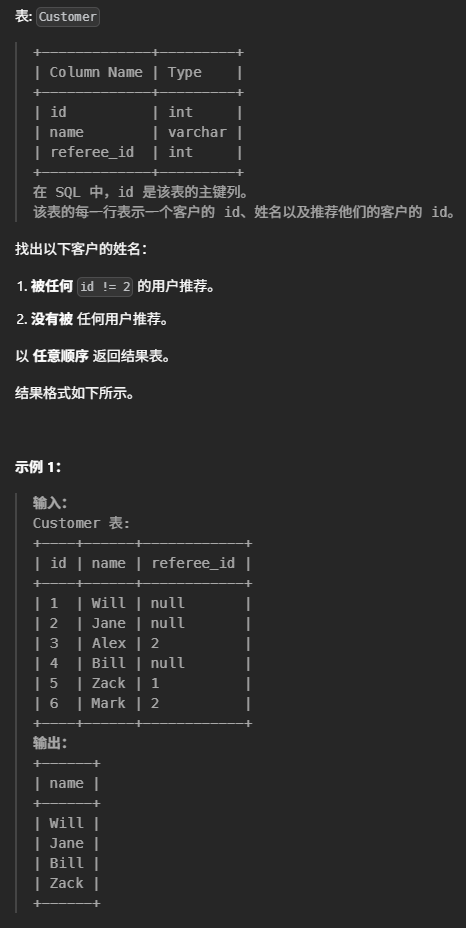
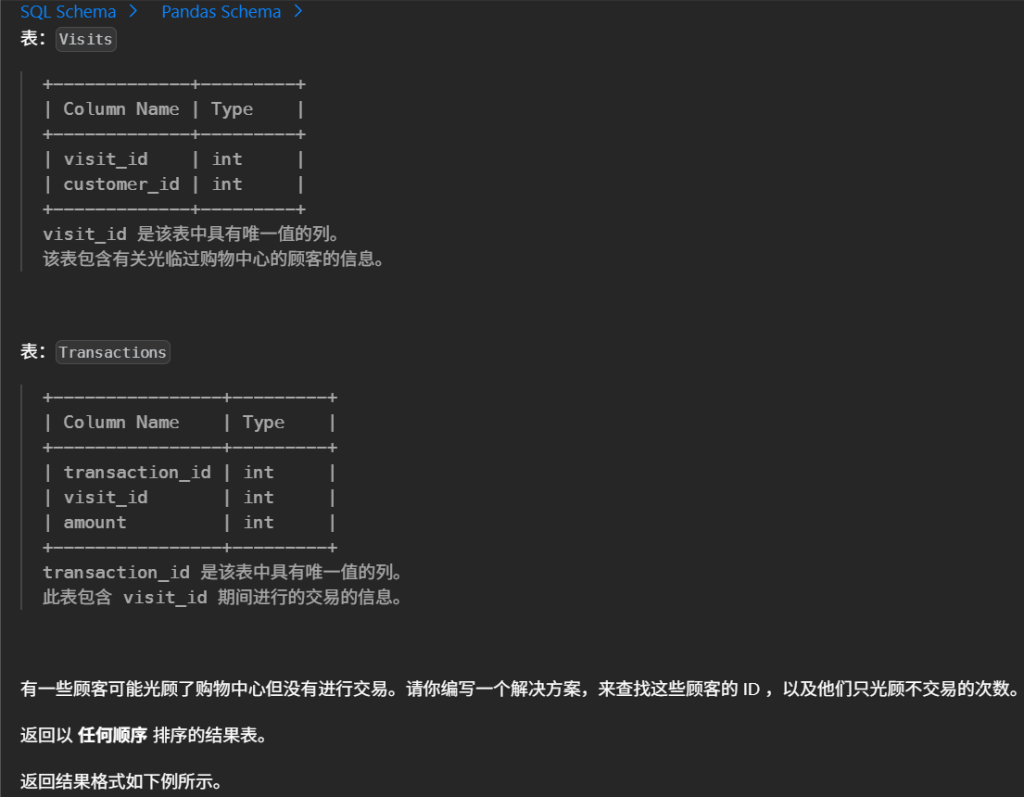
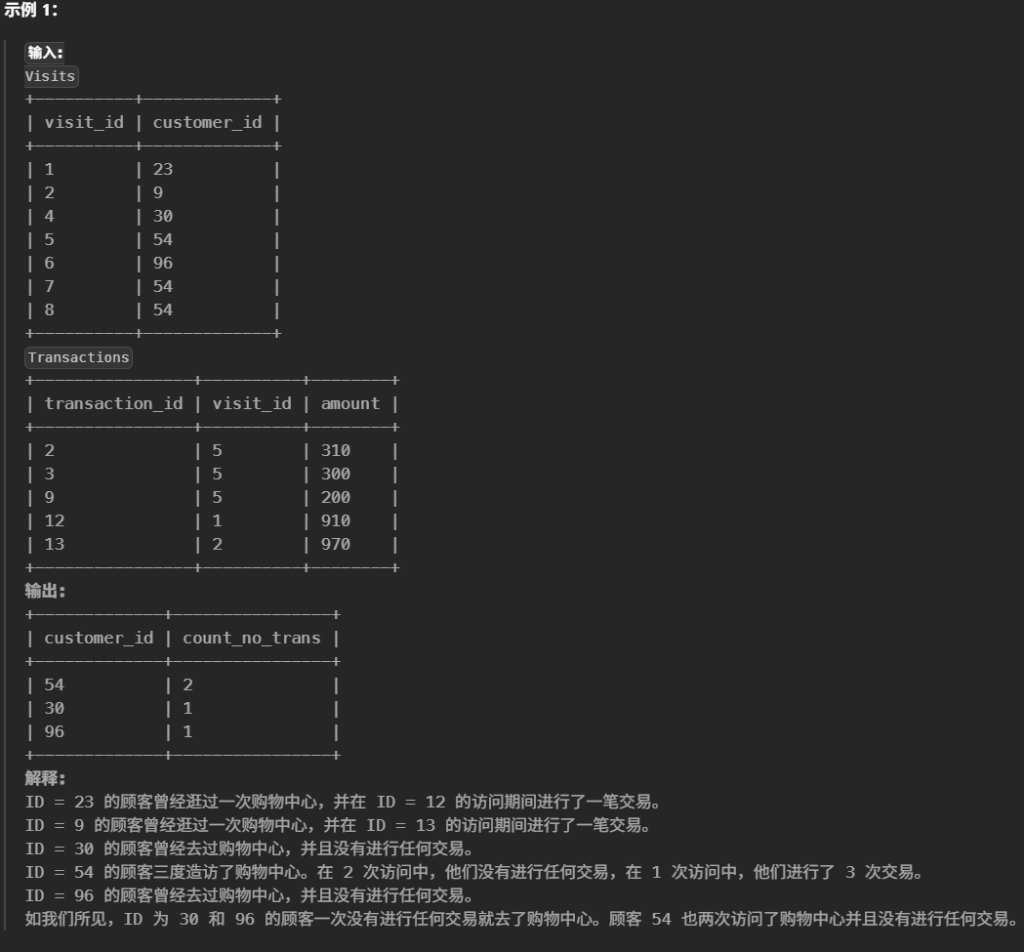
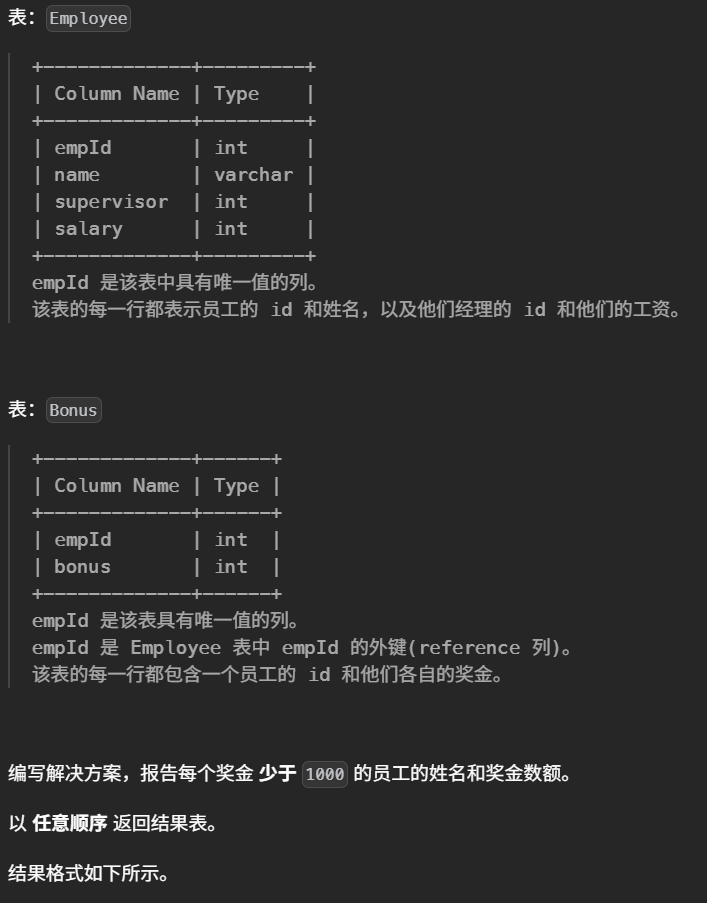
select v.customer_id , COUNT(*) AS count_no_trans from Visits v leftjoin Transactions t on v.visit_id = t.visit_id where t.transaction_id isnull groupby v.customer_id
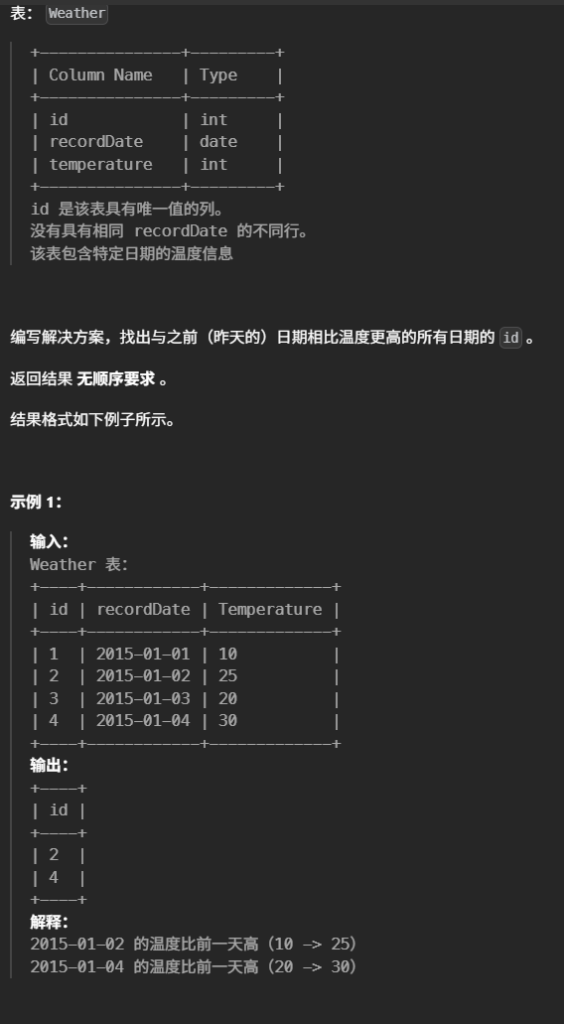
9.上升的温度(简单)
1 2 3 4
select cur.id from Weather cur join Weather pre on cur.recordDate = DATE_ADD(pre.recordDate, INTERVAL1DAY) where cur.temperature > pre.temperature
或者
1 2 3 4 5
SELECT cur.id FROM Weather cur JOIN Weather pre ON DATEDIFF(cur.recordDate, pre.recordDate) = 1 WHERE cur.temperature > pre.temperature;
DATEDIFF()是MySQL 中的一个日期时间函数,用于计算两个日期之间的天数差。
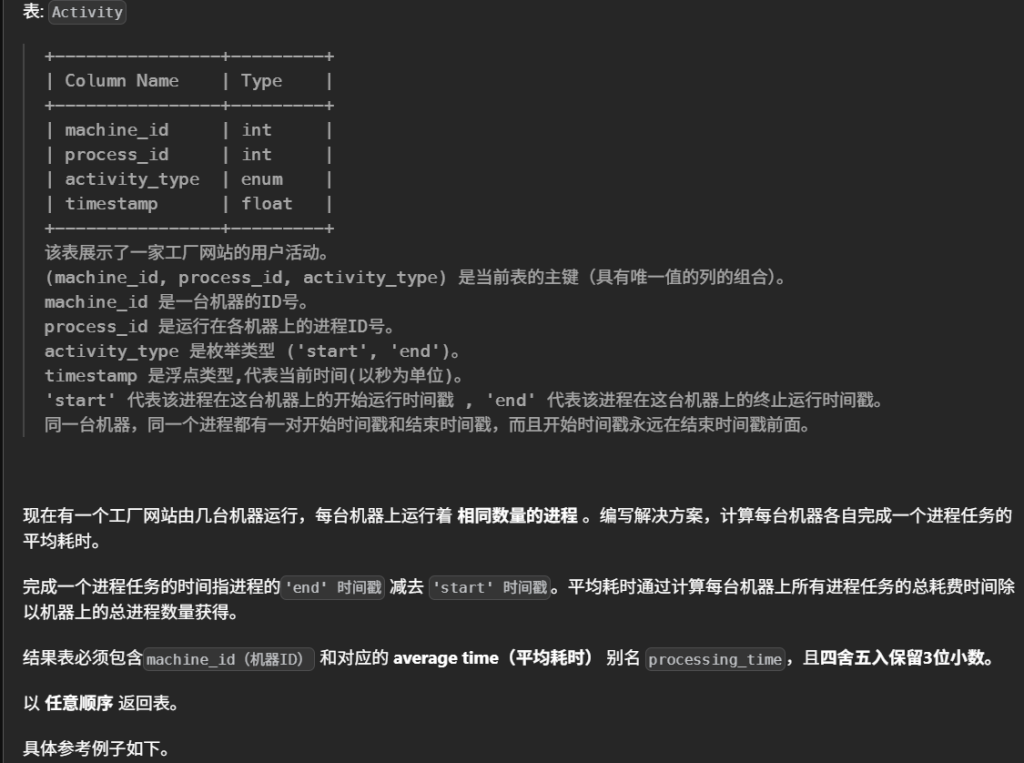
10.每台机器的进程平均运行时间(简单)
自连接
1 2 3 4 5 6 7 8 9 10 11
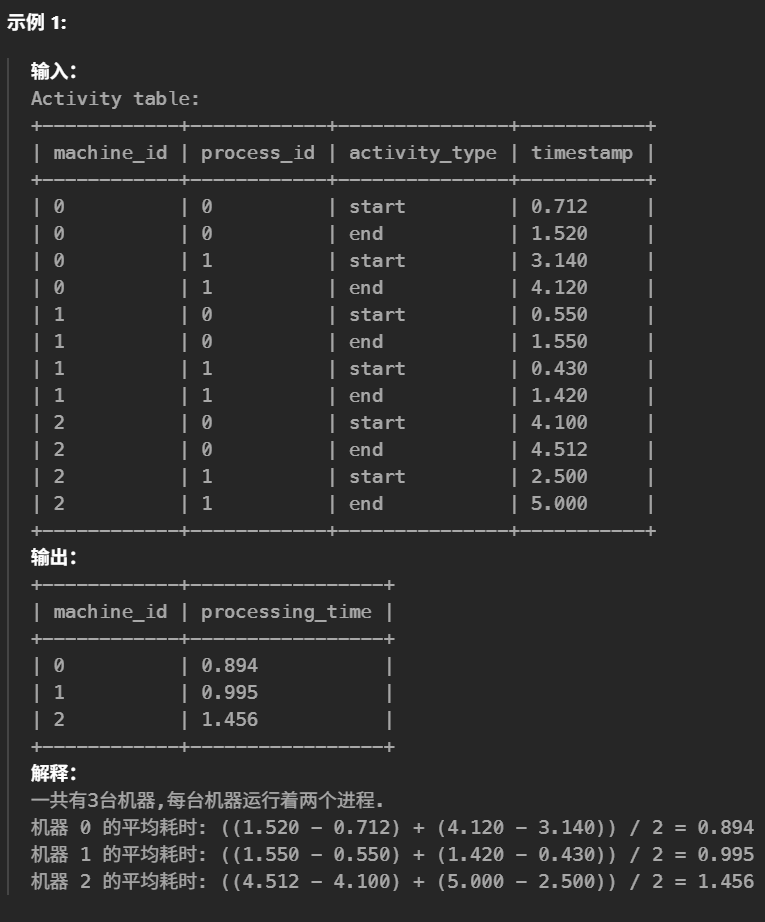
#计算每台机器各自完成一个进程任务的平均耗时。 #完成一个进程任务的时间指进程的'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。 #分组,start一组,end一组 select s.machine_id , round(Avg(e.timestamp - s.timestamp ),3)as processing_time from Activity s leftjoin Activity e on s.machine_id = e.machine_id and s.process_id = e.process_id and s.activity_type = 'start' ande.activity_type = 'end' groupby s.machine_id
11员工奖金(简单)
1 2 3 4 5
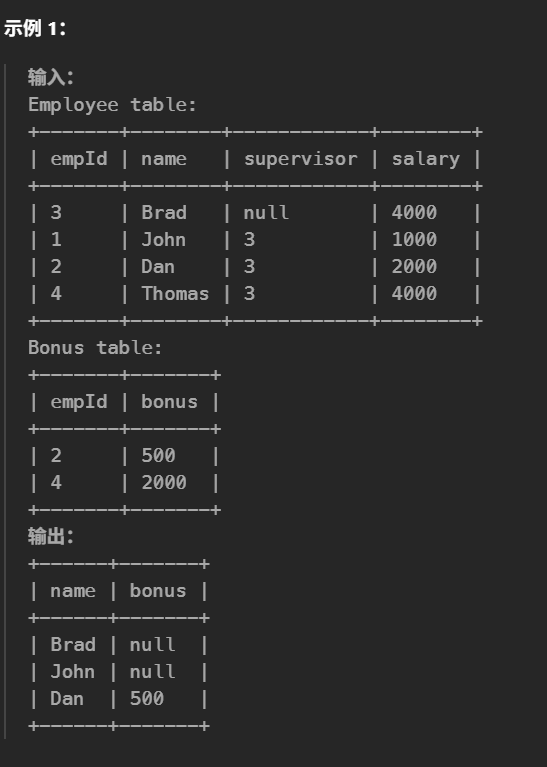
#编写解决方案,报告每个奖金 少于 1000 的员工的姓名和奖金数额。以 任意顺序 返回结果表。 selecte.name, b.bonus from Employee e leftjoin Bonus b one.empId = b.empId where bonus < 1000or bonus isnull
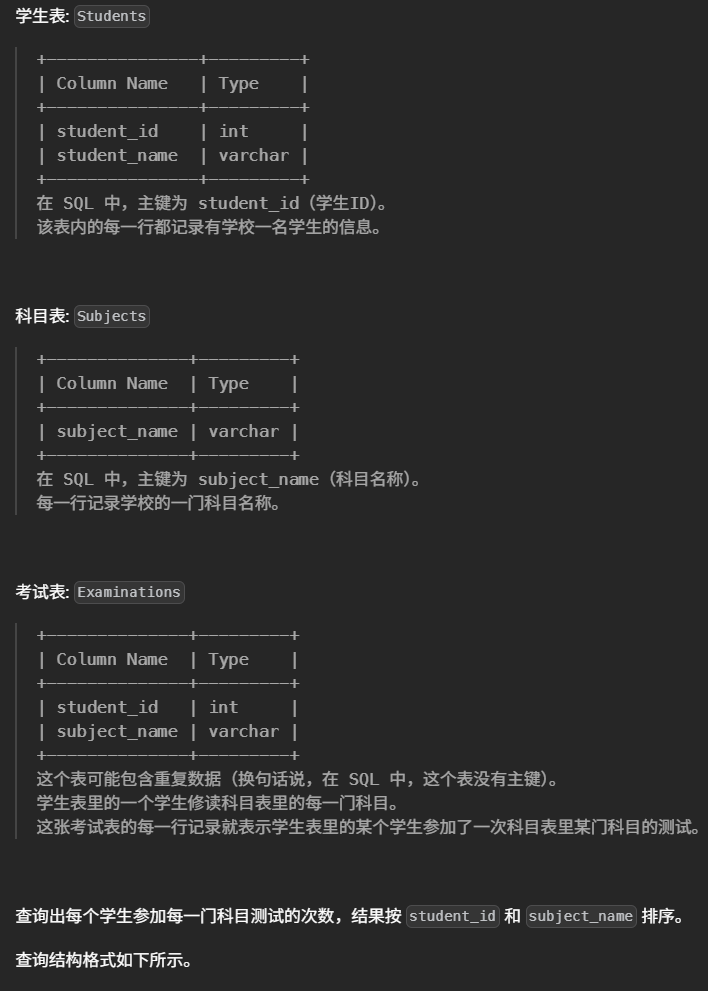
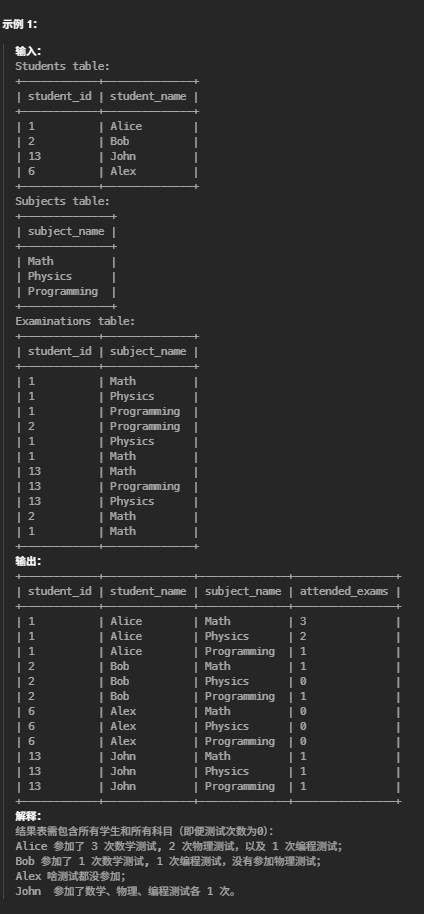
#查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。 select St.student_id, St.student_name,Su.subject_name,Count(e.subject_name) as attended_exams from Students St Cross join Subjects Su Left join Examinations e onSt.student_id = e.student_id and Su.subject_name = e.subject_name group bySt.student_id, St.student_name,Su.subject_name orderbySt.student_id,Su.subject_name;
CROSS JOIN 保证了每个学生和每个科目都会配对,即使没考过。
LEFT JOIN 保证了没有考试记录的组合也会出现。
COUNT(e.subject_name) 遇到没有匹配时(NULL)会自动统计为 0。
GROUP BY 必须包括 student_id, student_name, subject_name。
最后 ORDER BY 确保输出顺序。
13.有趣的电影(简单)
1 2 3 4 5
