MQ相关面试题
GQ MQ
我看到你的GQ Video简历上提到了RocketMQ,你来讲讲你在这个项目上为什么用上了RocketMQ?
-
我们最初用的是“线程池 + Redis 列表”做异步,能用但有几个痛点:服务间耦合重、突发流量容易把线程和 Redis 顶满;失败重试、死信、消息追踪都要自己造轮子;一旦进程挂了,队列里的任务容易丢,排障也不直观。
-
所以我把“播放事件统计、转码任务”这两条链路迁到了 RocketMQ。好处很直接:
- 彻底解耦:发布方只管发,消费方独立扩缩容;
- 抗峰值更稳:堆积可观测,消费端可以水平扩展;发布端响应时间明显变短;
- 可靠性提升:自动重试、死信队列、顺序/延时/事务消息这些能力都是现成的,任务丢失概率大幅下降;
- 可观测:Topic 堆积、耗时、轨迹一目了然,问题定位快。
你为什么考虑的是RocketMQ这个消息队列而不是RabbitMQ或者Kafka?
-
之所以选 RocketMQ,而不是 RabbitMQ 或 Kafka,我主要考虑了这个项目的特点:
- 对 RabbitMQ:它路由模型很灵活,但吞吐相对没那么高;延时消息要装插件,顺序保证容易受限于单队列瓶颈。我们的“播放事件”和“转码发布**”更偏大吞吐+延时/顺序/重试**,RocketMQ 原生支持更合适。
- 对 Kafka:吞吐极强,做日志/流式计算非常好。但业务型消息常用的“单条精确重试、死信、延时、事务消息”需要额外组件或自研,运维门槛也更高。我们更看重业务可靠投递和易用性,所以优先 RocketMQ。
-
落地时我做了一个开关
mq.enabled:开启走 MQ,关闭就回退到原来的“线程池 + Redis 队列”,可以灰度切换、出问题一键回滚。幂等用数据库唯一键或 Redis 做了防重。
一句话总结:上 RocketMQ 后,我们把“重活、峰值、可靠性、可观测性”这些问题一次性解决了;对这个以业务消息为主的场景,RocketMQ 比 RabbitMQ 更省插件、比 Kafka 更贴合业务消息的开箱能力。
你具体讲讲播放事件统计、转码任务这两个任务,没上MQ你是怎么实现的,用了MQ你又是怎么实现的?
当然可以 👍 我帮你把这段技术回答改成一个更自然、面试口语化、容易讲顺的版本👇
💬 面试口语版回答(MQ 改造播放统计 & 转码任务)
我用两分钟把“上 MQ 前后”的差异讲清楚。
一、没上 MQ 之前
那时候我们还没引入消息队列,用的是「线程池 + Redis 列表」来异步处理任务。
-
播放事件:
前端上报播放,我这边直接把事件丢进 Redis 列表(LPUSH),后台有个线程池 while(true) 从列表里取(RPOP),
做三件事:视频播放数 +1、写播放历史、同步 ES 计数。但问题挺多的:高峰期线程容易打满、Redis 队列堆积难监控,失败重试、死信都得自己写。进程挂了也不好排查。
-
转码任务:
用户投稿上传完视频,我也是把转码任务信息塞进 Redis 列表,然后线程池轮询去拿,用 FFmpeg 转码、切片、传对象存储、最后更新数据库状态。
同样的问题:并发不好控、延时触发不方便、重试补偿全靠自己维护。
二、上 MQ(RocketMQ)之后
后来我们用 RocketMQ 做异步解耦,效果挺明显。
我设计了两个 Topic:
video-play专门处理播放事件video-transcode处理转码任务
然后写了一个通用发布器(Publisher),再配两个 Consumer。
另外加了个 mq.enabled 开关,可以灰度切换或快速回退到 Redis 方案。
- 播放事件这块:
发布端接到上报后,直接把事件对象发到 MQ,不再阻塞主线程。
消费端收到后,还是那三件事:数据库 +1、播放历史 upsert、ES 同步计数。
可靠性方面 RocketMQ 自带重试、死信、堆积可查,我还做了幂等处理(比如用 userId+videoId+fileIndex 做唯一键)。 - 转码任务这块:
用户提交稿件或合并分片后,我发一条转码消息到video-transcode。
消费端收到后调转码组件,用 FFmpeg 转码、上传 MinIO、更新状态。
并发我用 Semaphore 控制;异常重试、超出次数进死信队列,支持延时重试退避。
三、上 MQ 之后的变化
- 性能上:主流程只负责发消息,响应速度更快。
- 稳定性:堆积看得见,消费可水平扩,不容易被线程卡死。
- 可靠性:MQ 自带重试、死信、轨迹,可观测性很好。
- 扩展性:以后要加统计维度或新转码逻辑,只需多加个消费者,不改主流程。
✅ 一句话总结
以前用“线程池 + Redis 列表”能跑,但维护成本高、峰值容易崩;
上了 RocketMQ 后,我改成“发布订阅”模型,用它的重试、死信、延时和监控能力,把可靠性和扩展性都拉满,还能随时灰度回退,整体更稳更可控。
要不要我帮你再压缩成「30 秒速答版」?适合一开口就能讲流畅的那种。
说一下 RocketMQ 中关于事务消息的实现?
