Agent项目实战开发-理论篇
Agent项目实战开发
一.AI大模型基础认知
大模型基础概念速通
1、Token:模型眼中的"字"
人类读文字是一个字一个字读的,模型处理文字的基本单位叫 Token。
Token 不等于字,也不等于词,是模型自己学出来的一种切分方式。
例如:
以英文为例
“Hello, world!” → [“Hello”, “,”, " world", “!”] 共 4 个 Token
“unbelievable” → [“un”, “believ”, “able”] 共 3 个 Token
以中文为例:
“你好世界” → [“你好”, “世界”] 共 2 个 Token
“人工智能” → [“人工”, “智能”] 共 2 个 Token
“量子纠缠” → [“量子”, “纠”, “缠”] 共 3 个 Token(生僻组合拆得更碎)
规律大概是这样:常见词/词组通常是 1 个 Token,生僻词、专业术语会被拆成多个,中文平均 1 个汉字约等于 0.6-0.7 个 Token,数字和标点也占 Token。
2、上下文窗口:模型的"工作台"
大模型每次处理请求时,能接收的 Token 总量有上限,这个上限叫上下文窗口(Context Window)。
3、消息结构:System、User、Assistant
调用大模型 API,输入不是一段文字,而是一个消息列表,每条消息有固定角色。
| 角色 | 说明 | 类比 |
|---|---|---|
system |
给模型的背景设定和行为指令 | 员工入职培训手册 |
user |
用户发送的消息 | 用户的每次输入 |
assistant |
模型的回复 | 模型的每次输出 |
一次多轮对话的消息结构长这样:
1 | [ |
模型收到这个列表,就能理解整个对话上下文,给出连贯的回复。
System Prompt 是整个 AI 应用的"灵魂",决定了模型的身份、能做什么、不能做什么、用什么风格回答。
示例:
1 | 你是xxx AI 的智能客服助手。 |
4、Temperature:控制模型的"随机性"
模型是怎么生成文字的
模型生成每个词,实际上是在做概率分布采样。比如补全"今天天气很"这句话:
1 | "好" → 40% 概率 |
模型不是每次都选概率最高的词,而是按概率"抽签"。Temperature 就是控制这个抽签过程的参数。
Temperature = 0:每次都选概率最高的词,结果确定,每次运行一样,适合代码生成、数据提取这类要求精确的场景。
Temperature = 0.7(默认):适当随机,有变化但总体合理,适合聊天对话、问答系统。
Temperature = 1.5+:高度随机,极具创意但可能不合逻辑,适合头脑风暴,但很少用这么高。
【简单来说,Temperature 控制模型在生成下一个词时的“大胆程度"】
举个例子感受一下:
1 | 提示:写一句关于春天的话 |
开发中怎么选
| 应用场景 | 推荐 Temperature |
|---|---|
| JSON 数据提取 | 0 |
| SQL 生成 | 0 ~ 0.2 |
| 问答系统 | 0.3 ~ 0.7 |
| 聊天助手 | 0.7 |
| 文案创作 | 0.8 ~ 1.0 |
5、其他常用参数(快速过一下)
Top-P(核采样)
和 Temperature 类似,也是控制随机性的。Top-P = 0.9 表示只从累积概率达到 90% 的词里随机选,排除掉长尾低概率词。
实践建议:Temperature 和 Top-P 不要同时调,选一个就够了。OpenAI 官方推荐调 Temperature,固定 Top-P = 1。
Max Tokens(最大输出长度)
控制模型单次回复最多输出多少 Token。不要设太小(回复被截断),也不要不设(遇到"话痨"模型会产生大量 Token 费用)。
Stop Sequences(停止序列)
指定当模型输出包含某些特定字符串时立即停止生成,用得不多,遇到了再查。
参数速查
| 参数 | 默认值 | 常用设置 |
|---|---|---|
temperature |
1.0 | 精确任务用 0~0.3,对话用 0.7 |
top_p |
1.0 | 通常不动 |
max_tokens |
模型上限 | 根据场景设合理上限 |
6、把这些概念串起来
一次完整的 API 调用长这样:
1 | { |
背后发生了什么:
- 消息列表被 Tokenize,计算总 Token 数,检查是否超出上下文窗口
- 模型根据消息内容生成概率分布
- Temperature = 0.3,偏向确定性,大概率选高概率词
- 模型逐个 Token 生成,直到遇到结束符或达到 max_tokens
- 返回结果,按(输入 Token + 输出 Token)计费
二.Transformer 与大模型工作原理
1.大模型到底是什么?