#编写解决方案,找出所有影片描述为 非 boring (不无聊) 的并且 id 为奇数 的影片。返回结果按 rating 降序排列。 select * from cinema c where description != 'boring' and mod(id,2) = 1 orderby rating desc
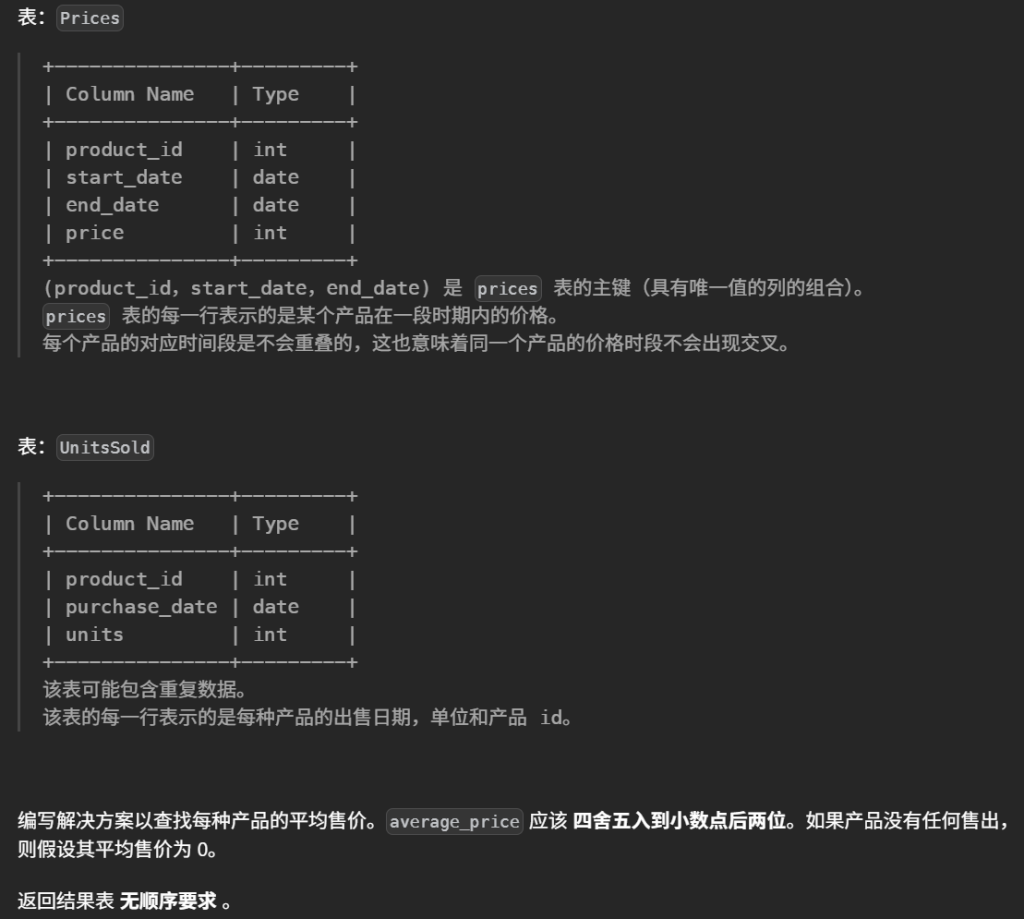
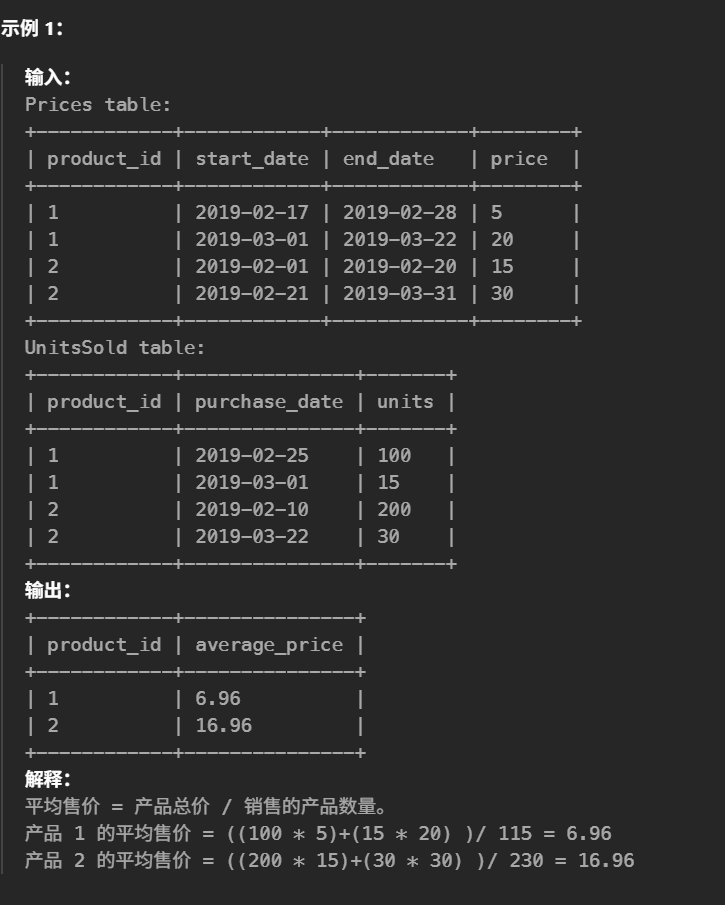
14.平均售价(简单)
1 2 3 4 5 6 7
#编写解决方案以查找每种产品的平均售价。average_price 应该 四舍五入到小数点后两位。如果产品没有任何售出,则假设其平均售价为 0。 select p.product_id, ROUND( COALESCE( SUM(u.units * p.price) / NULLIF(SUM(u.units), 0), 0 ), 2) as average_price #产品没有售出时,默认为0 from Prices p leftjoin UnitsSold u on p.product_id = u.product_id and u.purchase_date between p.start_date and p.end_date groupby p.product_id
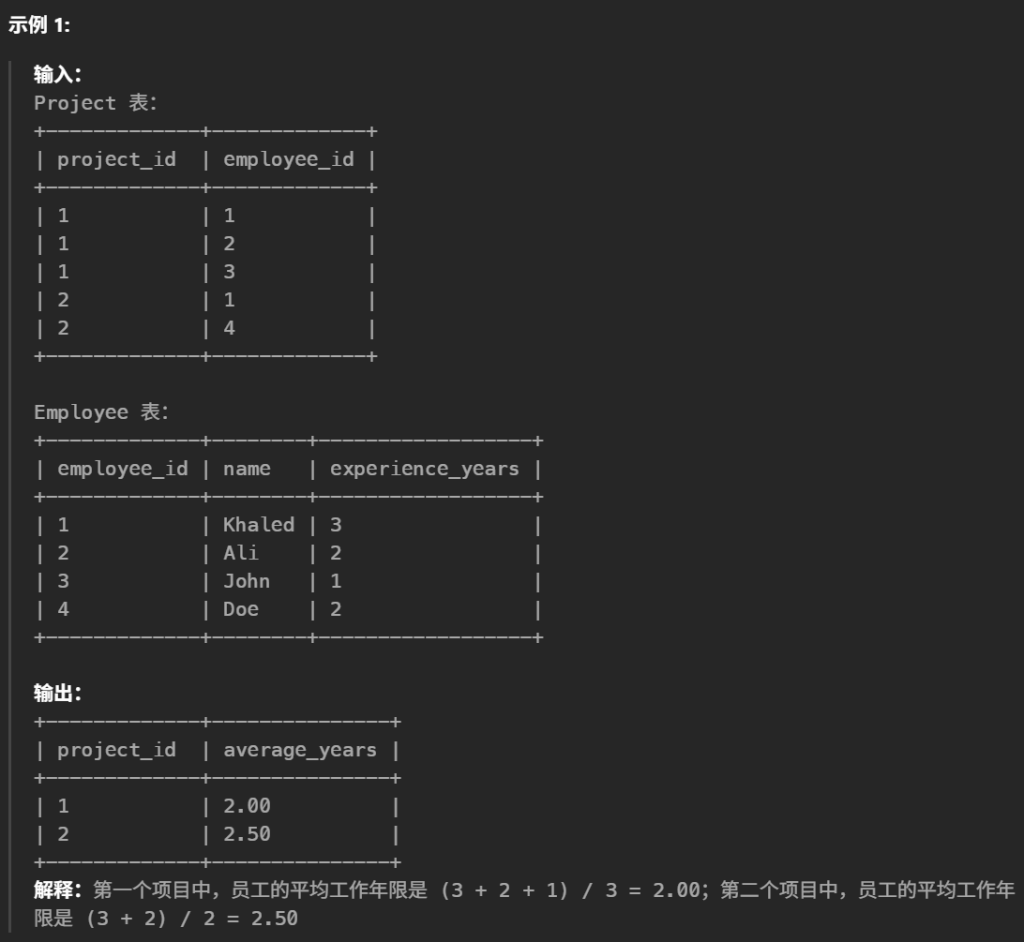
#查询每一个项目中员工的 平均 工作年限,精确到小数点后两位。以 任意 顺序返回结果表。 select p.project_id , Round(Avg(e.experience_years),2) as average_years from Project p leftjoin Employee e on p. employee_id = e. employee_id groupby project_id
#找出每次的 query_name 、 quality 和 poor_query_percentage。 #quality 和 poor_query_percentage 都应 四舍五入到小数点后两位 。 select query_name, round(Avg(rating / position),2) as quality, round(100 * Avg(rating < 3),2) as poor_query_percentage from Queries groupby query_name
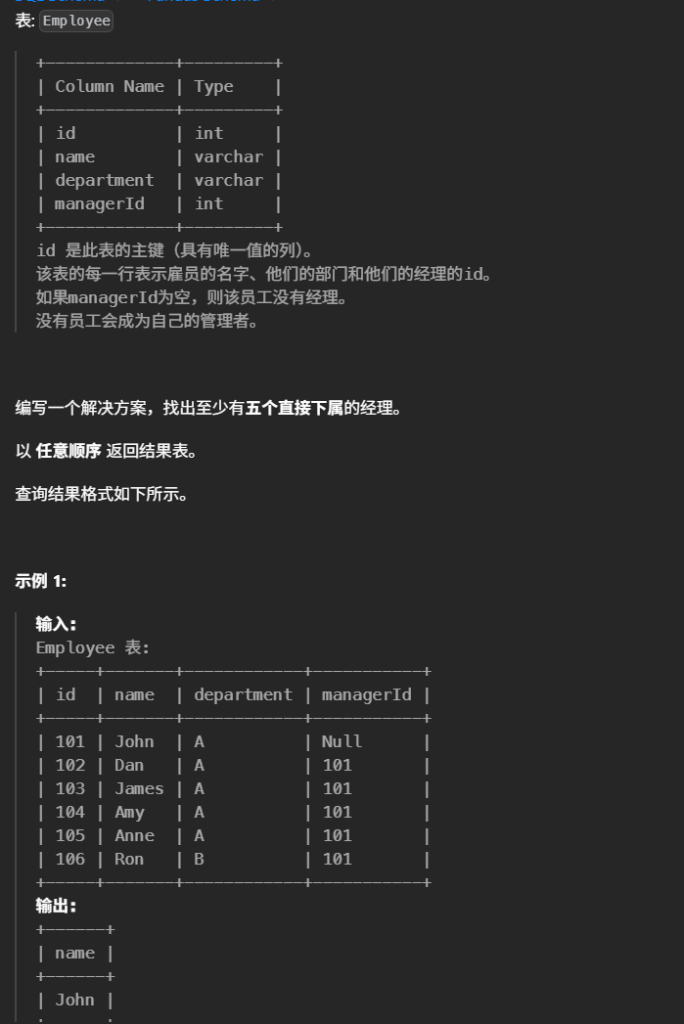
18至少有5名直接下属的经理(中等)
1 2 3 4 5 6 7 8 9 10 11
#找出至少有五个直接下属的经理。 selecte.name from Employee e join ( select managerId,count(*) as num from Employee where managerId isnotnull groupby managerId )c on c.managerId = e.id where c.num>=5
方法2
1 2 3 4 5 6 7 8 9
SELECTname FROM Employee WHERE id IN ( SELECT managerId FROM Employee WHERE managerId ISNOTNULL GROUPBY managerId HAVING COUNT(*) >= 5 );
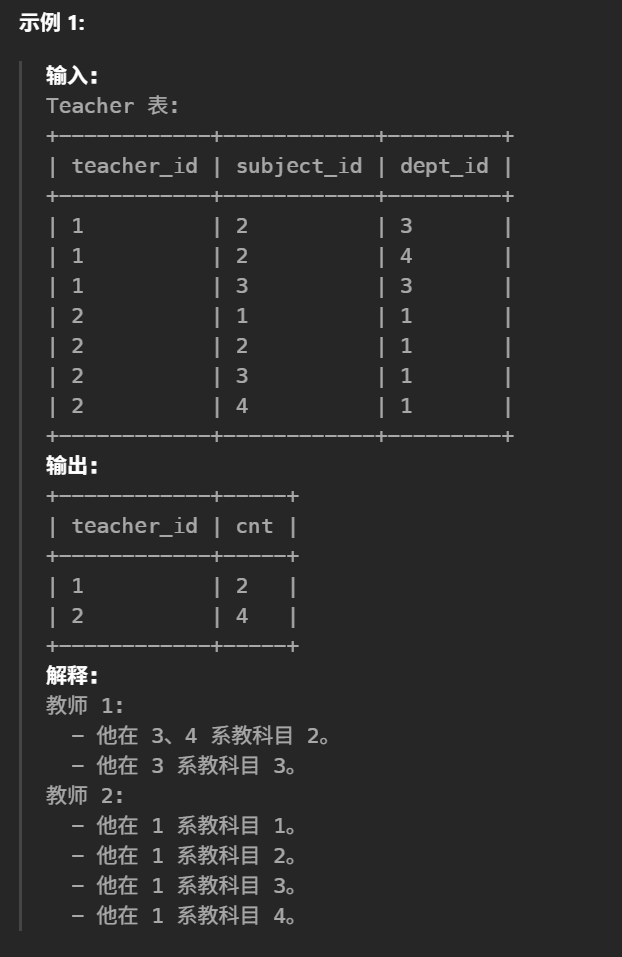
19.每位教师所教师的科目种类的数量(简单)
1 2 3 4
#查询每位老师在大学里教授的科目种类的数量。 select teacher_id, count(distinct subject_id) as cnt from Teacher groupby teacher_id
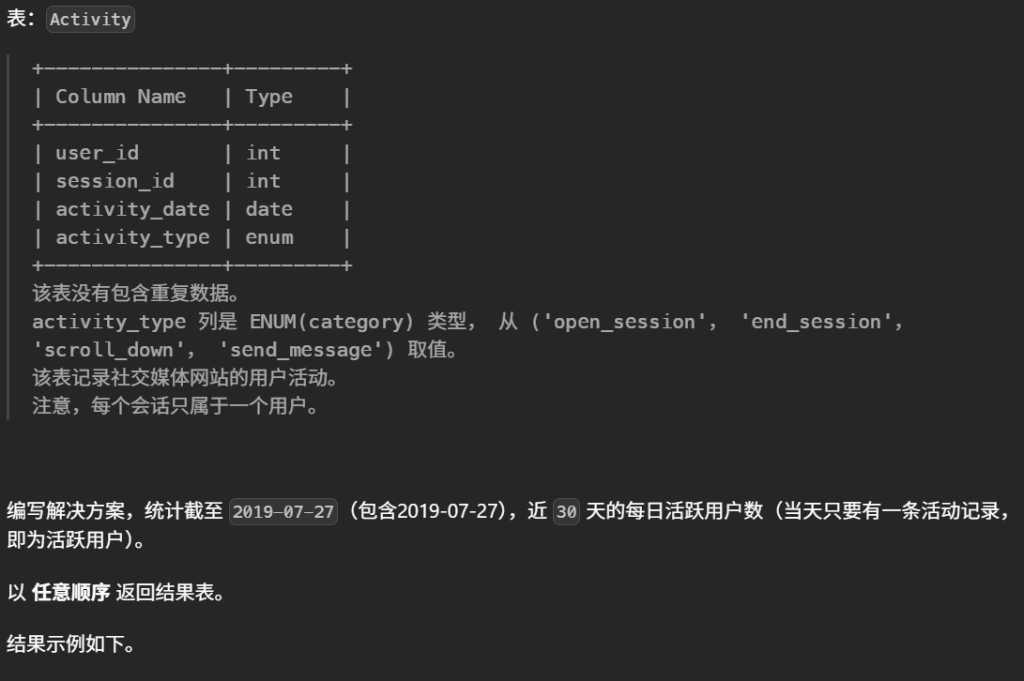
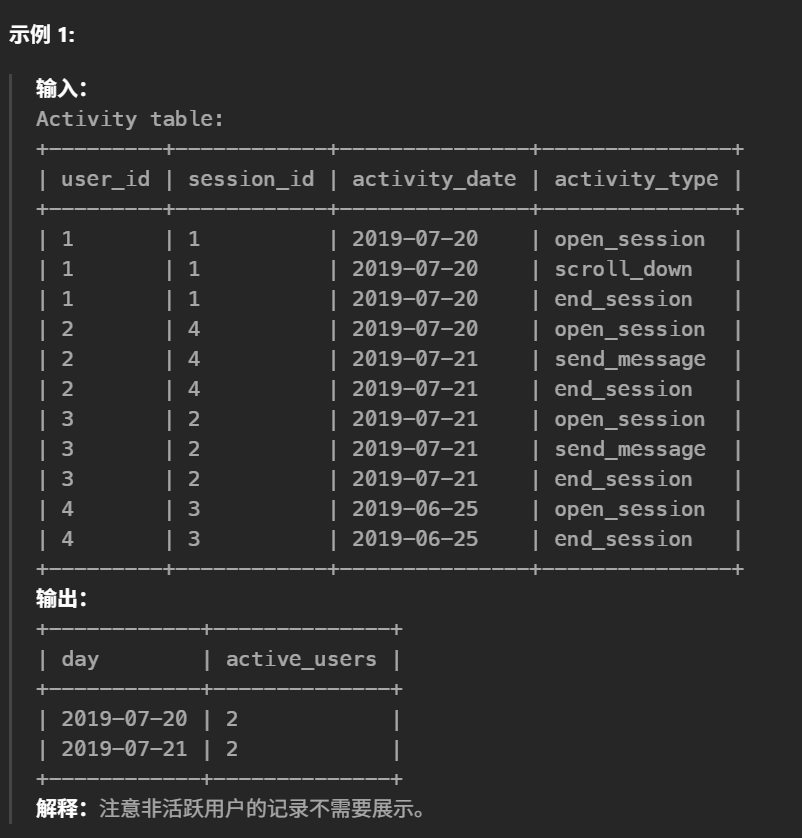
20.查询近30天活跃用户数(简单)
1 2 3 4 5
#编写解决方案,统计截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。 select activity_date as day,count(distinct user_id)as active_users from Activity where datediff("2019-07-27",activity_date) between0AND29 GROUPBY activity_date
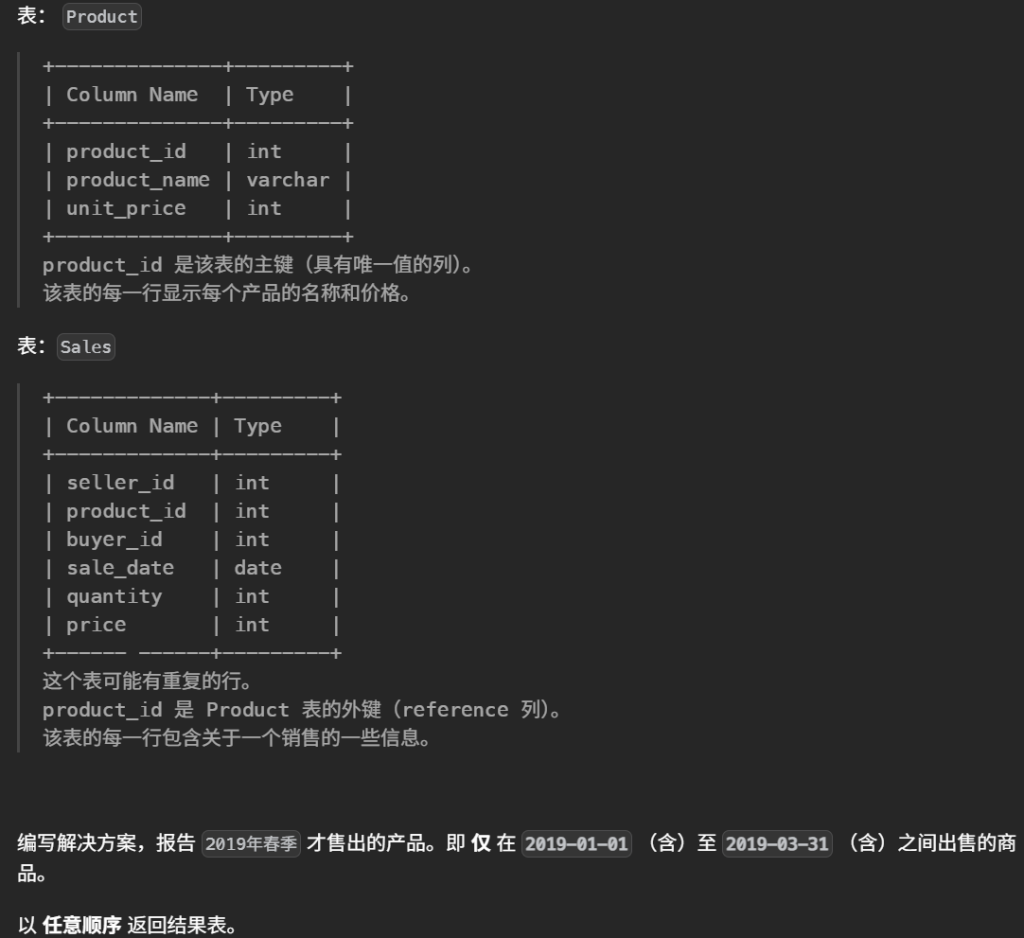
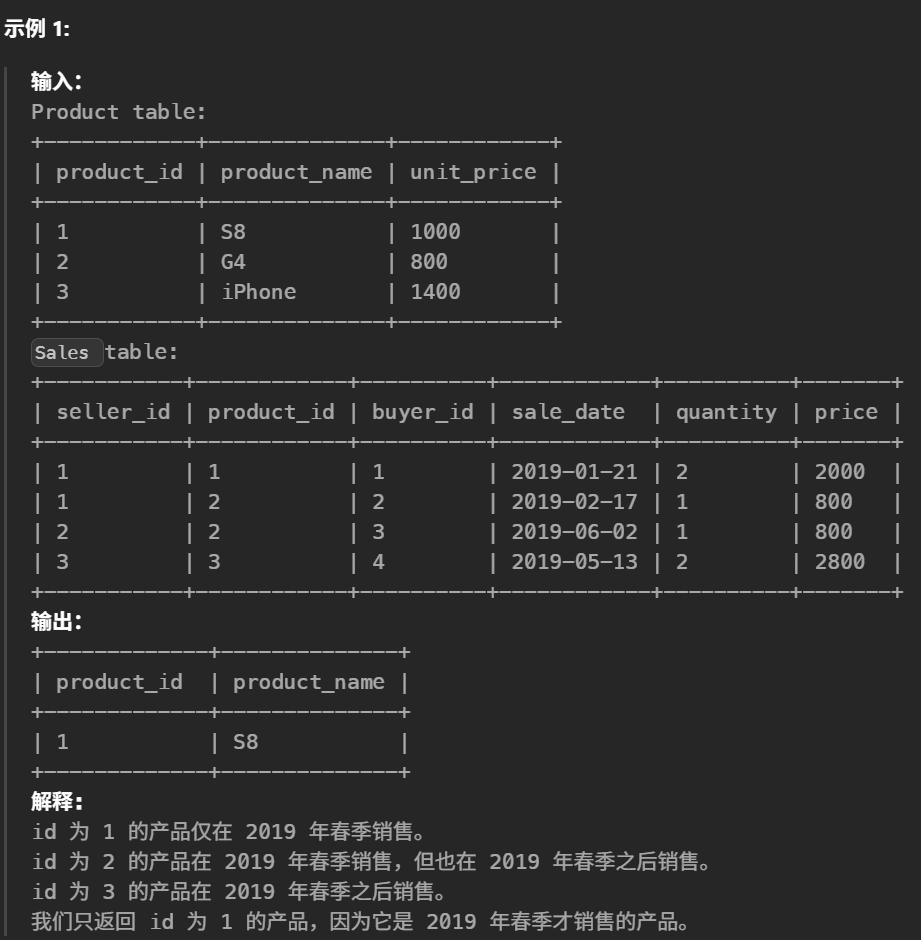
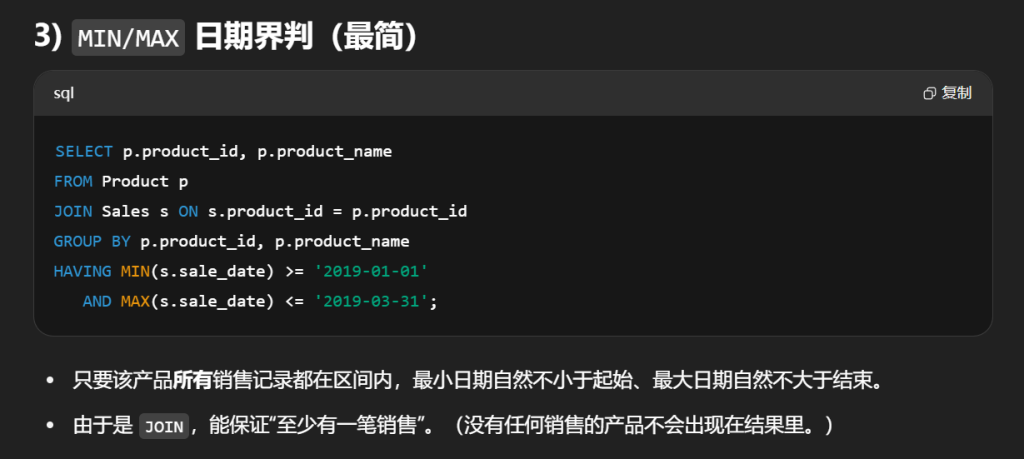
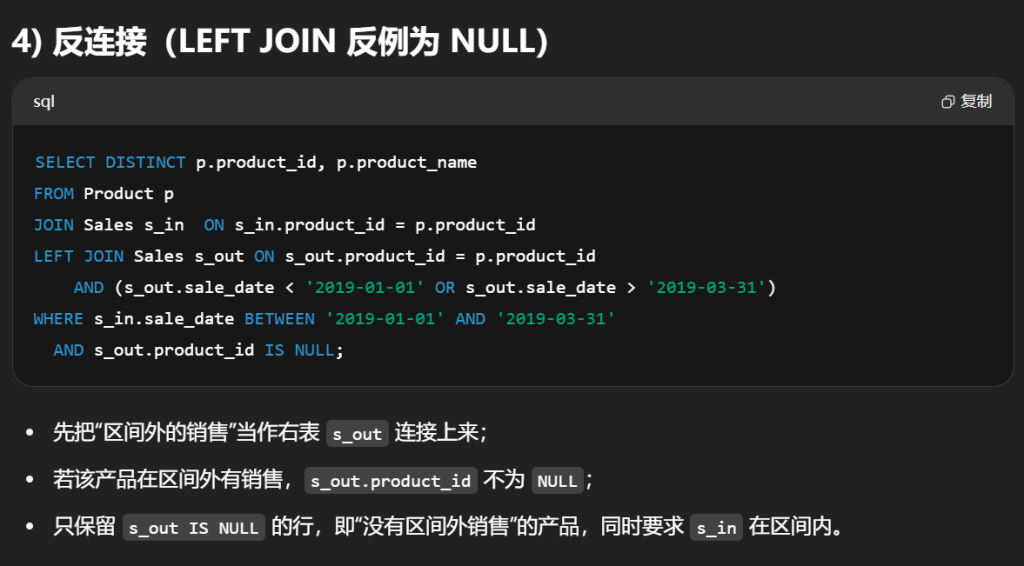
