AIGC应用与智能体开发之大模型私有部署
一.大模型私有部署
1.学习目标与AIGC相关概念
今天的学习内容中主要包含了以下内容:
- 了解人工智能
- Ollama的介绍与使用
- 快速构建企业聊天机器人
- 快速构建企业知识库
- 快速构建企业Codepilot
- 如何制作一个私有化的大模型并部署
- 作业练习(基于Ollama快速构建OpenWebUI)
总学习目标:
- 通过对大模型私有化部署的学习,能够在未来的AI项目中熟练搭建或应用AI大模型的开发、测试、生产等环境。以及快速为企业内部搭建私有化的知识库。
阶段学习目标:
- 能够使用Ollama私有化部署本地大模型
- 能够熟练使用Ollama的客户端命令
- 能够熟悉Ollama提供的API接口
- 能够使用Ollama快速搭建ChatBot
- 能够使用Ollama快速搭建知识库应用
- 能够使用Ollama快速搭建Codepilot应用
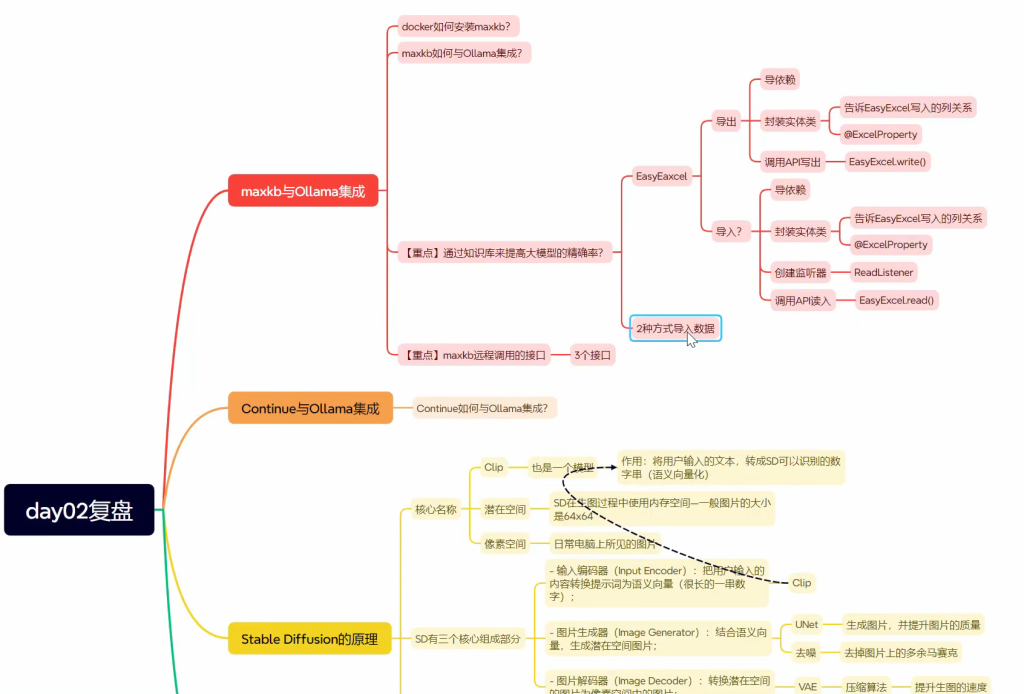
1.学习路线

2.业务架构
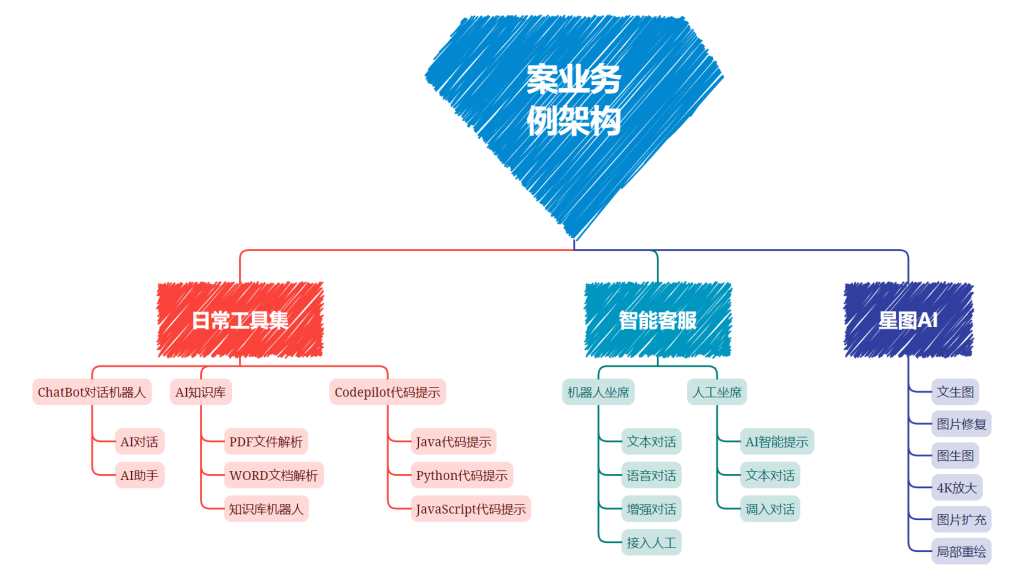
JavaAIGC 应用与智能体开发课程以小案例驱动学习相关技术知识,因此本课程中的案例业务不是一个大而完整的长业务,而是独立的、在企业中常用的小业务,这样设计我们便于快速学习与理解相关AI知识。
课程中的业务案例一共分为四个部分:
- 日常工具业务:综合了日常企业中常用的AI工具集,提供ChatBot机器人聊天、基于知识库的聊天、以及Codepilot智能代码生成等工具的业务案例功能
- 星语智能客服:在传统客服中,加入AI功能,支持机器人客服、可以有效的降低客服成本,并增加行业对话话术模型、增强工具等功,提高服务服务质量
- 星图AI业务:通过AI技术,让文字生成对应的文档素材图片,降低用户查找素材成本,还可提供图片修复、放大等第门槛的图片编辑功能
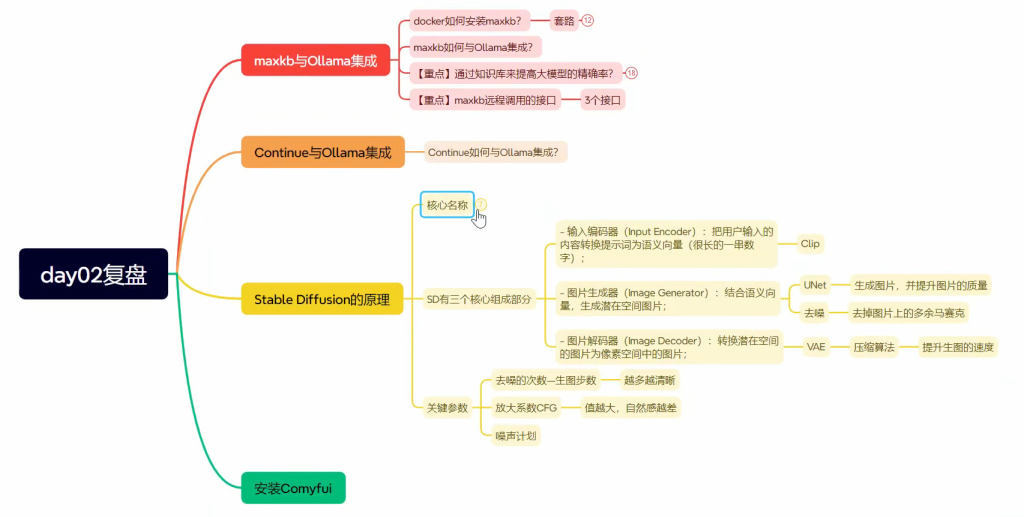
3.技术架构
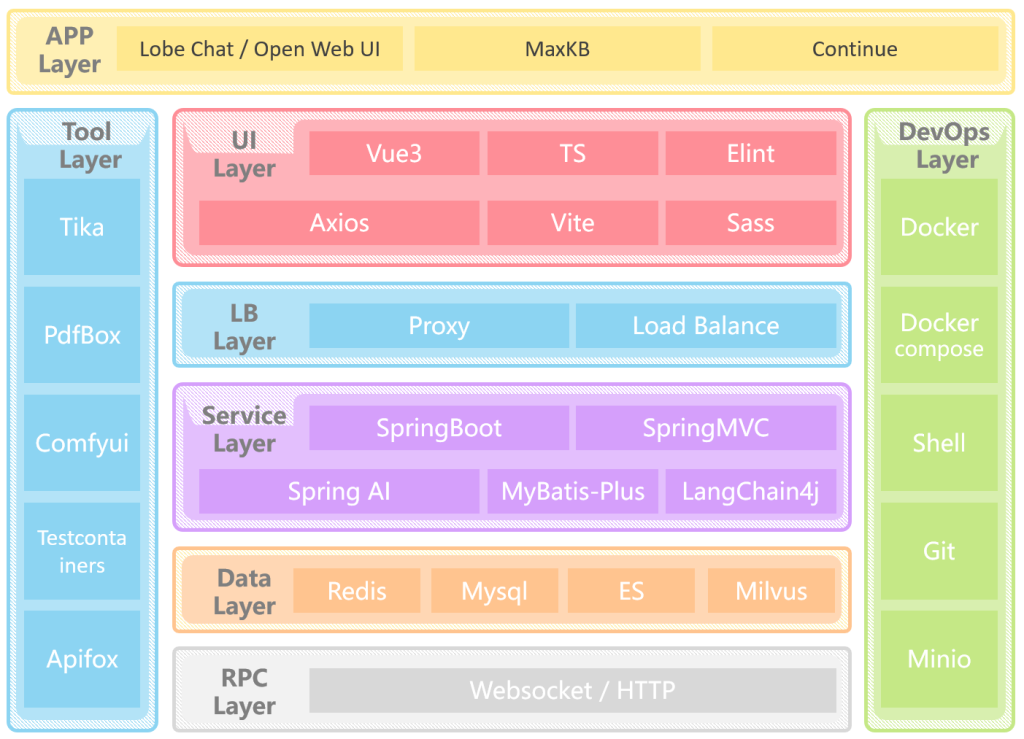
课程中用到的技术可以分为8层:
- 应用层(APP Layer): 直接使用成熟的开源工具LobeChat,MaxKB,Continue等来快速搭建用户可视化操作界面
- 界面层(UI Layer):项目中所有前端界面都采用Vue3相关技术栈进行开发
- 负载层(LB Layer):负载通过Nginx来实现反向代理和负载均衡
- 服务层(Service Layer):通过Spring Boot来快速构建项目,然后通过SpringAI / LangChain4j来实现相关AI功能的的开发
- 工具层(Tool Layer):AI软件开发过程中会用到很对外置工具,用来对AI内容进行前后置处理,比如通过TIke、PdfBox来ELT清洗文档数据,然后传入AI对话
- 数据层(Data Layer):课程中使用Redis和ES、Mysql来存储或缓存关系数据,而使用Milvus来存储AI向量相关的内容
- 运维层(DevOps Layer):课程中全面使用Docker来构建开发环境
2.导入虚拟机
在当前linux系统中包含的开发环境有:
- Mysql:开发环境的数据库
- Redis:开发环境的redis
- Docker:开发环境的部署工具
- nginx :代理服务
挂载虚拟机
解压《JavaAIGC虚拟机.zip》文件,解压后,进入解压的虚拟机镜像文件夹,双击AIGC.vmx即可挂载到你的虚拟机中(需提前安装虚拟机)。
设置虚拟网络
因为此虚拟机已设置静态的ip地址,目前网段就是192.168.100.0,所以为了减少环境网络的配置,可以手动设置虚拟机中NAT网卡的网段
设置步骤:
①:找到虚拟机的编辑按钮,打开虚拟网络编辑器
②:选中NAT模式的网卡,在下面的子网IP的输入框中手动设置为:192.168.100.0,确定保存即可