从程序员视角理解:
作为 Java 程序员,大家习惯了:代码 + 数据 → 输出。
大模型从本质上也是一个函数:
1 | f(输入文字) → 输出文字 |
但这个函数的参数不是 if-else 写出来的,而是从海量数据中学习出来的,存储在数十亿甚至数千亿个浮点数里。
1 | GPT-4:约 1.8 万亿参数(每个参数是一个 float32,占 4 字节) |
把模型想象成一本书,但这本书里没有文字,只有数十亿个调好的旋钮,每个旋钮的刻度共同决定了模型的"知识"和"能力"。
模型只做一件事
模型实际上只做一件事:预测下一个 Token 的概率分布。
输入:[“今天”, “天气”, “很”]
输出:{“好”: 0.40, “差”: 0.25, “热”: 0.20, “糟”: 0.10, …}
然后采样选一个词,加入序列,再预测下一个……如此循环,直到生成结束符。
整个 ChatGPT、整个智能客服、整个代码助手,底层都是这一个动作反复执行。
Transformer 之前:RNN 的问题
Transformer 出现之前,处理文字序列最主流的是 RNN(循环神经网络)
NN 的工作方式很像人读文章:一个字一个字读,同时维护一个"记忆状态",把前面读过的信息压缩进去。
1 | 读入"今" → 更新记忆状态 h1 |
但存在两个致命问题:
长距离依赖丢失
也就是早消息就被后来的消息覆盖后,容易出现信息丢失,也就是忘记你之前的对话内容
无法并行计算
RNN 必须一步一步顺序计算,读完第 N 个词才能读第 N+1 个词,没法利用 GPU 的并行计算能力。
2.Transformer:注意力机制的革命
核心思想
Transformer 完全抛弃了顺序处理的方式。它的核心思想是:
处理每个词时,同时看整个句子里所有其他词,计算它们之间的关联程度。
这就是注意力机制(Attention)。
直觉理解
还是那句话:“我在北京长大,后来去上海读书,又在广州工作了十年,现在终于回到了我魂牵梦绕的故乡”
当模型处理"故乡"这个词时,注意力机制会让它向整个句子"提问":
1 | "故乡"问:"谁和我最相关?" |
通过这种方式,无论"北京"和"故乡"之间隔了多少词,模型都能直接建立关联,不存在 RNN 那种"遗忘"问题。
而且,实际上,Transformer 不止做一次注意力计算,而是同时做多个(比如 16 个),每个从不同角度关注句子
- 第 1 个头:关注语法关系(主谓宾)
- 第 2 个头:关注语义相似性
- 第 3 个头:关注指代关系("它"指什么)
- 第 4 个头:关注时间顺序关系
最后把所有头的结果合并,得到全面的理解。(有点像代码审查——一个人盯性能,一个人盯安全,一个人盯可读性,最后汇总意见比一个人全看更全面。)
注意力机制的关键特性:每个词与其他词的关系可以同时计算,互不依赖。这就是为什么 Transformer 能并行的原因。
3.大模型是怎么学会知识的
大模型的训练第一阶段叫预训练(Pre-training),过程极其简单粗暴:
收集海量文本(维基百科、书籍、代码、网页……),然后反复做一件事:
给模型看一段文字,遮住最后一个词,让模型预测它是什么。
4.参数怎么调整
每次预测完,模型会计算"预测错了多离谱"(损失值),然后用反向传播算法,从后往前微调每一个参数,让下次预测更准确。
数十亿参数,每个都微调一点点,重复万亿次,最终就是大模型。
5.微调:让模型变成"好助手"
预训练完的模型只会"续写文章",不懂得回答问题,也不知道拒绝有害请求。还需要两步:
指令微调(SFT):用大量人工标注的"问题-答案"对来训练,让模型学会对话格式。
RLHF(人类反馈强化学习):让真人对多个回答打分,训练一个"奖励模型",再用强化学习让大模型往高分方向走。
这两步把"会续写文章的模型"变成了"会聊天的助手",ChatGPT 的成功很大程度上来自 RLHF 做得好。
6.大模型的能力边界
知道模型有知识截止日期 → 涉及最新信息的场景,必须用 RAG 把实时数据注入上下文。