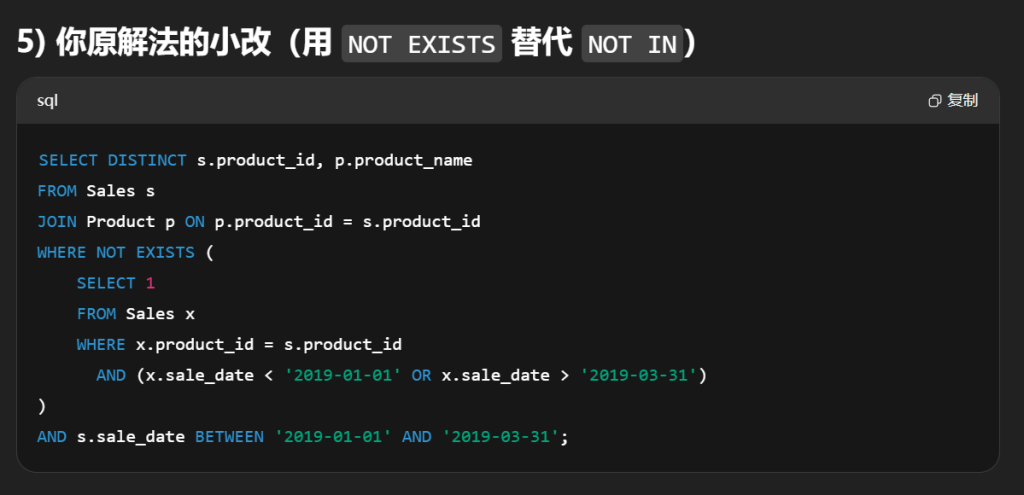
#编写解决方案,报告 2019年春季 才售出的产品。即 仅 在 2019-01-01 (含)至 2019-03-31 (含)之间出售的商品。 selectdistinct s.product_id,p.product_name from Sales s leftjoin Product p on s.product_id = p.product_id where s.product_id notin ( select product_id from Sales s where s.sale_date notbetween'2019-01-01'and'2019-03-31' )
条件聚合
1 2 3 4 5 6 7
SELECT p.product_id, p.product_name FROM Product p JOIN Sales s ON s.product_id = p.product_id GROUP BY p.product_id, p.product_name HAVING SUM(s.sale_date BETWEEN '2019-01-01' AND '2019-03-31') > 0 -- 区间内至少有一笔 AND SUM(s.sale_date < '2019-01-01' OR s.sale_date > '2019-03-31') = 0; -- 区间外 0 笔
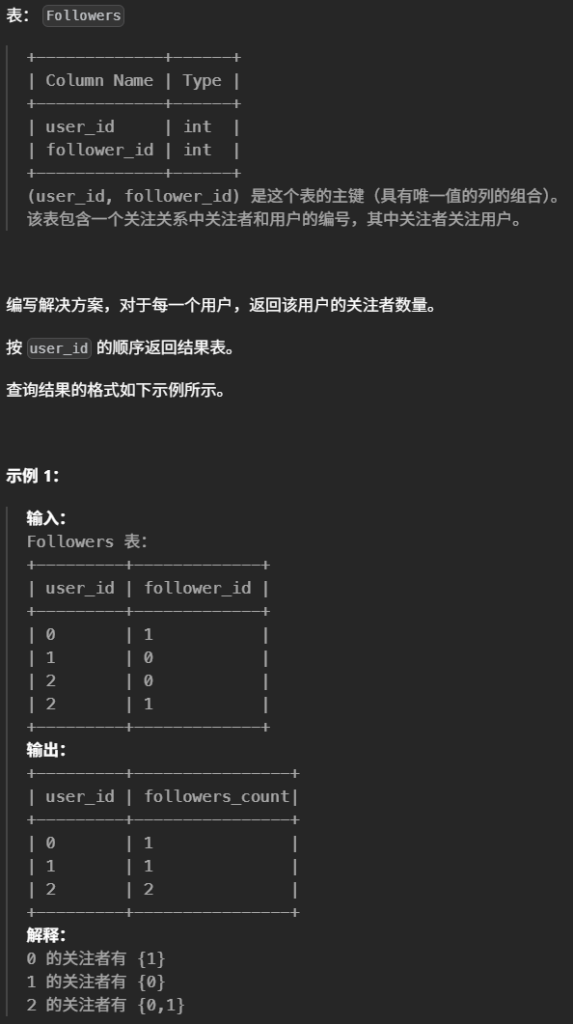
#编写解决方案,对于每一个用户,返回该用户的关注者数量。 select user_id,count(follower_id ) as followers_count from Followers groupby user_id orderby user_id
24.确认率(中等)
1 2 3 4 5 6 7 8
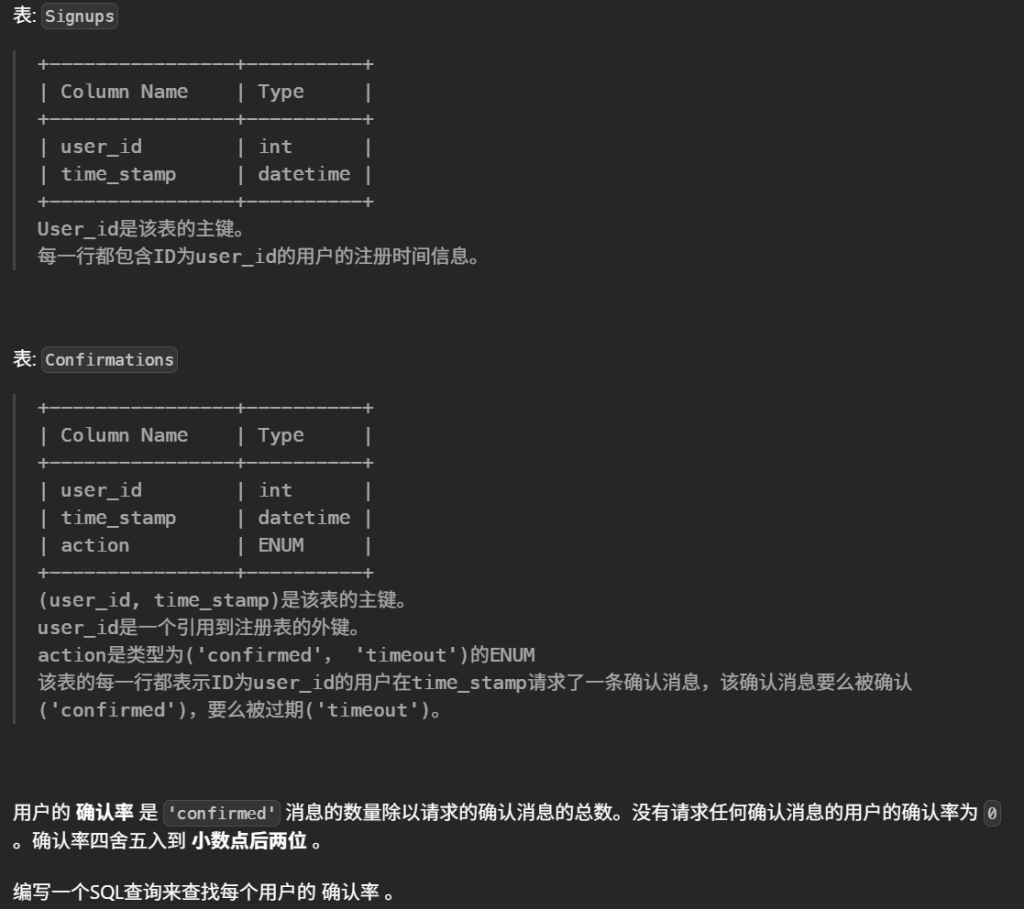
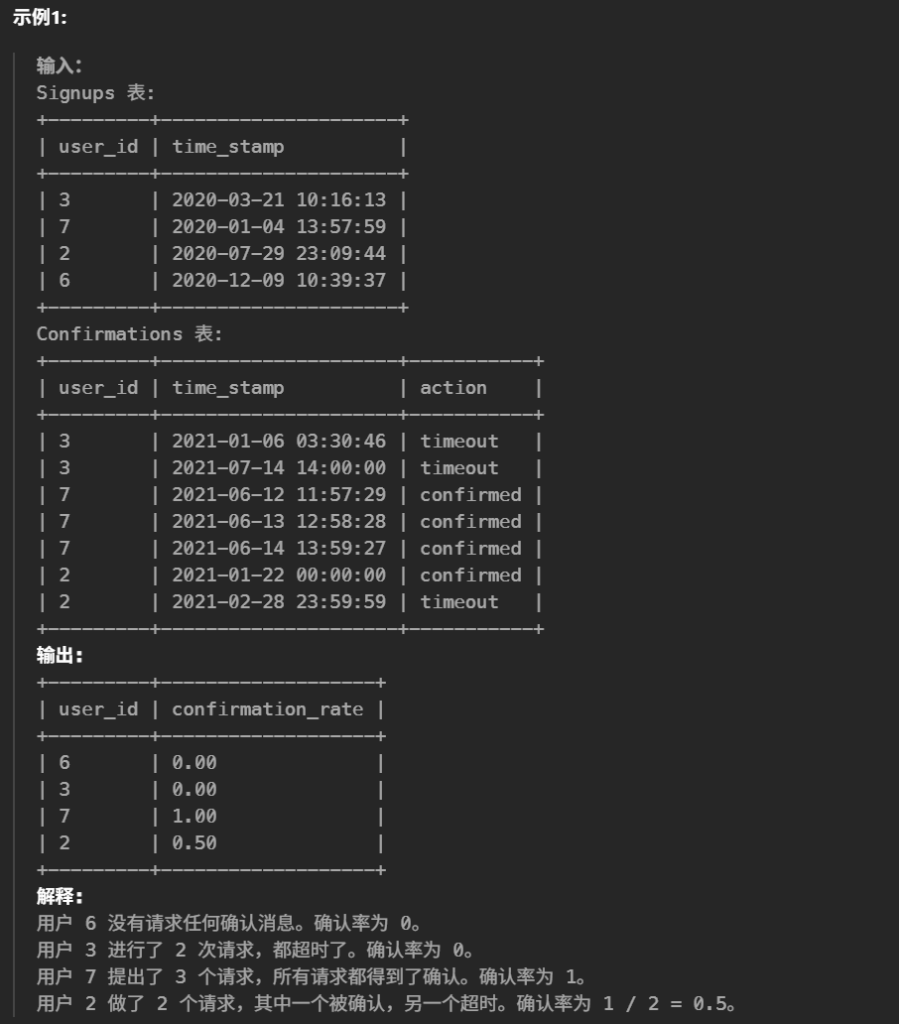
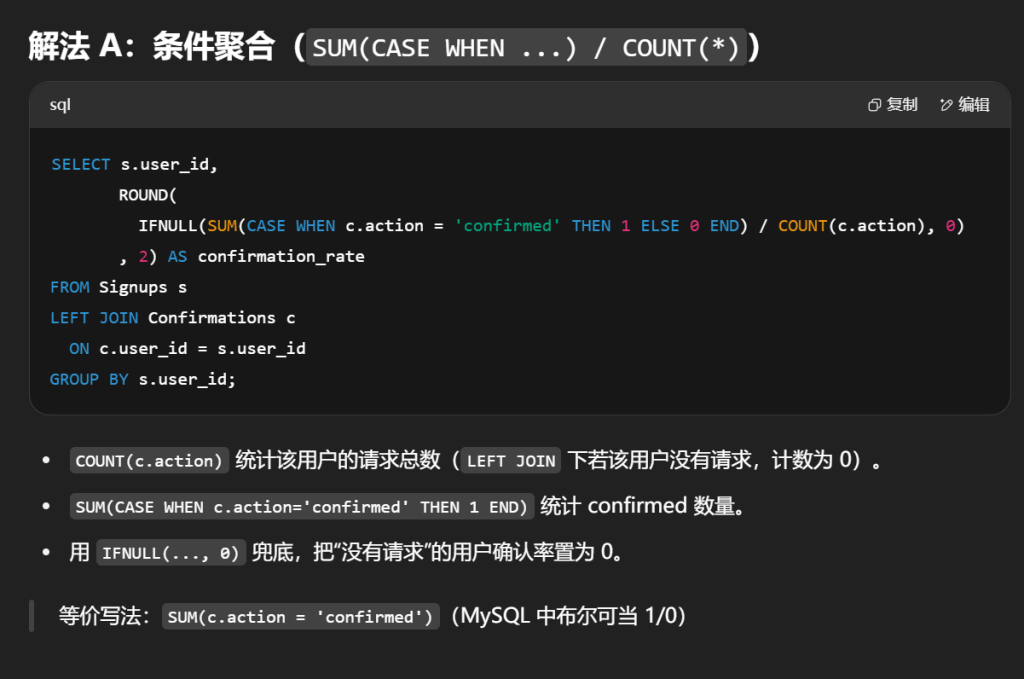
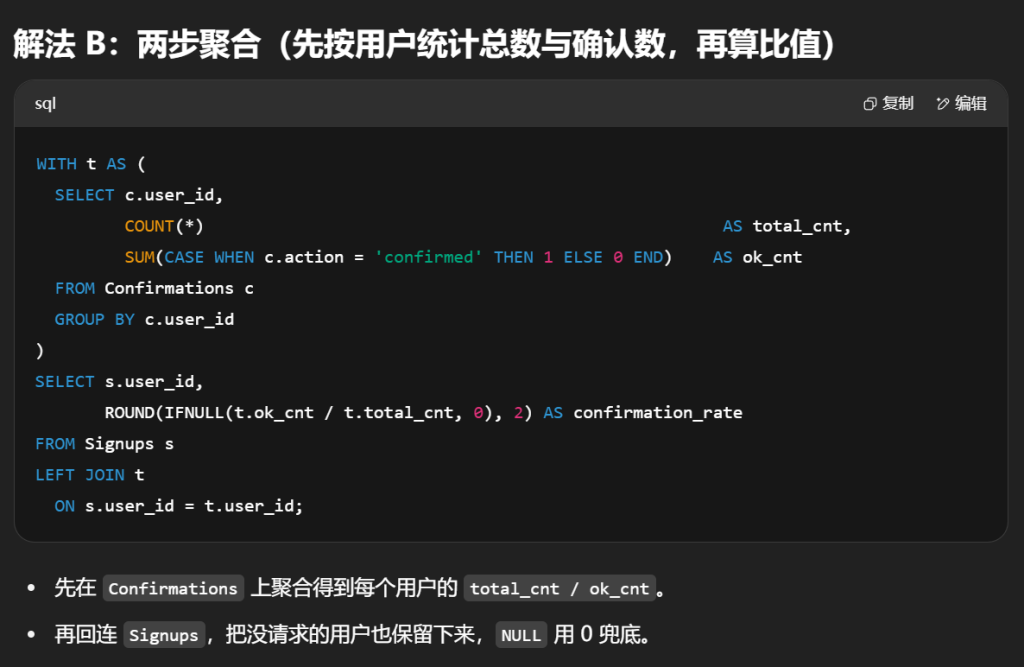
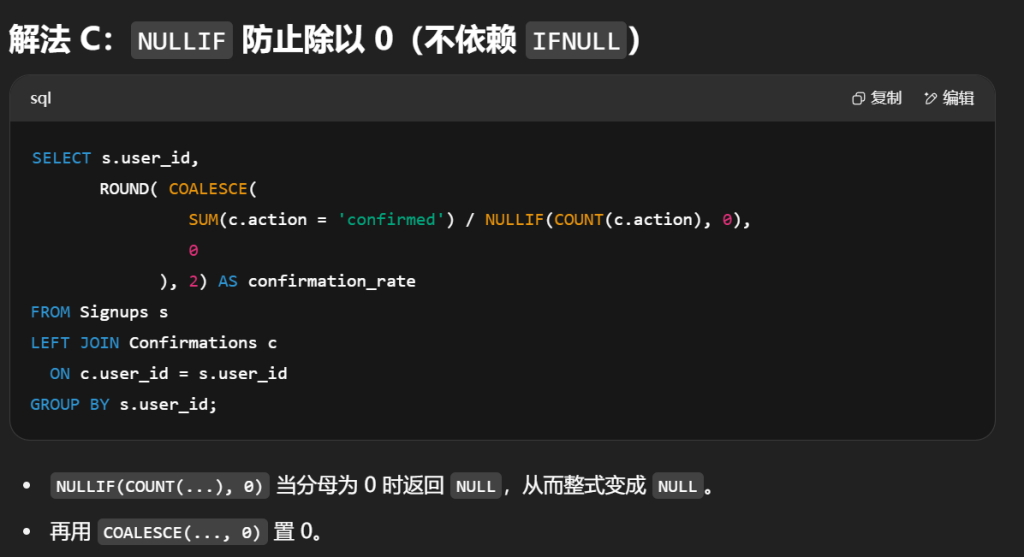
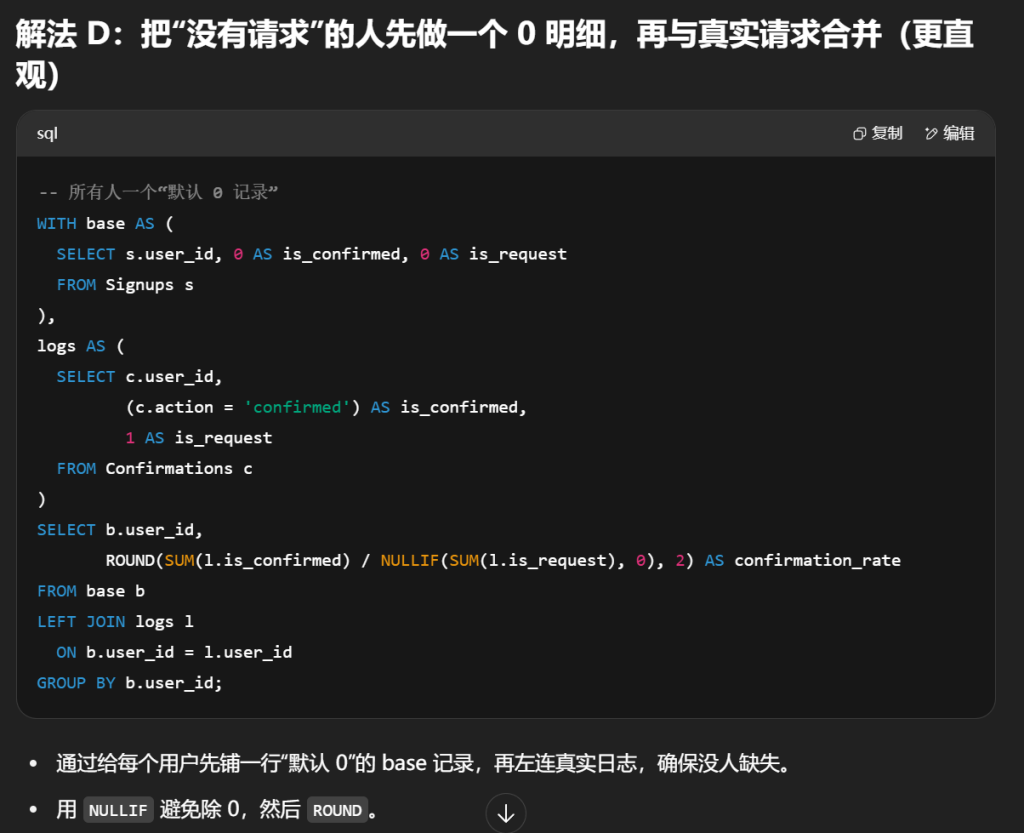
#用户的 确认率 是 'confirmed' 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。 #编写一个SQL查询来查找每个用户的 确认率 。 #confirmed 为该用户确认的消息占发送总消息的比例 select s.user_id,Round(IFNULL(AVG(c.action ='confirmed'),0),2)as confirmation_rate from Signups s left join Confirmations c on c.user_id = s.user_id groupby s.user_id
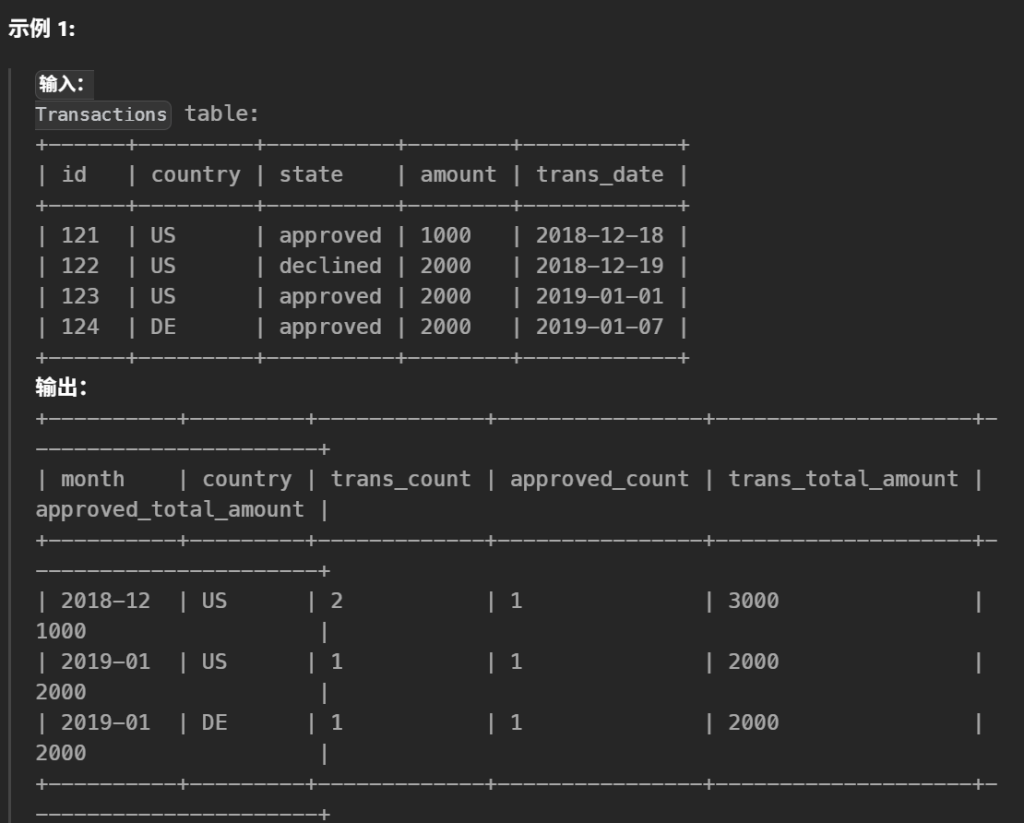
25.每月交易I(中等)
1 2 3 4 5 6 7 8 9 10 11
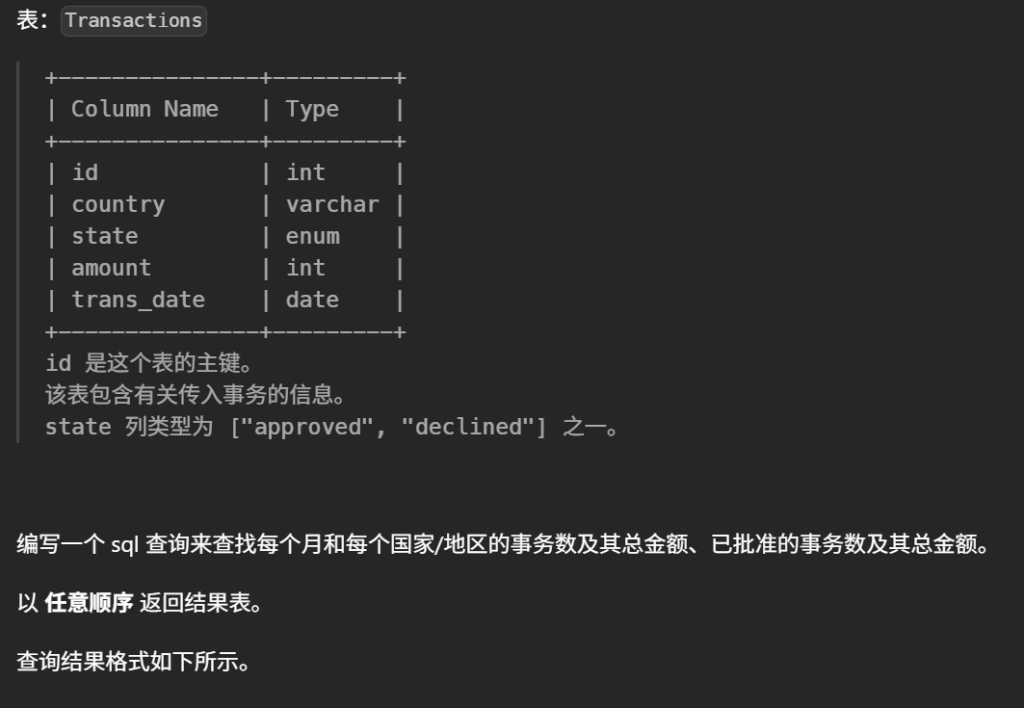
#编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。 SELECT DATE_FORMAT(trans_date, '%Y-%m') AS month, country, COUNT(*) AS trans_count, SUM(state = 'approved') AS approved_count, SUM(amount) AS trans_total_amount, SUM(CASEWHEN state = 'approved' THEN amount ELSE0END) AS approved_total_amount FROM Transactions GROUPBY DATE_FORMAT(trans_date, '%Y-%m'), country
批准的事务数:SUM(state='approved')(在 MySQL 中布尔表达式为真记作 1)
事务总金额:SUM(amount)
批准的事务总金额:SUM(CASE WHEN state='approved' THEN amount ELSE 0 END)
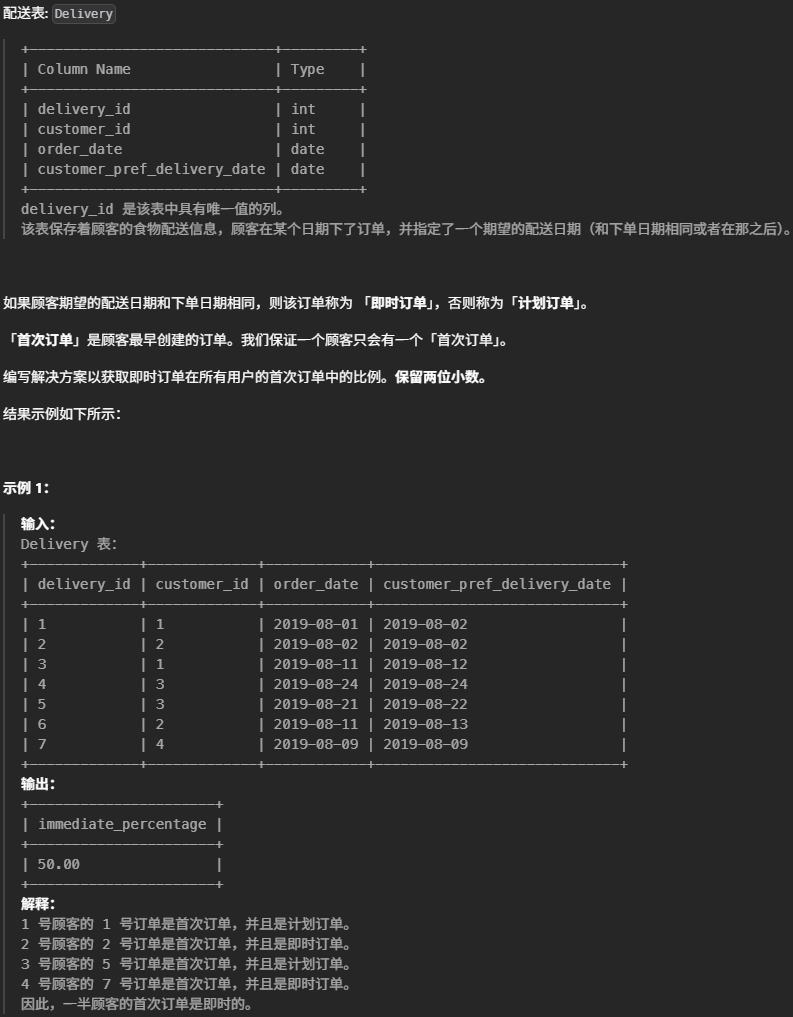
26.即时食物配送II(中等)
1 2 3 4 5 6 7 8 9 10 11 12