这个问题其实就是在考“RocketMQ 怎么保证消息和本地事务的一致性”。
RocketMQ 用的是两阶段提交 + 事务回查机制。
第一阶段:发送半消息(Half Message)
当我发送事务消息时,生产者会先往 MQ 里发一个“半消息”,也叫 Prepared 消息。
这个消息已经写入 Broker,但对消费者是不可见的。
然后生产者执行自己的本地事务,比如扣库存、加积分这些业务逻辑。
第二阶段:提交或回滚
本地事务执行完后有三种结果:
- 成功:生产者告诉 MQ “我这边事务 OK 了”,MQ 把半消息改成 正式消息,消费者就能看到。
- 失败:生产者通知 MQ 回滚,半消息就会被删除。
- 没回消息:如果 MQ 一直收不到 commit 或 rollback,它会主动回查。
事务回查(Transaction Check)
RocketMQ 会定期去问生产者:“你上次那个事务到底成了没?”
生产者实现 checkLocalTransaction 回调,返回三种状态:
- COMMIT_MESSAGE → 确认提交
- ROLLBACK_MESSAGE → 回滚消息
- UNKNOWN → 还没确定,Broker 过一会儿再问
这样即使网络异常、应用重启,也能靠回查机制最终确认消息状态。
为什么要这么设计?
如果不用事务消息,而是“本地事务先提交,再发消息”,一旦第二步发消息失败,就会造成业务成功但消息丢,数据不一致。
事务消息相当于先发半消息 → 执行业务 → 最后 commit,
就算 commit 消息失败,MQ 还能回查,最终也能补回来,保证一致性。
小结
RocketMQ 的事务消息通过“半消息 + 本地事务 + 回查机制”实现两阶段提交,
确保消息状态和业务事务状态保持一致,即使中途宕机也能恢复。
什么是消息队列?
消息队列是一种异步通信机制,用于在分布式系统中解耦发送方和接收方的通信。它通过在消息生产者和消费者之间引入一个中间缓冲区(broker),将消息存储在broker中,然后由消费者从brker中读取和处理消息。
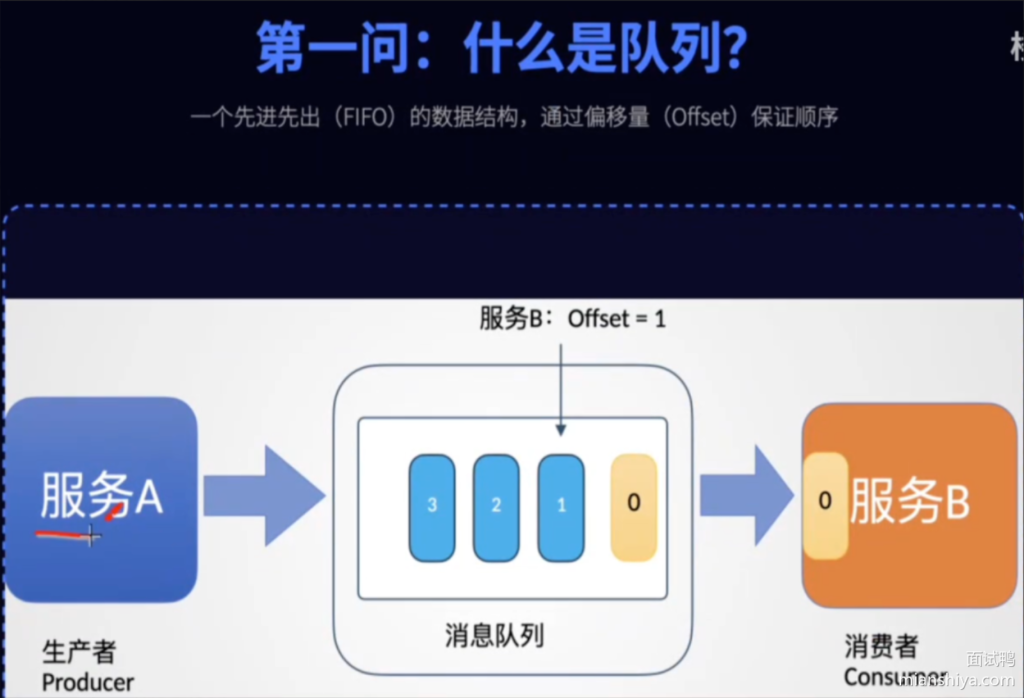
我举个最常见的例子来说: 假设服务 A 每秒要发 200 个请求给服务 B,但服务 B 一秒只能处理 100 个。 这时候如果直接调用,B 很快就被压垮了。
那怎么办?
