AI相关面试题
GQ AI
什么是 RAG?RAG 的主要流程是什么?
RAG (Retrieval-Augmented Generation)检索增强生成
什么是 RAG?
官方定义:

简单来说就是:RAG,全称是 Retrieval-Augmented Generation(检索增强生成)。
简单来说,它是一种让大模型“带脑子说话”的方式——
在 LLM 回答之前,先从外部知识库或企业文档里查到相关资料,再把这些资料注入到提示词中,让模型基于真实知识生成答案,这样能减少幻觉、提升准确度。
幻觉?
- 已读乱回
- 已读不回
- 似是而非
springai 中的 RAG
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
springai alibaba 中的 RAG 叫做文档检索 (Document Retriever)
https://java2ai.com/docs/1.0.0.2/tutorials/basics/retriever/?spm=5176.29160081.0.0.2856aa5cXggpMJ
RAG 核心设计理念
RAG 技术就像给 AI 大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让 AI 摆脱传统模型的” 知识遗忘和幻觉回复” 困境
一句话
类似考试时有不懂的,给你准备了小抄,对大模型知识盲区的一种补充
RAG 能干嘛
通过引入外部知识源来增强 LLM 的输出能力,传统的 LLM 通常基于其训练数据生成响应,但这些数据可能过时或不够全面。RAG 允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答
RAG 流程
索引和检索
官方流程如下图:
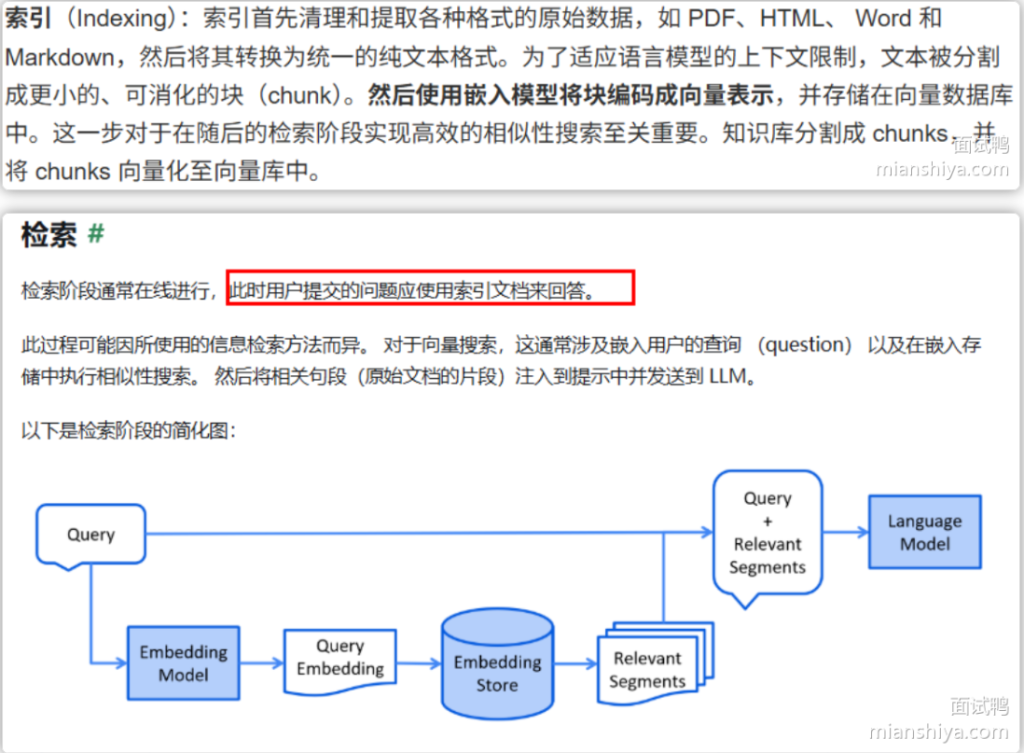
总结来说就是:
① 索引阶段(Indexing)
主要是“准备知识库”的过程:
- 先加载各种原始数据,比如 PDF、Word、Markdown 等;
- 清洗解析成纯文本;
- 再把文本按段落或句子拆分成小块(chunk);
- 用嵌入模型(Embedding Model)把每个块转换成向量;
- 最后把这些向量存入向量数据库中,方便后续做相似度搜索。
你可以理解为:这一步是“建知识库 + 做成能算距离的格式”。
② 检索阶段(Retrieval)
这一步是“模型答题前先查资料”:
- 用户提问时,系统先把问题也转成向量;
- 在向量数据库中找到最相似的文本片段;
- 把这些相关内容和用户的问题拼在一起,送进大模型;
- 模型再基于这些外部知识生成最终回答。
这样,模型不仅依靠自己的训练知识,还能结合实时的外部数据,回答更准确、更有依据。

一句话总结:
RAG = “查资料 + 再回答”。
它通过“索引阶段建知识库、检索阶段查知识”来增强大模型的上下文能力,
让回答更贴近事实、减少胡说八道。
什么混合检索?在基于大模型的应用开发中,混合检索主要解决什么问题?