#如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。 #「首次订单」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。 #编写解决方案以获取即时订单在所有用户的首次订单中的比例。保留两位小数。 selectRound(100*AVG(d.order_date = d.customer_pref_delivery_date),2) as immediate_percentage from Delivery d join ( select customer_id,MIN( order_date ) as first_order_date from Delivery groupby customer_id )f on d.customer_id = f.customer_id and d.order_date = f.first_order_date
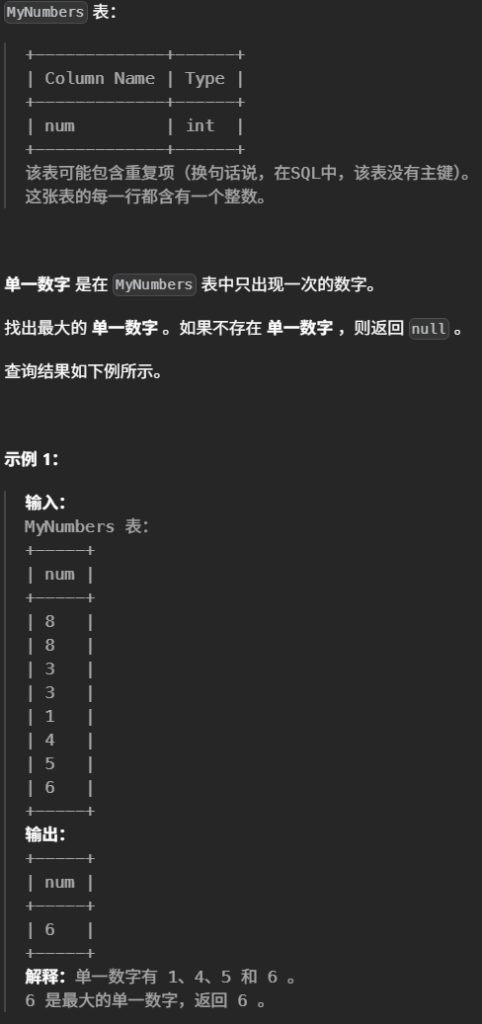
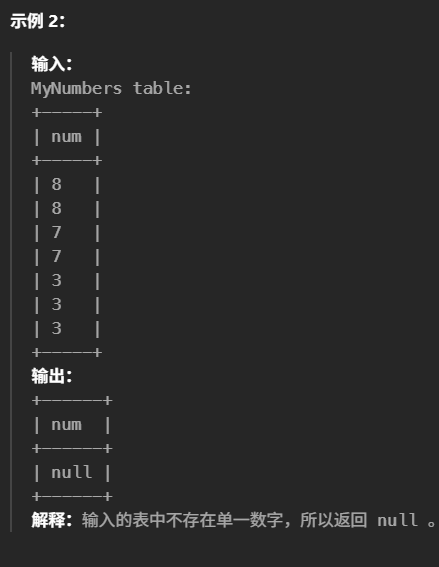
27.只出现一次的最大数字(简单)
1 2 3 4
#找出最大的 单一数字 。如果不存在 单一数字 ,则返回 null 。 select Max(num) as num from MyNumbers where num notin( select num from MyNumbers groupby num having count(num) > 1)
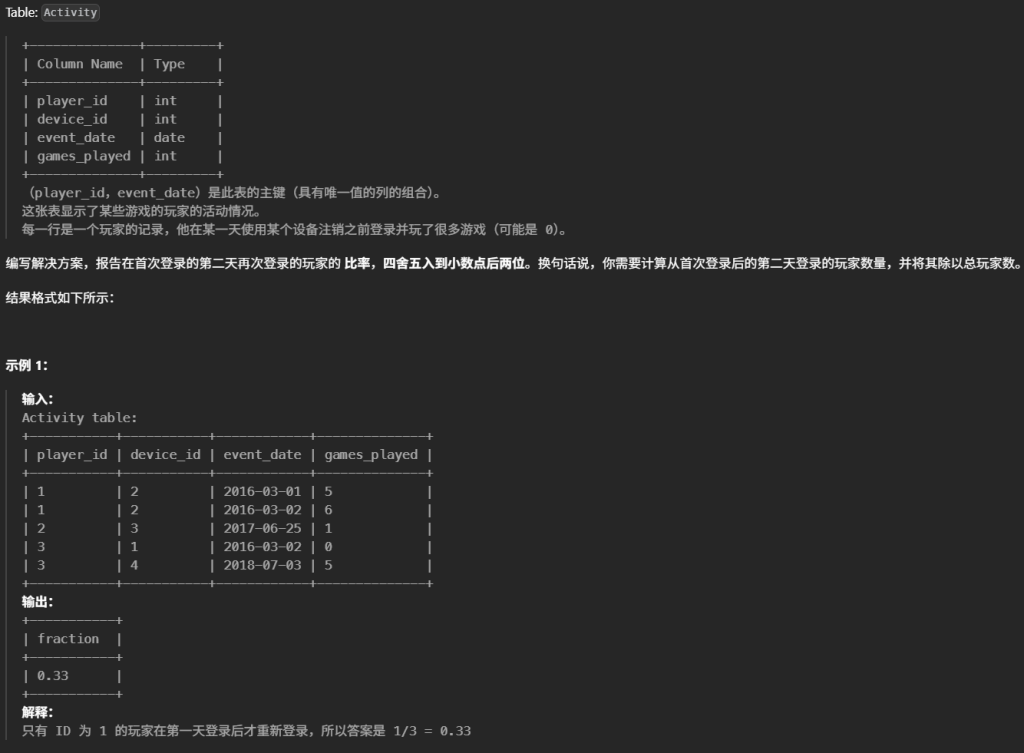
# Write your MySQL query statement below #编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录后的第二天登录的玩家数量,并将其除以总玩家数。 #1.查玩家总数 #select count( distinct player_id) from Activity #2.查询第二天登录的玩家数量 #2.1先查每个玩家的首次登录日期 #(select player_id,Min(event_date) as first_login_date #from Activity #group by player_id ) as F1 #2.2找出第二天登录的玩家数量:首次登录+1 #inner join Activity as A #on F1.player_id = A.player_id #and A.event_date = DATE_ADD(F1.first_login_date,INTERVAL 1 DAY)
#整合这几步最终的sql为 select Round( -- 分子: COUNT 出 JOIN 成功的玩家数 Count(F1.player_id) / -- 分母: 子查询计算总玩家数 (select count( distinct player_id) from Activity) --保留两位数字 ,2 ) as fraction from (#2.1先查每个玩家的首次登录日期 (select player_id,Min(event_date) as first_login_date from Activity groupby player_id ) )as F1 #2.2找出第二天登录的玩家数量:首次登录+1 innerjoin Activity as A on F1.player_id = A.player_id and A.event_date = DATE_ADD(F1.first_login_date,INTERVAL1 DAY)
下面这样写也是一样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
-- players whose first day +1 also login SELECT ROUND( IFNULL( ( SELECT COUNT(DISTINCT a.player_id) FROM ( SELECT player_id, MIN(event_date) AS first_login FROM Activity GROUPBY player_id ) f JOIN Activity a ON a.player_id = f.player_id AND a.event_date = DATE_ADD(f.first_login, INTERVAL1 DAY) ) / (SELECT COUNT(DISTINCT player_id) FROM Activity) , 0) , 2) AS fraction;
29.每位经理的下属员工数量(简单)
1 2 3 4 5 6 7 8 9 10
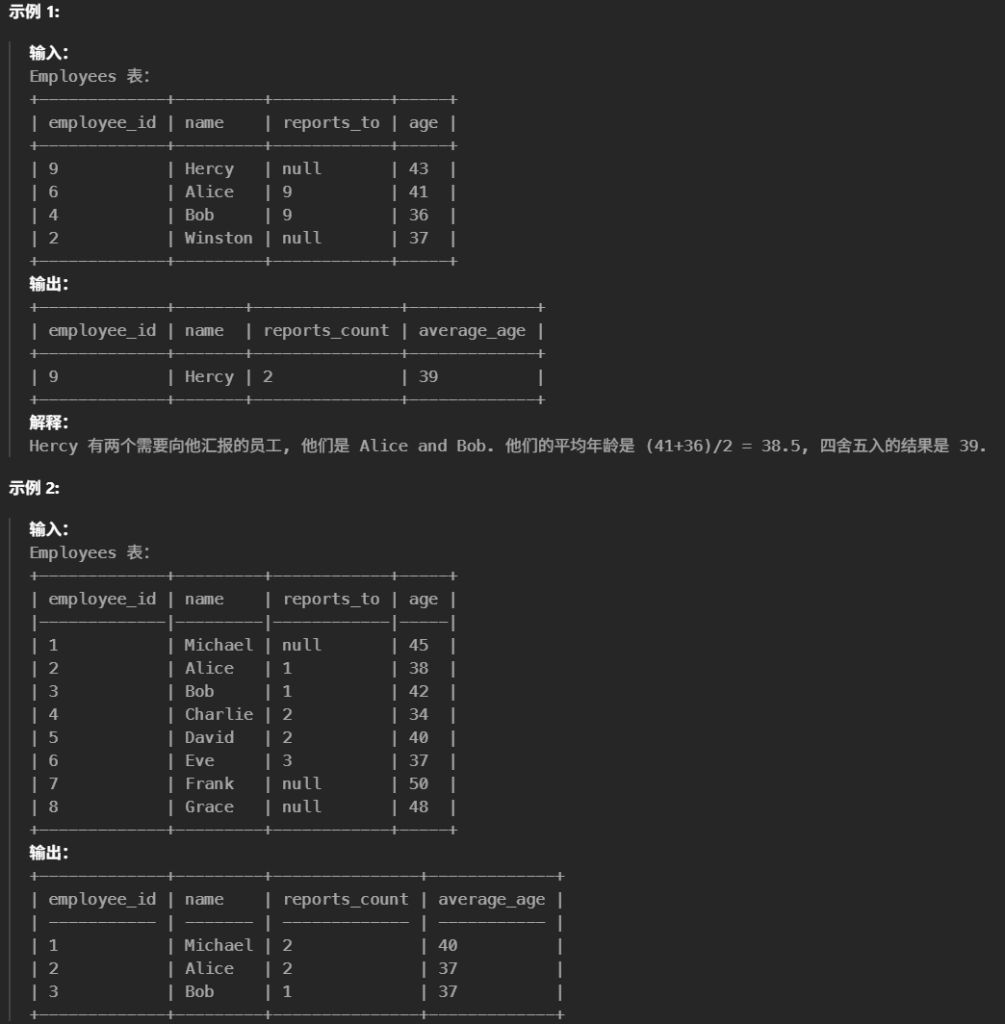
