JUC并发编程中篇
中篇
5.共享模型之内存
5.1 Java 内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、 CPU 指令优化等。
JMM 是一套抽象规范,解决的是:多线程环境下变量读写一致性的问题。
它屏蔽了:
- 各种处理器(CPU)架构差异
- 各种缓存策略带来的“看见的不一定是最新值”
- 指令乱序优化导致的“不按代码执行顺序”
JMM的意义
- 计算机硬件底层的内存结构过于复杂,JMM的意义在于避免程序员直接管理计算机底层内存,用一些关键字synchronized、volatile等可以方便的管理内存。
JMM 体现在以下几个方面
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 作用:
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 规定了线程和内存之间的一些关系
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成
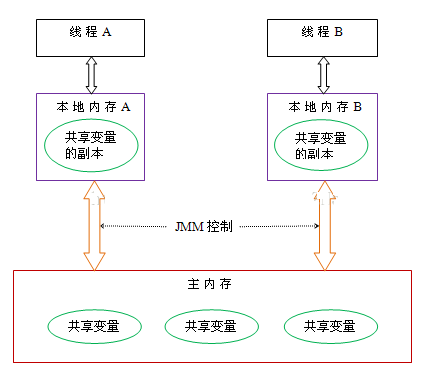
| 区域 | 描述 |
|---|---|
| 主内存 | 所有线程共享的变量存储区(真实RAM) |
| 工作内存 | 每个线程自己拷贝的一份变量副本 |
| 内存交互规则 | 必须通过主内存同步线程之间的变量变化 |
主内存和工作内存:
- 主内存:计算机的内存,也就是经常提到的 8G 内存,16G 内存,存储所有共享变量的值
- 工作内存:存储该线程使用到的共享变量在主内存的的值的副本拷贝
JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
内存交互的 8 个原子操作
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作,每个操作都是原子的
非原子协定:没有被 volatile 修饰的 long、double 外,默认按照两次 32 位的操作
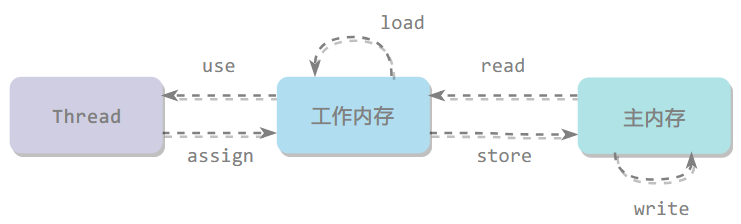
- lock:作用于主内存,将一个变量标识为被一个线程独占状态(对应 monitorenter)