知道模型没有持久化记忆 → 多轮对话系统必须自己管理历史消息,每次调用时把相关历史带上。
知道幻觉无法消除 → 关键业务场景(医疗、法律、财务)必须有人工审核或数据验证环节,不能完全信任模型输出。
知道 Prompt 影响概率分布 → System Prompt 写得好,相当于把模型的"注意力"引导到正确方向;写得差,模型就按训练数据里最常见的模式来补全,结果偏。
三.Embedding 与向量
1.机器不懂文字,只懂数字
解决思路
如果能把每段文字转化成一组数字,让意思相近的文字对应数字也相近,问题就解决了。
这组数字叫向量(Vector),把文字转成向量的过程叫 Embedding(嵌入)。
2.向量:用坐标描述语义
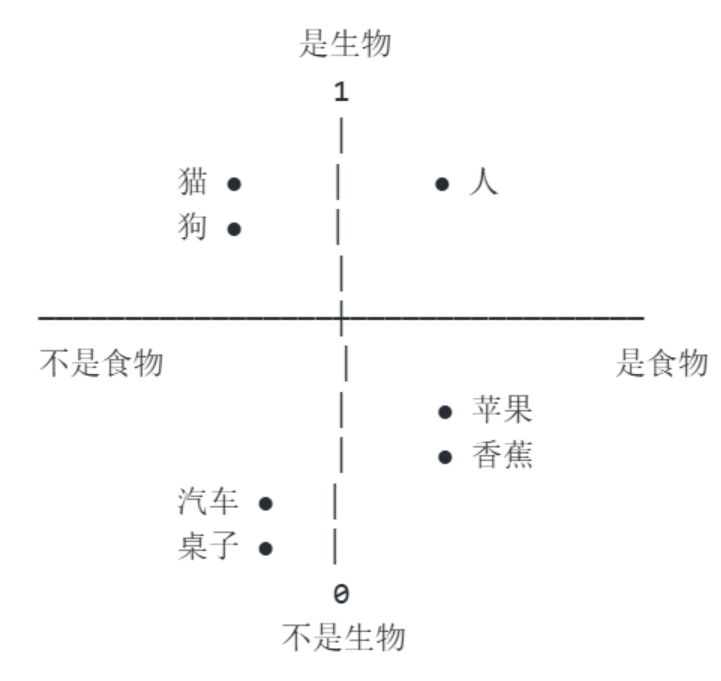
在这个空间里,"苹果"和"香蕉"很接近(都是食物,都不是生物),"猫"和"狗"很接近,"苹果"和"汽车"很远。
向量就是在高维空间里的一个坐标点,坐标相近意味着语义相近。
真实的 Embedding 不止 2 个维度,通常是 768、1536 甚至 3072 个维度。每个维度捕捉语言的某种抽象特征
这就是语义搜索的基础:找的不是关键词匹配,而是语义相近的内容。
3.相似度:两个向量有多近
| 余弦相似度 | 含义 |
|---|---|
| 1.0 | 完全相同 |
| 0.9+ | 非常相似 |
| 0.7~0.9 | 比较相似 |
| 0.5~0.7 | 有一定关联 |
| 0~0.5 | 关联性弱 |
| 负数 | 语义相反 |
有了向量和相似度,语义搜索的过程就很清晰了:
1 | ① 把所有文档段落转成向量,存入向量数据库 |
4.Embedding 模型
Embedding 向量不是人工设计的,由专门的 Embedding 模型生成。和对话模型不同,Embedding 模型不生成文字,只生成向量:
1 | // 概念示意 |
主流 Embedding 模型
| 模型 | 提供商 | 维度 | 特点 |
|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | 性价比高,英文效果好 |
| text-embedding-3-large | OpenAI | 3072 | 精度更高,价格较贵 |
| text-embedding-v3 | 阿里通义 | 1024 | 中文效果好,国内可用 |
| BGE-M3 | 北京智源 | 1024 | 开源,多语言,可本地部署 |
| nomic-embed-text | Nomic | 768 | 开源,可用 Ollama 本地跑 |
选型建议:纯中文场景选通义 text-embedding-v3 或 BGE-M3;英文为主选 OpenAI text-embedding-3-small;需要本地部署选 BGE-M3 + Ollama。
注意:一个关键原则-同进同出
查询时使用的 Embedding 模型,必须和存储时用的是同一个。
1 | 错误做法: |
5.向量数据库
向量搜索需要对大量向量做相似度计算,这和传统数据库的索引结构完全不同:
1 | 传统数据库:B+ 树索引,擅长精确匹配和范围查询 |
实际系统中,向量数据库和关系型数据库往往并存,各司其职。
主流向量数据库
| 数据库 | 部署方式 | 特点 | 适合场景 |
|---|---|---|---|
| PGVector | 本地 / 云 | PostgreSQL 扩展,熟悉 SQL | 入门首选,已有 PG 的项目 |
| Milvus | 本地 / 云 | 专用向量库,性能强,功能全 | 生产级大规模场景 |
| Qdrant | 本地 / 云 | Rust 编写,性能好,易用 | 中小规模生产场景 |
| Chroma | 本地 | 轻量,适合开发测试 | 快速原型 |
学习路径建议:PGVector 入门 → Milvus 进阶。
6.完整例子串联
1 | 【离线准备阶段】 |
四.定制大模型的三种方式——Prompt、RAG、Fine-tuning
1.为什么需要定制?