#编写一个解决方案来返回需要听取汇报的所有经理的 ID、名称、直接向该经理汇报的员工人数,以及这些员工的平均年龄,其中该平均年龄需要四舍五入到最接近的整数。 #返回的结果集需要按照 employee_id 进行排序。 selecte. employee_id,e.name, Count(r.reports_to)as reports_count, Round(AVG(r.age),0)as average_age from Employees e innerjoin Employees r one.employee_id = r.reports_to groupby r.reports_to orderby employee_id
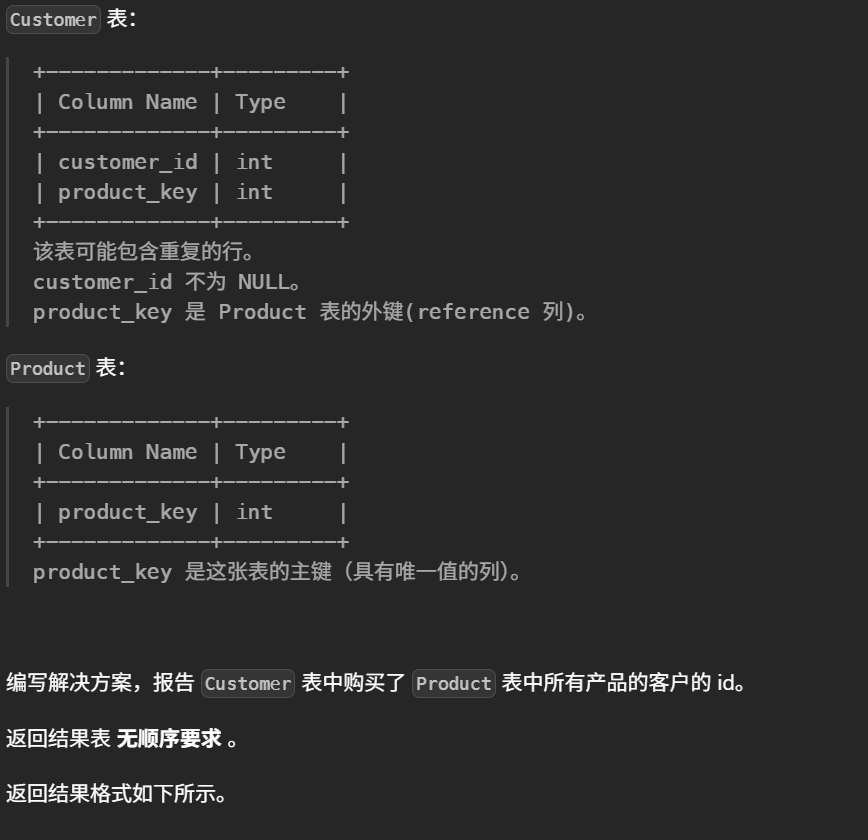
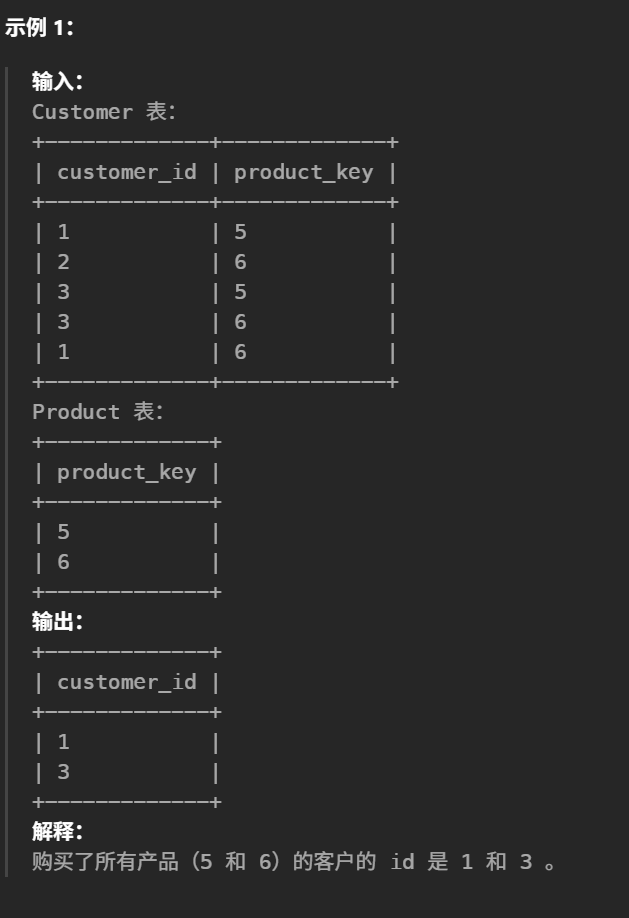
30.买下所有产品的客户(中等)
1 2 3 4 5 6
#编写解决方案,报告 Customer 表中购买了 Product 表中所有产品的客户的 id。 selectdistinct customer_id from Customer c groupby customer_id #按 customer_id 查时:Customer 表中出现的product_key = Product 表中出现的product_key havingcount(distinct c.product_key) = (selectcount(product_key)as cnt from Product)
31.员工的直属部门(简单)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#一个员工可以属于多个部门。当一个员工加入超过一个部门的时候,他需要决定哪个部门是他的直属部门。请注意,当员工只加入一个部门的时候,那这个部门将默认为他的直属部门,虽然表记录的值为'N'. #请编写解决方案,查出员工所属的直属部门。 #若员工在多个部门,则取 primary_flag = 'Y' 的那条; #若员工只在一个部门(即 count(*)=1),就取那一条(不管 flag 是什么)。 select employee_id,department_id from Employee e where e.primary_flag = 'Y' or employee_id in( select employee_id from Employee groupby employee_id having count(*) = 1 ) orderby employee_id,department_id
解释:
子查询找出“只有一个部门”的员工 employee_id;
外层选出两类行:primary_flag='Y' 的行,以及只有一个部门的那位员工的那一行。
写法二:窗口函数(MySQL 8+)
1 2 3 4 5 6 7 8 9 10 11 12
WITH t AS ( SELECT employee_id, department_id, primary_flag, COUNT(*) OVER (PARTITIONBY employee_id) AS cnt FROM Employee ) SELECT employee_id, department_id FROM t WHERE primary_flag = 'Y'OR cnt = 1 ORDERBY employee_id, department_id;
SELECT employee_id, department_id FROM t WHERE primary_flag = 'Y'OR cnt = 1 ORDERBY employee_id, department_id;
cnt = 1:该员工 只在一个部门,就取这唯一的一行(不管 primary_flag 记录的是 Y 还是 N)。
primary_flag = 'Y':该员工 在多个部门 时,只取标了主部门的那一行。
因此,这个 WHERE 同时覆盖了两类情况,满足题意:
只有一个部门 → cnt = 1,取它。
多个部门 → 用 primary_flag = 'Y' 选出主部门。
ORDER BY 只是为了输出稳定,可有可无。
用示例走一遍(题目样例)
原表(简化):
employee_id
department_id
primary_flag
1
1
N
1
2
Y
2
1
Y
2
3
N
3
1
Y
4
2
N
4
3
Y
CTE t 里多了 cnt:
employee_id
department_id
primary_flag
cnt
1
1
N
2
1
2
Y
2
2
1
Y
2
2
3
N
2
3
1
Y
1
4
2
N
2
4
3
Y
2
外层 WHERE primary_flag='Y' OR cnt=1 保留的行:
emp=1:两行里只有 Y 的那行保留 → (1, 2)
emp=2:保留 Y 的那行 → (2, 1)
emp=3:cnt=1,唯一一行保留 → (3, 1)
emp=4:保留 Y 的那行 → (4, 3)
结果:每个员工一行,就是他的主部门。
为什么不用 GROUP BY?
如果你 GROUP BY employee_id,就只剩一行,department_id 该取谁?
