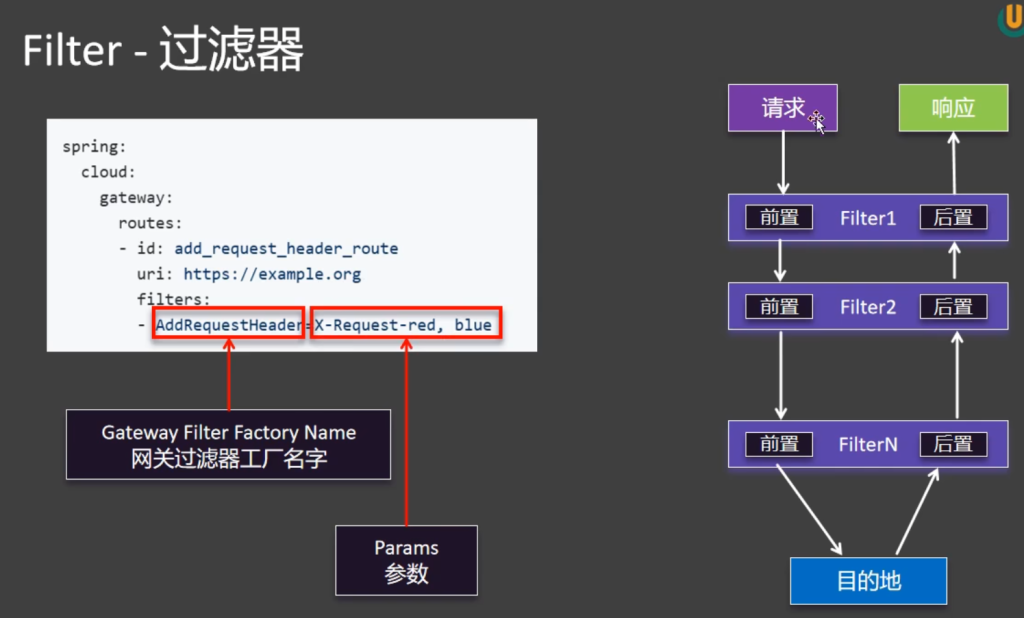
6.6Filter-过滤器
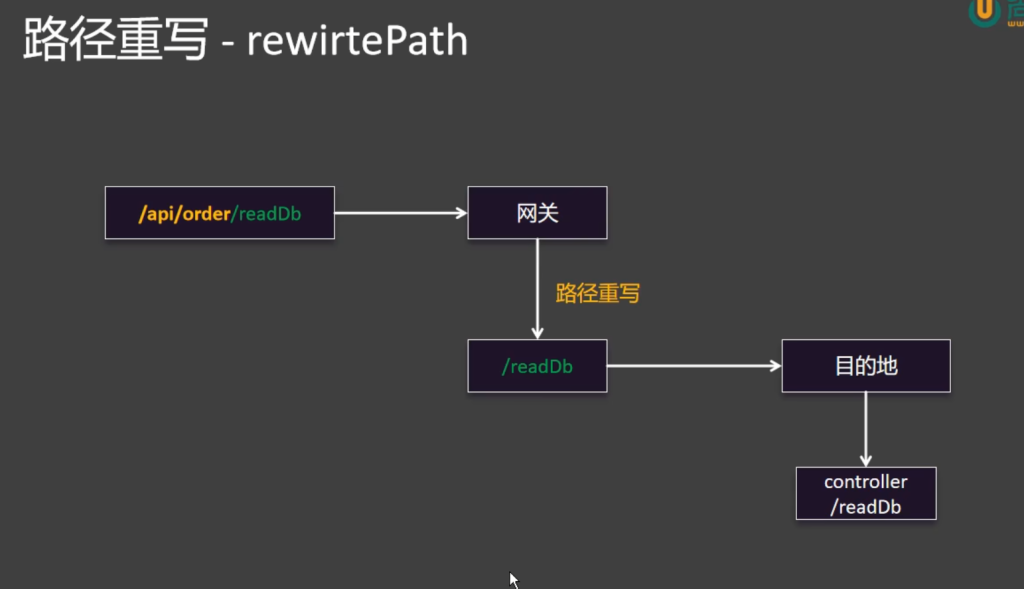
6.6.1路径重写Filter
之前每个controller上加@RequestMapping(“/api/order”)有点麻烦,这里可以通过路径重写来解决这个问题,在配置文件中来加过滤器
这样配置后就不用加基准路径@RequestMapping(“/api/order”)了
6.6.2过滤规则
6.6.3默认Filter
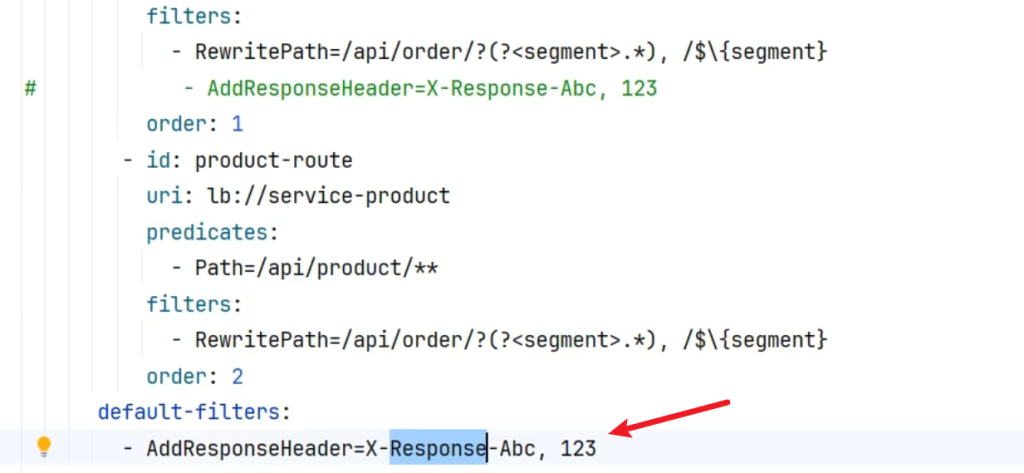
default-filters
加入默认Filter后商品虽然没有AddResponseHeader这个规则,但也会生效
6.6.4Global Filters
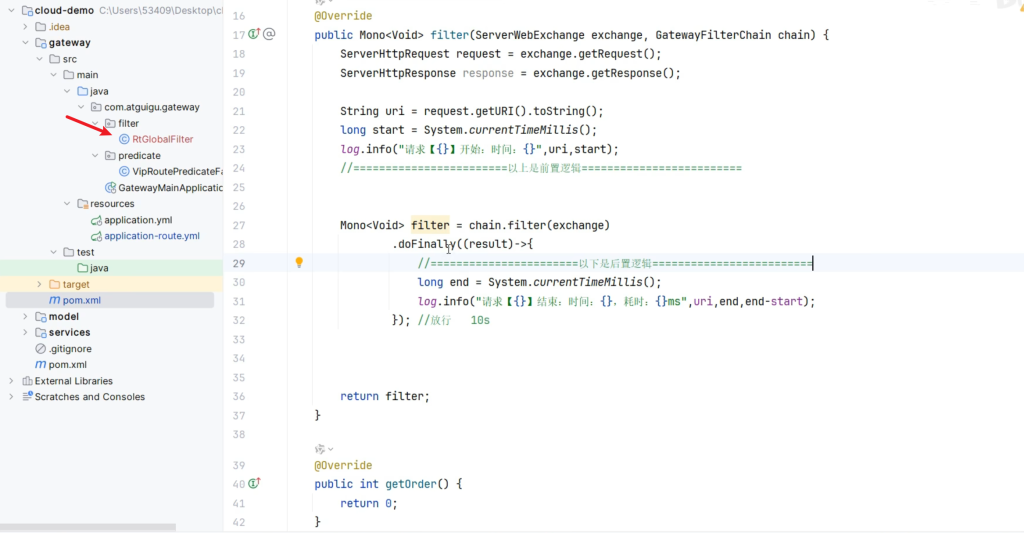
为响应时间写一个全局的Filter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.atguigu.gateway.filter ; import lombok.extern.slf4j.Slf4j;import org.springframework.cloud.gateway.filter .GatewayFilterChain;import org.springframework.cloud.gateway.filter .GlobalFilter;import org.springframework.core.Ordered;import org.springframework.http.server .reactive.ServerHttpRequest;import org.springframework.http.server .reactive.ServerHttpResponse;import org.springframework.stereotype.Component;import org.springframework.web.server .ServerWebExchange;import reactor.core.publisher.Mono;@Component @Slf4j public class RtGlobalFilter implements GlobalFilter, Ordered { @Override public Mono<Void > filter (ServerWebExchange exchange, GatewayFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); ServerHttpResponse response = exchange.getResponse(); String uri = request.getURI().toString(); long start = System .currentTimeMillis(); log .info ("请求【{}】开始:时间:{}",uri,start ); //========================以上是前置逻辑========================= Mono<Void > filter = chain.filter (exchange) .doFinally((result)->{ //=======================以下是后置逻辑========================= long end = System .currentTimeMillis(); log .info ("请求【{}】结束:时间:{},耗时:{}ms",uri,end ,end -start ); }); //放行 10 s return filter ; } @Override public int getOrder() { return 0 ; } }
6.6.5自定义过滤器工厂