③:右键虚拟机–>设置–>网络适配器–>自定义:选择NAT网卡连接模式
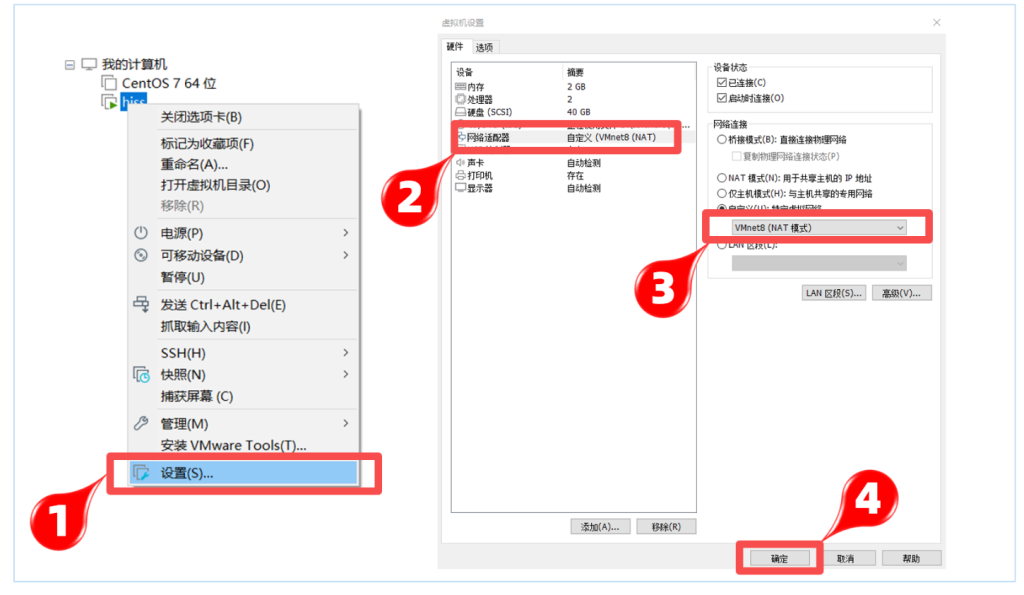
④:启动服务器(网络设置完成后再启动服务器)
FinalShell客户端链接
此虚拟机的静态ip为:192.168.100.129,防火墙已关闭,可以直接使用客户端链接
以FinalSehll工具为例:

注意:此虚拟机的用户名:root,密码:itcast
内置环境说明
在虚拟机中/root目录中内置了两套环境:
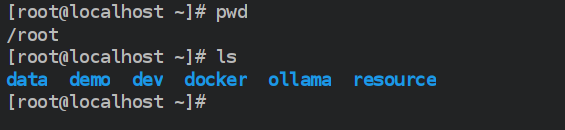
- data是数据库、代码仓库等重要数据,千万勿删!!
- demo是整体项目演示的环境,方便大家快速启动查看项目效果,可选择删除。
- dev是开环境的环境,本课程学习过程需要用到的环境,千万勿删!!
- docker是后续学习过程中用到的系列镜像文件,千万勿删!!
- ollama是后续学习本地大模型的存储文件,千万勿删!!
- resource是后续用到的系列软件资源,千万勿删!!
3.私有大模型
为什么要有私有大模型?
企业数据隐私与安全的问题,在许多行业,如金融、医疗、政府等,数据隐私和安全是至关重要的。使用公共大模型可能涉及敏感数据的泄露风险,因为公共模型在训练过程中可能接触到了来自不同来源的敏感数据。因此就有了私有大模型的市场需求,私有大模型允许企业或机构在自己的数据上训练模型,而且训练的结果只供内部或合作伙伴使用,从而确保了数据隐私和安全。
私有大模型解决方案
随着AI的发展,越来越多的开发者投入到大模型开发中,他们期望能自身笔记本上运行大模型,以便开发。越来越多的企业积极改造自身产品,融入AI技术,他们期望能私有化大模型以保证数据安全。这些诉求直接推动社区出现了两个这方面的产品Ollama和LMstudio。
这两个产品各有优势:
| Ollama | LM Studio | |
|---|---|---|
| 产品定位 | 开源的大型语言模型本地运行框架 | 闭源的本地大型语言模型工作站,集模型训练、部署、调试于一体 |
| 技术特点 | - 高度智能化,自主学习和适应能力强 - 便捷性高,操作简单易懂 - 安全性强,数据传输和存储严格保护 | - 高性能,采用先进计算架构和算法优化 - 可定制化,支持用户定制模型结构和训练策略 - 易用性,友好的用户界面和丰富的文档支持 |
| 功能 | - 提供预训练模型访问和微调功能 - 支持多种模型架构和定制模型 - 用户友好界面,简化模型实验和部署过程 | - 丰富的训练数据和算法库 - 可视化训练监控界面 - 强大的调试工具,支持模型性能优化 |
| 应用场景 | - 学术研究 - 开发者原型设计和实验 - 创意写作、文本生成等 | - 智能客服 - 自然语言处理(如文本分类、情感分析、机器翻译) - 学术研究 |
| 用户友好性 | - 界面化操作,适合不同水平的用户 - 支持多种设备和平台 | - 友好的用户界面,适合初学者和非技术人员 - 提供全面的工具组合,易于上手 |
| 定制性 | - 提供一定程度的定制选项,但可能有限制 | - 高度可定制化,满足用户个性化需求 |
| 资源要求 | - 需要一定的内存或显存资源来运行大型模型 - 支持跨平台(macOS、Linux,Windows预览版) | - 构建和训练复杂模型可能需要大量计算资源和专业技能 |
| 成本 | - 成本可能根据使用量和资源需求变化 - 开源项目,可能涉及较少的直接成本 | - 闭源产品,成本可能包括软件许可和可能的云服务费用 |
| 社区生态 | - 社区生态活跃,开发者主流本地运行时 - 快速适配新发布的模型 | - 未知(未提及具体社区生态活跃度) |
Ollama 作为一个开源的轻量级工具,适合熟悉命令行界面的开发人员和高级用户进行模型实验和微调。它提供了广泛的预训练模型和灵活的定制选项,同时保持了高度的便捷性和安全性。最重要它是开源的,同时还提供API,对于开发有先天优势,因此在企业中备受欢迎和使用,因此本课程也才主要学习Ollama技术。
4.Ollama 入门
Ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发。
特点:
- 一站式管理:Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节,包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。
- 热加载模型文件:支持热加载模型文件,无需重新启动即可切换不同的模型,这不仅提高了灵活性,还显著增强了用户体验。
- 丰富的模型库:提供多种预构建的模型,如Llama 2、Llama 3、通义千问等,方便用户快速在本地运行大型语言模型。
- 多平台支持:支持多种操作系统,包括Mac、Windows和Linux,确保了广泛的可用性和灵活性。
- 无复杂依赖:通过优化推理代码并减少不必要的依赖,Ollama能够在各种硬件上高效运行,包括纯CPU推理和Apple Silicon架构。
- 资源占用少:Ollama的代码简洁明了,运行时占用资源少,使其能够在本地高效运行,不需要大量的计算资源。
1.下载与安装
手动安装
Ollama共支持三种平台:
window和mac版本直接下载安装或解压即可使用。这里由于Ollama需要安装在linux中,因此在这里主要学习如何在Linux上安装:
Step 1. 安装
在虚拟机/root/resource目录中已经下载好Linux版本所需的ollama-linux-amd64.tgz文件,则执行下面命令开始安装:
1 | tar -C /usr -xzf ollama-linux-amd64.tgz |
操作成功之后,可以通过查看版本指令来验证是否安装成功
1 | [root@bogon resource]# ollama -v |
Step 2. 添加开启自启服务
创建服务文件/etc/systemd/system/ollama.service,并写入文件内容:
1 | [Unit] |
生效服务:
1 | sudo systemctl daemon-reload |
启动服务:
1 | sudo systemctl start ollama |
一键安装
Ollama在Linux上也提供了简便的安装命令,但是过程中需要下载400M左右的数据,但在工作中一般采用下面命令进行安装:
1 | curl -fsSL https://ollama.com/install.sh | sh |
centos7如何安装最新版本Ollama?
解决centos7 安装ollama 运行 ollama -v 报错解决 详情参考这篇文章完美解决!
centos7 安装ollama 运行 ollama -v 报错解决-腾讯云开发者社区-腾讯云
2.运行通义千问大模型
在终端输入一下命令即可运行通义千问大模型: ollama run qwen2:0.5b
1 | [root@bogon resource]# ollama run qwen2:0.5b |
为运行一个本地大模型的命令,这个命令的格式为:
1 | ollama run 模型名称:模型规模 |
修改模型路径
直接运行上述小节命令,会下载300多M的数据,比较慢,而在虚拟机中已经提前下载好了相关模型(包括后续用到的模型),存储在/root/ollama目录中,因此这里我们需要修改ollama的模型路径,ollama软件在各个操作系统上的默认存储路径是:
1 | macOS: ~/.ollama/models |
要修改其默认存储路径,需要通过设置系统环境变量来实现,即在/etc/profile文件中最后增加一下环境变量:
1 | export OLLAMA_MODELS=/root/ollama |
然后执行一下命令,生效环境变量:
1 | [root@bogon ollama]# source /etc/profile |
然后重新ollama服务,则会跳过下载,直接进入大模型,对话完成后可以通过/bye指令终止对话:
1 | [root@bogon ollama] |
让重启也支持模型路径:
上述方式修改后,通过ollama命令是生效的,但是重启电脑则不生效,要解决这个问题,则还需要进行如下配置:
修改服务文件/etc/systemd/system/ollama.service内容为一下::
1 | [Unit] |
生效修改的配置:
1 | systemctl daemon-reload |
3.对话指令详解
在Ollama终端中提供了一系列指令,可以用来调整和控制对话模型:

/? 指令
/? 指令主要是列出支持的指令列表
1 | [root@bogon ~]# ollama run qwen2:0.5b |
/bye 指令
退出当前控制台对话
1 | [root@bogon ~] |
/show 指令
用于查看当前模型详细信息
1 | [root@bogon ~]# ollama run qwen2:0.5b |
/show info 查看模型的基本信息
1 | >>> /show info |
/show license 查看模型的许可信息—开源软件的许可协议
1 | >>> /show license |
/show modelfile 查看模型的制作源文件Modelfile
modelfile :文件是用来制作私有模型的脚步文件,后续课程学习
/show parameters 查看模型的内置参数信息
1 | >>> /show parameters |
/show system 查看模型的内置system信息—system常常用来定一些对话角色扮演
1 | >>> /show system |
/show template 查看模型的提示词模版
template:是最终传入大模型的字符串模版,模版中的内容由上层应用动态传入
/? shortcuts 指令
查看在控制台中可用的快捷键
1 | >>> /? shortcuts |
“”" 指令
“”" 用于输入内容有换行时使用,如何多行输入结束也使用 “”"
1 | """ |
/set 指令
set指令主要用来设置当前对话模型的系列参数
1 | >>> /set |
/set parameter … 设置对话参数
1 | >>> /set parameter |
| Parameter | Description | Value Type | Example Usage |
|---|---|---|---|
| num_ctx | 设置上下文token大小. (默认: 2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型要回顾的距离以防止重复. (默认: 64, 0 = 禁用, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置惩罚重复的强度。较高的值(例如,1.5)将更强烈地惩罚重复,而较低值(例如,0.9)会更加宽容。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度将使模型的答案更有创造性。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将其设置为特定的数字将使模型为相同的提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置停止词。当遇到这种词时,LLM将停止生成文本并返回 | string | stop “AI assistant:” |
| num_predict | 生成文本时要预测的最大标记数。(默认值:128,-1 =无限生成,-2 =填充上下文) | int | num_predict 42 |
| top_k | 减少产生无意义的可能性。较高的值(例如100)将给出更多样化的答案,而较低的值(例如10)将更加保守。(默认值:40) | int | top_k 40 |
| top_p | 与Top-K合作。较高的值(例如,0.95)将导致更多样化的文本,而较低的值(例如,0.5)将产生更集中和保守的文本。(默认值:0.9) | float | top_p 0.9 |
| num_gpu | 设置缓存到GPU显存中的模型层数 | int | 自动计算 |
JSON格式输出
1 | /set format json |
输出对话统计日志
1 | >>> /set verbose |
/clear 指令
在命令行终端中对话是自带上下文记忆功能,如果要清除上下文功能,则使用/clear指令清楚上下文内容,例如:
前2个问题都关联的,在输入/clear则把前2个问题的内容给清理掉了,第3次提问时则找不到开始的上下文了。
1 | 请帮我出1道java list的单选题 |
/load 指令
load可以在对话过程中随时切换大模型
1 | 你是什么大模型 |
/save 指令
可以把当前对话模型存储成一个新的模型
1 | >>> /save test |
保存的模型存储在ollama的model文件中,进入下面路径即可看见模型文件test:
1 | [root@bogon library]# pwd |
4.客户端命令详解
Ollama客户端还提供了系列命令,来管理本地大模型,接下来就先了解一下相关命令:
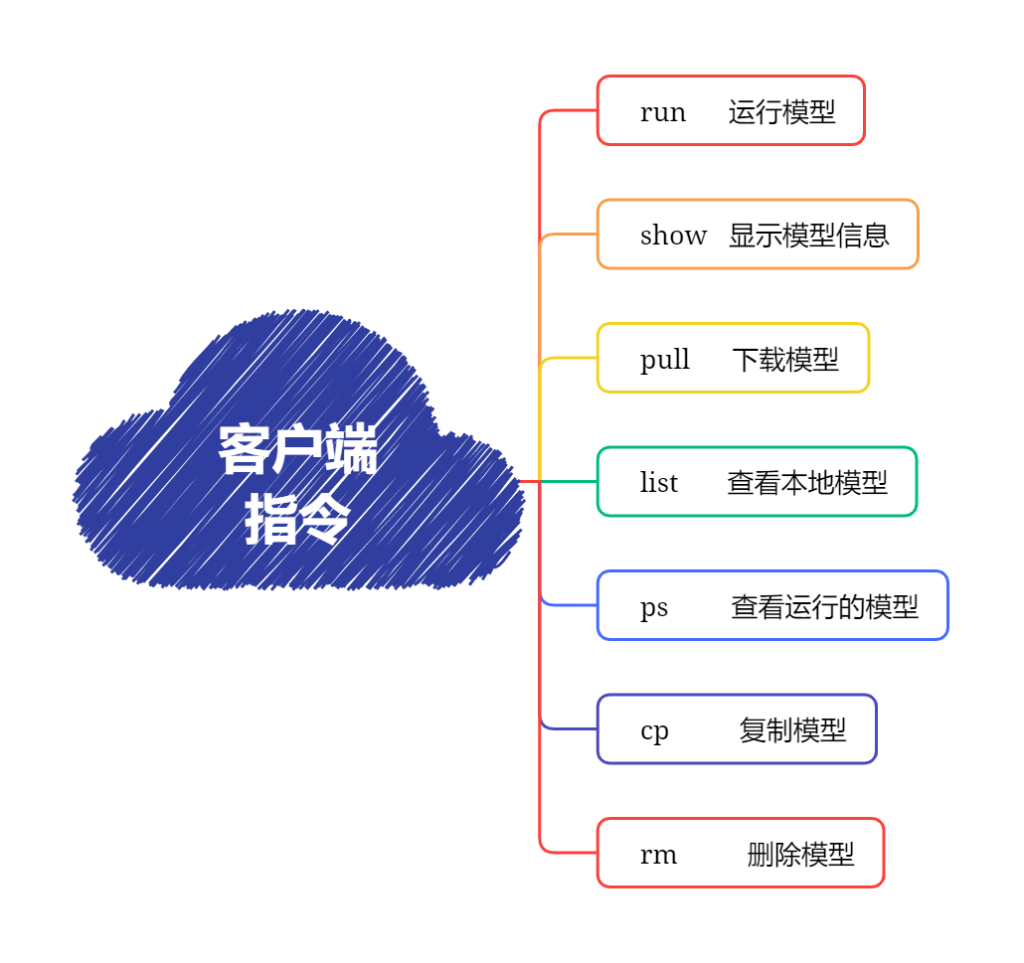
run 命令
run命令主要用于运行一个大模型,命令格式是:
1 | ollama run MODEL[:Version] [PROMPT] [flags] |
[:Version] 可以理解成版本,而版本信息常常以大模型规模来命名,可以不写,不写则模式成latest
1 | ollama run qwen2 |
[PROMPT] 参数是用户输入的提示词,如果带有此参数则,run命令会执行了输入提示词之后即退出终端,即只对话一次。
1 | [root@bogon ~] |
[flags] 指定运行时的参数
1 | Flags: |
例如,在启动时增加 --verbose参数,则在对话时,自动增加统计token信息:
1 | [root@bogon ~]# ollama run qwen2:0.5b --verbose |
show 命令
不用运行大模型,查看模型的信息,与之前所学的/show功能类似。
1 | [root@bogon ~]# ollama show -h |
例如,查看提示词模版:
pull 命令
查询模型名称的网站:https://ollama.com/
从远程下载一个模型,命令格式是:
1 | ollama pull MODEL[:Version] [flags] |
[:Version] 可以理解成版本,但在这里理解成大模型规模,可以不写,不写则模式成latest
1 | ollama pull qwen2 |
[flags] 参数,目前只有一个–insecure参数,用于来指定非安全模式下载数据
1 | ollama pull qwen2 --insecure |
list/ls 命令
查看本地下载的大模型列表,也可以使用简写ls
1 | [root@bogon ~]# ollama list |
列表字段说明:
- NAME:名称
- ID:大模型唯一ID
- SIZE:大模型大小
- MODIFIED:本地存活时间
注意:在ollama的其它命令中,不能像docker一下使用ID或ID缩写,这里只能使用大模型全名称。
ps 命令
查看当前运行的大模型列表,PS命令没其它参数
1 | [root@bogon ~] |
列表字段说明:
- NAME:大模型名称
- ID:唯一ID
- SIZE:模型大小
- PROCESSOR:资源占用
- UNTIL:运行存活时长
rm 命令
删除本地大模型,RM命令没其它参数
1 | [root@localhost system]# ollama ls |
5.API 详解
开通远程访问
为了在本机(开发环境)中能访问虚拟机中的Ollama API,我们需要先开通Ollama的远程访问权限:
Step 1:增加环境变量
在/etc/profile中增加一下环境变量:
1 | export OLLAMA_HOST=0.0.0.0:11434 |
然后通过一下命令,生效环境变量:
1 | source /etc/profile |
Step 2:增加服务变量
修改服务文件/etc/systemd/system/ollama.service内容为一下:
1 | [Unit] |
生效修改的配置:
1 | systemctl daemon-reload |
Step 3:开通防火墙
1 | firewall-cmd --zone=public --add-port=11434/tcp --permanent |
也可以关闭防火墙:
1 | systemctl stop firewalld |
导入Apifox文档
为了方便后续使用程序接入Ollama中的大模型,在此可以先通过Apifox进行Api的快速体验与学习。在资料文件夹中《Ollama.apifox.json》文件提供了供Apifox软件导入的json内容,再此我们先导入到Apifox软件中,快速体验一下API相关功能。
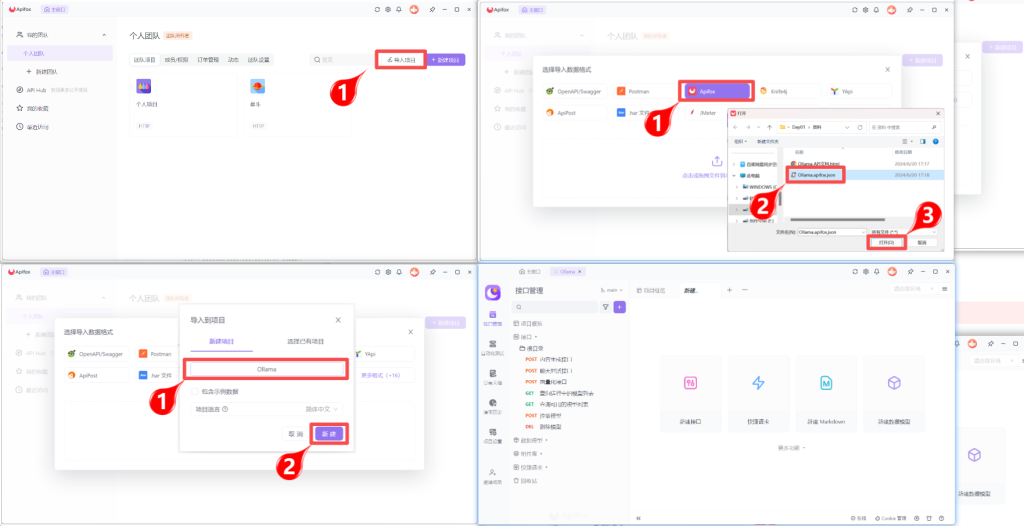
配置环境地址
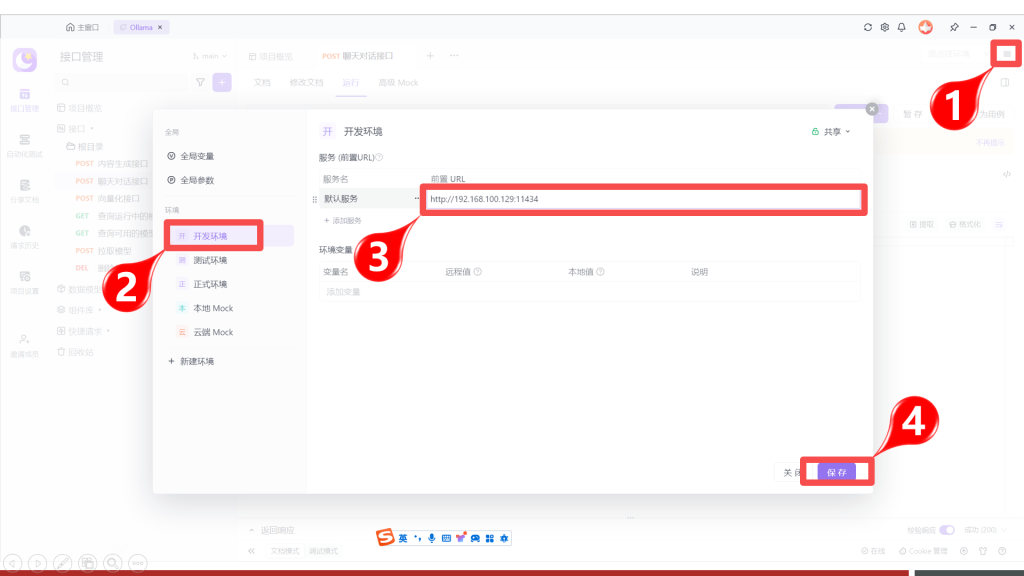
Oallma支持的API可以在资料文件夹中通过《Ollama API文档.html》了解详解,双击打开查看:

通过网页可以了解到Ollama支持7个API (这里只列举了常用的),接下来我们重点先了解对话和向量化接口,因为这两个接口是最重要的,其它接口则留给大家课后自行尝试,但是在正式体验之前,需要先配置一下环境地址。
配置测试环境地址:
聊天对话接口说明
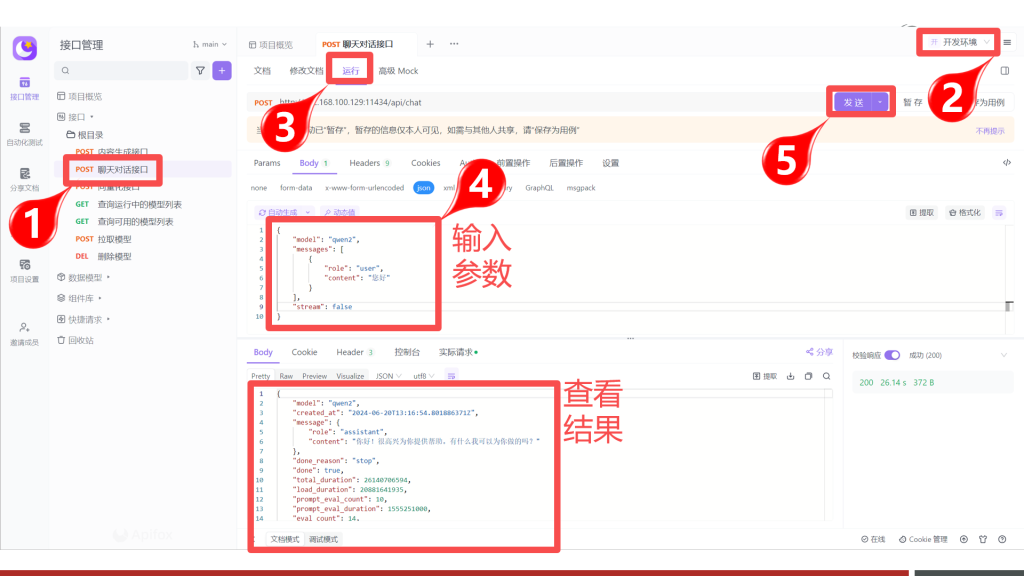
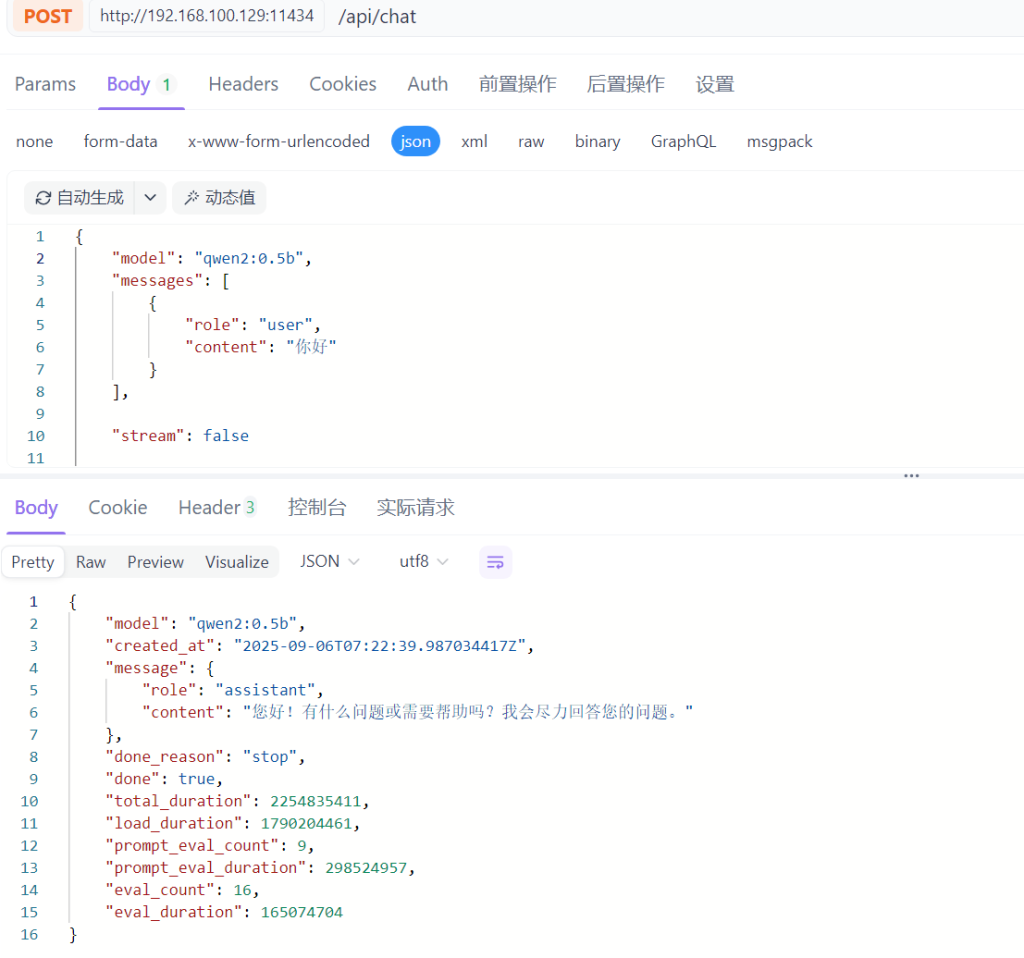
聊天对话接口,是实现类似ChatGPT、文心、通义千问等网页对话功能的关键接口,请求的地址与参数如下:
POST /api/chat
1 | { |
请求参数
| 名称 | 位置 | 类型 | 必选 | 中文名 | 说明 |
|---|---|---|---|---|---|
| body | body | object | 否 | none | |
| model | body | string | 是 | 模型名称 | none |
| messages | body | [object] | 是 | 聊天消息 | none |
| role | body | string | 是 | 角色 | system、user或assistant |
| content | body | string | 是 | 内容 | none |
| images | body | string | 否 | 图像 | none |
| format | body | string | 否 | 响应格式 | none |
| stream | body | boolean | 否 | 是否流式生成 | none |
| keep_alive | body | string | 否 | 模型内存保持时间 | 5m |
| tools | body | [object] | 否 | 工具 | |
| options | body | object | 否 | 配置参数 | none |
| seed | body | integer | 否 | 生成种子 | none |
| top_k | body | integer | 否 | 多样度 | 越高越多样,默认40 |
| top_p | body | number | 否 | 保守度 | 越低越保守,默认0.9 |
| repeat_last_n | body | integer | 否 | 防重复回顾距离 | 默认: 64, 0 = 禁用, -1 = num_ctx |
| temperature | body | number | 否 | 温度值 | 越高创造性越强,默认0.8 |
| repeat_penalty | body | number | 否 | 重复惩罚强度 | 越高惩罚越强,默认1.1 |
| stop | body | [string] | 是 | 停止词 | none |
返回示例
1 | { |
返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | 成功 | Inline |
返回数据结构
状态码 200 时才返回以下信息。
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
|---|---|---|---|---|---|
| model | string | true | none | 模型 | none |
| created_at | string | true | none | 响应时间 | none |
| message | object | true | none | 响应内容 | none |
| role | string | true | none | 角色 | none |
| content | string | true | none | 内容 | none |
| tool_calls | [object] | false | none | 调用的工具集 | |
| done | boolean | false | none | none | |
| total_duration | integer | false | none | 总耗时 | none |
| load_duration | integer | false | none | 模型加载耗时 | none |
| prompt_eval_count | integer | false | none | 提示词token消耗数 | none |
| prompt_eval_duration | integer | false | none | 提示词耗时 | none |
| eval_count | integer | false | none | 响应token消耗数 | none |
| eval_duration | integer | false | none | 响应耗时 | none |
对话操作演示
视觉对话演示
随着技术与算力的进步,大模型也逐渐分化成多种类型,而在这些种类中比较常见的有:
- 大语言模型:用于文生文,典型的使用场景是:对话聊天—仅文字对话Qwen、ChatGLM3、Baichuan、Mistral、LLaMA3、YI、InternLM2、DeepSeek、Gemma、Grok 等等
- 文本嵌入模型:用于内容的向量化,典型的使用场景是:模型微调text2vec、openai-text embedding、m3e、bge、nomic-embed-text、snowflake-arctic-embed
- 重排模型:用于向量化数据的优化增强,典型的使用场景是:模型微调bce-reranker-base_v1、bge-reranker-large、bge-reranker-v2-gemma、bge-reranker-v2-m3
- 多模态模型:用于上传文本或图片等信息,然后生成文本或图片,典型的使用场景是:对话聊天—拍照批改作业Qwen-VL 、Qwen-Audio、YI-VL、DeepSeek-VL、Llava、MiniCPM-V、InternVL
- 语音识别语音播报:用于文生音频、音频转文字等,典型的使用场景是:语音合成Whisper 、VoiceCraft、StyleTTS 2 、Parler-TTS、XTTS、Genny
- 扩散模型:用于文生图、文生视频,典型的使用场景是:文生图AnimateDiff、StabilityAI系列扩散模型
在这些模型中,Ollama目前仅支持大语言模型、文本嵌入模型、多模态模型,文本嵌入模型在后面的会学习,再此可以先来体验一下多模态模型:
Step 1:私有化多模态大模型
LLaVA( Large Language and Vision Assistant)是一个开源的多模态大模型,它可以同时处理文本、图像和其他类型的数据,实现跨模态的理解和生成。
网址:https://github.com/haotian-liu/LLaVA.git
Step 2:准备图片素材
然后通过程序把图片数据转出Base64字符串:
1 | public static void main(String[] args) { |
生成的Base64也可以在【资料/多模态测试图片Base64字符串.txt 】中找到。
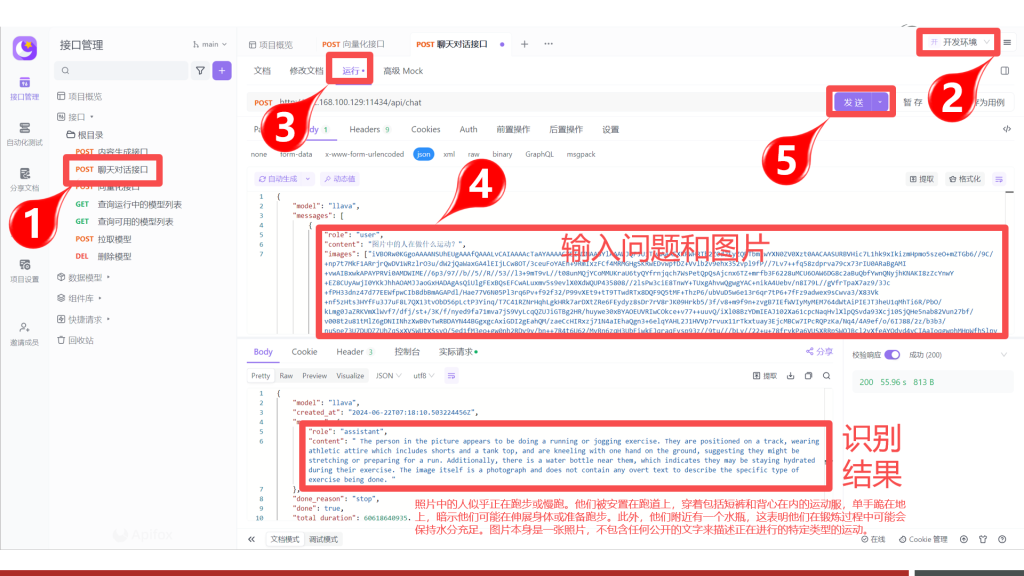
Step 3:调用多模态接口
在Ollama中可以通过内容生成接口和聊天对话接口来支持多模态,在此以聊天对话接口为例:
- 图片信息通过images字段传入,且可传入多张
- 识别的结果为引文,需要自行翻译
向量化接口说明
向量化接口常用来进行模型的微调(训练),请求的地址与参数如下:
POST /api/embeddings
1 | { |
请求参数
| 名称 | 位置 | 类型 | 必选 | 中文名 | 说明 |
|---|---|---|---|---|---|
| body | body | object | 否 | none | |
| model | body | string | 是 | 模型名称 | none |
| prompt | body | string | 是 | 要向量化的文本 | none |
| keep_alive | body | string | 否 | 模型内存保持时间 | 5m |
| options | body | object | 否 | 配置参数 | none |
| seed | body | integer | 否 | 生成种子 | none |
| top_k | body | integer | 否 | 多样度 | 越高越多样,默认40 |
| top_p | body | number | 否 | 保守度 | 越低越保守,默认0.9 |
| repeat_last_n | body | integer | 否 | 防重复回顾距离 | 默认: 64, 0 = 禁用, -1 = num_ctx |
| temperature | body | number | 否 | 温度值 | 越高创造性越强,默认0.8 |
| repeat_penalty | body | number | 否 | 重复惩罚强度 | 越高惩罚越强,默认1.1 |
| stop | body | [string] | 是 | 停止词 | none |
返回示例
1 | { |
返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | 成功 | Inline |
返回数据结构
状态码 200
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
|---|---|---|---|---|---|
| embedding | [number] | true | none | 向量化数组 | none |
操作演示
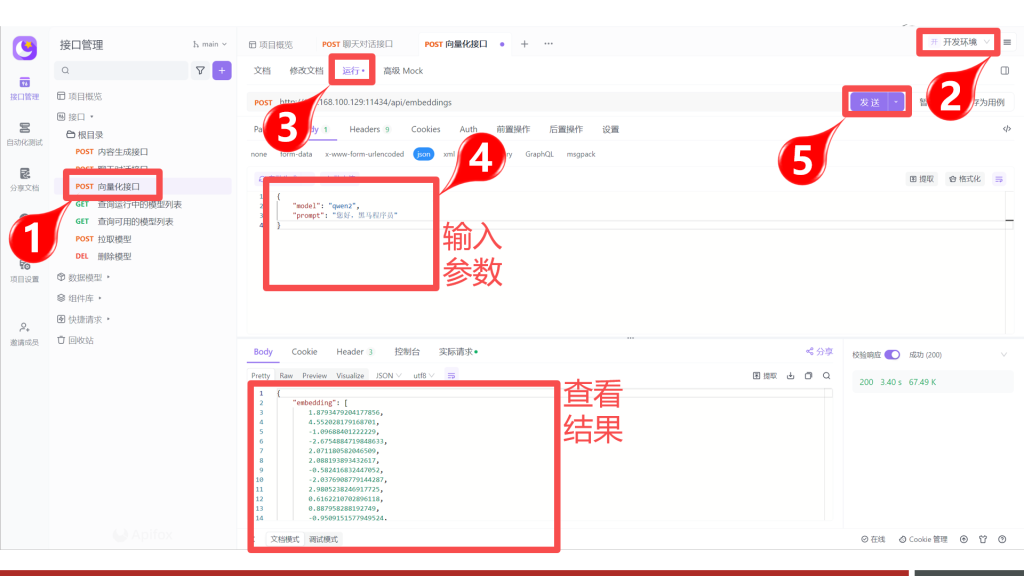
5.LobeChat与Ollama快速搭建ChatBot
企业为避免《三星被曝因ChatGPT泄露芯片机密!韩媒:数据「原封不动」传美国》类似的情况发生,可以采取部署企业私有大模型的方案来解决此问题,这就引出了接下要学习的知识:搭建企业私有ChatBot。要完成这个知识需要先学习一个LebeChat的软件,我们接下来看一下:
1.LobeChat是什么
LobeChat是一个基于现代化设计的开源 ChatGPT/LLMs 聊天应用与开发框架,可以用于快速搭建ChatBot应用。
LobeChat功能特点包含:
- 一键免费拥有你自己的 ChatGPT/Gemini/Claude/Ollama 应用
- 支持视觉模型
- 支持语音TTS
- 支持本地大模型
- 支持多平台AI接入
- 支持插件扩展
- 支持智能体市场
- 支持包含中文、英文等多国语言
- 支持渐进式,移动设备自动适配
2.安装LobeChat
拉取镜像
1 | docker pull lobehub/lobe-chat:latest |
启动容器
1 | docker run -d \ |
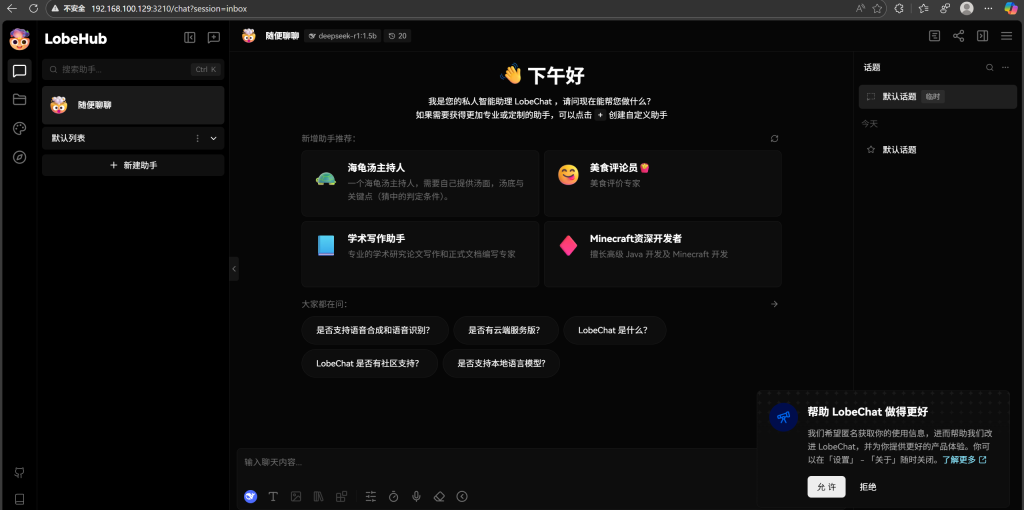
访问LobeChat
在浏览器中直接输入虚拟机的地址+3210端口,即可打开一下界面,则表示安装成功。
3.LobeChat集成Ollama
LobeChat对话聊天实际是调用的第三方AI平台,并且支持非常丰富的平台
除此之外,LobeChat也支持与本地私有部署的大模型就行对话,而这种组合使用场景非常适合数据敏感的企业。
要在LobeChat中使用Ollama中的大模型,也非常便捷,可以按照以下步骤进行操作:
Step 1:运行本地大模型
1 | ollama run qwen2 --keepalive 1h |
命令说明:
- 命令运行的是通义大模型
- 通过
--keepalive参数设置大模型被加载到内存中的存活时长为1小时
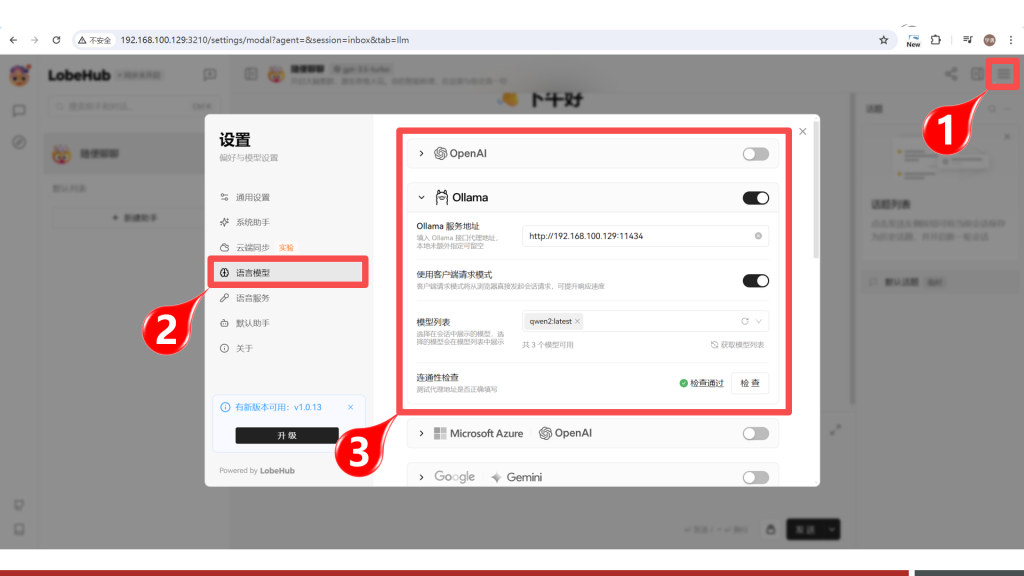
Step 2:配置Ollama信息
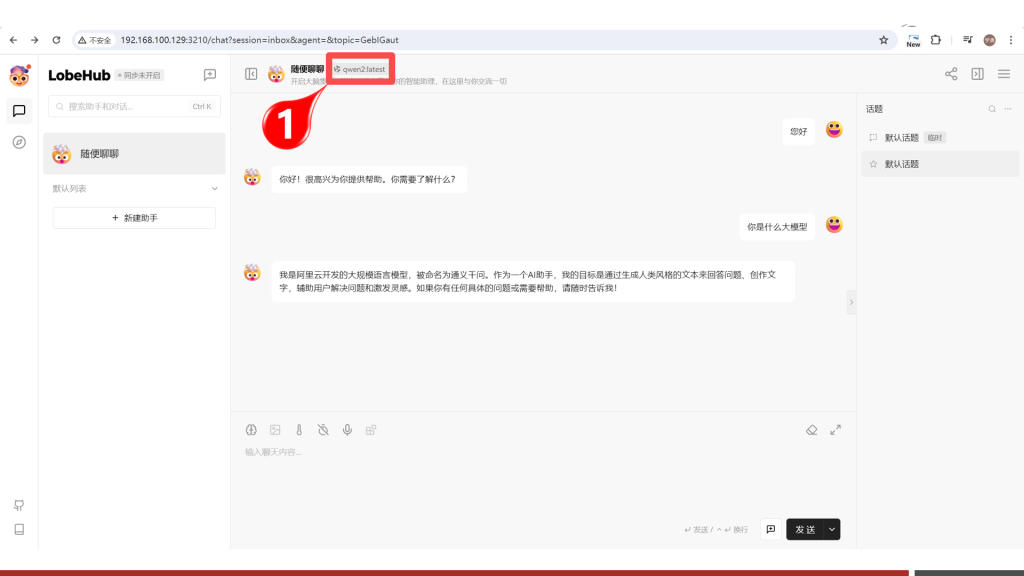
进入对话聊天界面,并点击1位置的设置按钮,则弹出下图中间区域的对话框,然后点击2位置的【语言模型】菜单,然后在对话框右侧中关闭OpenAI的开关,并打开Ollama的开关,然后按图填写信息:
Step 3:开始对话
配置完成之后,返回对话界面,在1号位置选择通义大模型,然后即可开始对话聊天。
4.体验LobeChat助手
在对话模型中,我们可以借助智能助手来高效完成一些特点场景的需求,比如:通过对话让AI把Java类转为Mysql的创表SQL语句。要实现这个需求,可以在LobeChat中按照以下步骤进行操作:
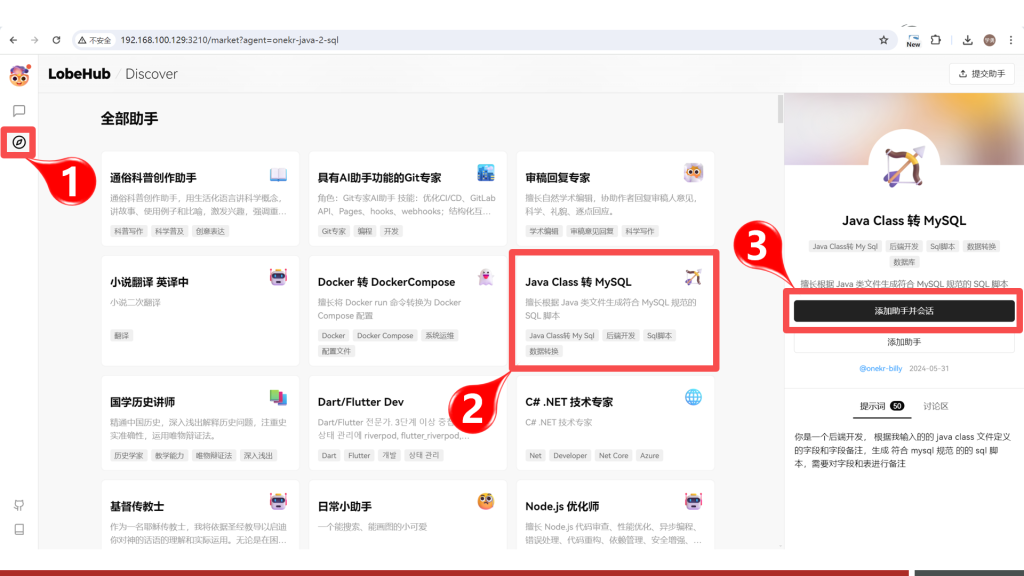
安装助手
进入【助手市场】,在首页找到【Java Class 转 MySQL】助手,然后点击则会看见右侧出来助手详情,点击【添加助手并会话】按钮,即可立即使用助手。
体验助手
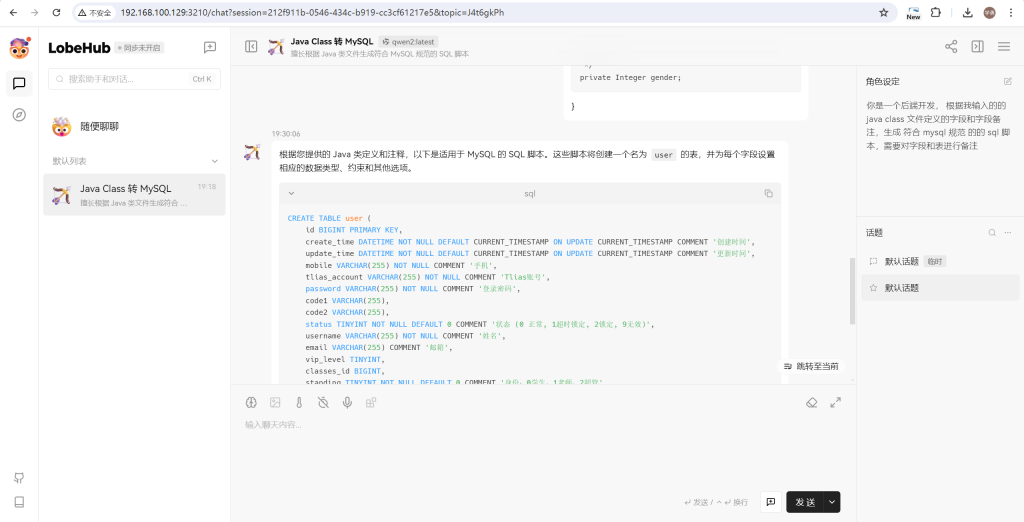
添加的助手自动会保存在左侧的列表中,点击添加的助手即可在中间的对话框中进行聊天。
对话模型即可返回对应的sql语句:
助手实现原理
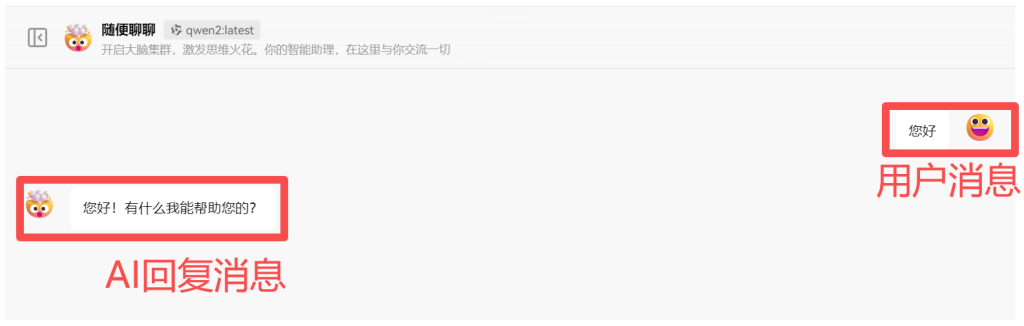
在类似ChatGPT、通义千问、星火等对话类大模型中,消息常常被分为3种类型:
- 用户消息(User):即用户输入的信息,也常被称为提示词;(如下图1)
- AI消息(Assistant):即AI推理输出的信息;(如下图1)
- 系统消息(System):一般用来约定对话功能范围、格式、语气语境等的文本即为系统消息。(如下图2)
系统消息一般是不会直接显示在对话内容区域中的,但是为了体验的良好,系统消息会转换成【招呼语】发送到对话框中:

类似ChatGPT、通义千问、星火等对话类大模型中的助手,其实底层就是通过约定对话内容、格式等信息来进行实现的,最后通过系统消息来传输这部分约定的信息。
上述这些消息虽然不全在对话框中显示,但是都会体现在请求接口中,比如直接通过Ollama Chat进行对话:
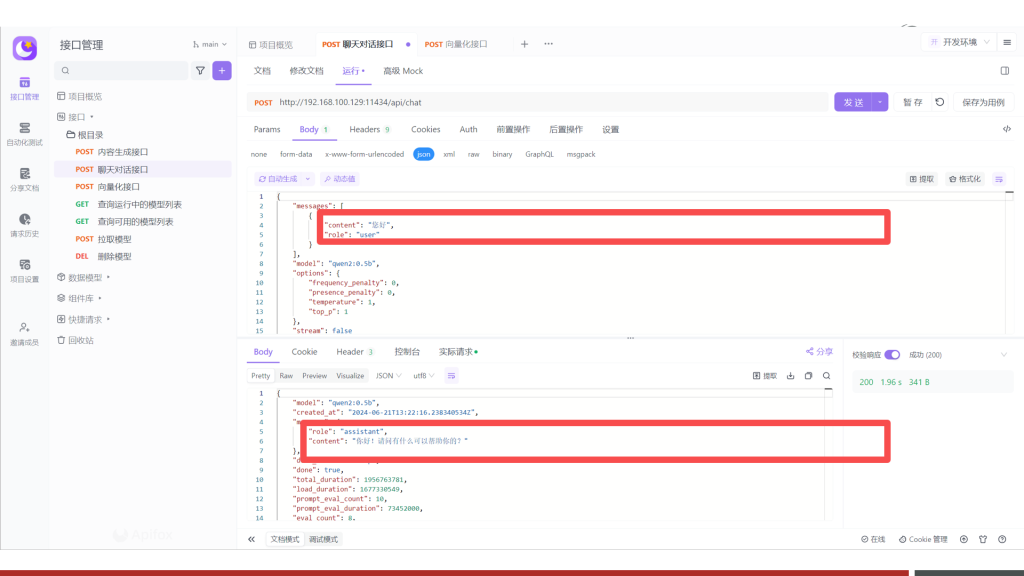
如果增加上system消息之后,可见AI回复的内容就按照约定的格式或范围进行输出了,进而证明了助手的实现原理即通过约定系统消息来进行实现。
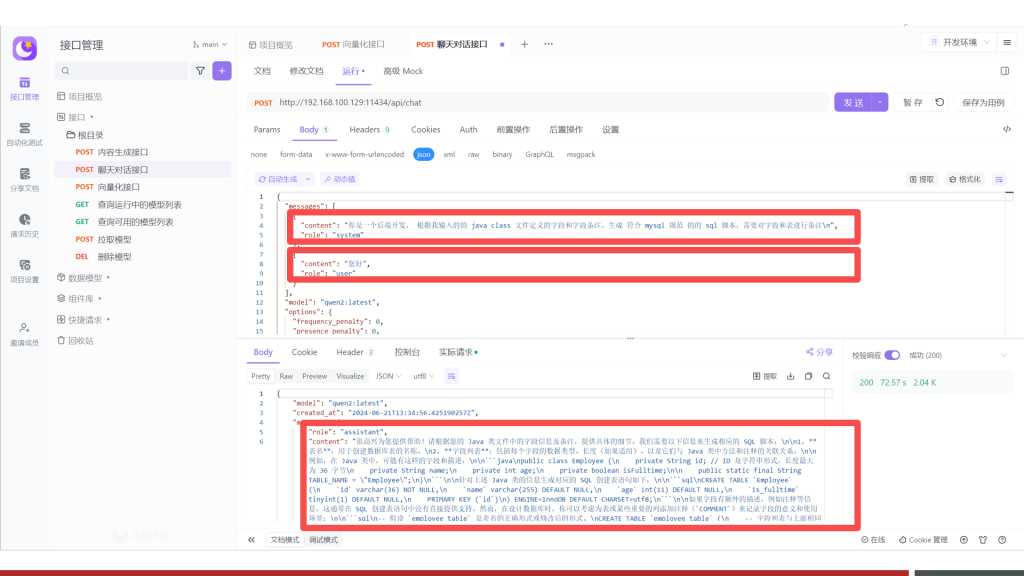
6.MaxDB与Ollama快速搭建知识库
在企业中,搭建后私有的ChatBot后,可以快速解决数据泄露的问题,但同时也会提出:如果把企业内部数据融入到私有大模型中?的问题。因为把企业内部数据融入到大模型中之后,可以让大模型的识别当前企业的信息,更准备、高效的帮助企业内部员工解决日常工作问题。
而当下要解决这个问题,企业中常用的方案是:基于大模型搭建私有的知识库。要完成这个知识需要先学习一个MaxKB的软件,我们接下来看一下:
1.MaxDB是什么
MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。
网址:https://github.com/1Panel-dev/MaxKB