除非你再写一轮子查询/关联去“把那一行拉回来”。窗口函数保留了明细粒度,所以外层筛选非常干净。
边界 / 数据质量说明
题目保证:员工加入多个部门时会唯一选一个主部门(Y),所以不会出现多个 Y。
如果担心数据异常(比如既无 Y 又多部门),可以用更稳妥的写法:
1 2 3 4 5 6 7 8 9 10 11 12
WITH t AS ( SELECT employee_id, department_id, primary_flag, ROW_NUMBER() OVER ( PARTITIONBY employee_id ORDERBYCASEWHEN primary_flag='Y'THEN0ELSE1END ) AS rn FROM Employee ) SELECT employee_id, department_id FROM t WHERE rn = 1;
更“容错”。
一句话概括这条 SQL 的巧妙点: 用窗口函数把“每个员工的部门数量”写到每一行上,再用一条简单的 WHERE 同时处理两种规则,既简洁又高效。
32.判断三角形(简单)
1 2 3 4 5 6 7
#对每三个线段报告它们是否可以形成一个三角形。 #两边之和大于第三边 #两边之差的绝对值小于第三边 select t1.*, if(((t1.x+t1.y)>t1.z and (t1.y+t1.z)>t1.x and (t1.x+t1.z)>t1.y),'Yes','No')as triangle from Triangle t1
法二
1 2 3 4 5 6
select t1.*, casewhen x+y+z>2*greatest(x,y,z) then'Yes' else'No' endas triangle from triangle
SELECT t1.*, CASE WHEN x+y+z > 2*GREATEST(x,y,z) THEN'Yes' ELSE'No' ENDAS triangle FROM triangle;
含义:
GREATEST(x,y,z) 找到三条边里最长的那条边。
如果 x+y+z > 2*最长边,就说明三边能构成三角形 → 输出 'Yes'。
否则 → 输出 'No'。
这是利用“三角形两边之和大于第三边”的判定条件。
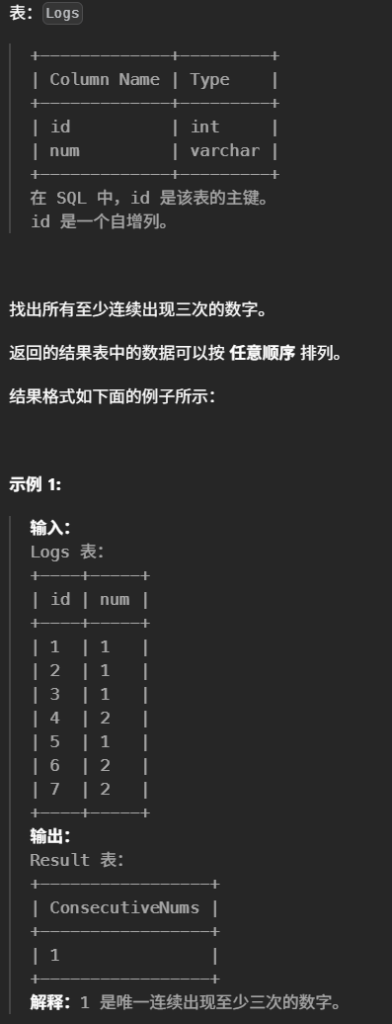
33.连续出现的数字(中等)
1 2 3 4 5 6 7 8
#找出所有至少连续出现三次的数字。 #返回的结果表中的数据可以按 任意顺序 排列。 select distinct l1.num as ConsecutiveNums from Logs l1 join Logs l2 on l1.id = l2.id - 1 join logs l3 on l2.id = l3.id - 1 where l1.num = l2.num and l2.num = l3.num
解释:
l1.id, l2.id, l3.id 分别是连续的三行(id, id+1, id+2)。
如果这三行的 num 都相同,就说明 num 连续出现了至少三次。
DISTINCT 去重,避免重复结果。
1 2 3 4 5 6 7 8 9 10
#找出所有至少连续出现三次的数字。 #返回的结果表中的数据可以按 任意顺序 排列。 selectdistinct num as ConsecutiveNums from ( select num, lead(num,1)over(orderby id)as next1, lead(num,2)over(orderby id)as next2 from Logs )t where num = next1 and num = next2
# CONCAT 用来拼接字符串 ● LEFT 从左边截取字符 ● RIGHT 从右边截取字符 ● UPPER 变为大写 ● LOWER 变为小写 ● LENGTH 获取字符串长度
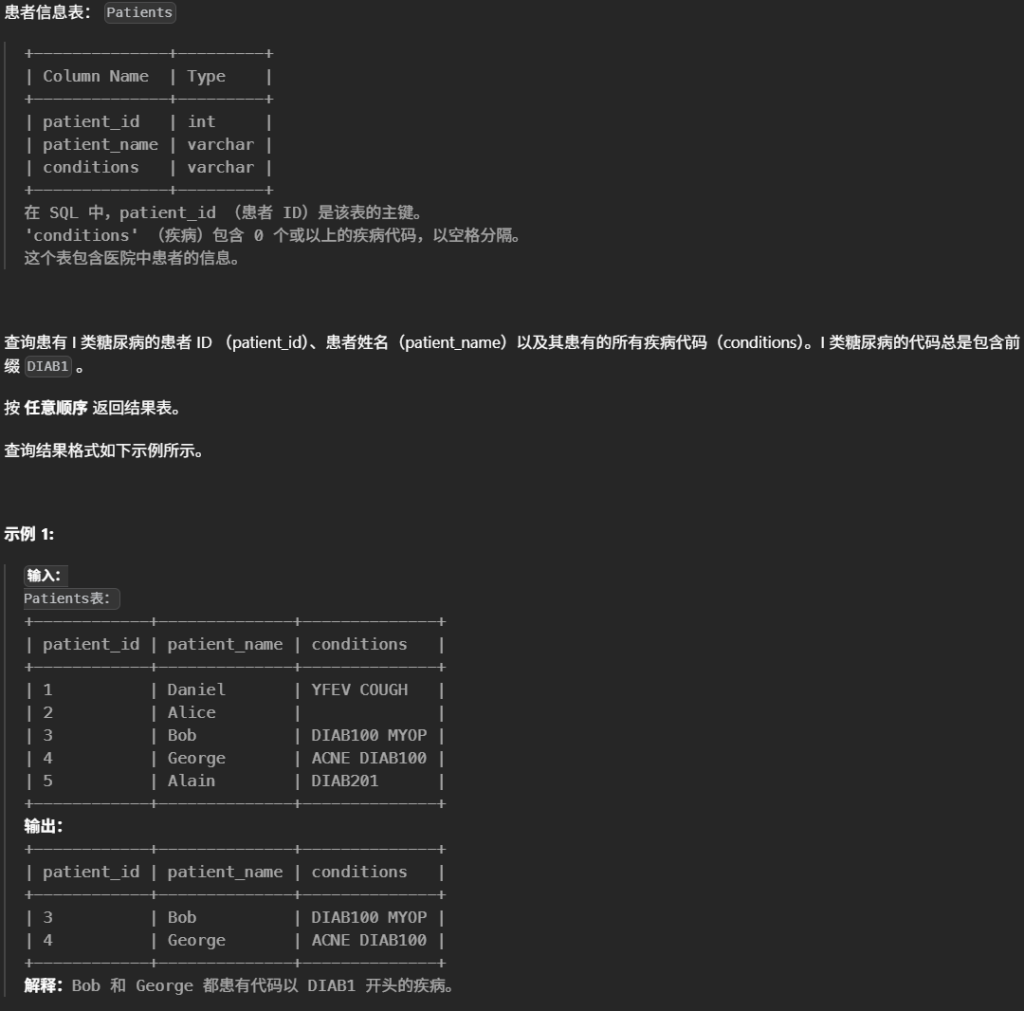
35.患某种疾病的患者(简单)
1 2 3 4 5
#查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。 select * from Patients where conditions like'DIAB1%' or conditions like'% DIAB1%';
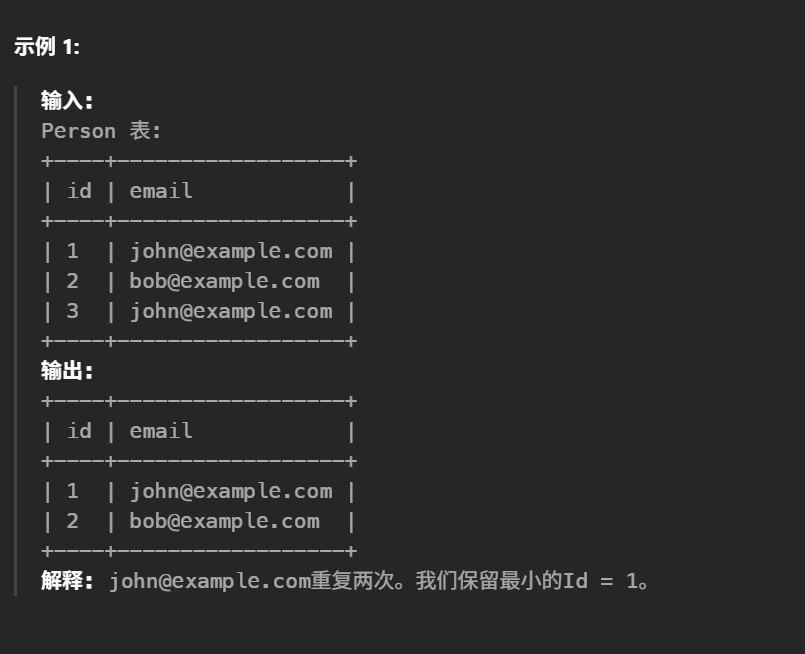
36.删除重复的电子邮箱(简单)
1 2 3 4 5 6
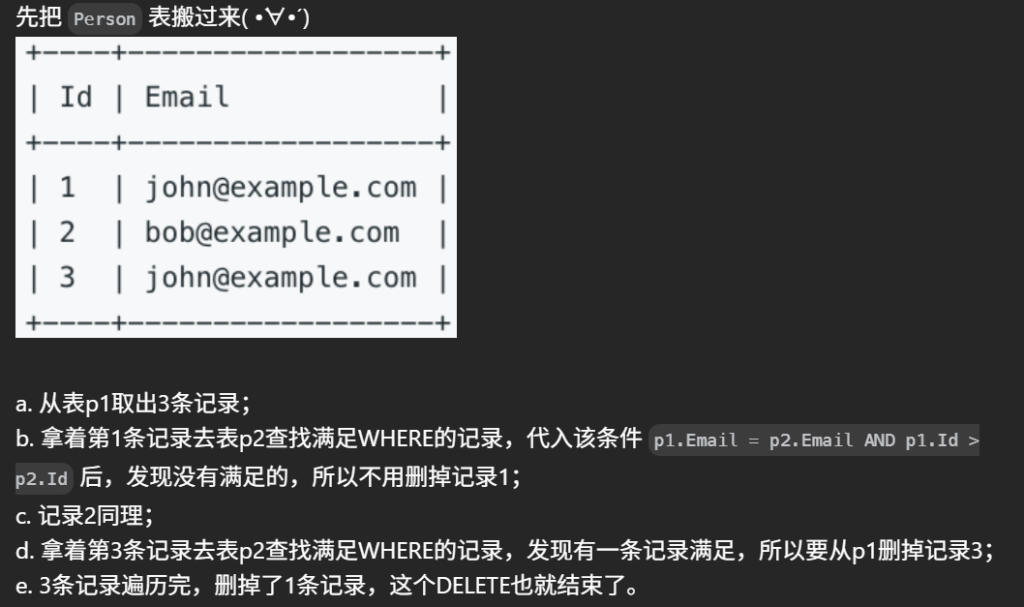
#编写解决方案 删除 所有重复的电子邮件,只保留一个具有最小 id 的唯一电子邮件。 #(对于 SQL 用户,请注意你应该编写一个 DELETE 语句而不是 SELECT 语句。) #运行脚本后,显示的答案是 Person 表。驱动程序将首先编译并运行您的代码片段,然后再显示 Person 表。Person 表的最终顺序 无关紧要 。 DELETEp1 from Person p1, Personp2 wherep1.Email = p2.Email andp1.id > p2.id
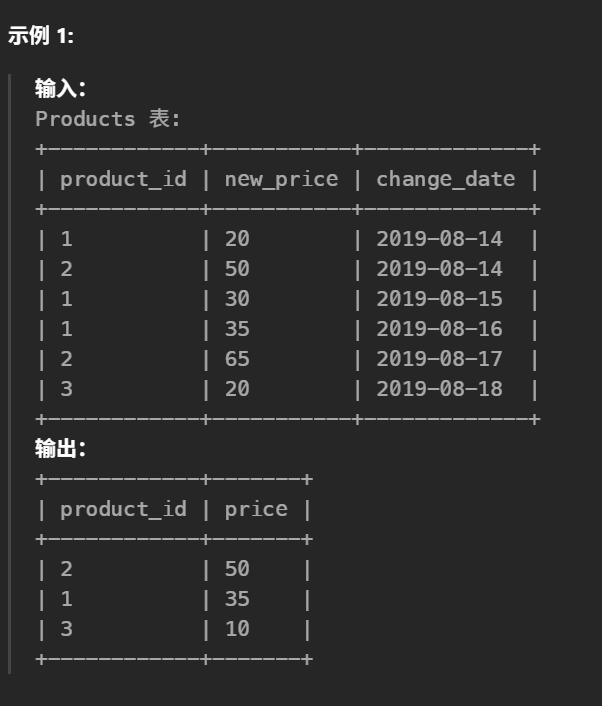
37.指定日期的产品价格(中等)
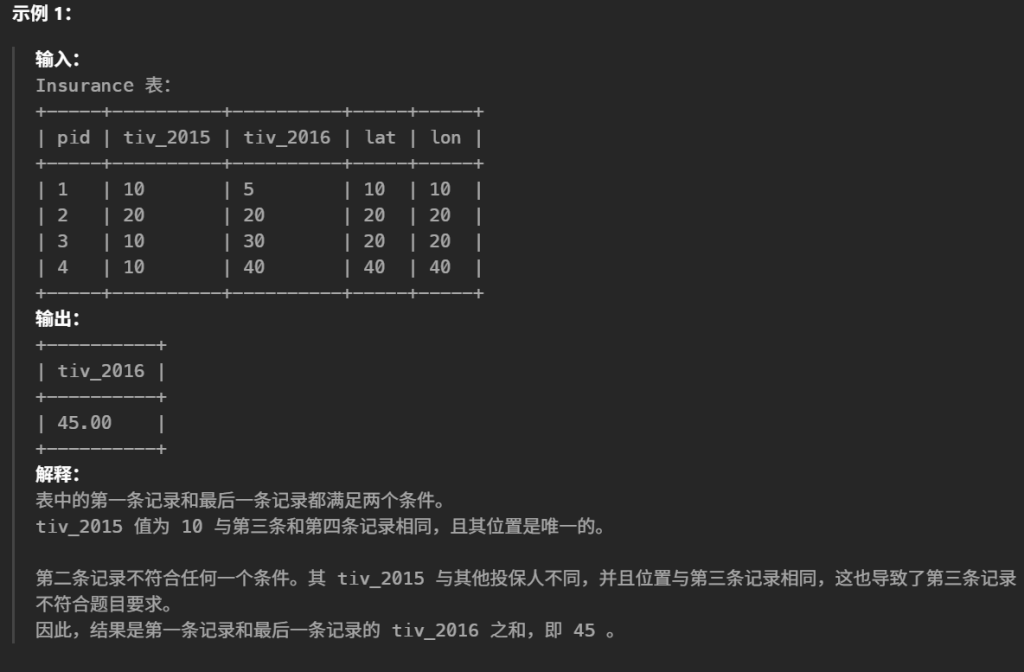
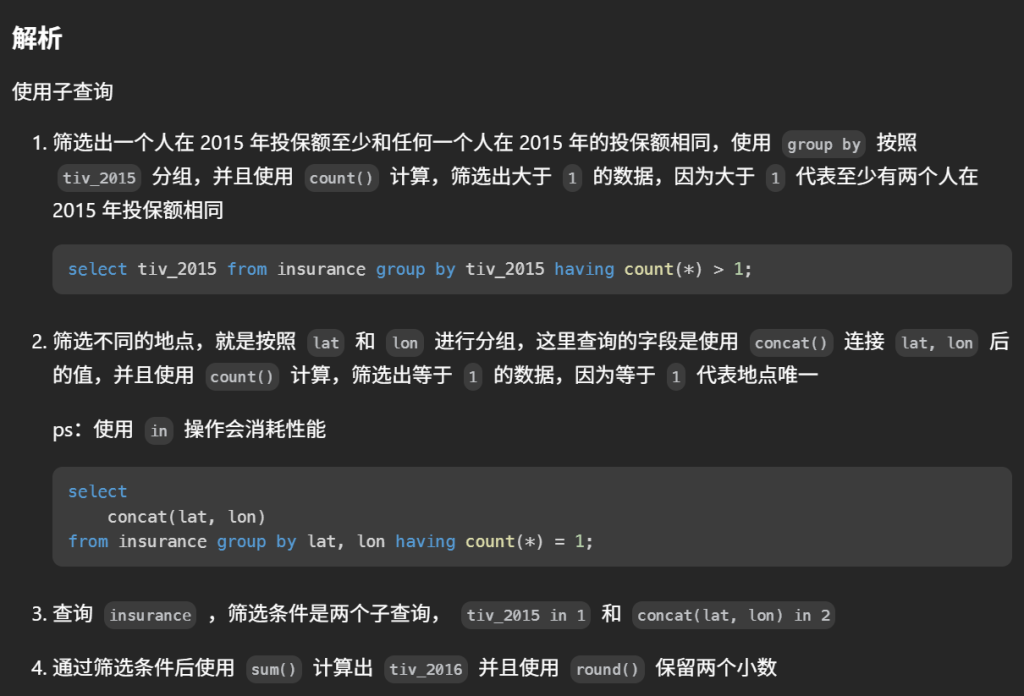
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#一开始,所有产品价格都为 10。 #编写一个解决方案,找出在 2019-08-16 所有产品的价格。 #如果在 2019-08-16没数据,找表中在 2019-08-16以内中最接近在 2019-08-16的数据,否则置默认值10 select p1.product_id, coalesce(p2.new_price,10) as price from(select distinct product_id from Products)p1 left join Products p2 onp1.product_id = p2.product_id andp2.change_date <= '2019-08-16' #保证p2是最接近2019-08-16的数据 and not exists( select 1 from Products p3 where p3.product_id = p2.product_id andp3.change_date <= '2019-08-16' andp3.change_date > p2.change_date ) order by p1.product_id
WITH last_change AS ( SELECT product_id, new_price, ROW_NUMBER() OVER (PARTITIONBY product_id ORDERBY change_date DESC) AS rn FROM Products WHERE change_date <= '2019-08-16' ) SELECT p.product_id, COALESCE(lc.new_price, 10) AS price -- 没有记录则用默认价 10 FROM (SELECTDISTINCT product_id FROM Products) AS p LEFT JOIN last_change lc ON lc.product_id = p.product_id AND lc.rn = 1-- 取每个产品“最近一次”的那条 ORDERBY p.product_id;
说明
ROW_NUMBER() … PARTITION BY product_id ORDER BY change_date DESC:对每个产品按时间倒序编号,rn=1 就是“该日期之前最近的一次变价”。
WHERE change_date <= '2019-08-16':只看目标日之前(含当天)的记录。