什么是混合检索?它在大模型应用中主要解决什么问题?
混合检索(Hybrid Retrieval)其实就是在 RAG(检索增强生成) 场景下,把向量检索和关键词检索结合起来用。
它的目标是利用两种方式的互补优势,让检索结果既能“理解语义”,又能“精准命中”,整体更全面、更准确。
举个例子:
比如用户问“猫捕老鼠”,
- 向量检索能理解语义关系,比如把“猫”联想到“猫科动物”,
- 但如果问“iPhone 15”这种专有名词,向量检索可能模糊匹配不到。
这时候关键词检索就能精确命中这些具体词。
所以混合检索的核心思想就是:
语义理解靠向量检索,精准命中靠关键词检索,两者结合取长补短。
在工程实现上
混合检索一般会:
- 并行执行两种检索(向量 + 关键词);
- 然后用一个融合算法(比如 QDRF 或重排模型)把结果合并、去重、排序;
- 最后把最优结果送进大模型生成答案。
在实际落地中,比如 LlamaIndex + ElasticSearch 的组合就很常见:
LlamaIndex 负责语义检索,ElasticSearch 负责关键词匹配。
一句话总结:
混合检索解决了大模型在“语义理解强但命中不准、关键词命中准但不懂语义”的矛盾,
让 RAG 系统既能“懂你在问什么”,又能“找对内容”。
RAG 的完整流程是怎么样的?
① 索引阶段(Indexing)
主要是“准备知识库”的过程:
- 先加载各种原始数据,比如 PDF、Word、Markdown 等;
- 清洗解析成纯文本;
- 再把文本按段落或句子拆分成小块(chunk);
- 用嵌入模型(Embedding Model)把每个块转换成向量;
- 最后把这些向量存入向量数据库中,方便后续做相似度搜索。
你可以理解为:这一步是“建知识库 + 做成能算距离的格式”。
② 检索阶段(Retrieval)
这一步是“模型答题前先查资料”:
- 用户提问时,系统先把问题也转成向量;
- 在向量数据库中找到最相似的文本片段;
- 把这些相关内容和用户的问题拼在一起,送进大模型;
- 模型再基于这些外部知识生成最终回答。
这样,模型不仅依靠自己的训练知识,还能结合实时的外部数据,回答更准确、更有依据。
什么提示压缩?为什么在 RAG 中需要提示压缩?
什么是提示压缩?为什么在 RAG 中需要它?
提示压缩(Prompt Compression)简单来说,就是在 RAG(检索增强生成) 里,
把从知识库检索出来的大量文档内容进行“精简、去噪、压缩”,
只保留最有用、最相关的信息,再送进大模型里。
这样既能减少无关内容占用 token,又能让模型专注在关键信息上,生成更精准的答案。
为什么需要提示压缩?主要有三点原因:
- 模型上下文有限
- 检索内容可能冗余或噪声多
- 性能与成本考虑
举个例子
比如用户问:“如何优化代码性能?”