代码仿照原有的断言源码(用AI写)
自定义的过滤器名字是方法的前缀
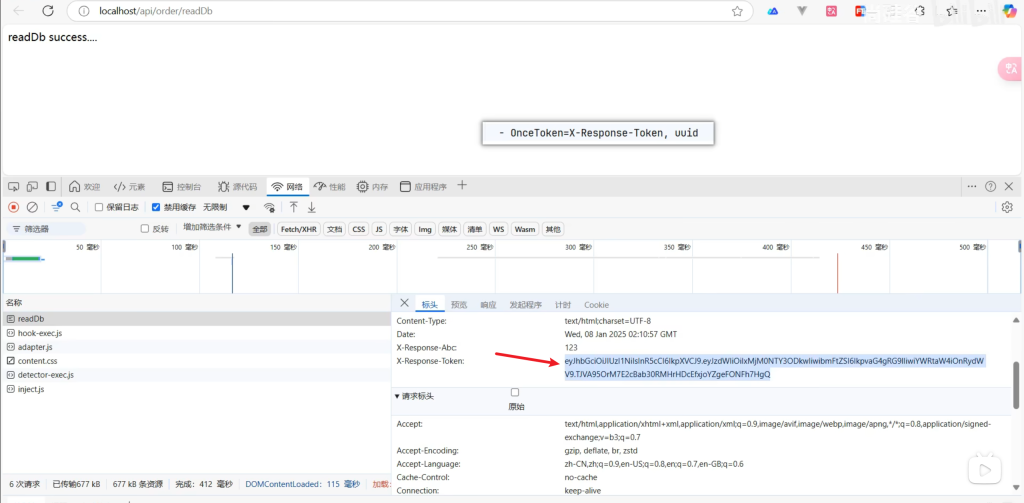
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.atguigu.gateway.filter;import org.springframework.cloud.gateway.filter.GatewayFilter;import org.springframework.cloud.gateway.filter.GatewayFilterChain;import org.springframework.cloud.gateway.filter.factory.AbstractNameValueGatewayFilterFactory;import org.springframework.http.HttpHeaders;import org.springframework.http.server.reactive.ServerHttpResponse;import org.springframework.stereotype.Component;import org.springframework.web.server.ServerWebExchange;import reactor.core.publisher.Mono;import java.util.UUID;@Component public class OnceTokenGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory { @Override public GatewayFilter apply (NameValueConfig config) { return new GatewayFilter () { @Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) { return chain.filter(exchange).then(Mono.fromRunnable(()->{ ServerHttpResponse response = exchange.getResponse(); HttpHeaders headers = response.getHeaders(); String value = config.getValue(); if ("uuid" .equalsIgnoreCase(value)){ value = UUID.randomUUID().toString(); } if ("jwt" .equalsIgnoreCase(value)){ value = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ" ; } headers.add(config.getName(),value); })); } }; } }
6.7跨域(CORS)配置
6.7.1全局跨域
1 2 3 4 5 6 7 8 9 spring : cloud : gateway : globalcors : cors-configurations : '[/**]' : allowed-origin-patterns : '*' allowed-headers : '*' allowed-methods : '*'
6.7.2局部跨域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 spring: cloud: gateway: routes: - id: cors_route uri: https: predicates: - Path = /service/ ** metadata: cors: allowedOrigins: '*' allowedMethods: - GET - POST allowedHeaders: '*' maxAge: 30
6.8总结
面试题:微服务之间的调用经过网关吗?