这时候我们就在中间加一层“消息队列”。
A 不再直接把请求发给 B,而是先把消息丢进队列,B 再按照自己的节奏、自己的处理能力,从队列里一点点取出来消费。
这样,A 和 B 就被队列隔离开了,互不影响。
消息队列到底解决了什么问题?(消息队列的作用)
- 异步处理
-
以前 A 发完请求得等 B 处理完才能继续,现在有了 MQ,A 发完消息直接返回。
-
这样响应更快、系统吞吐量也更高。流量削峰(流量控制)
在高峰期,比如大促、秒杀时,请求量会瞬间暴增。
消息队列可以当“缓冲层”,先把请求堆起来,消费者慢慢消费,防止系统被冲垮。
这也是很多系统抗压的关键。 -
比如:下单之后再去发短信、发邮件这种操作,其实不需要同步完成,放 MQ 里异步处理就行。
- 服务解耦
- 有了消息队列,发送方和接收方就不再强绑定。
- A 只负责“发消息”,根本不用知道是谁来消费。
- 将来如果要多加几个消费者,比如一个做日志,一个做分析,直接订阅这个队列就行,完全不用改 A。
- 流量削峰(流量控制)
- 在高峰期,比如大促、秒杀时,请求量会瞬间暴增。
- 消息队列可以当“缓冲层”,先把请求堆起来,消费者慢慢消费,防止系统被冲垮。
- 这也是很多系统抗压的关键。
消息队列的核心价值是:
解耦、异步、削峰。
它让系统更快(异步),更松耦合(解耦),也更稳(削峰)。
为什么需要消息队列?
我举个最常见的例子来说:
假设服务 A 每秒要发 200 个请求给服务 B,但服务 B 一秒只能处理 100 个。
这时候如果直接调用,B 很快就被压垮了。
那怎么办?
这时候我们就在中间加一层“消息队列”。
A 不再直接把请求发给 B,而是先把消息丢进队列,B 再按照自己的节奏、自己的处理能力,从队列里一点点取出来消费。
这样,A 和 B 就被队列隔离开了,互不影响。
消息队列的典型应用场景:
- 订单系统:在电商系统中,订单的创建、支付、发货等步骤可以通过消息队列进行异步处理和解耦。
- 日志处理:使用消息队列将日志从应用系统传输到日志处理系统,实现实时分析和监控。
- 任务调度:在批量任务处理、任务调度系统中,通过消息队列将任务分发给多个工作节点,进行并行处理。
- 数据同步:在数据同步系统中,消息队列可以用于将变更的数据异步同步到不同的存储系统或服务。
那消息队列到底解决了什么问题?
- 异步处理
-
以前 A 发完请求得等 B 处理完才能继续,现在有了 MQ,A 发完消息直接返回。
-
这样响应更快、系统吞吐量也更高。流量削峰(流量控制)
在高峰期,比如大促、秒杀时,请求量会瞬间暴增。
消息队列可以当“缓冲层”,先把请求堆起来,消费者慢慢消费,防止系统被冲垮。
这也是很多系统抗压的关键。 -
比如:下单之后再去发短信、发邮件这种操作,其实不需要同步完成,放 MQ 里异步处理就行。
- 服务解耦
- 有了消息队列,发送方和接收方就不再强绑定。
- A 只负责“发消息”,根本不用知道是谁来消费。
- 将来如果要多加几个消费者,比如一个做日志,一个做分析,直接订阅这个队列就行,完全不用改 A。
- 流量削峰(流量控制)
- 在高峰期,比如大促、秒杀时,请求量会瞬间暴增。
- 消息队列可以当“缓冲层”,先把请求堆起来,消费者慢慢消费,防止系统被冲垮。
- 这也是很多系统抗压的关键。
消息队列的核心价值是:
解耦、异步、削峰。
它让系统更快(异步),更松耦合(解耦),也更稳(削峰)。
说一下消息队列的模型有哪些?