检索到的文档里可能有 10 页内容,其中 8 页是原理、2 页才是优化技巧。
提示压缩的作用就是自动“提炼出那 2 页关键信息”,再结合问题注入模型。
最终模型生成的答案会更聚焦、更高效。
一句话总结:
提示压缩就是“先浓缩再喂模型”。
它在 RAG 中用来解决上下文超限、信息冗余和成本过高的问题,
让模型既能看到核心内容,又能保持高质量输出。
在 RAG 中的 Embedding 嵌入是什么?
官网-嵌入模型 (Embedding Model)
https://java2ai.com/docs/1.0.0.2/tutorials/basics/embedding/?spm=5176.29160081.0.0.2856aa5cXggpMJ

在 RAG 里,Embedding(嵌入)就是 把文本、图像和视频变成“能让机器听得懂的数字向量” 的过程。
可以把它理解成:
“把一句话翻译成一串数字,这些数字能表达它的语义含义。”
Embedding 做的,就是把这些语义关系映射到一个高维空间里:
- 语义相近的内容 → 数字距离靠得很近(聚在一起)
- 语义不相关的内容 → 距离会很远(分散开)
Embedding 在 RAG 里具体干什么?
RAG(检索增强生成)其实分两步:
① 先把所有知识库的文本 embed 成向量存到向量数据库(FAISS、Milvus 等)。
② 用户提问时,也把问题 embed 成向量然后计算两个向量的距离(比如余弦相似度)。
找到“最接近的问题/文档块”,再把内容喂给大模型回答。
Embedding 决定了你的 RAG 能不能“读懂问题”和“找到正确内容”。 它是 RAG 的核心基石。
在 RAG 中,你如何选择 Embedding Model 嵌入模型,需要考虑哪些因素?
RAG 常用的 embedding 模型主要分三类:
① 开源模型,比如 BGE、M3E、Sentence Transformers、E5、GTE;
② 商业 embedding,比如 OpenAI text-embedding-3、Cohere、Google Gecko;
③ 大模型自带的向量接口,比如 GPT-4o、Qwen、Claude。
其中中文场景下 BGE 和 M3E 最常用;需要极致效果则用 OpenAI 或 Cohere。
Copilot 模式和 Agent 模式的区别是什么?
Copilot 模式强调“协作”,用户主导、大模型辅助,需要多轮互动,比如写代码、生成文档。
Agent 模式强调“自主”,用户只给目标,Agent 会自动规划任务、自动调用工具并执行完整流程,更像一个 AI 管家。
两者最大的区别就是 自主性:Copilot 依赖用户驱动,而 Agent 是自驱动完成任务。
- Copilot = 助手(帮忙但全程听你的)
- Agent = 执行官(你定目标,它全程帮你干会帮你规划)
什么是向量数据库?在基于大模型的应用开发中,向量数据库主要解决什么问题?
向量数据库就是专门用来存储和检索向量的系统,它能进行语义相似度搜索,而不是关键词匹配。
- 比如 “肯德基” 和 “麦当劳” 在向量空间的距离会很近,而和 “新疆大盘鸡” 距离就远很多。
它解决了哪些核心问题
1. 解决“高效的语义搜索”问题(关键词搜索不行)
传统搜索是关键词匹配,比如你搜“天气”,只能匹配到包含天气两个字的内容。
但 RAG 需要的是语义搜索:
- 用户问“上海今天下雨吗”
- 它也要能找到“上海今日天气预报”的内容
向量数据库可以做到基于向量的“相似度搜索”,快速找到最相关的文本片段。
2. 解决“海量数据处理”问题
大模型上下文是有限的(比如 8k、16k token),但企业知识库可能是几十万文档、上亿数据。
解决方案:
- 所有文档 → 转成向量 → 存入向量数据库
- 查询时:只取“最相关”的 Top-K 文档送给大模型
这样就能处理超大规模知识库。
- 解决“实时交互”问题(低延迟、高吞吐)
像智能客服、智能问答、小模型 Agent 这种应用,都需要在几十毫秒内返回结果。
向量数据库专门对这种“高并发 + 低延迟”的相似度检索做了优化。
小结:
向量数据库就是专门用来存储和检索向量的系统,它能进行语义相似度搜索,而不是关键词匹配。
在 RAG 应用中,它主要解决:找到最相关知识、处理海量数据、支持实时交互这三个核心问题。
你都了解哪些向量数据库?如何选型?