通用大模型是在互联网公开数据上训练的,开箱即用有几个明显的限制:
- 不知道你公司内部的知识(产品文档、规章制度、历史数据)
- 不了解你的业务场景和专业术语
- 说话风格和你的品牌调性可能不符
- 对于高度专业化的任务效果有限
当通用能力不够时,主流方案有三种:Prompt Engineering、RAG、Fine-tuning。
2.三种方式
Prompt Engineering(提示词工程)
核心思路:不改变模型本身,通过精心设计输入来引导模型输出符合预期的结果。

类比:同一个员工,大家给他不同的工作说明书,他的输出就不同。不需要"换"一个员工,只需要写好说明书。
RAG(检索增强生成)
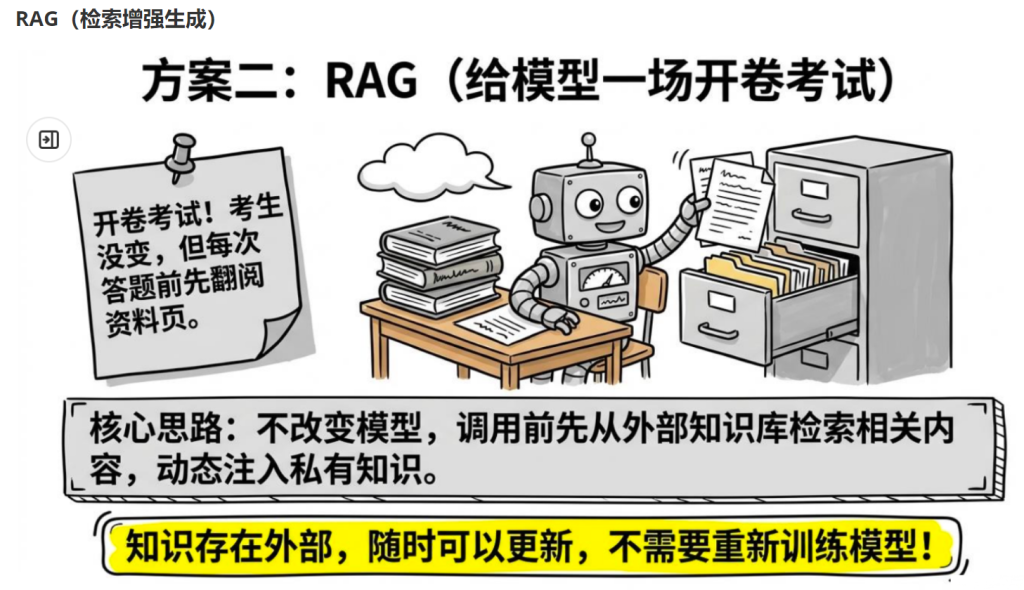
核心思路:不改变模型,但在每次调用前,先从外部知识库里检索相关内容,动态注入 Prompt,让模型"临时学到"你的私有知识。
类比:开卷考试。考生(模型)没变,但每次答题前先翻到相关资料页,回答就会更准确。
Fine-tuning(微调)
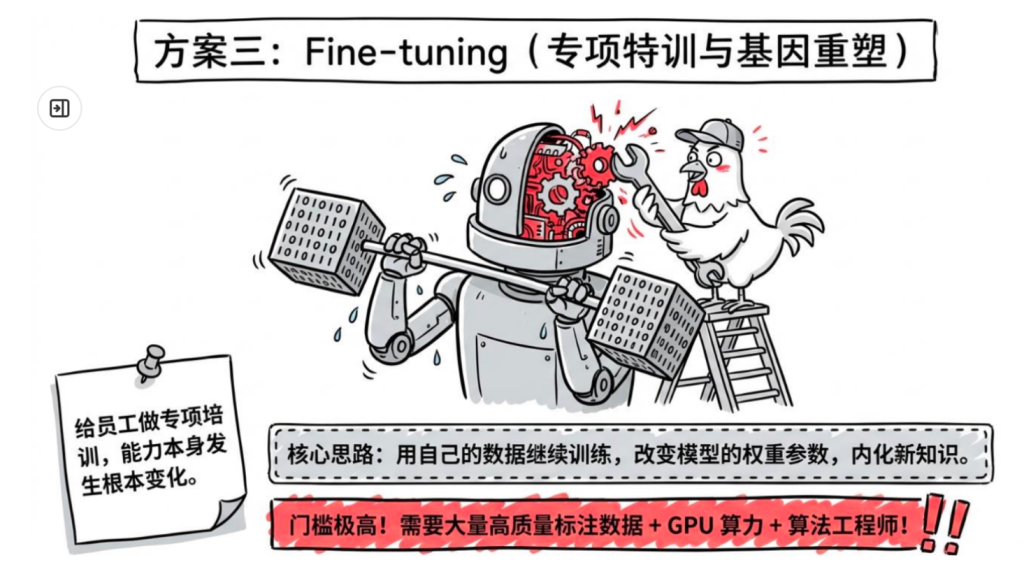
核心思路:在已有大模型的基础上,用自己的数据继续训练,改变模型的权重参数,让模型"内化"新的知识或行为模式。
类比:给员工做专项培训,培训完他的能力本身00
发生了变化,不需要每次都带着参考资料。
Fine-tuning 需要什么:大量高质量的标注训练数据(通常数百到数千条问答对)、较高的计算资源(GPU)、专业的 ML 工程知识、持续的维护成本(数据更新要重新训练)。
3.三种方式全面对比