不经过,但如果你想要过网关也是可以实现的(不建议)
微服务之间的调用 是否经过网关,要看具体的业务场景和架构设计。
🔹 通常情况下,网关主要用于外部客户端访问微服务 ,作为统一入口,提供鉴权、路由、限流、日志等功能。
🔹 微服务之间的内部调用(服务与服务之间),一般不会经过网关 ,而是通过 服务注册与发现 (如 Nacos、Eureka)加上 负载均衡组件 (如 Ribbon、Feign、RestTemplate)进行直连调用,效率更高、开销更小。
当然,如果企业对 链路监控、安全控制 有统一规范,也可能让微服务间的调用也经过网关,但这并不常见,会带来额外的网络和性能开销。
7.Seata-分布式事务
官⽹:https://seata.apache.org/zh-cn/
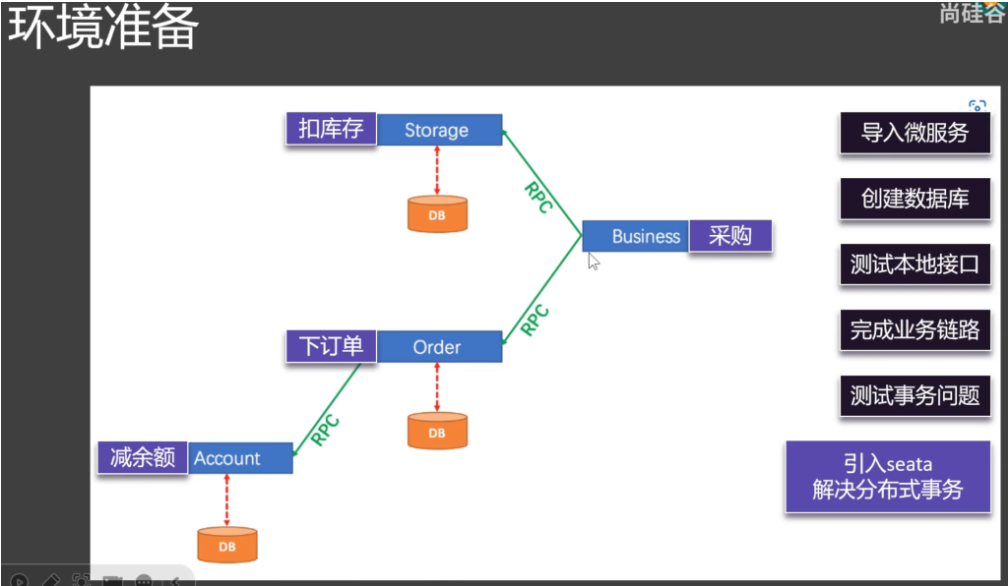
7.1环境准备
下载 seata ⼯程⽂件,导⼊到项⽬中,并在services中添加module聚合
导入SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 CREATE DATABASE IF NOT EXISTS `storage_db`; USE `storage_db`; DROP TABLE IF EXISTS `storage_tbl`; CREATE TABLE `storage_tbl` ( `id` int(11 ) NOT NULL AUTO_INCREMENT, `commodity_code` varchar(255 ) DEFAULT NULL, `count` int(11 ) DEFAULT 0 , PRIMARY KEY (`id`), UNIQUE KEY (`commodity_code`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 INSERT INTO storage_tbl (commodity_code, count) VALUES ('P0001', 100 ) INSERT INTO storage_tbl (commodity_code, count) VALUES ('B1234', 10 ) -- 注意此处0.3 .0 + 增加唯一索引 ux_undo_log DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20 ) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20 ) NOT NULL, `xid` varchar(100 ) NOT NULL, `context` varchar(128 ) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11 ) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100 ) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 CREATE DATABASE IF NOT EXISTS `order_db`; USE `order_db`; DROP TABLE IF EXISTS `order_tbl`; CREATE TABLE `order_tbl` ( `id` int(11 ) NOT NULL AUTO_INCREMENT, `user_id` varchar(255 ) DEFAULT NULL, `commodity_code` varchar(255 ) DEFAULT NULL, `count` int(11 ) DEFAULT 0 , `money` int(11 ) DEFAULT 0 , PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 -- 注意此处0.3 .0 + 增加唯一索引 ux_undo_log DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20 ) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20 ) NOT NULL, `xid` varchar(100 ) NOT NULL, `context` varchar(128 ) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11 ) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100 ) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 CREATE DATABASE IF NOT EXISTS `account_db`; USE `account_db`; DROP TABLE IF EXISTS `account_tbl`; CREATE TABLE `account_tbl` ( `id` int(11 ) NOT NULL AUTO_INCREMENT, `user_id` varchar(255 ) DEFAULT NULL, `money` int(11 ) DEFAULT 0 , PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 INSERT INTO account_tbl (user_id, money) VALUES ('1 ', 10000 ) -- 注意此处0.3 .0 + 增加唯一索引 ux_undo_log DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20 ) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20 ) NOT NULL, `xid` varchar(100 ) NOT NULL, `context` varchar(128 ) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11 ) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100 ) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
7.2打通远程链路
1.扣减库存
StorageFeignClient中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com .atguigu .business .feign ;import org .springframework .cloud .openfeign .FeignClient ;import org .springframework .web .bind .annotation .GetMapping ;import org .springframework .web .bind .annotation .RequestParam ;@FeignClient (value = "seata-storage" ) public interface StorageFeignClient { @GetMapping ("/deduct" ) String deduct (@RequestParam ("commodityCode" ) String commodityCode, @RequestParam ("count" ) Integer count); }
BusinessService
1 2 3 4 5 6 7 8 9 10 11 12 package com.atguigu.business.service;public interface BusinessService void purchase (String userId, String commodityCode, int orderCount) }
BusinessServiceImpl
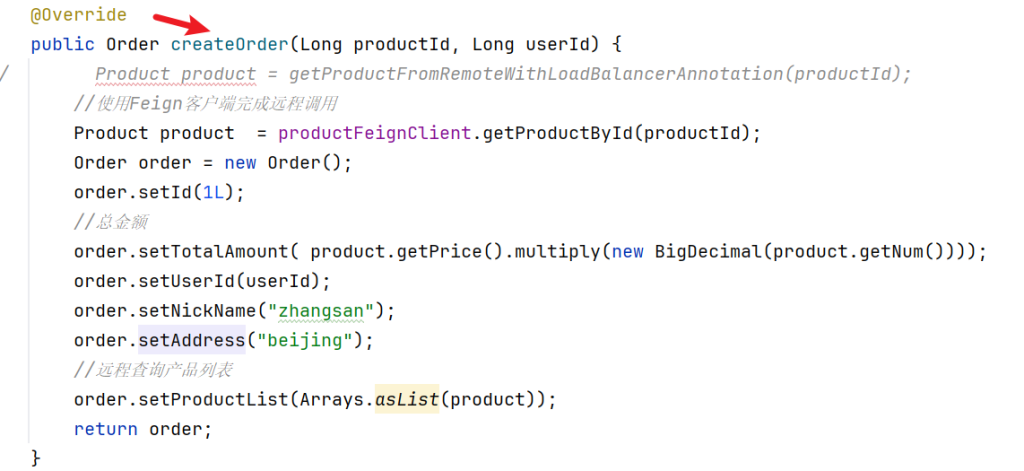
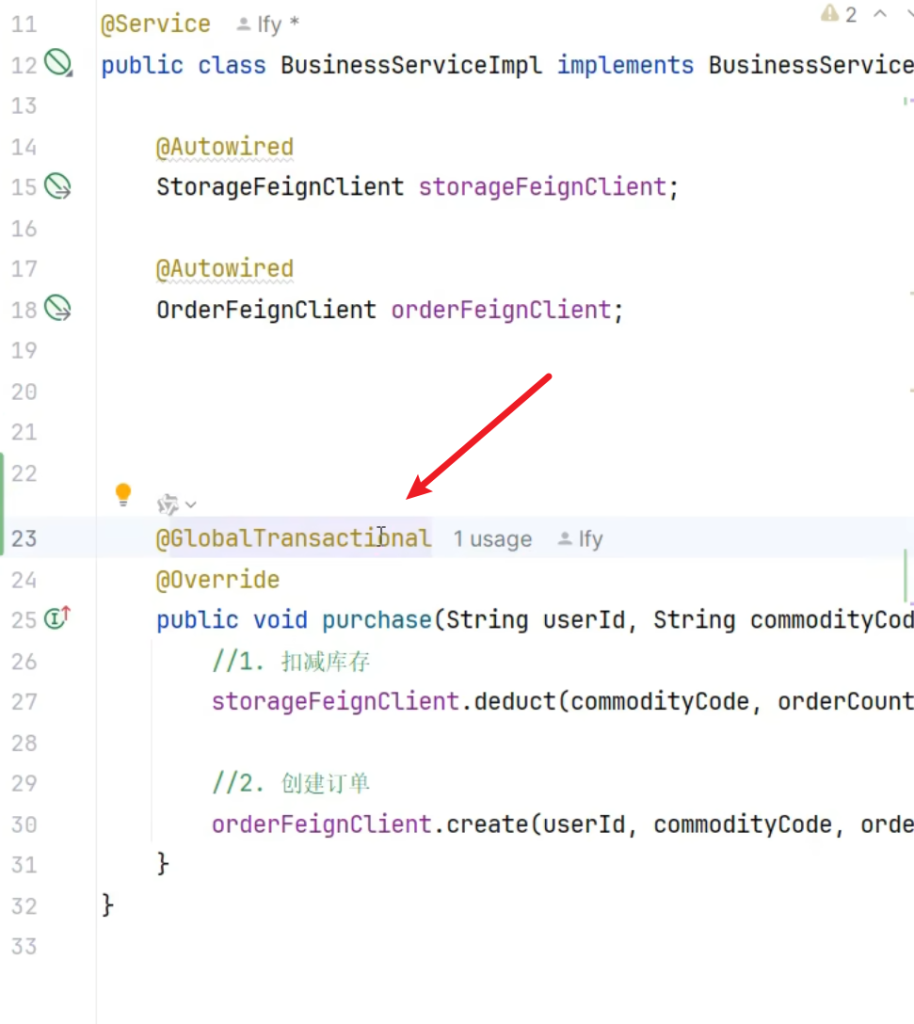
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.atguigu.business.service.impl;import com.atguigu.business.feign.OrderFeignClient;import com.atguigu.business.feign.StorageFeignClient;import com.atguigu.business.service.BusinessService;import org.apache.seata.spring.annotation.GlobalTransactional;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;@Service public class BusinessServiceImpl implements BusinessService @Autowired StorageFeignClient storageFeignClient; @Autowired OrderFeignClient orderFeignClient; @GlobalTransactional @Override public void purchase(String userId, String commodityCode, int orderCount) { storageFeignClient.deduct(commodityCode, orderCount); orderFeignClient.create(userId, commodityCode, orderCount); } }