1. 常见的向量数据库/向量检索方案
我接触过的主流向量库,大概可以分三类来说:
专用向量数据库(自带服务)
- Milvus
开源、功能比较全,支持大规模分布式存储和检索,社区很活跃,适合企业级、数据量特别大的推荐/搜索/RAG 场景。 - Pinecone
全托管云服务,不用自己运维,开箱即用,性能也不错,但成本会相对高一些,更适合需要快速上线、对云厂商依赖没问题的团队。 - Weaviate
支持向量 + 结构化 + 模糊搜索,Schema 比较灵活,对多模态/混合检索友好,做知识库、智能问答比较合适。 - Qdrant
Rust 写的,性能不错,支持过滤、分片、副本等能力,部署也比较轻量,适合中小团队自建服务。 - Chroma
偏轻量的本地向量库,Python 生态好,经常用在原型验证或本地 RAG Demo 里。
嵌入式/算法库
- Faiss(Facebook 出的)
更像是“向量检索算法库”,支持多种 ANN 索引结构和 GPU 加速,适合自己控制存储层、做离线或高性能向量检索,不直接提供服务能力。 - Annoy
偏读多写少、“查询多、构建少”的场景,常用于推荐、相似度搜索的离线/准在线场景。
具备向量能力的“通用数据库 / 搜索引擎”
- 比如 OpenSearch / Elasticsearch、PostgreSQL + pgvector、ClickHouse、Redis 等,现在都支持向量检索。
优点是:一套系统里把结构化字段 + 全文检索 + 向量检索都做了,运维成本低,适合原来就大量用这些系统的团队。
2. 选型时我一般从哪些维度考虑?
我会按几个维度和场景来选:
-
数据量 & QPS 规模
- 小规模、PoC:Chroma、Weaviate、本地 SQLite/pgvector 就够了。
- 中等规模、需要高可用:Qdrant、Milvus。
- 超大规模、对 SLA 有要求又不想运维:Pinecone 这类托管服务。
-
团队技术栈 & 运维能力
- 团队擅长 K8s / 云原生,并且有运维能力 → 选择 Milvus、Qdrant 这类专用向量库,性能和功能都比较强。
- 已经大量用 Elastic / Postgres,不想再引入新组件 → 优先考虑 ES/OpenSearch + 向量插件 或 pgvector,一套系统搞定。
-
功能需求
- 只要向量相似搜索,不怎么做复杂过滤 → Faiss / Annoy / 轻量库即可。
- 需要 向量 + 过滤条件 + 排序 + 多字段检索 → Milvus、Qdrant、Weaviate 或 ES/OpenSearch 这种“向量 + 结构化/全文”混合检索更合适。
-
成本与上线速度
- 想快速上线 MVP:Pinecone/Weaviate Cloud 这类托管服务,几乎不用运维。
- 想长期可控、节省成本:自建 Milvus / Qdrant / 开源方案。
3.“偏好组合”
小规模原型我一般用 Chroma 或 Weaviate;
线上中等规模业务会选 Qdrant 或 Milvus 做专用向量库;
如果公司本身 ES/Postgres 用得多,我会优先考虑 OpenSearch/ES + 向量插件 或 Postgres + pgvector,这样整体架构更简单;
对全球多 Region、SLA 要求高又不想自己运维的场景,会考虑 Pinecone 这类托管服务。
向量数据库原理是什么? 请简述下它的原理
向量数据库的核心原理,其实就是一句话:
把复杂的数据(文本、图片等)先变成向量,再通过高效的近似搜索算法,在海量向量里快速找到和查询最相似的那几个。
向量数据库的工作流程有哪些?请简述下
向量数据库的核心目标是:
把非结构化数据(如文本、图片)转成可计算的向量,并能快速做相似度检索。
整体流程可以分成 五个步骤:
① 数据处理(清洗与预处理)
对原始数据做清洗、去噪、归一化,提取结构化字段
如:标签、时间戳、作者信息等。
② 向量化(模型生成向量)
使用 AI 模型(如 BERT、ResNet 等)提取特征,
把文本、图片等转换成高维向量。
③ 向量存储(高效格式)
向量与原始数据绑定,一起存入向量数据库,
常见使用分布式存储、块存储等方式。
④ 构建索引(HNSW / LSH 等 ANN 结构)
为了加速搜索,对存储的向量建立高效的近似最近邻结构(ANN),
例如:
- HNSW 图索引
- LSH 哈希索引
⑤ 相似度检索(返回 Top-K)
用户查询时:
- 查询内容也会先被转成向量
- 使用索引快速定位“可能相似”的向量
- 计算相似度(如余弦相似度)
- 返回最相似的 Top-K 条结果
小结
向量数据库的流程就是:数据清洗 → 向量化 → 存储 → 建索引 → 相似检索,最终帮我们在海量数据中快速找到最相似的内容。
什么是 MCP 协议,它在 AI 大模型系统中的作用是什么?