- unclock:作用于主内存,将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定(对应 monitorexit)
- read:作用于主内存,把一个变量的值从主内存传输到工作内存中
- load:作用于工作内存,在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:作用于工作内存,把工作内存中一个变量的值传递给执行引擎,每当遇到一个使用到变量的操作时都要使用该指令
- assign:作用于工作内存,把从执行引擎接收到的一个值赋给工作内存的变量
- store:作用于工作内存,把工作内存的一个变量的值传送到主内存中
- write:作用于主内存,在 store 之后执行,把 store 得到的值放入主内存的变量中
| 操作 | 描述 | 作用域 |
|---|---|---|
| lock | 变量标记为独占 | 主内存 |
| unlock | 解除变量的独占 | 主内存 |
| read | 从主内存读取 | 主内存 → 线程 |
| load | 将 read 的值存入工作内存 | 主内存 → 工作内存 |
| use | 执行引擎使用变量 | 工作内存 → CPU |
| assign | 执行引擎赋值给变量 | CPU → 工作内存 |
| store | 将变量存回主内存 | 工作内存 → 主内存 |
| write | write 将 store 的值写入主内存 | 主内存 |
可见性
可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
存在不可见问题的根本原因是由于缓存的存在,线程持有的是共享变量的副本,无法感知其他线程对于共享变量的更改,导致读取的值不是最新的。但是 final 修饰的变量是不可变的,就算有缓存,也不会存在不可见的问题
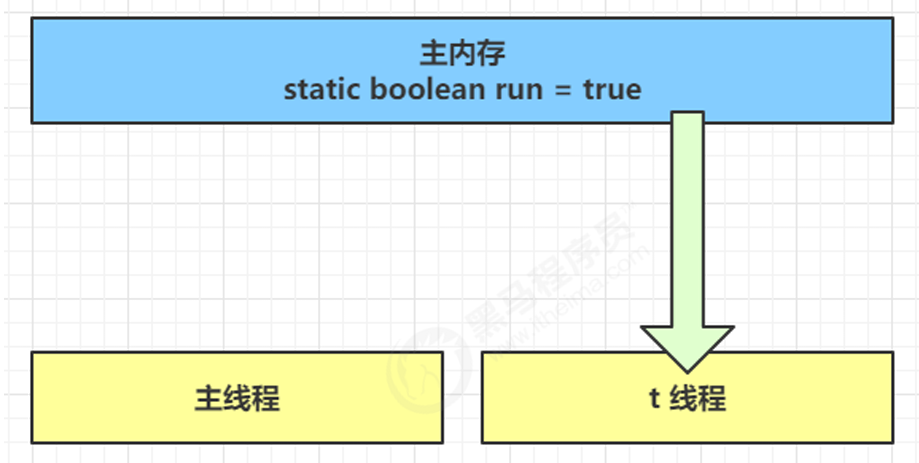
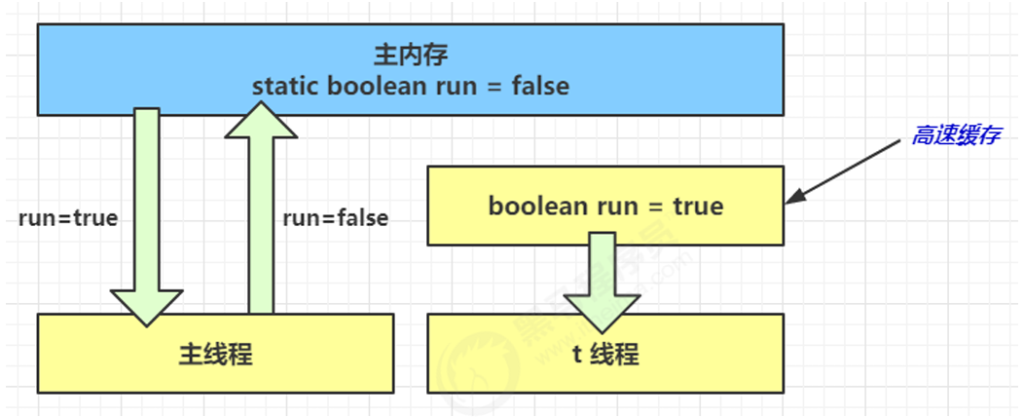
退不出的循环:
main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
1 | static boolean run = true; //添加volatile |
原因:工作内存中的 run 副本未同步主内存更新。