COALESCE(..., 10):如果某产品在目标日前没有任何记录,返回默认价 10。
外层用 Products 的去重 product_id 保证输出覆盖所有出现过的产品。
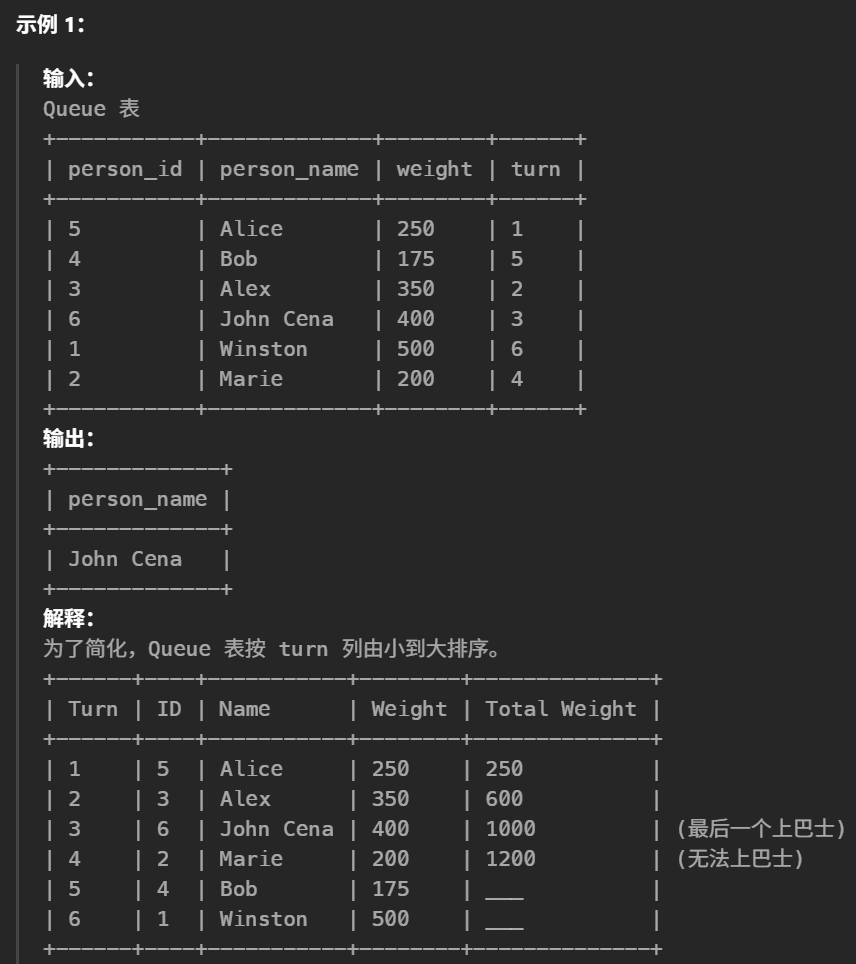
38.最后一个能进入巴士的人(中等)
写法一:自连接
1 2 3 4 5 6 7 8 9 10 11
#编写解决方案找出 最后一个 上巴士且不超过重量限制的乘客,并报告 person_name 。 #题目测试用例确保顺位第一的人可以上巴士且不会超重。 select person_name from Queue q1 #找最接近1000的上一次数据,最后要小于1000 where ( selectsum(weight) from Queue where turn<=q1.turn )<=1000 orderby turn desc limit 1
写法二:窗口函数+where in
1 2 3 4 5 6 7 8 9 10 11
select person_name from Queue #取最后一位 where turn in( selectmax(turn) from ( select turn,person_id,person_name,weight,sum(weight) over(orderby turn) as total_weight from Queue ) as a where a.total_weight<=1000 )
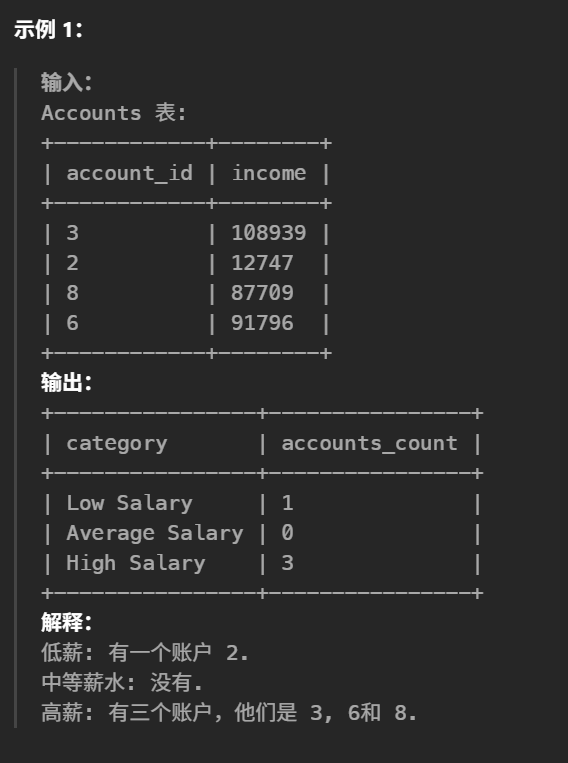
39.按分类统计薪水(中等)
select 类别+union+sum(case when)
1 2 3 4 5 6 7 8 9 10 11 12 13
#查询每个工资类别的银行账户数量。 #结果表 必须 包含所有三个类别。 如果某个类别中没有帐户,则报告 0 。 select'Low Salary'as category, sum(casewhen income<20000then1else0end) as accounts_count from accounts union select'High Salary'as category, sum(casewhen income>50000then1else0end) as accounts_count from accounts union select'Average Salary'as category, sum(casewhen income>=20000and income<=50000then1else0end) as accounts_count from accounts
select目标字段+where过滤条件+union去重合并表
1 2 3 4 5 6 7 8 9 10 11 12 13 14
select'Low Salary'as category, count(*) as accounts_count from accounts where income<20000 union select'Average Salary'as category, count(*) as accounts_count from accounts where income<=50000and income>=20000 union select'High Salary'as category, count(*) as accounts_count from accounts where income>50000
ifnull输出0值+union all临时表+left join
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# Write your MySQL query statement below select a.category, ifnull(count(account_id),0) as accounts_count from ( select'Low Salary'as category unionallselect'Average Salary' unionallselect'High Salary' ) as a leftjoin (select account_id, case when income<20000then'Low Salary' when income<=50000then'Average Salary' else'High Salary' endas category from accounts ) as b on a.category=b.category groupby a.category
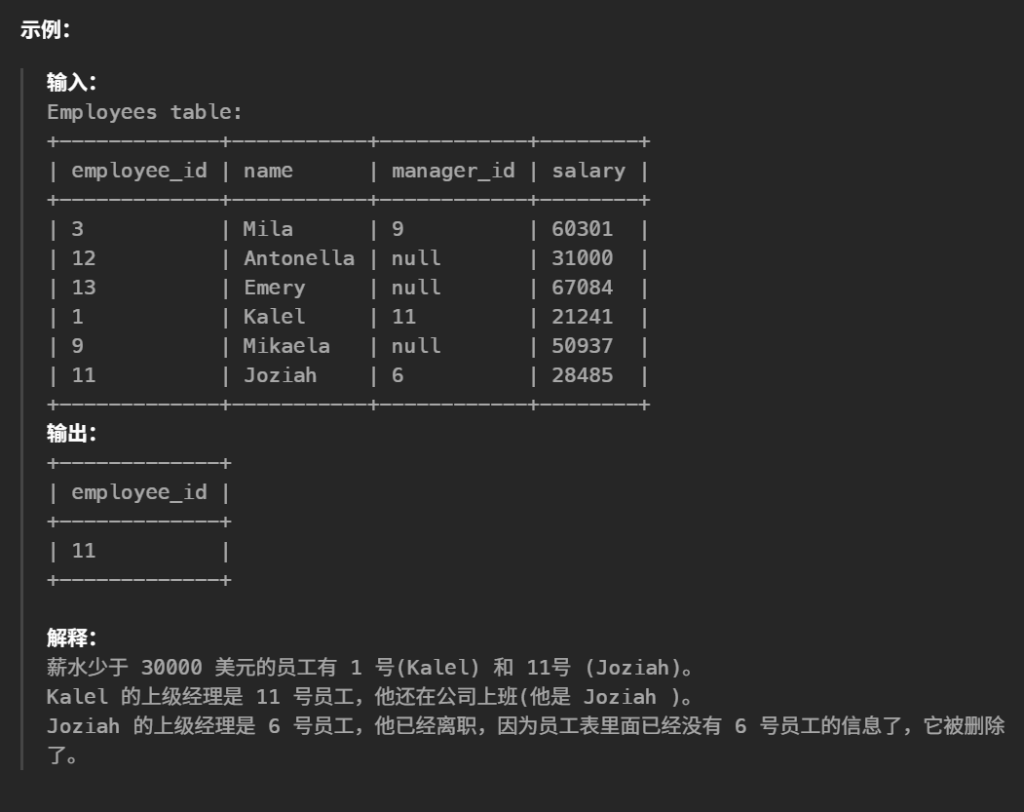
40.上级经理已离职的公司员工(简单)
1 2 3 4 5 6 7 8 9
#查找这些员工的id,他们的薪水严格少于$30000 并且他们的上级经理已离职。当一个经理离开公司时,他们的信息需要从员工表中删除掉,但是表中的员工的manager_id 这一列还是设置的离职经理的id 。 #返回的结果按照employee_id 从小到大排序。 select employee_id from Employees where salary<30000 and manager_id not in( select distinct employee_id from Employees ) orderby employee_id asc
写法2
1 2 3 4 5 6
select a.employee_id from employees a leftjoin employees b on a.manager_id=b.employee_id where b.employee_id isnulland a.manager_id isnotnulland a.salary<30000 orderby a.employee_id
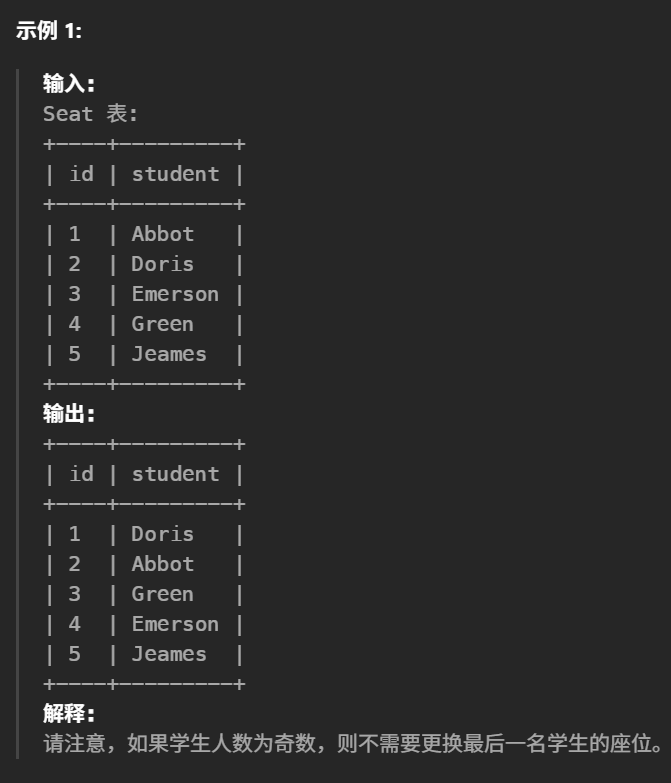
41.换座位(中等)
1 2 3 4 5 6 7 8 9 10 11 12
#编写解决方案来交换每两个连续的学生的座位号。如果学生的数量是奇数,则最后一个学生的id不交换。
#按 id 升序 返回结果表。 select case when id%2 = 1andid<(select max(id) from Seat)thenid+1 when id%2 = 0thenid-1 elseid endasid, student from Seat order byid
id % 2 = 1:说明是奇数编号 → 一般换到后面一个座位 (id+1)。
id < (SELECT MAX(id) FROM Seat):保证不是最后一个人,否则不要动。
id % 2 = 0:说明是偶数编号 → 换到前一个座位 (id-1)。
ELSE id:处理最后一个奇数 id 的情况,保持不变。
最后 ORDER BY id,按照交换后的顺序输出结果。
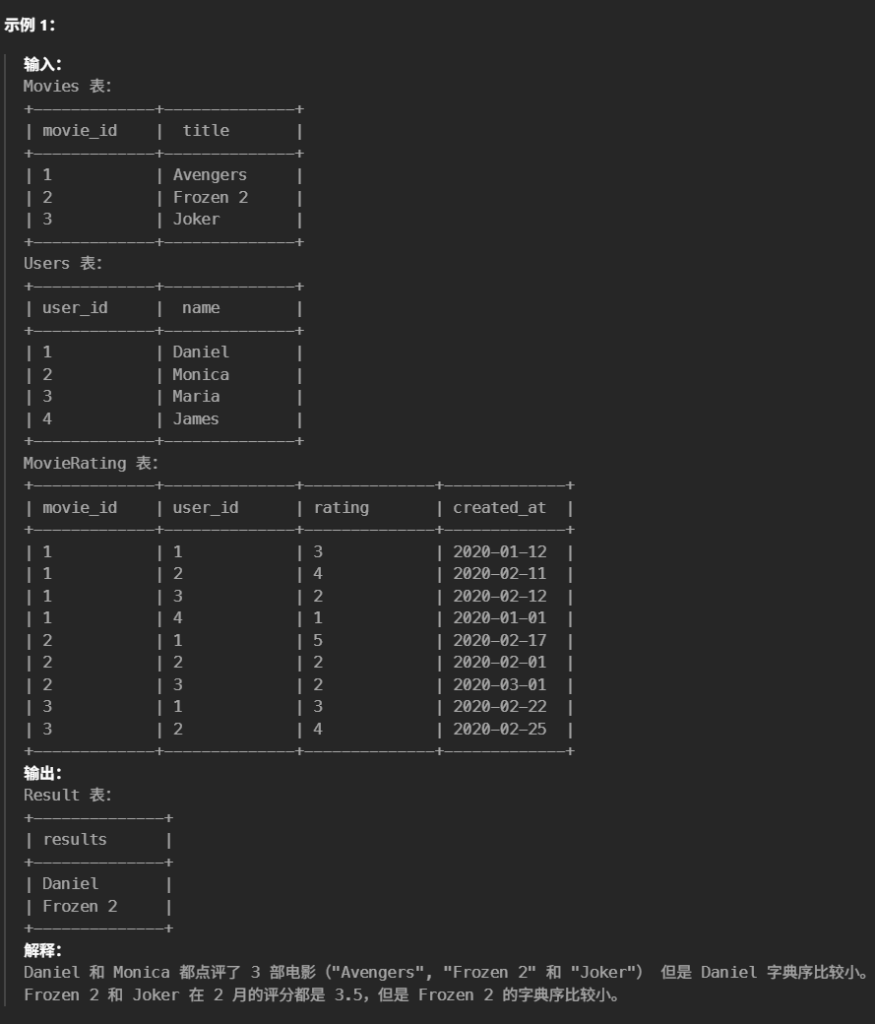
42.电影评分(中等)
请你编写一个解决方案:
查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。
查找在 February 2020平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。