2.创建订单
OrderFeignClient中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com .atguigu .business .feign ;import org .springframework .cloud .openfeign .FeignClient ;import org .springframework .web .bind .annotation .GetMapping ;import org .springframework .web .bind .annotation .RequestParam ;@FeignClient (value = "seata-order" ) public interface OrderFeignClient { @GetMapping ("/create" ) String create (@RequestParam ("userId" ) String userId, @RequestParam ("commodityCode" ) String commodityCode, @RequestParam ("count" ) int orderCount); }
3.减余额
AccountFeignClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com .atguigu .order .feign ;import org .springframework .cloud .openfeign .FeignClient ;import org .springframework .web .bind .annotation .GetMapping ;import org .springframework .web .bind .annotation .RequestParam ;@FeignClient (value = "seata-account" ) public interface AccountFeignClient { @GetMapping ("/debit" ) String debit (@RequestParam ("userId" ) String userId, @RequestParam ("money" ) int money); }
OrderServiceImpl
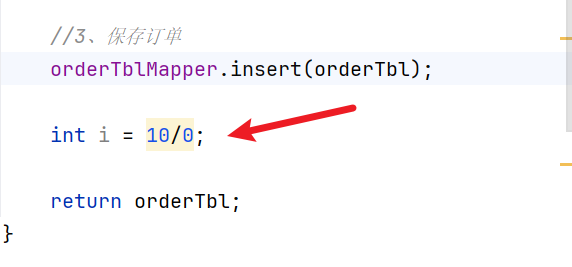
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.atguigu.order.service.impl;import com.atguigu.order.bean.OrderTbl;import com.atguigu.order.feign.AccountFeignClient;import com.atguigu.order.mapper.OrderTblMapper;import com.atguigu.order.service.OrderService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;@Service public class OrderServiceImpl implements OrderService { @Autowired OrderTblMapper orderTblMapper; @Autowired AccountFeignClient accountFeignClient; @Transactional @Override public OrderTbl create (String userId, String commodityCode, int orderCount) { int orderMoney = calculate(commodityCode, orderCount); accountFeignClient.debit(userId, orderMoney); OrderTbl orderTbl = new OrderTbl (); orderTbl.setUserId(userId); orderTbl.setCommodityCode(commodityCode); orderTbl.setCount(orderCount); orderTbl.setMoney(orderMoney); orderTblMapper.insert(orderTbl); int i = 10 /0 ; return orderTbl; } private int calculate (String commodityCode, int orderCount) { return 9 *orderCount; } }