| 维度 | Prompt Engineering | RAG | Fine-tuning |
|---|---|---|---|
| 实现难度 | 低 | 中 | 高 |
| 开发成本 | 极低 | 中等 | 高 |
| 知识更新 | 即时生效 | 即时生效 | 需重新训练 |
| 知识容量 | 受上下文窗口限制 | 理论无限 | 烘焙进参数(有限) |
| 模型是否改变 | 否 | 否 | 是 |
| 可解释性 | 高(能看到 Prompt) | 高(能看到检索到的内容) | 低(黑盒) |
| 适合场景 | 行为控制、格式约束 | 私有知识问答 | 风格迁移、专业术语内化 |
4、什么时候用哪种
1 | 你的需求是什么? |
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 让模型用公司口吻回复 | Prompt Engineering | 只是行为约束,Prompt 就能搞定 |
| 企业内部知识库问答 | RAG | 文档多、会更新,必须用 RAG |
| 实时查询数据库回答 | RAG + Tool Calling | 数据是动态的,需要实时查询 |
| 模型回答某垂直领域专业问题 | RAG(优先)或 Fine-tuning | 先试 RAG,不够再考虑微调 |
| 训练一个特定语言风格的模型 | Fine-tuning | 风格需要内化,RAG 解决不了 |
| 医疗/法律等高度专业场景 | RAG + Fine-tuning 组合 | 双管齐下,知识+能力都要提升 |
“Fine-tuning 比 RAG 效果一定更好”
不一定。Fine-tuning 的效果高度依赖训练数据的质量和数量。