什么是MCP
MCP(Model Context Protocol)是一套让大模型(LLM)统一、安全地调用外部数据、工具、服务的标准协议。
就像 USB-C 统一了电子设备接口一样,MCP 统一了 AI 调用外部能力的方式。
为什么需要 MCP?之前有什么痛点?
以前大模型要调用工具时,每个工具都要重新写适配层(Function Calling),例如:
- 微信写一套接口
- Excel 写一套接口
- Git 写一套接口
- 数据库再写一套……
每个模型厂商都要写一遍,开发成本高、重复劳动严重。
而且不同模型(ChatGPT、DeepSeek、Claude)之间接口不兼容。
MCP 解决的核心:统一标准,让工具写一次,所有兼容 MCP 的大模型都能调用。
“过去每个软件都要单独给 AI 做接口,现在 MCP 就像 USB-C,不用重复造轮子。”
MCP 的作用
- MCP 的作用是让大模型具备一致的能力去访问“上下文资源”,例如工具、文件、数据库、API。
- 它让大模型不仅能“回答问题”,还能“主动调用服务”,真正变成一个可编排的智能体(Agent)。
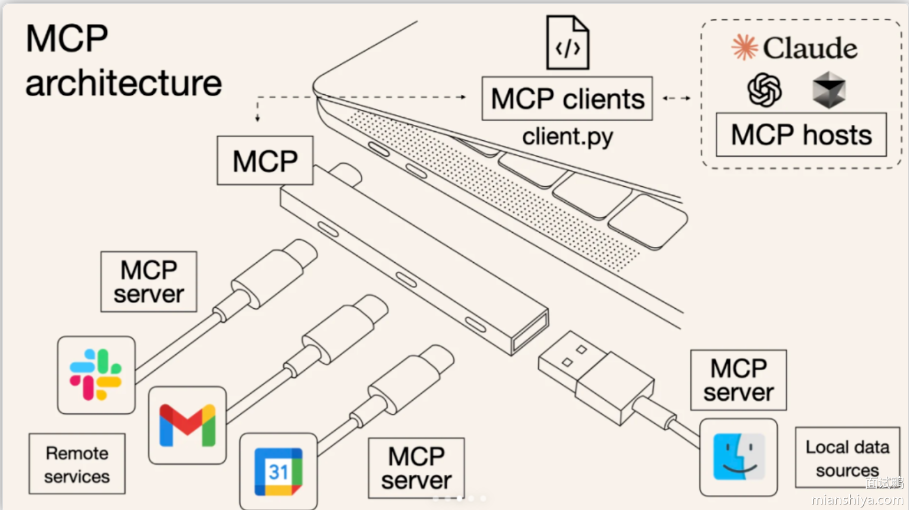
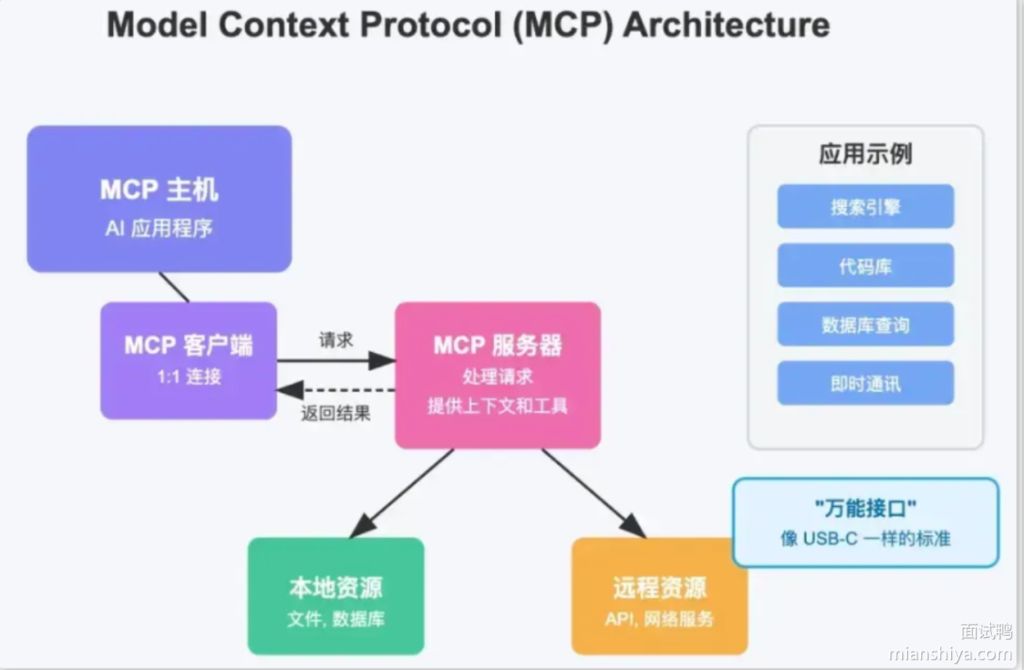
MCP 架构包含哪些核心组件?
MCP 的客户端-服务器架构:
1. MCP Host(主机)
发起请求的应用,例如:
- ChatGPT
- IDE(Cursor、VSCode)
- AI Agent 应用
它负责决定“什么时候需要外部工具”。
2. MCP Client(客户端)
Host 中的组件,负责维持与某个 MCP Server 的连接(1:1)。
可以理解为:
Host 的“工具管理器”。
3. MCP Server(服务器)