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
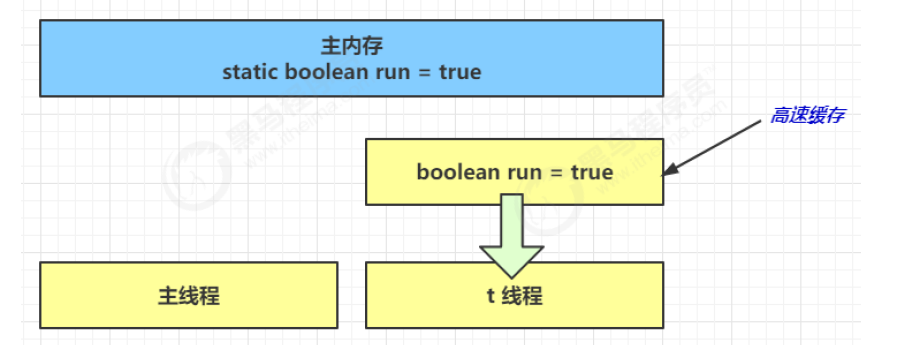
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
解决方法
volatile:强制每次都从主内存读取、写回synchronized:退出锁会刷新主内存
可以在共享的变量上加修饰符volatile(易变关键字),代表这个变量是容易变化的。
它可以用来修饰成员变量和静态成员变量,加了volatile之后线程不能从自己工作缓存中读取变量的值,必须去到主内存中获取变量的最新值。
线程操作volatile变量都是直接操作主存。
1 | @Slf4j(topic="c.Test32") |
加synchronized之后同样可以改变变量的可见性。

可见性vs原子性
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可 见, 不能保证原子性,仅用在一个写线程,多个读线程的情况: 上例从字节码理解是这样的:
1 | getstatic run // 线程 t 获取 run true |
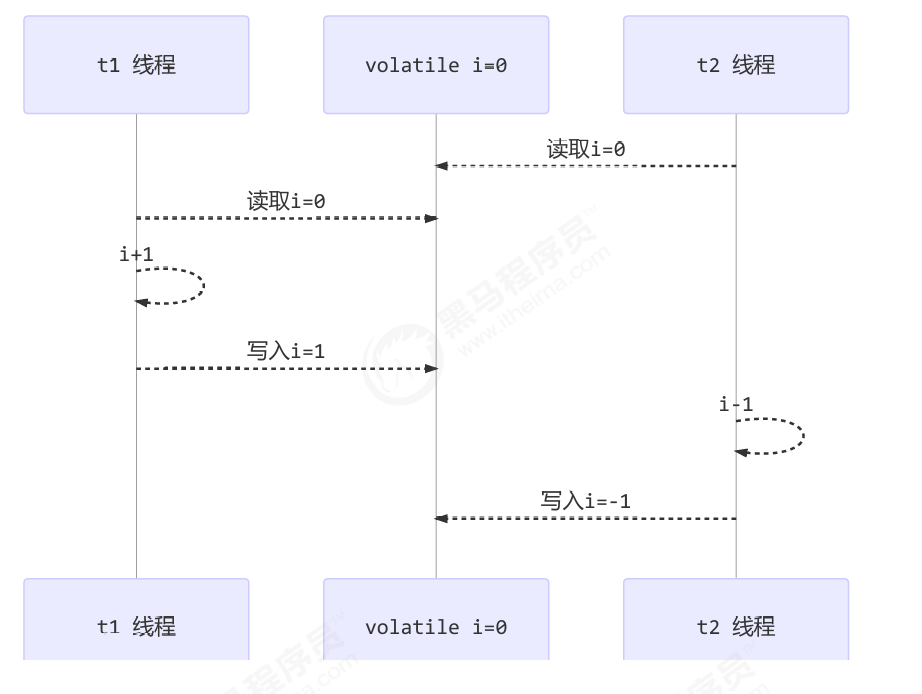
比较一下之前我们将线程安全时举的例子:两个线程一个 i++ 一个 i-- ,只能保证看到最新值,不能解决指令交错
1 | // 假设i的初始值为0 |
注意
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 是属于重量级操作,性能相对更低 。
JMM关于synchronized的两条规定:
1)线程解锁前,必须把共享变量的最新值刷新到主内存中
2)线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新获取最新的值
(注意:加锁与解锁需要是同一把锁)
通过以上两点,可以看到synchronized能够实现可见性。同时,由于synchronized具有同步锁,所以它也具有原子性
如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到 对 run 变量的修改了,想一想为什么?(println方法中有synchronized代码块保证了可见性)
答:
1 | while (run) { |
println 方法内部用了 synchronized,强制了主内存与线程内缓存的同步 → 间接解决了可见性。
synchronized关键字不能阻止指令重排,但在一定程度上能保证有序性(如果共享变量没有逃逸出同步代码块的话)。因为在单线程的情况下指令重排不影响结果,相当于保障了有序性。
volatile 与 synchronized 的可见性对比
| 特性 | volatile |
synchronized |
|---|---|---|
| 可见性 | ✅ 强制主内存交互 | ✅ 解锁前刷新主内存 |
| 原子性 | ❌ | ✅ 加锁保证互斥 |
| 性能 | 高 | 低(重量级锁) |
| 语义 | 轻量 | 阻塞/解阻塞 |
原子性
原子性:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被分割,需要具体完成,要么同时成功,要么同时失败,保证指令不会受到线程上下文切换的影响
定义原子操作的使用规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,必须顺序执行,但是不要求连续
- 不允许一个线程丢弃 assign 操作,必须同步回主存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(assign 或者 load)的变量,即对一个变量实施 use 和 store 操作之前,必须先自行 assign 和 load 操作
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁,lock 和 unlock 必须成对出现
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新从主存加载
- 如果一个变量事先没有被 lock 操作锁定,则不允许执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)

设计模式 volatile改进两阶段终止
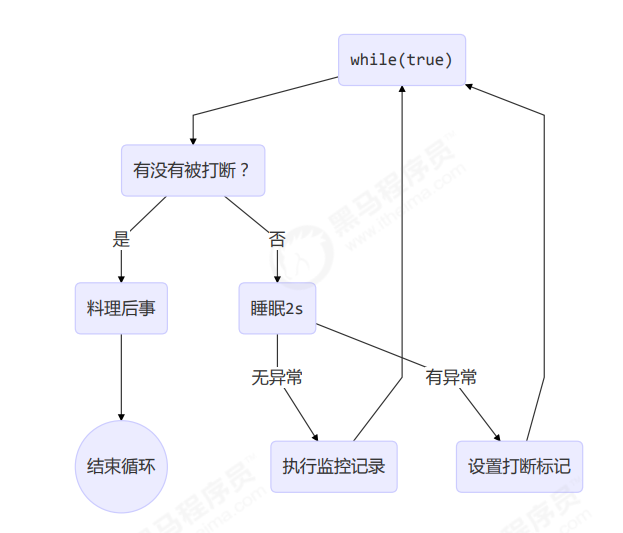
Two Phase Termination
在一个线程 T1 中如何“优雅”终止线程 T2?这里的【优雅】指的是给 T2 一个料理后事的机会。
1.错误思路