对于"让模型知道公司内部知识"这类需求,RAG 的效果往往优于 Fine-tuning,因为:RAG 能精确引用原文、知识更新即时生效、来源可追溯。Fine-tuning 的知识是黑盒,而且可能在原有知识上产生混淆。
“Prompt Engineering 只是入门手段,后面要换掉”
不对。Prompt Engineering 是贯穿始终的基础能力。
即使用了 RAG 或 Fine-tuning,Prompt 依然决定了模型如何利用这些知识。好的 Prompt 是 AI 应用质量的地基,永远不会过时。
“数据不多,Fine-tuning 没用”
基本正确。Fine-tuning 需要足够多且高质量的训练样本。
数据量少时(几十条),Fine-tuning 不仅效果差,还可能导致过拟合——模型死记硬背,泛化能力变差。这种情况用 Prompt + RAG 效果反而更好。
5.实际项目中的组合使用
三种方式并不互斥,生产系统中常常组合使用:
1 | 典型的企业智能客服架构: |
五.AI应用开发全景图
一个完整的 AI 应用,由以下核心组件构成:
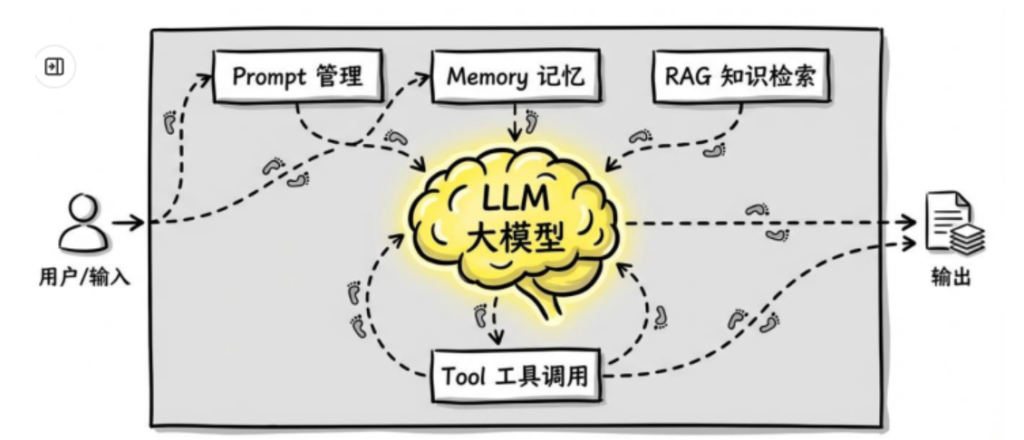
1.LLM——整个系统的大脑

大语言模型是整个系统的核心,负责理解输入、推理决策、生成输出。没有 LLM,系统只能走固定的 if-else 逻辑。
但 LLM 本身有几个硬限制:
- 知识有截止日期,不知道最新信息
- 没有持久化记忆,每次调用都是"新员工"
- 无法主动操作外部系统
- 可能产生幻觉
这些限制,正是其他组件存在的理由。