开发者编写的服务端,用来提供:
- 工具(Tools)
- 上下文(Context)
- 资源(Resources)
特点:只需要写一次,所有 MCP 模型都能用。
4. Local Resources(本地资源)
例如:
- 本地文件系统
- 本地数据库
- 本地配置
服务器可安全访问。
5. Remote Resources(远程资源)
例如:
- Web API
- 云数据库
- 企业内部系统
结构可总结为一句话:
Host(模型端) → Client(连接管理) → Server(工具/数据提供者) → Resource(真实资源)
MCP 协议支持哪两种模式?
MCP 支持的通信模式
STDIO(标准输入输出)
- 常用于本地集成、命令行工具
SSE(服务器发送事件)
-
用于 HTTP 流式长连接
-
支持流式输出结果(大模型常见)
MCP 与 Function Calling 的区别是什么?
| 技术 | 作用 |
|---|---|
| Tool Calling | 让模型调用某个工具(例如执行一个 API) |
| RAG | 让模型获取知识上下文(向量搜索) |
| MCP | 让模型调用“更多更复杂的外部系统”,包括工具 + 数据 + 文件 |
RAG 解决“我知道什么”,ToolCalling 解决“我能做什么”,MCP 解决“我能连接谁”。
MCP VS ToolCalling
- 之前每个大模型(如DeepSeek、ChatGPT)需要为每个工具单独开发接口(FunctionCalling),导致重复劳动
- MCP通过统一协议
- 开发者只需写一次MCP服务端,所有兼容MCP协议的模型都能调用,MCP让大模型从"被动应答”变为”主动调用工具”
- 我调用一个MCP服务器就等价调用一个带有多个功能的Utils工具类,自己还不用受累携带
MCP 的工作流程是什么?