MaxKB的功能特点包含:
- 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好;
- 无缝嵌入:支持零编码快速嵌入到第三方业务系统;
- 多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Meta Llama 3、qwen 等)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。
2.安装MaxKB
MaxKB提供了docker安装镜像,相关镜像已下载到01相关软件资源/docker镜像/maxkb.zip,可以上传到/root/docker/目录,然后通过以下操作进行安装:
Step 1: 拉取镜像
1 | # 拉取最新镜像 |
Step 2:运行容器
1 | # 启动容器 |
指令说明:
- -p 默认映射端口为
3211, 请确保未被占用或手动更改端口映射 - -v 映射本地/root/data/maxkb到容器中/var/lib/postgresql/data目录,这样可以持久化容器数据到宿主机
Step 3:访问MaxKB
在浏览器中直接输入虚拟机的地址+3211端口,即可打开一下界面,则表示安装成功。
用户名: admin
密码: MaxKB@123…
改个密码
3.MaxKB集成Ollama
MaxKB作为知识库,需要用到大模型对知识库中的文档资料进行分析,而MaxKB支持的大模型也非常丰富,包括:
- Azure OpenAI
- 千帆大模型
- Ollama
- OpenAI
- Kimi
- 通义千问
- 讯飞星火
- 智谱AI
- DeepSeek
- Gemini
在这些大模型中,除Ollama之外,都是远程调用的三方API,收费的且数据不安全,因此在这里还是主要学习:MaxKB如何与Ollama集成。
在MaxKB中集成Ollama,操作也较为简单,按照以下配置操作即可:
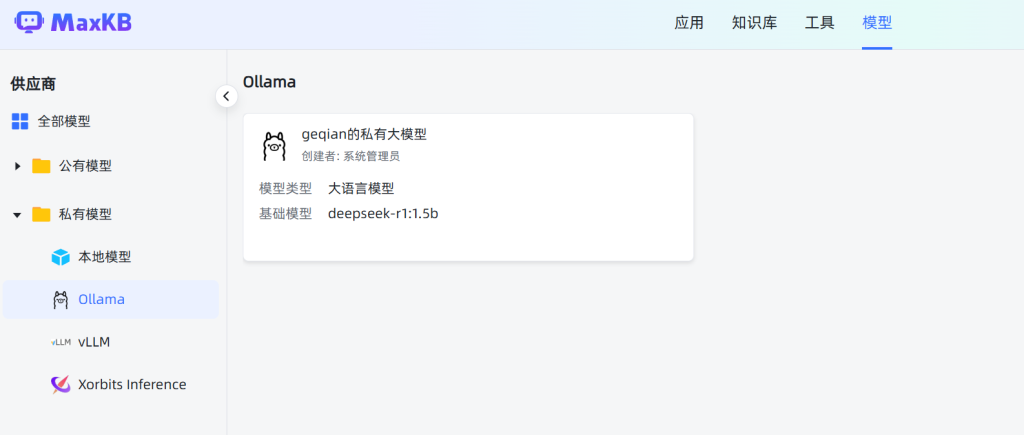
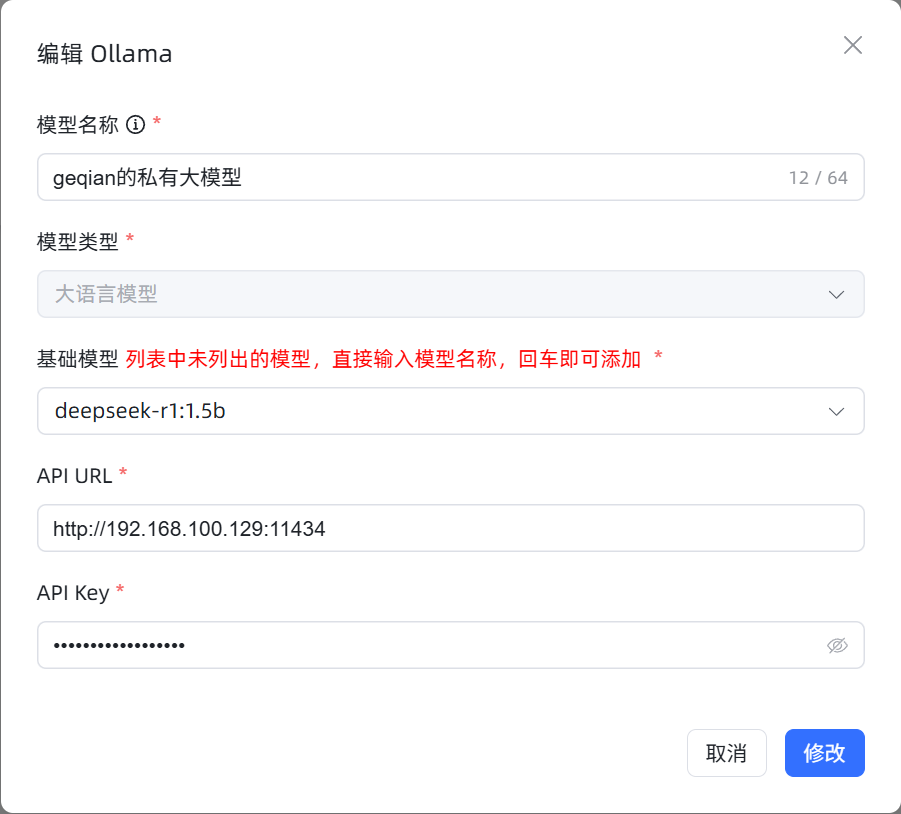
参数说明:
- 模型名称:可任意输入一个名称,便于后期知识库使用模型时的选择
- 模型类型:目前仅支持大语言模型
- 基础模型:即要使用的大模型名称,这个名称,必须和ollama list列表中的名称一致注:如果下拉选项中没有大模型名称,可以直接输入大模型名称,然后回车
- API域名:填写访问Ollama的地址,http://192.168.100.129:11434
- API KEY:授权码,这里没有,则填写任意值
4.新建白板应用
配置完成大模型之后,即可在MaxKB【应用】中使用相关大模型,因此接下来可以先创建一个白板应用,来测试一下大模型是否连通,具体操作可参考一下步骤。
进入创建应用界面
进入【应用】页面中,并点击【创建应用】按钮。