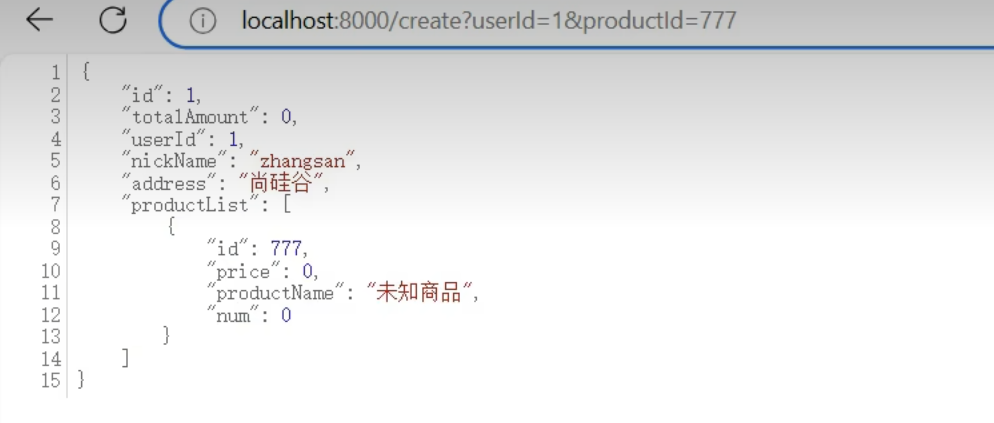
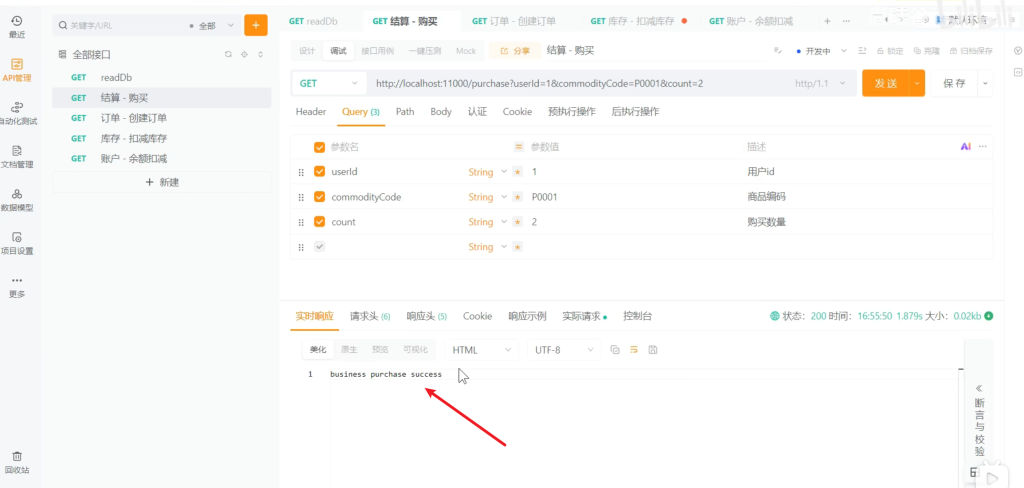
测试:下一个订单
去表里看一下,发现库存扣了2个,账户余额减了18,远程调用链是通的
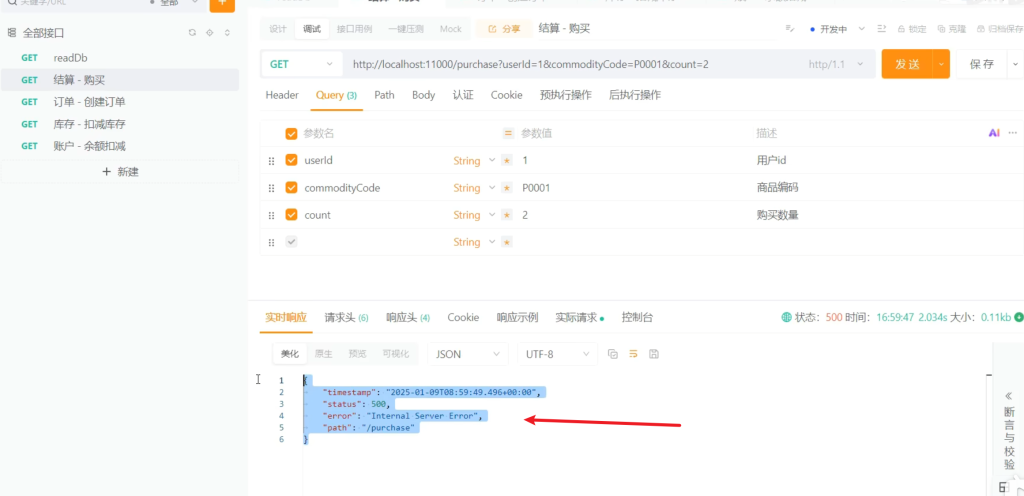
但是如果在最后一步加入一个异常,创建订单时没有成功,但发现库存扣了,余额也扣了即部分回滚,这便是分布式系统下出现的分布式事务没有一起提交没有一起回滚出现的数据不一致问题
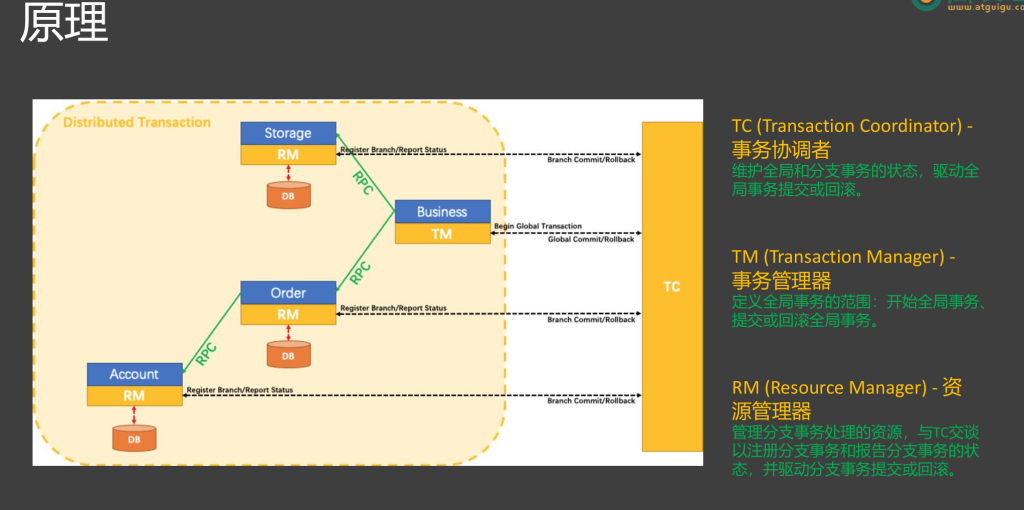
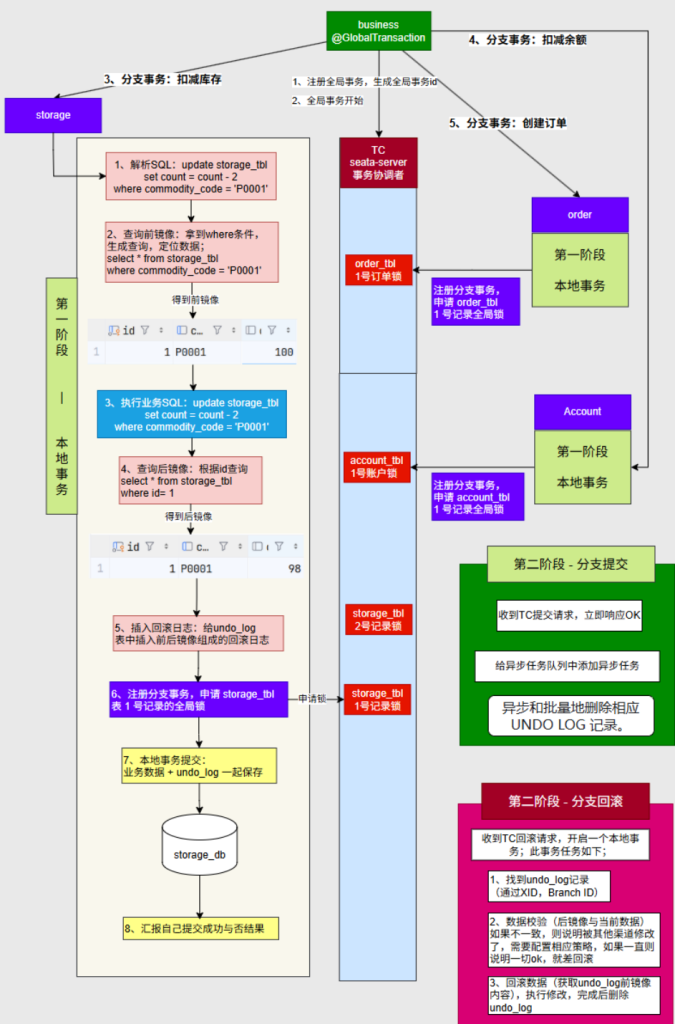
7.3架构原理(Seata 的分布式事务处理原理 )
TC:相当于项目经理,TC去来感知全局事务和分支事务的状态,基于它们的状态,然后驱动谁来提交,谁来回滚,TC是一个中间件,需要下载TC服务器启动起来
管理所有事务(全局 + 分支)状态;
决定:谁提交、谁回滚;
是一个中间件,需要独立部署;
所有 RM、TM 都要和 TC 通信。
TM:负责发起任务,开启全局事务,全局事务要调用每一个微服务,做自己的分支事情
是全局事务的发起者;
一般存在于业务服务 (如:下单服务、支付服务)中;
负责:
开启一个 全局事务 ;
调用多个子服务(每个服务执行自己的“分支事务”);
最终由 TC 统一控制提交或回滚。
RM:每一个微服务里面去控制事务的在Seata中称为RM资源管理器,只管理自己的资源,它的作用就是处理好它的分支事务,它分支事务的提交回滚都是RM来做,RM也要跟TC及时通信,去来及时的报告它的事务状态,方便TC进行总体管控
每个微服务里负责自己的本地数据库事务 ;
与 TC 通信:
接收 TC 的命令:提交 or 回滚分支事务 ;
通过 undo_log 实现回滚(哪怕之前已经提交,也能改回来)。
简述一下流程:整个工作流程就是:首先全局事务如果要开始,业务的入口会开启一个global transaction(全局事务),全局事务的开启也要告诉TC,TC知道我们要开始做一个全局事务了,接下来我们每调用的一个远程微服务它们就是一个分支事务,如果它们的事务开始,它们要注册自己的分支事务给TC,那么TC也知道我们当前全局事务的当前状态正在做某一个分支事务,而且这个分支事务的状态也要汇报给TC(分支事务是提交了还是回滚了),每一个微服务都一样,那这样的话如果某一个环节出现问题例如accout,TC就会要求那个出问题的微服务accout对他的事务进行回滚,而且由于TC知道accout出了问题,而其他微服务可能不知道,它们可能已经提交了,但就算你提交了,TC会要求你们把提交的数据再改回去,已提交的事务怎么改回去,它是基于一个undo_log机制,Seata的工作原理就是这样的
🟡步骤 1:开始全局事务(TM 发起)
比如业务入口是 Business 服务(下单);
TM 开启一个 Global Transaction(全局事务);
并通知 TC:我们开始做全局事务了。
🟡 步骤 2:调用其他微服务(产生分支事务)
TM 在事务中调用了 Storage、Order、Account 等服务;
每个服务的 RM 会:
注册自己的分支事务到 TC ;执行自己的本地事务(如扣库存) ;上报执行状态(成功/失败)给 TC 。
🟡 步骤 3:TC 做决策(统一协调)
如果所有分支都成功 → TC 通知所有 RM 执行 提交 ;
如果有一个服务失败(比如 Account 余额不足) → TC 通知所有服务 回滚 。
🟡 步骤 4:RM 根据命令执行提交/回滚
即使某个服务已经提交了事务,只要 TC 要求回滚;
RM 会用 undo_log 把已提交的数据“改回去”;
保证全局事务的最终一致性。
总结一句话:
Seata 就像一个指挥系统,TM 发起事务,RM 执行本地操作,TC 统一管理事务命运(提交或回滚) ,通过 undo_log 实现真正的分布式事务一致性。
7.4整合Seata
7.4.1.引入Seata依赖
1 2 3 4 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-seata</artifactId > </dependency
7.4.2.每个微服务创建file.conf⽂件
完整内容如下;
1 2 3 4 5 6 7 8 9 10 service { vgroupMapping.default_tx_group = "default" default .grouplist = "127.0.0.1:8091" enableDegrade = false disableGlobalTransaction = false }
file.conf 的配置核心目的是让每个微服务知道:“我属于哪个事务分组?我的 TC 协调器在哪里?我是否启用全局事务?”