其实常见的消息队列模型主要有两种:队列模型和发布订阅模型。
队列模型(也叫点对点模型)
这个模型就像排队买咖啡。
生产者(比如点单的人)把消息放进队列,
消费者(比如咖啡师)从队列里一个个取消息来处理。
特点是:
- 每条消息只会被一个消费者处理一次(谁先拿到谁处理)。
- 消费完消息就从队列中删掉了。
这种模型适合“一个任务只需要一个人干”的场景,比如:
订单处理、视频转码、短信发送这种“谁处理都行”的任务分发场景。
发布 / 订阅模型(Publish / Subscribe)
这个模型就像微信公众号。
生产者(比如公众号)发一条消息到一个主题(Topic),
所有订阅这个主题的消费者(比如订阅号的用户)都会同时收到。
特点是:
- 一条消息会被多个订阅者同时收到。
- 特别适合广播通知、实时推送、监控告警这类场景。
比如我发布一条“系统更新通知”,只要订阅了这个 Topic 的系统都能收到消息。
消息队列主要有两种模型:
队列模型 一条消息只被一个消费者处理,适合任务分发;
发布订阅模型 一条消息可以被多个消费者收到,适合广播通知。
消息队列设计成推消息还是拉消息?推拉模式的优缺点?
消息队列有两种消费模式:推(Push) 和 拉(Pull)。
- 推模式:Broker 主动把消息推给消费者。
- 拉模式:消费者主动去 Broker 拉取消息。
RocketMQ 和 Kafka 其实都选择了“拉模式”,只是 RocketMQ 的“推”其实是封装了长轮询的拉模式,也就是消费者在后台不断长轮询去拉消息,看起来像是 Broker 在推。
所以本质上还是拉,只是体验像推。
优缺点对比一下
-
推模式优点:消息能实时送达,延迟很低;
- 缺点是如果消费者处理慢,Broker 一直推消息,容易把消费者压垮,尤其是高并发时不好做流控。
-
拉模式优点:消费者自己掌握节奏,可以根据自身负载调节拉取速率,避免过载,还能做批量拉取;
- 缺点就是实时性稍差,拉得太慢可能延迟会高一点。
为什么 RocketMQ 选拉模式
RocketMQ 和 Kafka 一样,选择拉模式主要是为了稳定和可控。
因为现在 MQ 都有“消息持久化”的需求——消息要先存好,再被消费。
所以用拉模式更安全,消费者按能力来拉,不会被推爆;再加上长轮询机制,也能兼顾实时性。
一句话总结:
推模式实时但容易压垮消费者,
拉模式可控但实时性略差。
RocketMQ 实际上是“伪推真拉”,底层用长轮询实现拉取,这样既能稳又能快。
RocketMQ 的事务消息有什么缺点?你还了解过别的事务消息实现吗?
先讲 RocketMQ 事务消息的优缺点,再顺带提到其他方案对比一下。
RocketMQ 事务消息的缺点
-
改造成本高
RocketMQ 的事务消息需要你去改造业务逻辑,把原本的发送逻辑拆成两步(半消息 + 提交),
还要实现一个回查接口 checkLocalTransaction,保证回查不会重复、不丢、不乱。
对已有业务侵入性比较大。 -
功能受限
它只支持单事务消息,没法处理跨多个 Topic 或多步骤的复杂分布式事务。
简单说,RocketMQ 的事务消息更偏“轻量分布式事务”,不是真正的全局事务。 -
可用性问题
如果 MQ 集群挂了,事务消息就没法继续执行。
因为事务消息机制是“先发半消息”,Broker 不可用时半消息发不出去,后续本地事务也没法往下走。
等于说 MQ 是事务执行的关键环节,一旦不可用整个流程都卡住。
其他事务消息方案
-
Kafka 事务消息
Kafka 的事务偏“生产者侧原子提交”,主要是保证“写入消息 + 提交 offset”一致,
更适合流式计算和 Exactly Once 语义,不太像 RocketMQ 这种业务型事务。 -
本地消息表(Outbox Pattern)
很多公司其实用这个方案。
就是业务操作和消息写入放在同一个本地事务里,然后异步任务去扫消息表发 MQ。
好处是实现简单、无 MQ 依赖,坏处是延迟略高、需要额外表和任务管理。 -
Seata 的 AT 模式 / TCC 模式
这类属于真正的分布式事务框架,强调强一致。
优点是自动补偿,缺点是侵入性更强,对性能影响更大。
小结
RocketMQ 的事务消息是通过“半消息 + 本地事务 + 回查”实现最终一致性的,但也有三个主要缺点:
一是改造成本高,要改业务逻辑并实现回查接口;
二是功能有限,只支持单事务,不适合跨 Topic;
三是依赖 MQ 可用性,Broker 挂了事务就卡住。
其他常见方案像 本地消息表 更简单易用,Seata 强一致但性能开销大。
所以 RocketMQ 的事务消息更适合“高可用、最终一致”的业务场景。
为什么 RocketMQ 不使用 Zookeeper 作为注册中心呢?而选择自己实现 NameServer?