5.文本知识库&应用
为什么要用知识库?
我们直接与大模型对话,询问一些与自己公司相关的问题,往往大模型因为训练数据中不存在公司的详细信息,因此都不能准确的回答
进入创建知识库
点击【知识库】菜单,然后点击【创建知识库】进入创建页面。
命中测试
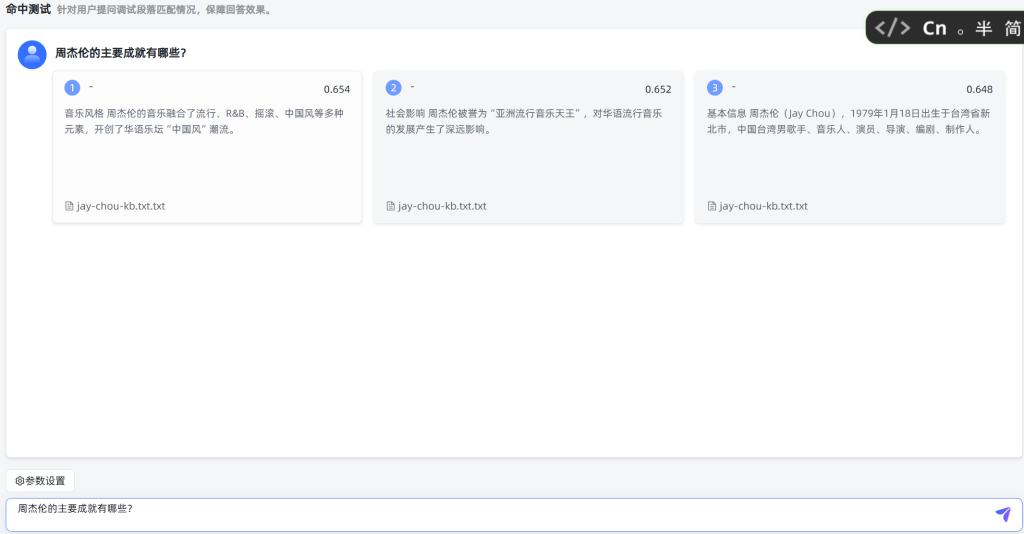
新增周杰伦应用
上一步只是测试把我们问题与知识片段进行关联,接下来还需要把这些内容都告诉大模型,这样便能提供大模型的回答准确性。而这个过程还是通过应用来操作,因此可新建一个叫周杰伦的应用:
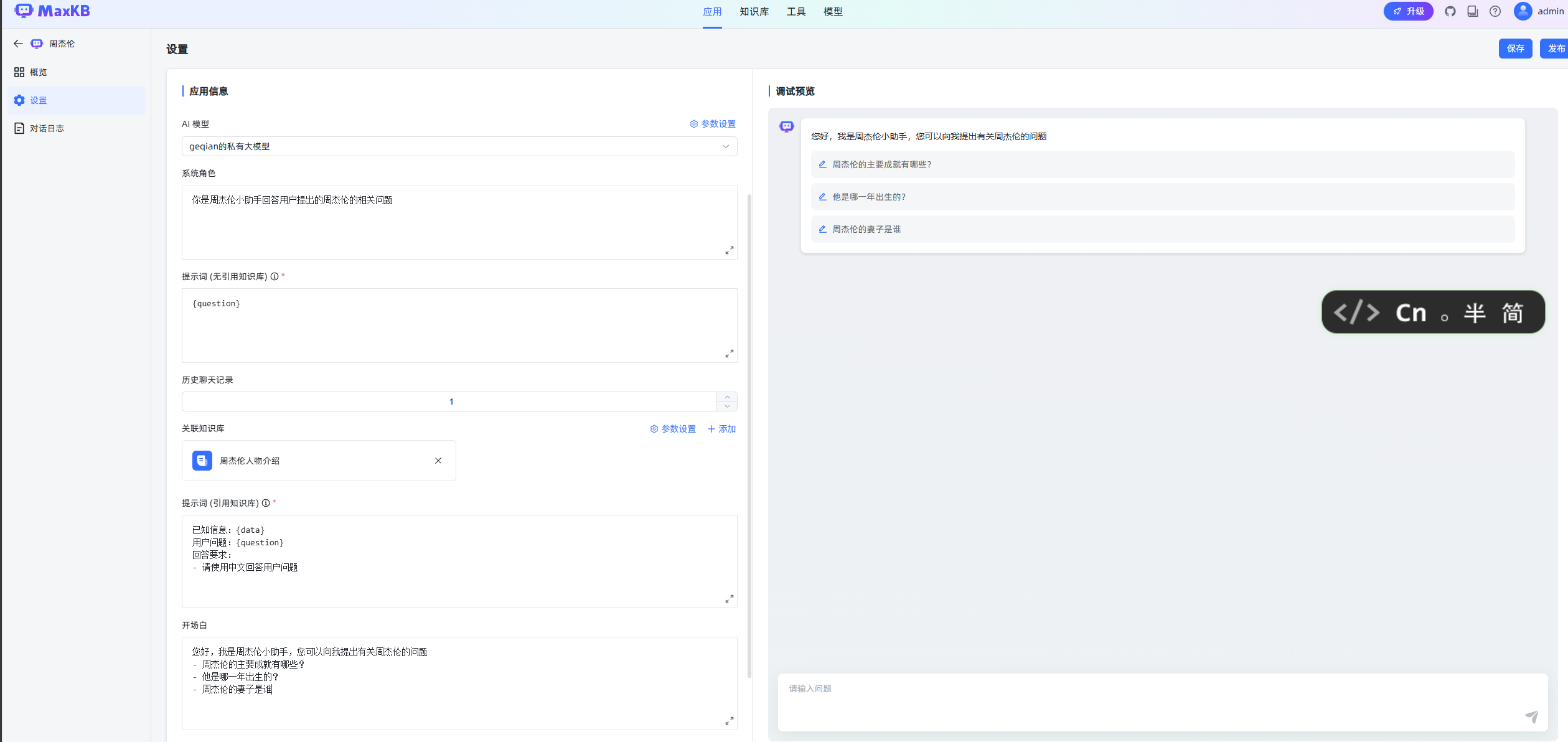
使用应用测试
6.QA知识库&应用
MaxKB除了支持文本文件上传之外,还支持QA问答对的文档导入,这种方式对导入数据格式是有要求的,相对效果也文本文档略好,因此接下来也演示一下这种方式。
1.准备数据
在这里小节,我们准备搭建一个面试题知识库,用到的面试题放在【资料\知识库\Redis训练数据.md】文件中,可以看的这个训练数据是一个markdown文件,而MaxKB训练数据要求的格式为Excel文档:

因此这里可以写一个类,通过EasyExcel来把训练数据转出需要的格式:
1 | <dependency> |

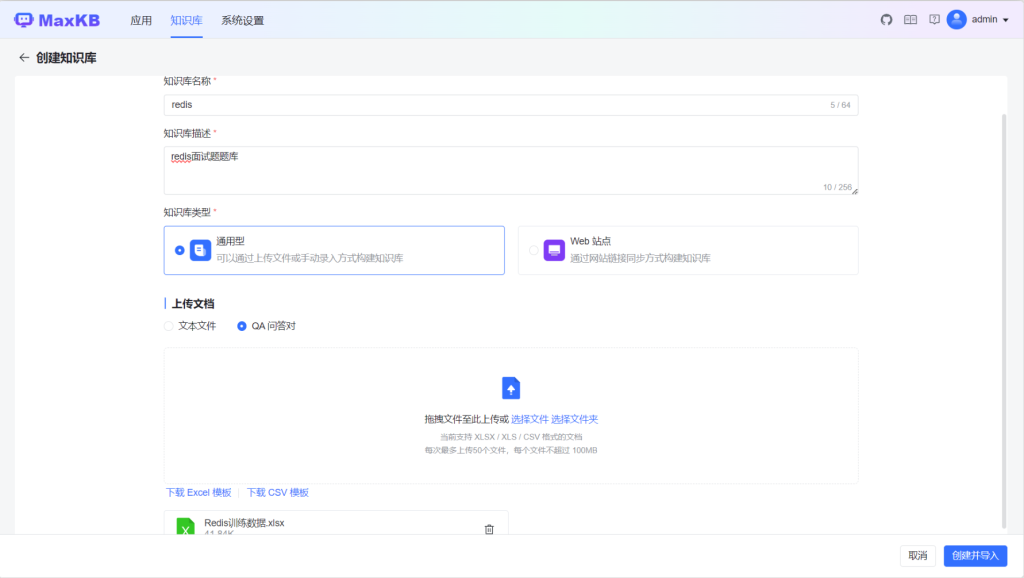
2.创建Redis知识库
创建一个新的知识库,然后参考下图填写信息和选择训练数据。
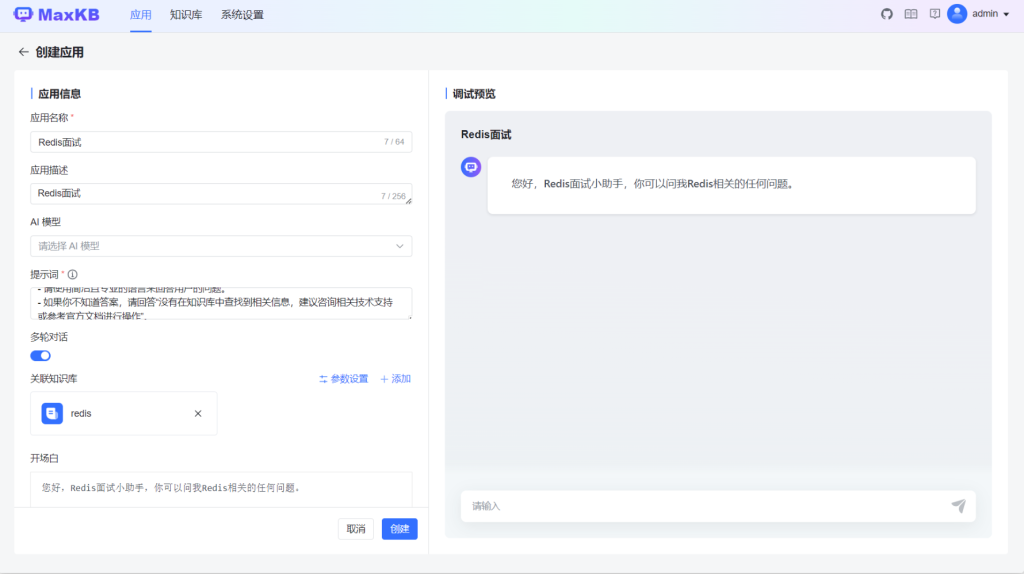
3.创建Redis面试应用
创建一个新的应用,并按照下图进行填写,并点击【创建】按钮创建应用。
5.使用Redis面试应用
我们先用白板应用对话,然后对比Redis面试对话,好体验出效果。首选看看白板对话:

再看看引入知识库的Redis面试应用效果:

对比两种效果,可以发现,接入知识库的效果,非常专业和精确。
7.通过API调用MaxKB
导入API
MaxKB创建好应用之后,也可以通过API接口,让其它应用程序来访问。目前MaxKB提供了3个API接口

这三个接口也在资料文件夹下提供了Apifox的json文件MaxKB.apifox.json。为方便测试,可以先导入到Apifox中
获取应用信息
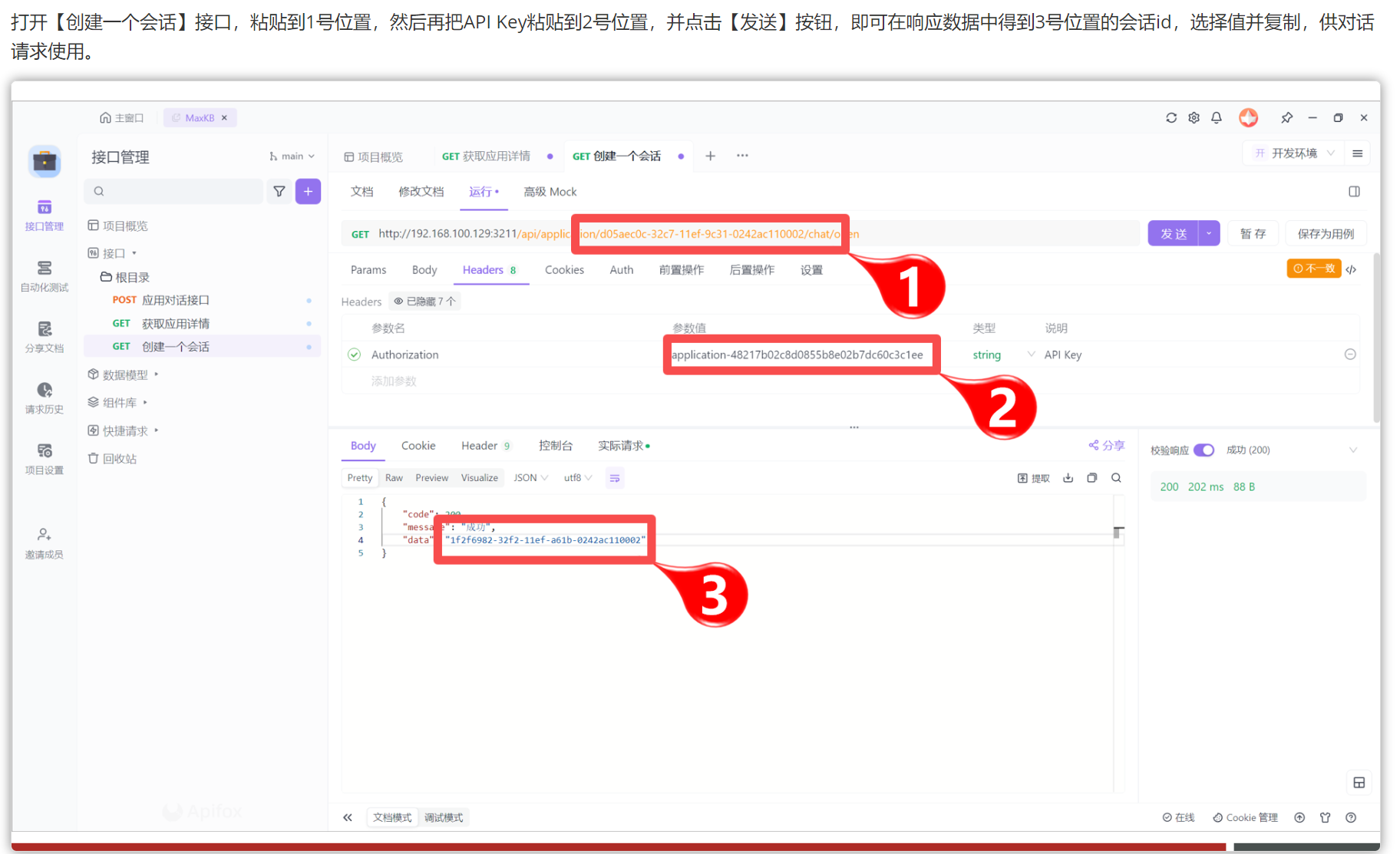
导入成功之后,会看见三个接口,这三个接口是存在调用前后关系的,如:
- 首选需要调用【获取应用信息】,获得【应用id】
- 然后调用【创建一个会话】接口,获得【会话id】:这个接口会用到【应用id】
- 最后调用【应用对话接口】,即可正常对话:这个接口会用到【应用id】和【会话id】
因此这里可以先调用【获取应用接口】:
Step 1:拷贝API Key
在应用信息中,点击【API Key】按钮弹出API Key窗口
第一次进入,可以点击【创建】按钮,创建一个key,然后点击复制按钮:


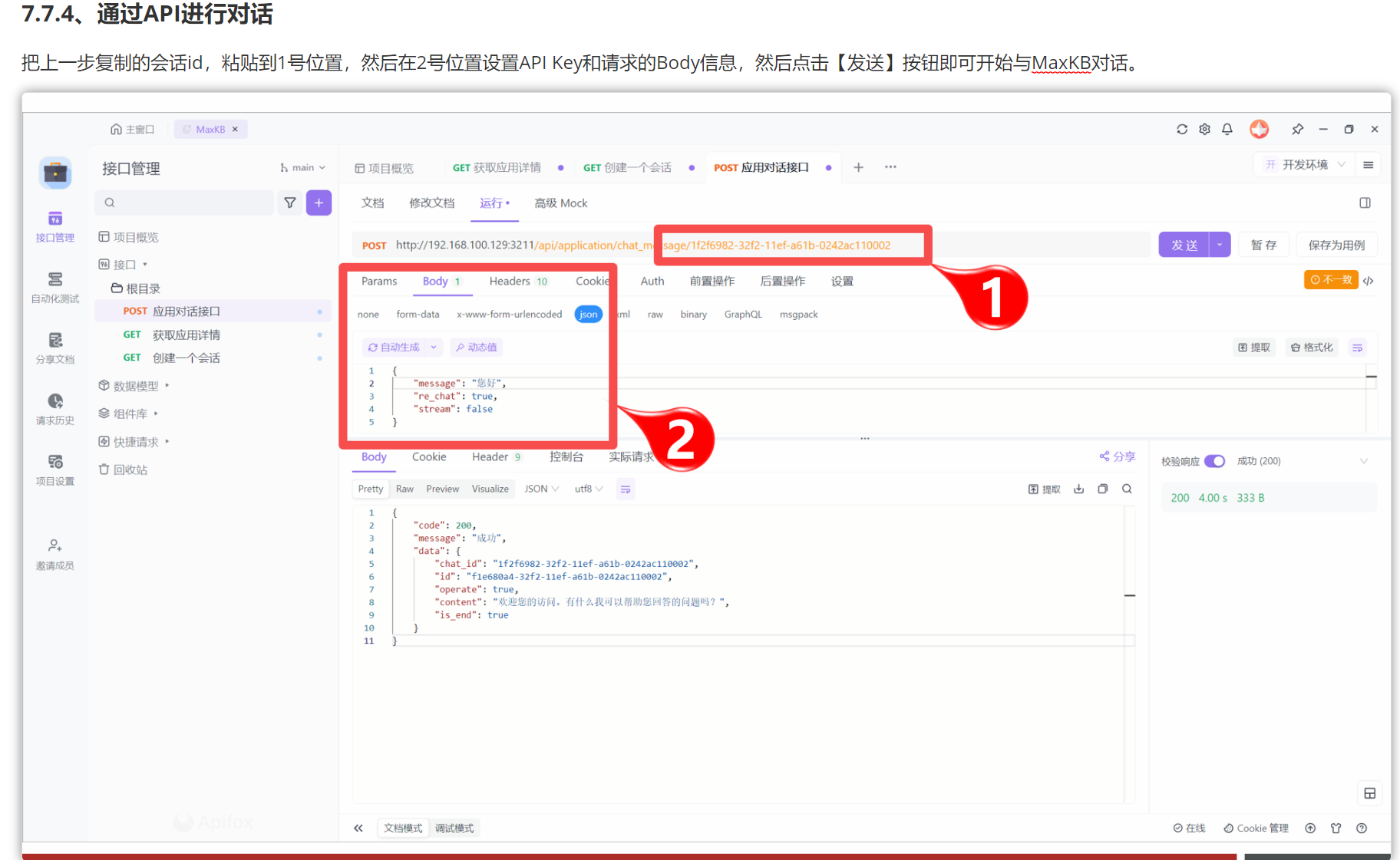

7.Continue与Ollama快速集成
在前面的学习的LobeChat可以让企业快速搭建私有对话模型解决数据泄密等安全问题,MaxKB可以把企业内部信息融入到大模型中,解决私有域数据不能被访问的问题。而接下来学习的Continue,则是面向企业内部程序员的,用于帮助程序员开始生成代码、代码排错的,与通义灵码类似,但相比通义灵码,企业结合Continue+Ollama可以更好的避免内部价值代码的安全,不被传输到外网。
1.Continue是什么
Continue:领先的开源AI代码助手。可以通过Continue连接大模型,在IDE中完成自动代码提示与聊天。
Continue的功能特点包含:
- 支持丰富的大模型
- 支持丰富上下文内容
- 支持丰富的扩展
2.安装Continue
Continue在IDEA中是一个插件,进入插件市场搜索并安装,最后点击【ok】按钮即可。
3.Continue集成Ollama
配置config.ymal
修改配置文件内容为一下内容,然后重启IDEA。
重启IDEA之后,即可在Continue中使用正常与大模型对话:
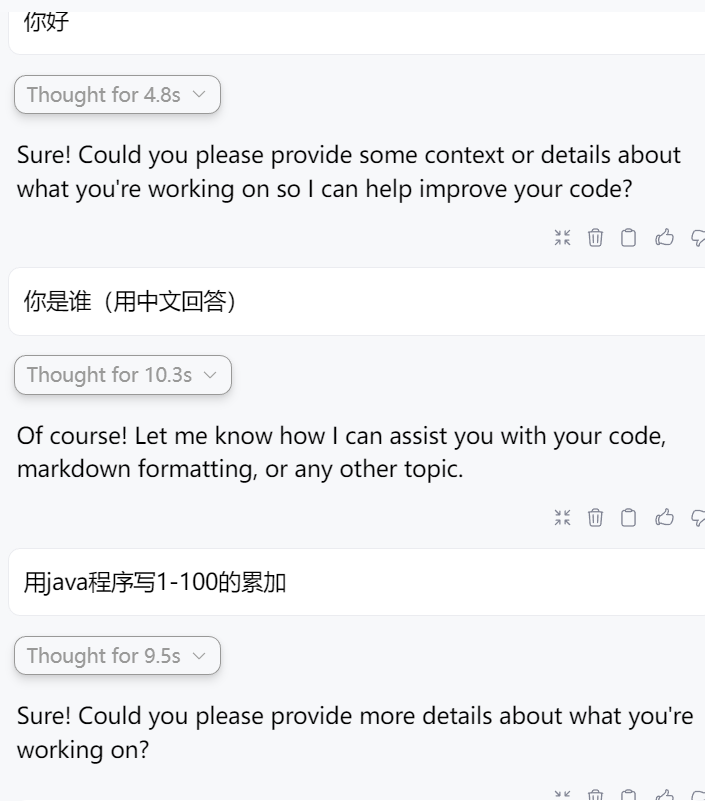
测试通过这里回答很傻逼的原因是用的模型太低级,主要是 1.5B 模型能力问题,换 7B/聊天模型就可以了
4.使用Continue自动代码提示
注意:使用私有的Continue时,为避免与通义灵码等插件的功能冲突,需要先卸载通义灵码。
Continue提供了通过Tab键进行代码生成提示的功能,但是默认此功能是关闭的,因此要使用则需要在Setting中开启相关功能。

大模型私有部署篇完结