1 vgroupMapping.default_tx_group = "default"
作用: 事务分组名 到 TC 服务集群名。
default.grouplist = "127.0.0.1:8091"
作用: default 分组指定具体的 TC 地址和端口。
enableDegrade = false
作用: 事务降级机制 (当前版本不支持,一般设为 false)。
disableGlobalTransaction = false
作用:
7.4.3标注全局事务注解@GlobalTransactional
完成了这三步之后回过头来再进行之前的测试,发现这次分布式事务被Seata成功控住了,没有出现数据不一致的现象,订单每创建,库存和金额也没被减
7.5Seata-二阶提交协议
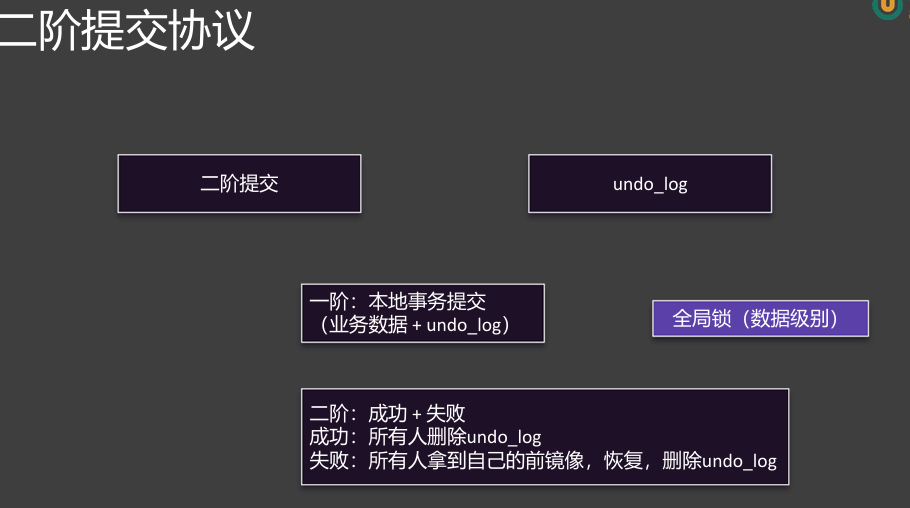
二阶事务的第一阶段就是每一个分支事务先去自己的数据库本地提交,但是要提交两个东西:第一个你业务修改后的数据和第二个undo_log回滚日志,这样Seata(TC服务器)就知道谁在第一阶段成了,谁在第一阶段败了
第二阶段,如果每个分支事务都成了,TC会通知每个微服务,告知它们可以提交本次分支事务,而每一个微服务只需要把自己的undo_log日志一删就可以了。如果某个事务失败了,Seata就会通知每一个已经成功本地提交的微服务去回滚,一旦每一个微服务收到了Seata服务器的回滚通知该怎么办,那么每一个微服务就会开启一个回滚任务,这个任务也是一个事务,主要做这么几件事:第一件步,找到undo_log记录(根据全局事务id和分支事务id)我的undo_log记录我的前镜像和后镜像。第二步,做一个数据校验,后镜像和当前数据进行一个对比,如果一致就可以放心大胆的回滚,如果不一致,说明外部有一些其他渠道修改了,需要在Seata里配置相应的策略(只要编码正确的话一般不会出现这种情况)。第三步,数据校验完成,回滚数据,拿到它的前镜像,执行修改,完成后删除undo_log
只要我们的总事务没有执行完成,总事务期间用到的所有全局锁都不会被释放,在并发的情况下很有效。
一阶段:执行本地业务并生成回滚日志 每个微服务(分支事务)要做以下几件事:
执行业务操作 (例如减库存、扣余额、创建订单);查询并记录前镜像数据 (操作前的快照);执行 SQL 修改数据 ;记录后镜像数据 ;将前镜像和后镜像写入 undo_log 表 ;向 TC 注册分支事务并锁定数据(记录全局锁) ;提交本地事务:业务数据 + undo_log 一起提交 ;将执行结果上报给 TC(成功/失败) 。