RocketMQ 为什么要自主设计一个 NameServer,而不用其他现成的注册中心 zookeeper,nacos?
答:这个问题直击 RocketMQ 的设计核心,因为 RocketMQ 的核心是金融,电商这类非常灵活的业务场景服务的,这使得 RocketMQ 的整个设计思想和 Kafka 这样追求极致的吞吐的消息中间件有根本的区别,在保证高性能的同时,对于服务的可靠性也要做到极致。
- 一方面 NameServer 采用一种极为轻量级的集群方案,每个 NameServer 节点之间不需要和集群当中的其他节点发生任何的数据交互,这样可以保证 NameServer 集群当中只要有任何一个节点正常工作,那么整个 NameServer 集群就能够保持正常。
- 另一方面,业务的频繁更迭,使得 RocketMQ 也需要及时进行升级,自主研发的 NameServer 可以更灵活的应对新的业务场景
消息队列如何处理重复消息(保证消息的幂等性)?
首先,在消息队列里重复消息是一定会发生的。无论是 MQ 重投、网络抖动、Broker 写入成功但生产者没收到 ACK,或者消费者消费成功但没来得及提交 offset,都会导致同一条消息被多次投递。所以我们不能寄希望于“消息只来一次”,真正可靠的做法是让消费者的处理逻辑具有幂等性。
1. 核心思路:让业务逻辑幂等(处理多次结果一样)
① 基于唯一幂等号(业务 ID / 消息 ID)防重复
给消息里加一个唯一 ID(比如订单号、业务流水号、UUID)。
消费者在处理前先检查这个 ID 是否处理过:
- 处理过 → 直接跳过
- 没处理过 → 执行并记录这个 ID
可以把这个记录放在:
- Redis(高并发读写)
- 数据库(唯一索引、insert ignore)
- 业务表中的状态字段(如“已支付”、“已发货”)
② 利用数据库的唯一约束实现幂等
例如 MySQL 使用:
1 | insert into ... on duplicate key update ... |
或者条件判断:
1 | update t set money = 150 where id = 1 and money = 100; |
无论执行业务多少次,结果相同。
2. 为什么不能从源头完全避免重复消息?
- 生产者 → Broker 的确认可能丢
- Broker 已写入但 ACK 丢了 → 生产者重发
- 消费者处理成功但 offset 未提交 → 新的消费者会再次消费
因此重复消息是 无法彻底避免的,只能在消费端处理幂等。
小结
在 MQ 里,重复消息是无法彻底避免的,比如生产者重发、ACK 丢失、消费者 offset 未提交等。所以我们不依赖“消息只来一次”,而是让消费端具备幂等性。
常用的幂等处理方式有三种:
-
唯一业务 ID 防重(最常用)
消息里带一个唯一的幂等号,比如订单号、流水号。消费者处理前先查这个 ID 是否处理过,处理过就跳过。 -
Redis 防重(SETNX)
收到消息先执行 SETNX,成功才继续处理,失败说明重复消费。 -
数据库幂等(最终兜底)
- 条件更新:
update ... where status = 'UNPAID' - 唯一键约束:
insert ... on duplicate key update
保证重复执行不会影响最终结果。
- 条件更新:
一句话总结:
重复消息不可避免,但重复消费可控。核心是:唯一业务 ID + Redis 去重 + DB 幂等更新,执行多次结果保持一致。
举个例子 订单重复支付幂等处理
在我们的支付项目里,支付成功后会把消息投到 MQ,因为回调重试、Broker ACK 丢失、offset 未提交等原因,消息可能会被多次投递。为了避免重复扣库存、重复更新订单,我们做了完整的幂等设计。
核心做法有三点:
-
消息中携带唯一业务 ID(paymentId)
每条支付消息都有唯一流水号,用于判断是否处理过。 -
Redis 防重(SETNX)
消费端先用 Redis 做一次快速幂等校验,SETNX 成功才继续处理。 -
数据库层幂等
- 订单更新使用条件更新:
where pay_status = 'UNPAID',只会从未支付 → 已支付一次 - 支付记录表用唯一索引
paymentId,重复 insert 不会生效
- 订单更新使用条件更新:
最终效果:
无论 MQ 消息来几次,订单只更新一次,库存只扣一次,实现真正的幂等性。
消息队列如何保证消息的有序性(顺序性)?