其他每一个组件,都是在弥补 LLM 某一个具体的缺陷。这个视角很重要,理解了这个,整个架构就很好理解了。
2.Prompt 管理——说话的艺术
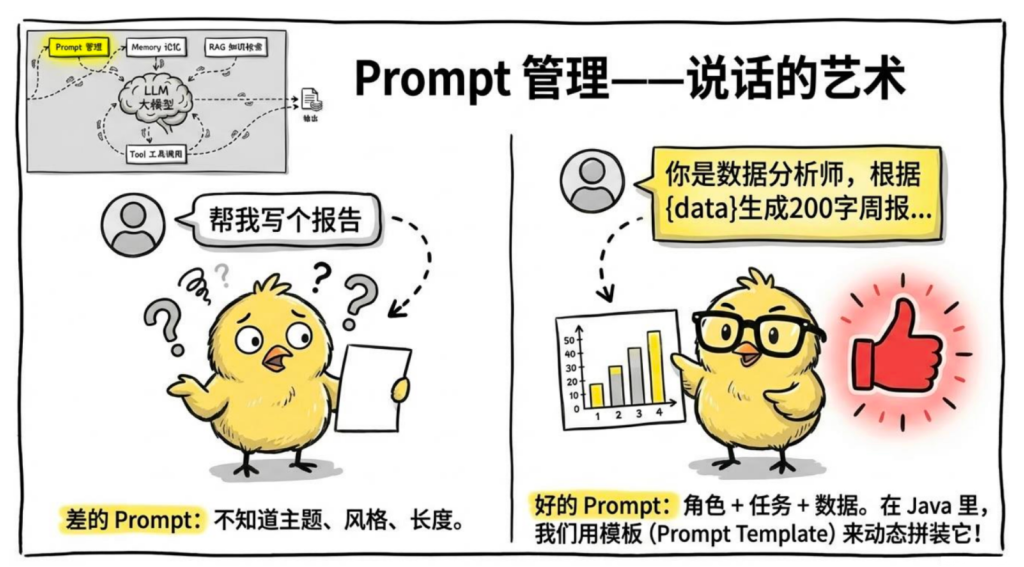
Prompt 是给 LLM 的输入,包括 System Prompt 和 User Prompt。Prompt 管理是指如何在代码里组织、模板化、动态构建这些输入。
同样的模型,不同的 Prompt 效果天差地别:
在 Java 里,用 Spring AI 或 LangChain4j 的 Prompt Template 来管理:
1 | String template = "你是{role},请{task}。数据:{data}"; |
3、Memory——让 AI 记住大家
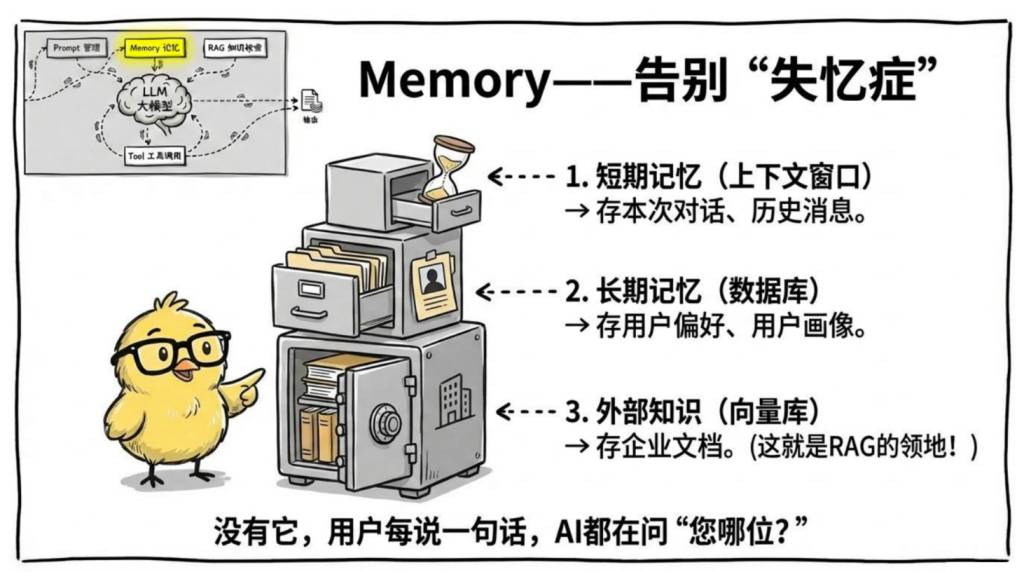
AI 应用的记忆系统分三层:
| 层级 | 存在哪里 | 生命周期 | 典型内容 |
|---|---|---|---|
| 短期记忆 | 上下文窗口 | 本次对话 | 历史消息、当前任务状态 |
| 长期记忆 | 数据库 / 向量库 | 永久 | 用户偏好、历史摘要 |
| 外部知识 | 向量数据库 | 永久 | 企业文档、知识库 |
没有记忆管理,多轮对话的 AI 每轮都是"失忆状态":
技术实现思路:
短期记忆把历史消息列表存在 Redis,每次调用时取出带入上下文;长期记忆把用户画像存入数据库,每次按需查询注入;外部知识文档向量化存入向量数据库,问题来了先检索再回答(这就是 RAG)。
4.RAG——给 AI 装上知识库