👉 此时,数据已修改,但可以“回滚”,因为 undo_log 记录了变更前后状态。
二阶段:根据 TC 指令提交或回滚 ✅ 情况一:所有分支事务都成功
TC 统一发出 “提交” 通知;
各服务在本地执行:
删除对应的 undo_log 日志;
表示数据最终确认生效;
无需其他额外操作。
📌 注意:提交是非常轻量的操作,只是删除日志。
❌ 情况二:某个分支事务失败,需要全局回滚
TC 向所有已经成功提交的服务发送 “回滚” 指令;
每个微服务执行“回滚事务”,包含:
全局锁说明
在整个全局事务未完成前(无论提交还是回滚),相关数据持有全局锁 ,不能被其他事务访问,确保数据一致性。
总结一句话:
Seata 的 2PC 模型中,一阶段提交业务数据+回滚日志,二阶段根据 TC 决定是删除日志(提交)还是回滚数据(根据日志还原),最终实现分布式事务的一致性。
7.6undo_log
7.7Seata的四种事务模式
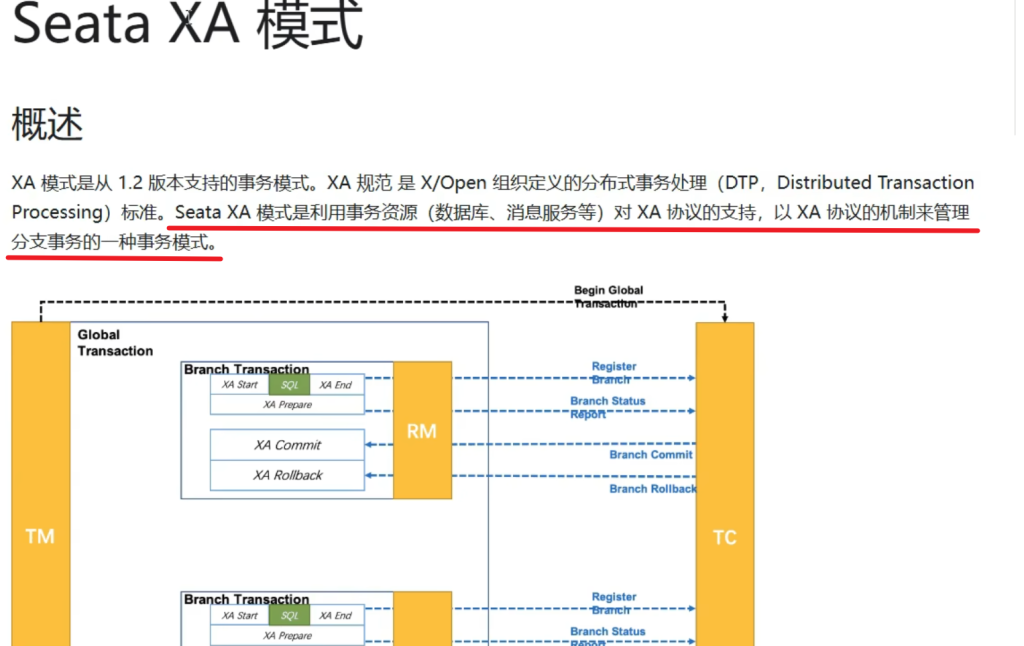
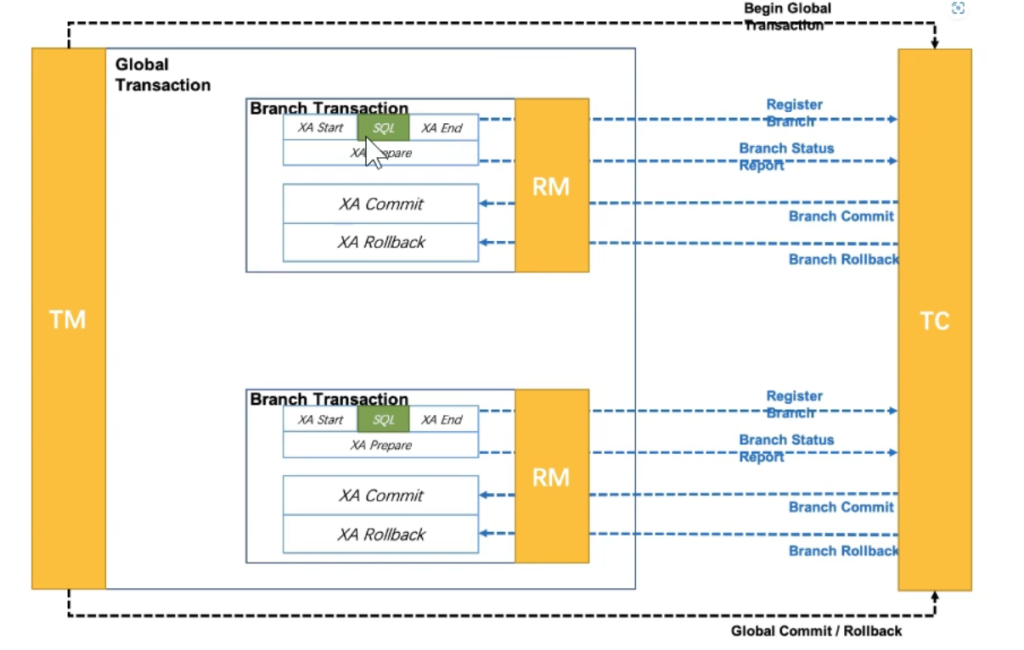
7.7.1 Seata AT模式(默认)
7.7.2XA模式
XA模式也是一种二阶提交协议,不同的是第一阶段它并不会给本地数据库真正的提交数据,它会阻塞住这个事务请求,只有在第二阶段确认要提交以后才会真正去提交
补充:AT->XA(不推荐)
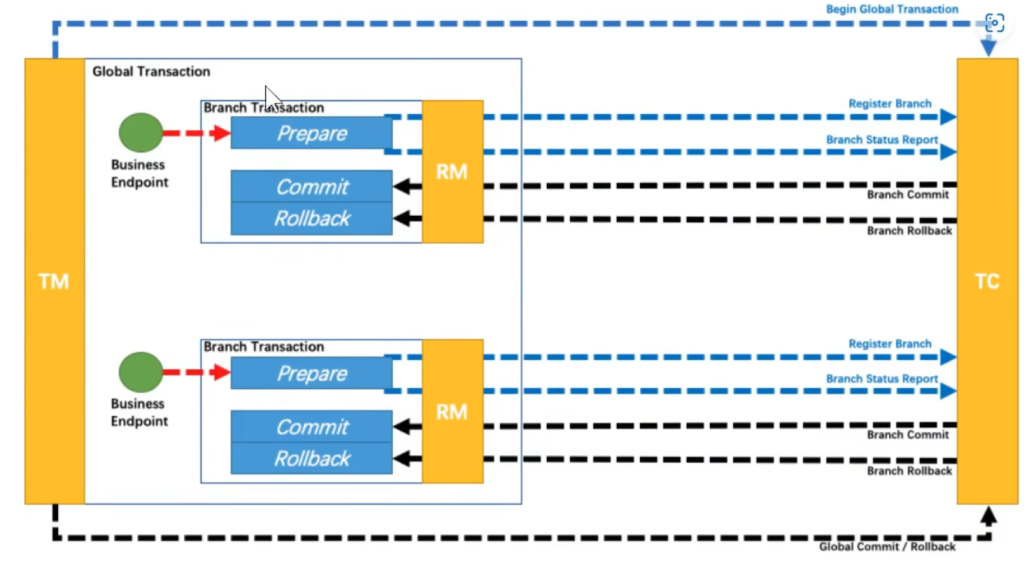
7.7.3TCC模式
第一阶段叫准备,我该给数据库里面存什么或删什么,第一阶段给它执行完
第二阶段提交或回滚,大家都成了提交,有一个败了回滚 这里的prepare,commit,rollback需要程序员去定义每一个阶段的实现代码
TCC模式适合于一些夹杂了非数据库的事务代码。需要我们全程手写,TC服务器仅帮我们协调调用每一个阶段
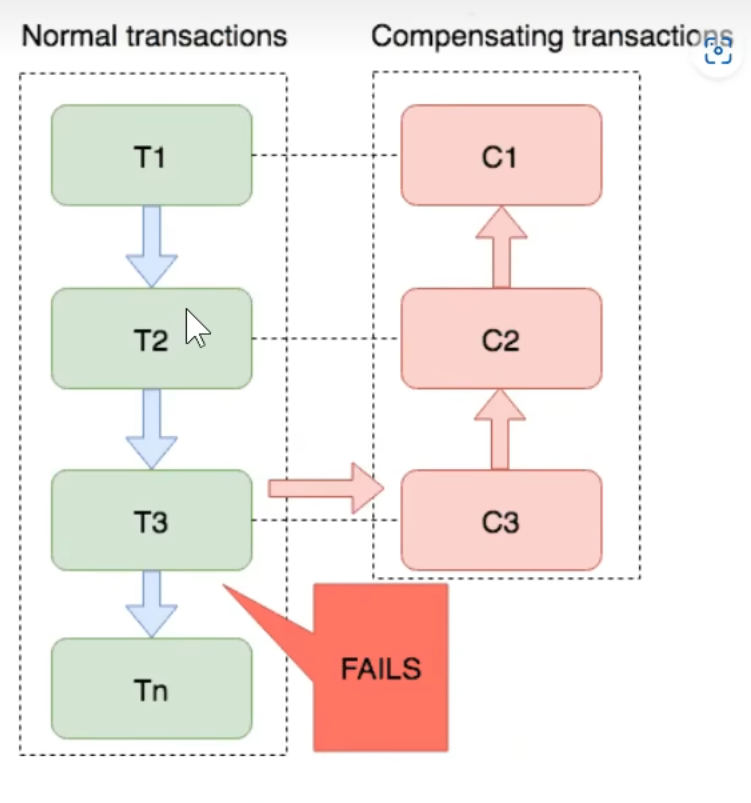
7.7.4Saga模式
例如请假审批等一系列流程不适用于其他三个模式,会导致锁长期锁在业务里,对系统是非常大的一种阻塞,Saga模式是Seata结合消息队列实现的
8.总结
SpringCloud完结