MQ 想保证消息顺序,核心思想其实只有一句话:
让同一类相关的消息进入同一个队列,并让这个队列只被一个消费者、一个线程顺序处理。
下面按常见的 3 种方式总结:
① 单生产者 + 单消费者 + 单队列(最简单)
只要把消息全部发到一个队列,让消费者单线程处理,就天然有序。
缺点也很明显:性能瓶颈严重,不适合高并发场景。
② 使用分区 + 分区键(Partition Key)——Kafka / RocketMQ 最常用
做法:
- 设置一个 顺序键(如订单号、用户 ID)
- 用这个键做 hash 路由,让同一类业务消息始终进入同一个分区 / 队列
例如:订单号相同的消息全部进入 Queue #3
这样每个分区内部天然是顺序的,又能通过多个分区 提高并发能力。
③ 使用顺序队列(Ordered Queue)机制
像 RabbitMQ、某些 MQ 提供 原生顺序队列:
- 存储顺序 = 投递顺序 = 消费顺序
- 但要求“同一顺序队列只能配一个消费者”,吞吐量有限
RocketMQ 的顺序消息(补充)
RocketMQ 的顺序消息除了分区路由外,还需要:
- MessageQueueSelector 控制路由
- MessageListenerOrderly 顺序消费模式
- 同时在消费端 三层加锁(Broker Queue 锁、MessageQueue 锁、ProcessQueue 锁)来确保只有一个线程顺序处理队列消息
小结
MQ 保证顺序的核心就是:让同一类消息进入同一个队列,并由一个消费者顺序处理。
常见做法有三种:
-
单队列 + 单消费者
所有消息进一个队列,单线程消费,天然有序,但吞吐量低。 -
分区 + 分区键(最常用,如 Kafka、RocketMQ)
通过 Partition Key(如订单号) 做路由,让同一业务的消息都落到同一个分区;分区内部天然有序,还能利用多分区并发。 -
使用顺序队列(一些 MQ 原生支持)
顺序队列保证写入顺序 = 投递顺序 = 消费顺序。
一句话总结:
顺序性 = 相同消息路由到同一队列 + 单线程顺序消费。
消息队列如何处理消息堆积?
消息堆积本质上是 生产速度 > 消费速度,导致大量消息积在队列里。所以解决思路就是提升消费能力、降低生产速度,或者清理无效消息。
可以从以下几方面来处理:
① 增加消费者的并发能力(最有效)
- 增加消费者线程数 → 提高单实例并发度
- 增加消费者实例数 → 多机器一起消费,提高整体吞吐
② 优化消费者消费逻辑
- 减少单条消息的处理时延
- 提高数据库批量写效率、减少 I/O
- 引入线程池异步处理
③ 降低生产者速度(如果可控)
- 对生产端限流
- 消息分级,只优先处理关键消息
④ 清理过期或无效消息
如果某些消息已无业务价值,可以评估后丢弃,快速消化堆积。
⑤ 调整 MQ 配置 / 增加队列数
- 增加 Topic 的队列数量,提高并行度
- 调整 MQ 消费模式、拉取频率等配置
小结
消息堆积主要是因为消费速度跟不上生产速度,所以解决方式就是提高消费能力或降低生产速度。
常见处理办法 3 步:
-
扩大消费能力(最有效)
- 增加消费者实例数
- 增加消费者线程
- 增加 Topic 队列数,提高并行度
-
优化消费逻辑
- 减少单条消息处理时间
- 批量处理、减少 I/O、引入线程池
-
必要时限流或丢弃无效消息
- 控制生产端速度
- 清理过期/失败无意义的消息
一句话总结:
核心就是提升消费能力,加并发、加实例、提高效率;如果不行,就限流生产或清理无效消息。