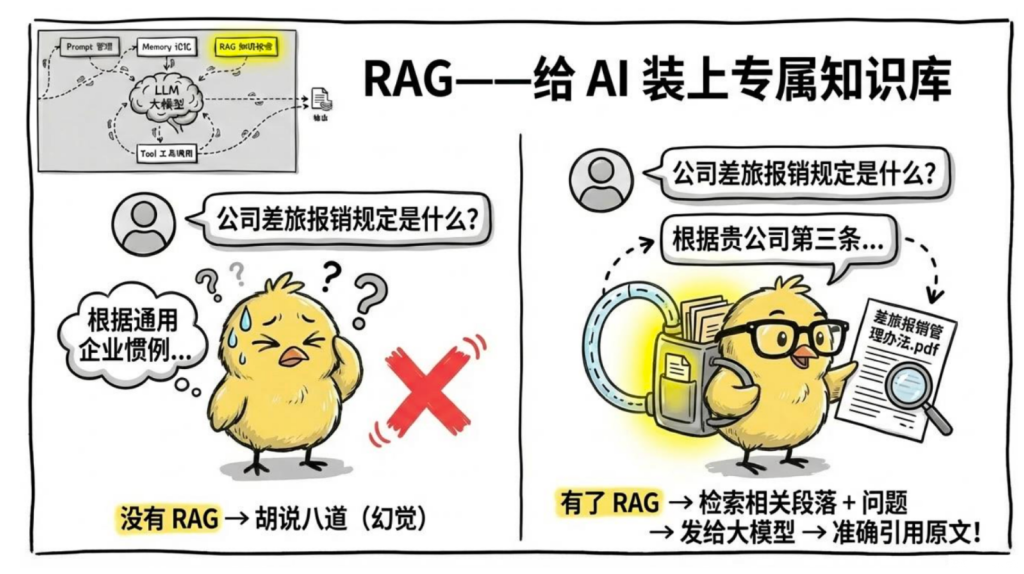
RAG(Retrieval-Augmented Generation,检索增强生成)是一种架构模式:在调用 LLM 之前,先从知识库里检索相关内容,把它塞进 Prompt 一起发给模型。
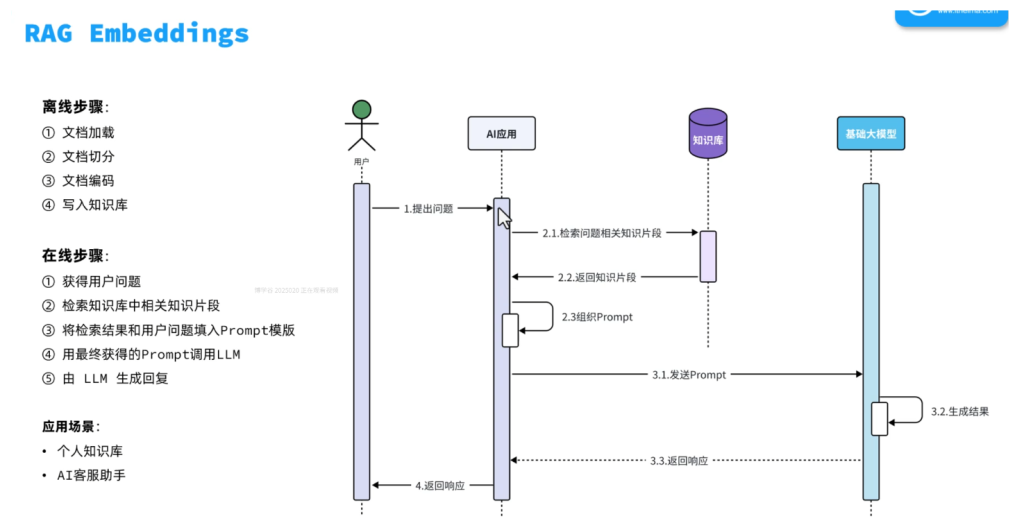
RAG 完整流程:
1 | 【离线阶段】 |
5.Tool——让 AI 有手有脚
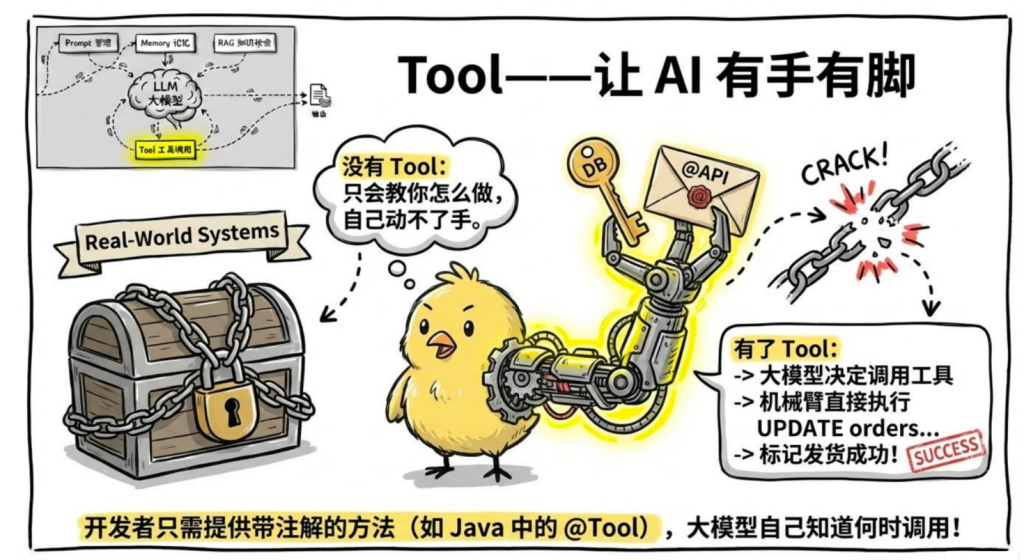
Tool(工具)是开发者提供给 LLM 的一组函数。LLM 可以在推理过程中决定调用哪个工具、传什么参数,把工具的返回值作为信息继续推理。
LLM 本身只能"说话",无法直接操作任何系统。Tool 让 LLM 有了"手":
在 Java 里,一个工具就是一个普通方法,加上描述注解让 LLM 知道它的用途:
1 |
|
LLM 读到这个描述,就知道什么时候该调用它、怎么传参数。
6.一个完整例子,把所有组件串起来
场景:用户问"帮我查一下上个月华东区业绩,和公司考核标准对比一下"
1 | ① 用户输入进入系统 |
7.什么是Agent
**Agent(智能体)**是以大语言模型为核心大脑,能够自主感知环境、制定计划、调用工具、执行行动,并根据反馈持续调整,最终完成复杂任务的一个 AI 系统。
几个关键词拆解:
- 自主:不需要人类每一步都介入
- 感知环境:能读取数据库、文件、网页等外部信息
- 制定计划:能把大目标拆分成可执行的步骤
- 调用工具:能操作外部系统(数据库、API、邮件…)
- 根据反馈调整:工具执行失败时能换个方式重试