MCP 的流程分 5 步:
- 客户端初始化后先从 MCP Server 获取工具列表;
- 用户提问后,客户端把问题和工具描述一起发给 LLM;
- 模型判断是否要调用工具,如果要就生成工具调用请求;
- MCP Server 真正执行工具并返回结果;
- 最后模型整合执行结果生成最终回复。
整个流程实现了 LLM 的“能力发现 → 决策 → 执行 → 汇总”的闭环。
什么是工具调用 Tool Calling?如何利用 Spring AI 实现工具调用?
什么是工具调用(Tool Calling)?
一句话:Tool Calling 就是让大模型“开口点单”,真正去干活的是我们注册的工具 / API。
LLM 本身只会算 token,不会真的去发 HTTP、查数据库、调业务代码。
有了 Tool Calling 之后,大模型可以说:“请调用 getWeather(city=上海)”,然后由我们的程序去执行这个方法,拿到结果再喂回给大模型,让它继续组织自然语言回答。
这样,大模型的“脑子”+ 外部工具的“手脚”结合起来,就能:
- 访问实时数据(天气、股价、数据库、内部系统接口等)
- 执行各种业务操作(发邮件、查询订单、创建工单、调用支付网关等)
可以把 Tool Calling 理解成:“LLM 的外部 utils 工具类 / 第三方插件系统”。
Tool Calling 的典型工作流程
- 用户提问
比如:“帮我查一下今天上海的天气,再顺便推荐一身穿搭。”
- 程序把问题丢给大模型
同时告诉大模型:我这里有一些工具(getWeather、getTime、查订单……)可以用。
- 大模型判断要不要用工具
它分析语义后觉得:“这题我自己编不靠谱,需要实时天气。”
于是产生一个“工具调用意图”,比如:
1 | { "tool": "getWeather", "args": { "city": "上海" } } |
- 应用程序真正去调工具
- 程序解析出工具名和参数
- 调用对应的 Java 方法 / HTTP 接口 / 脚本等,拿到真实结果
- 把结果再塞回大模型:
“工具 getWeather 返回:今天 25℃,多云,有小风……”
- 大模型整合工具结果给出最终回复
比如:
“上海今天 25℃多云,建议穿衬衫+长裤,出门带件薄外套。”
在 Spring AI 里实现工具调用很简单:用 @Tool 把 Java 方法暴露成工具,配置到 ChatClient,然后正常发起对话即可,Spring AI 会自动完成工具选择、调用和结果回填的完整闭环。
什么是 Spring AI 框架?它有哪些核心特性?
Spring AI 是 Spring 官方推出的 AI 应用框架,核心是把“AI 集成”变成像 Spring 一样简单。
- 它提供统一的模型调用 API,兼容几乎所有主流大模型;
- 支持结构化输出、工具调用、向量数据库与 RAG、ETL 文档处理、流式对话、拦截器等能力;
- 并通过 Spring Boot Starter 做了自动化集成,让 Java 能轻松构建企业级 AI 应用。
说说你理解的vibe Coding
vibe Coding它呢颠覆了我们以前写代码的那种方式,vibe Coding压根不关心你的代码具体是怎么实现的,核心关注的是代码生成的结果对还是不对,至于实现逻辑的底层细节这些繁琐活都交给AI,我们只需要盯着效果,哪有有问题就去改对应的prompt,AI呢就会自动帮你去调整,然后去优化直到符合预期为止。所以说vibe Coding是人类负责出题加审核,AI负责解题加改卷。
这种vibe Coding大幅提高了我们的效率,你不再需要花大量的时间去纠结底层逻辑,调试bug,查文档。我们可以把精力放到我到底想要什么上,执行细节全部交给AI,我们只负责review即可。
我用过的几个vibe Coding工具,比如cursor,国产的trae还有Code Buddy