# Write your MySQL query statement below #查找评论电影数量最多的用户名(desc)。如果出现平局,返回字典序较小的用户名。(asc) #查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。 #字典序 ,即按字母在字典中出现顺序对字符串排序,字典序较小则意味着排序靠前。 #1.先查评论电影数量最多的用户名(desc)。 (select u.name as results from Users u left join MovieRating mr on u.user_id = mr.user_id groupby u.user_id orderby count(*)desc,nameasc limit1) unionall #2.再查在 February 2020 平均评分最高 的电影名称 (select title as results from Movies m left join MovieRating mr on m.movie_id = mr.movie_id and year(mr.created_at) = 2020and month(mr.created_at)=2 groupby mr.movie_id orderby Avg(mr.rating)desc,title asc limit1)
43.餐馆营业额变化增长(中等)
窗口函数
语法:
1 2 3
[你要的操作] OVER ( PARTITIONBY <用于分组的列名> ORDERBY <按序叠加的列名> ROWS|RANGE <窗口滑动的数据范围> )
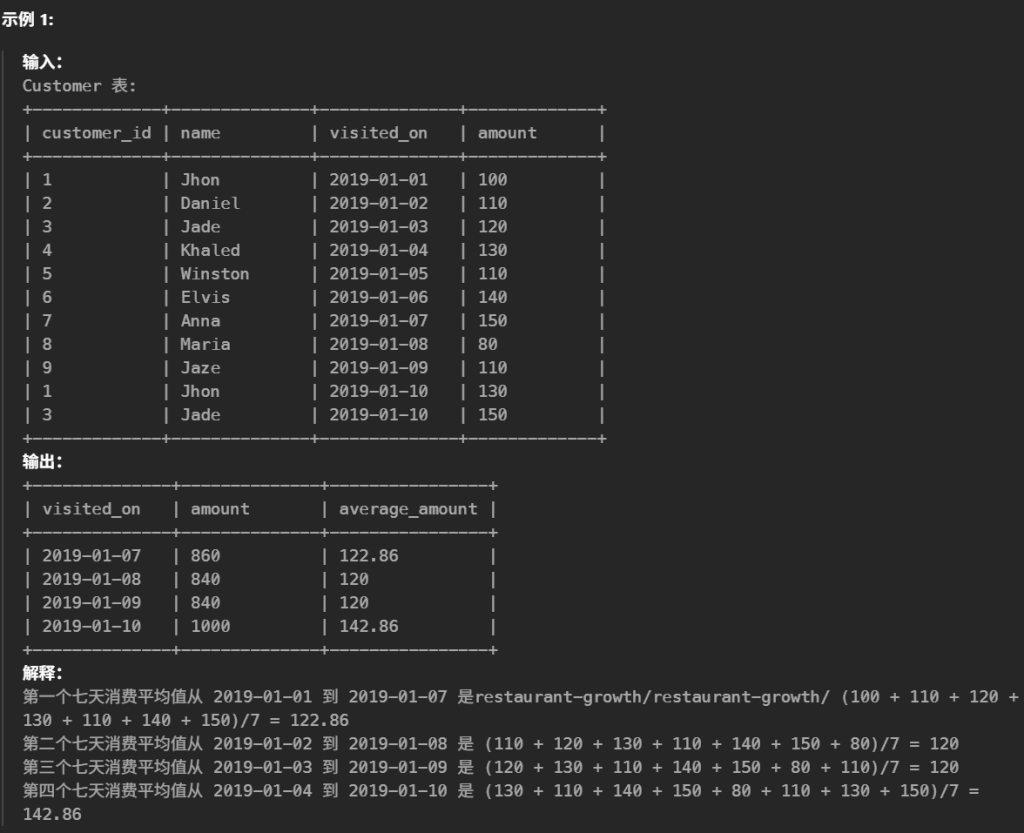
SELECT a.visited_on, sum( b.amount ) AS amount, round(sum( b.amount ) / 7, 2 ) AS average_amount FROM ( SELECT DISTINCT visited_on FROM customer ) a JOIN customer b ON datediff( a.visited_on, b.visited_on ) BETWEEN 0 AND 6 WHERE a.visited_on >= (SELECT min( visited_on ) FROM customer ) + 6 GROUP BY a.visited_on ORDER BY a.visited_on
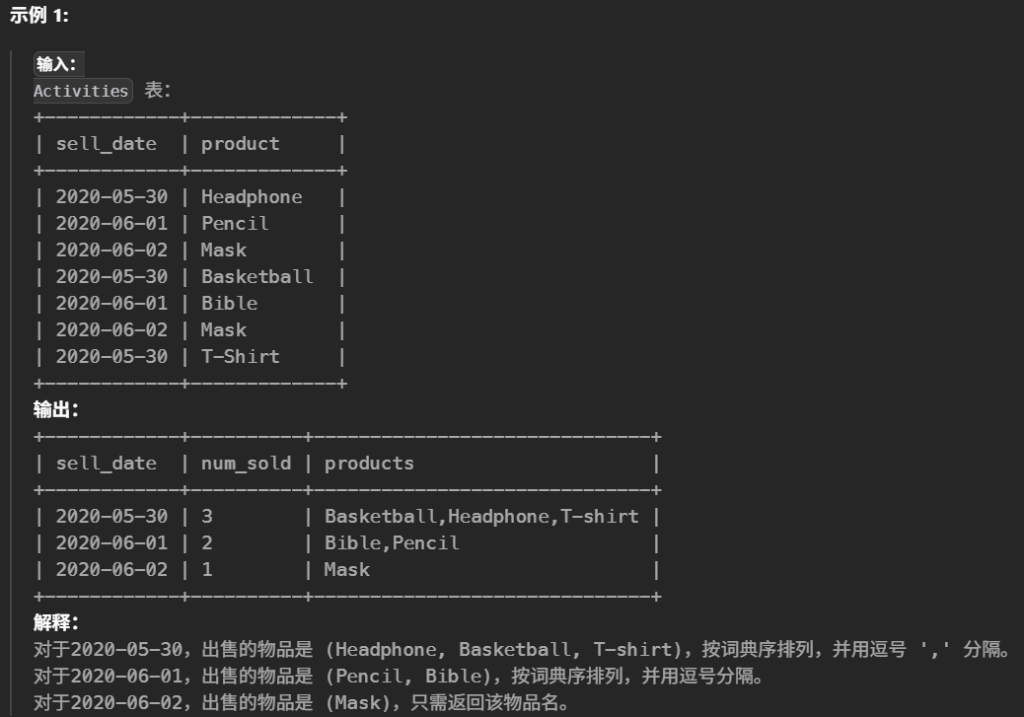
#编写解决方案找出每个日期、销售的不同产品的数量及其名称。 #每个日期的销售产品名称应按词典序排列。 #返回按 sell_date 排序的结果表。 SELECT sell_date, COUNT(DISTINCT(product)) AS num_sold, GROUP_CONCAT(DISTINCT product ORDERBY product SEPARATOR ',') AS products FROM Activities GROUPBY sell_date ORDERBY sell_date ASC
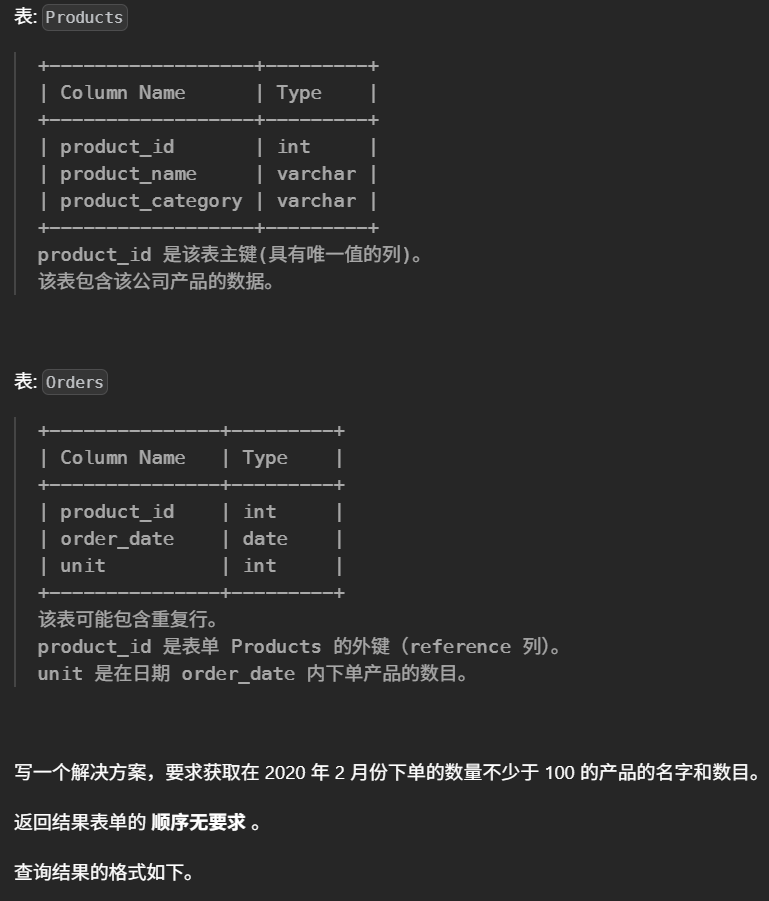
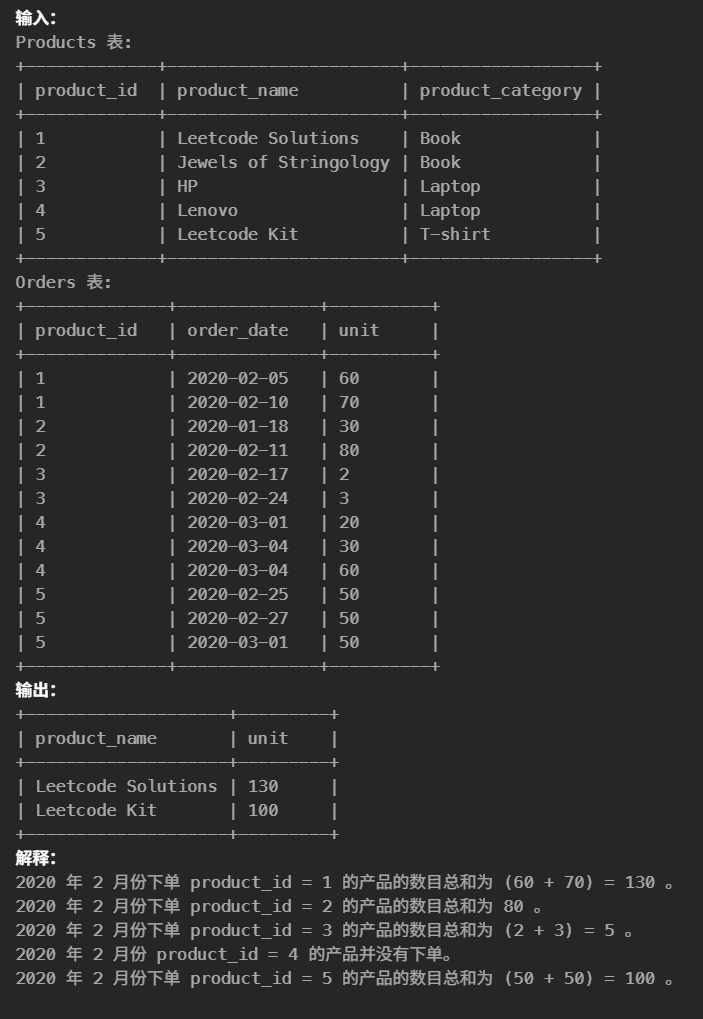
45.列出指定时间段内所有的下单产品(简单)
1 2 3 4 5 6 7
#要求获取在 2020 年 2 月份下单的数量不少于 100 的产品的名字和数目。 select p.product_name,sum(o.unit)as unit from Products p leftjoin Orders o on p.product_id = o.product_id where o.order_date like'2020-02%' groupby p.product_id having unit>=100
1 2 3 4 5 6 7 8 9 10 11
select p.product_name,o.unit from products AS p JOIN( select product_id,sum(unit) AS unit from orders whereyear(order_date) = 2020 andmonth(order_date) = 2 groupby product_id havingsum(unit) >=100 ) AS o ON p.product_id = o.product_id;
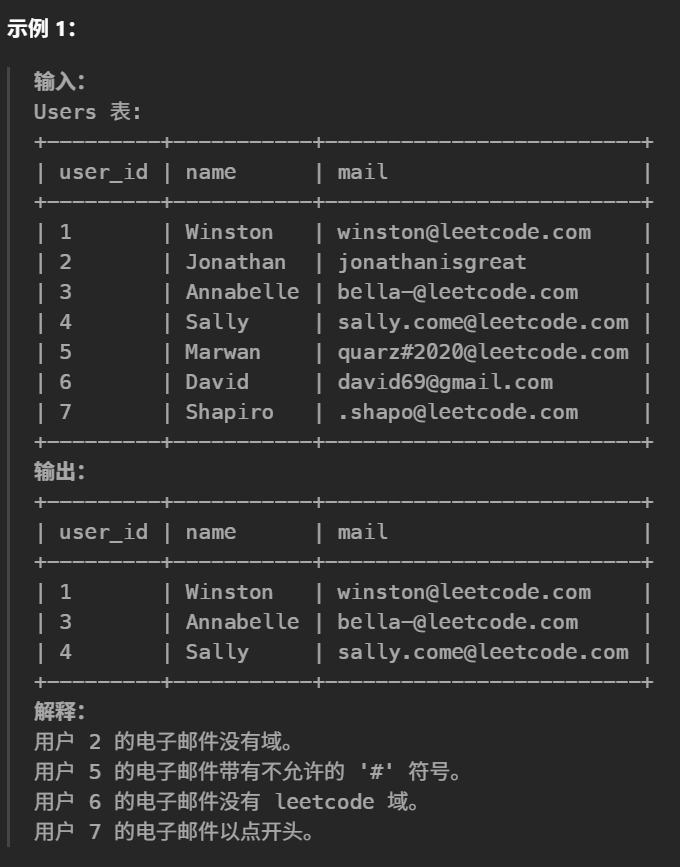
46.查找拥有有效邮箱的用户(简单)
1 2 3 4 5
#编写一个解决方案,以查找具有有效电子邮件的用户。 select user_id,name,mail from Users whereregexp_like(mail,'^[a-zA-Z][a-zA-Z0-9._-]*@leetcode\\.com$','c') select * from users where mail collate utf8_bin REGEXP '^[a-zA-Z][a-zA-Z0-9\_\.\-]*@leetcode\\.com$'
union all不去重合并两张表,group by分组+order by排序+limit限制+子查询外count(*)行数
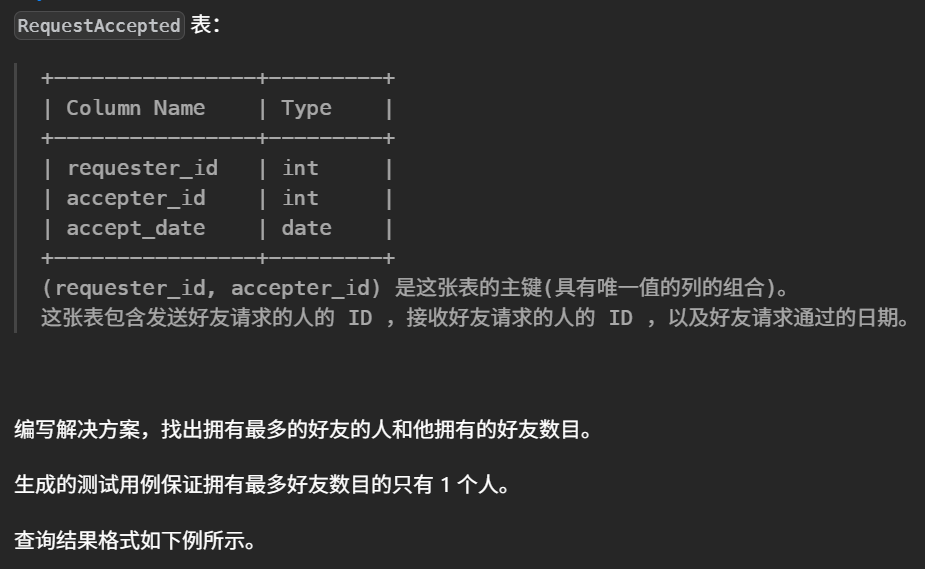
1 2 3 4 5 6 7 8 9 10 11 12 13
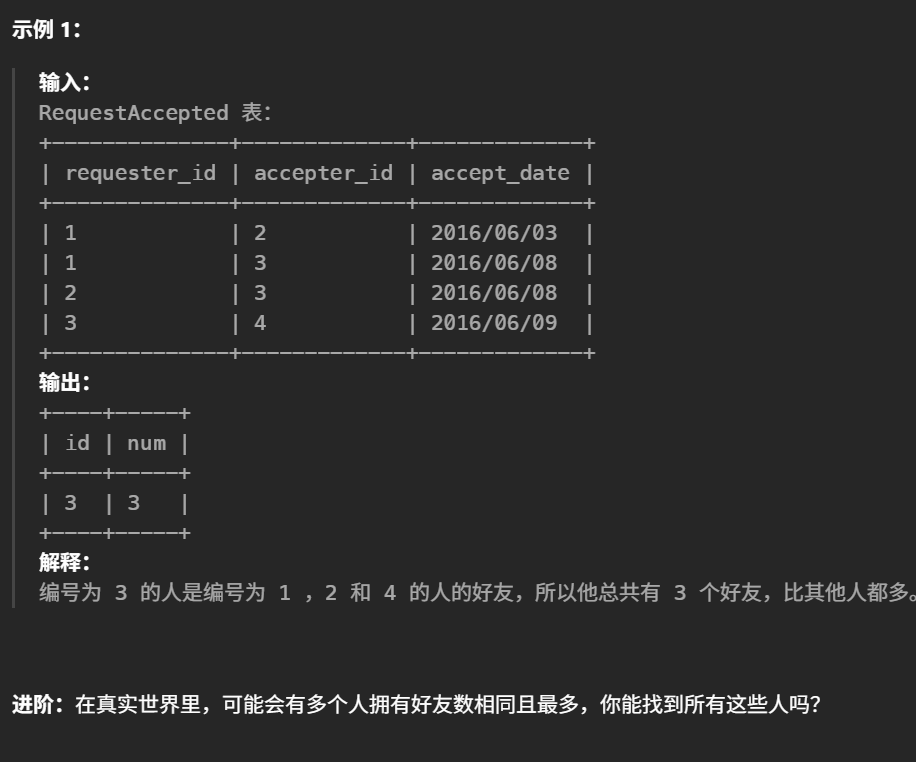
#编写解决方案,找出拥有最多的好友的人和他拥有的好友数目。 select a.id as id, count(*) as num #统计统计每个id在request_id 和accepter_id中出现的次数和。 from ( select requester_id id from RequestAccepted unionall select accepter_id ids from RequestAccepted ) as a groupby id orderby num desc limit1
子查询内先求好友数,然后union,最后再sum求和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
select ids as id,sum(nums) as num from ( select requester_id as ids, count(*) as nums from RequestAccepted groupby ids unionall select accepter_id as ids, count(*) as nums from RequestAccepted groupby ids ) as a groupby id orderby num desc limit1
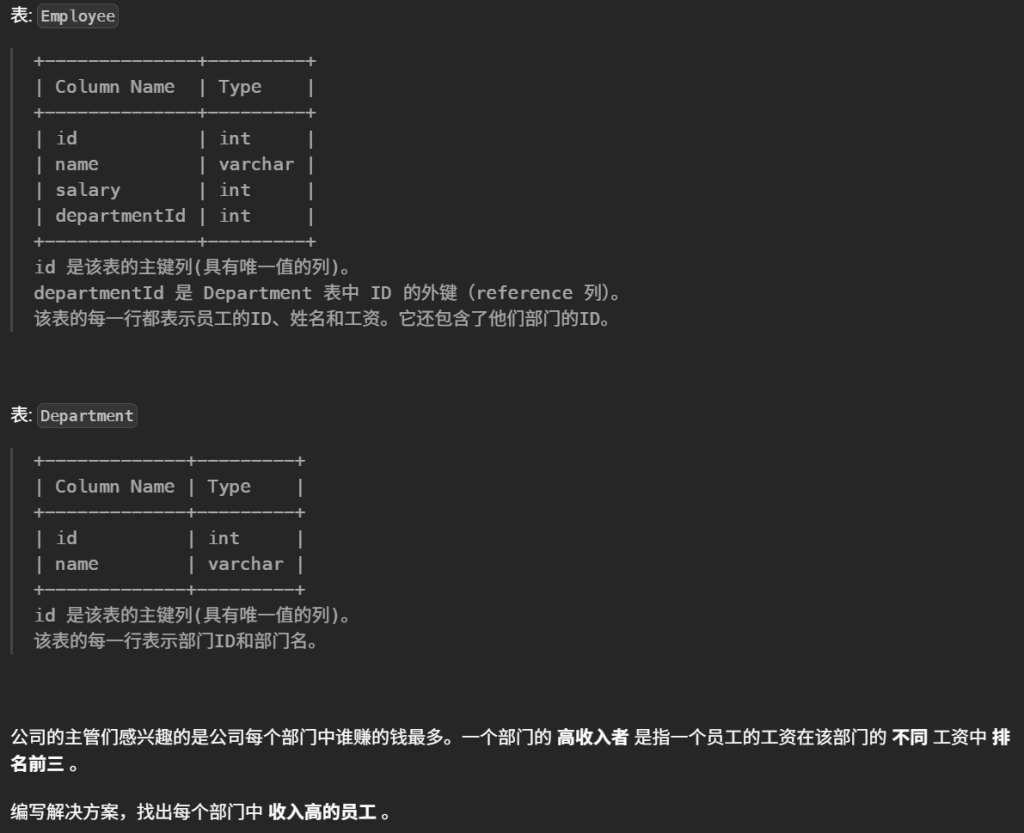
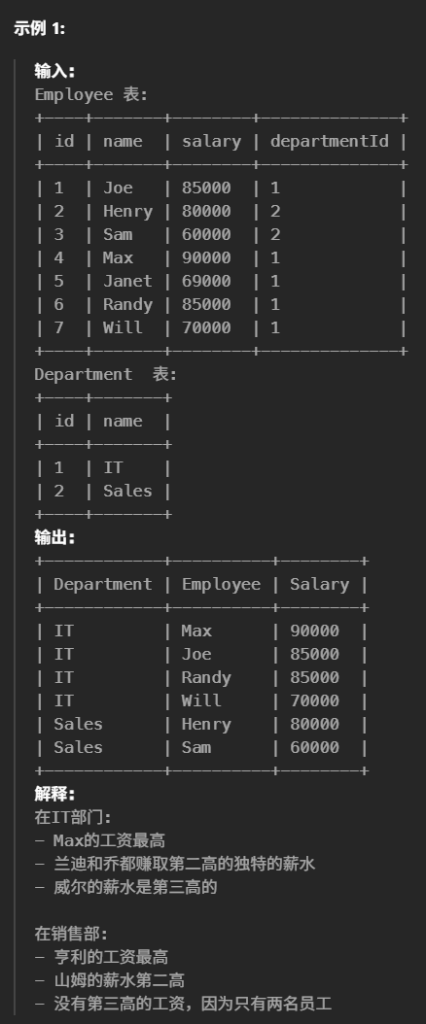
#编写解决方案,找出每个部门中 收入高的员工 。 select d.name as Department,e1.name as Employee,e1.salary as Salary from Employee e1 left join Department d on e1.departmentId = d.id where ( #查询工资中 排名前三 select count(distinct e2.salary) from Employee e2 where e2.salary>e1.salary and e1.departmentId = e2.departmentId )<3
窗口函数
1 2 3 4 5 6 7 8 9 10 11
/** 解题思路:先对Employee表进行部门分组工资排名,再关联Department表查询部门名称,再使用WHERE筛选出排名小于等于3的数据(也就是每个部门排名前3的工资)。 **/ SELECT B.Name AS Department, A.Name AS Employee, A.Salary FROM (SELECT DENSE_RANK() OVER (partitionby DepartmentId orderby Salary desc) AS ranking,DepartmentId,Name,Salary FROM Employee) AS A JOIN Department AS B ON A.DepartmentId=B.id WHERE A.ranking<=3