| 方法 | 问题 |
|---|---|
stop() |
线程会被强制杀死,无法释放锁或清理资源 → ⚠️ 早就被弃用 |
System.exit() |
直接退出整个程序,连 main 线程都结束了,不可控 |
2.两阶段终止模式
给线程一个“料理后事”的机会,而不是粗暴结束它的生命。
比如:
- 清理资源(关闭连接、文件)
- 写入最终状态
- 打印最后日志
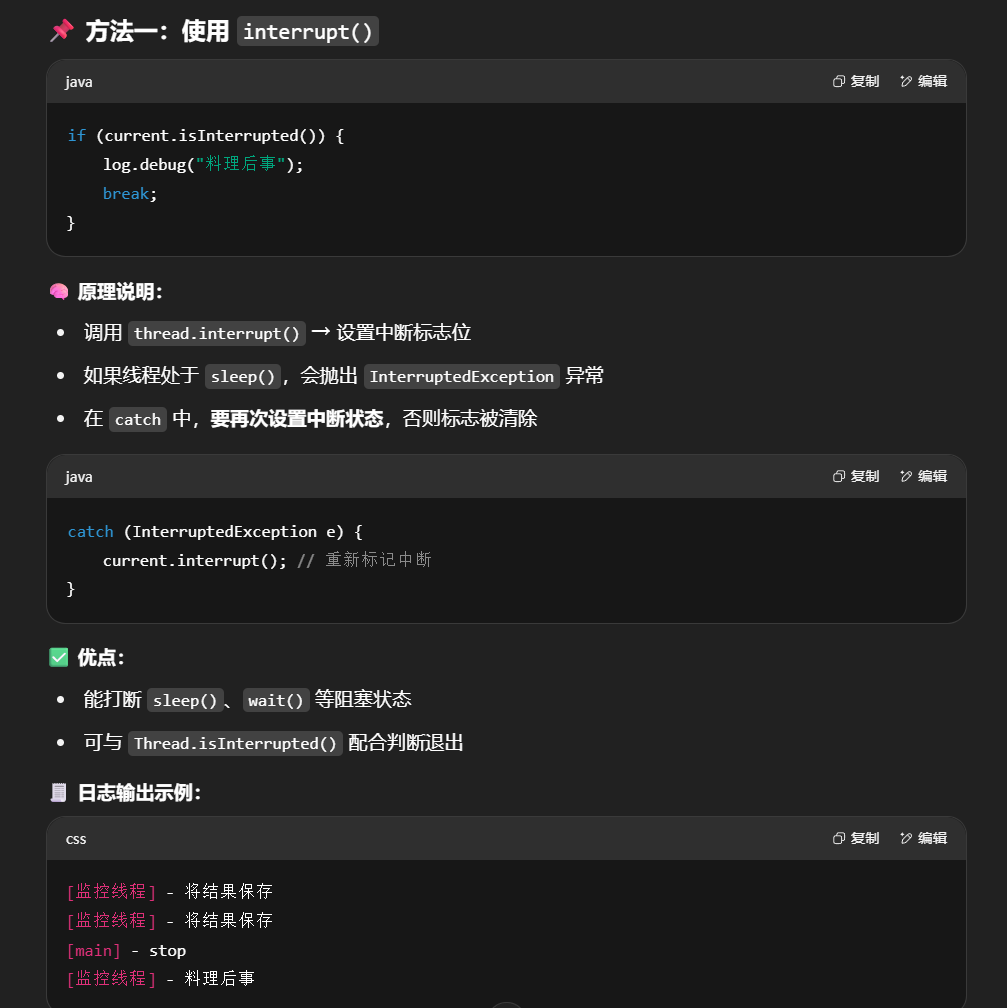
利用 isInterrupted
interrupt 可以打断正在执行的线程,无论这个线程是在 sleep,wait,还是正常运行
1 | class TPTInterrupt { |
调用
1 | TPTInterrupt t = new TPTInterrupt(); |
结果
1 | 11:49:42.915 c.TwoPhaseTermination [监控线程] - 将结果保存 |
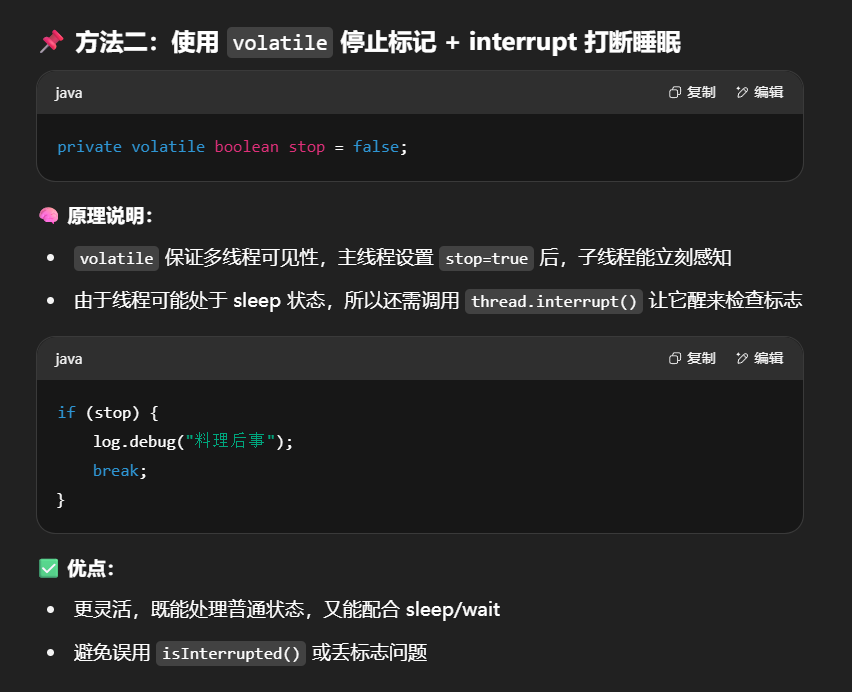
利用volatile修饰的停止标记(使用 volatile 停止标记 + interrupt 打断睡眠)
1 | // 停止标记用 volatile 是为了保证该变量在多个线程之间的可见性 |
调用
1 | TPTVolatile t = new TPTVolatile(); |
结果
1 | 11:54:52.003 c.TPTVolatile [监控线程] - 将结果保存 |
两种实现方式对比
| 对比项 | interrupt() 实现 |
volatile + interrupt 实现 |
|---|---|---|
| 是否能打断 sleep | ✅ 是 | ✅ 是(需手动调用) |
| 退出标志维护 | 用 isInterrupted() 判断 |
用 volatile boolean 标志 |
| 标志是否易失 | ✅ 中断状态可能在 sleep 后被清除 | ❌ volatile 标志稳定可控 |
| 是否能中断阻塞 | ✅ 是 | ✅ 是 |
| 适用范围 | 线程中断退出场景 | 通用场景、可读性高 |
设计模式之犹豫
1.什么是 Balking(犹豫)模式?
定义:
当一个操作正在运行,或者已经完成时,再有线程试图发起相同操作会被“拒绝”或“犹豫”——即不再继续执行,直接返回。
也就是说:
- 做过了,就别做第二遍
- 当前状态不对,就直接返回
应用场景举例
- 单例模式初始化(只初始化一次)
- 定时器或后台线程只启动一次
- 页面多次点击“启动按钮”时,确保只启动一个任务
示例分析:启动监控线程(设置一个标记变量,来判断是否执行过某个方法)
1 | private volatile boolean starting; |
关键机制:
| 机制 | 说明 |
|---|---|
starting |
表示是否已经启动 |
volatile |
保证线程间的可见性 |
synchronized |
保证原子性判断与赋值操作 |
return |
如果状态已是“启动”,则拒绝重复执行 |

常见用途:线程安全单例(懒汉式)
1 | public static synchronized Singleton getInstance() { |
同样地:
- 如果实例已经创建,就不再重复创建
- 也是一种 Balking 行为:状态不符就直接返回
对比:保护性暂停模式 vs 犹豫模式
| 模式 | 行为 | 典型场景 |
|---|---|---|
| Balking(犹豫) | 状态不符,立即返回 | 防止重复执行,任务只做一次 |
| 保护性暂停 | 条件不符,等待 | 等待另一个线程的结果或信号 |
📌 总结一句话:
Balking 是“不做”,保护性暂停是“等一等”。
有序性
前言
- 程序有序性原则:一个线程内的操作看起来是顺序执行的
- 多线程视角下的无序:不同线程之间看起来是乱序执行的
👉 这种乱序的根本原因就是「指令重排(Instruction Reordering)」

处理器在进行重排序时,必须要考虑指令之间的数据依赖性
- 单线程环境也存在指令重排,由于存在依赖性,最终执行结果和代码顺序的结果一致
- 多线程环境中线程交替执行,由于编译器优化重排,会获取其他线程处在不同阶段的指令同时执行
补充知识:
- 指令周期是取出一条指令并执行这条指令的时间,一般由若干个机器周期组成
- 机器周期也称为 CPU 周期,一条指令的执行过程划分为若干个阶段(如取指、译码、执行等),每一阶段完成一个基本操作,完成一个基本操作所需要的时间称为机器周期
- 振荡周期指周期性信号作周期性重复变化的时间间隔
指令重排
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序,思考下面这些代码
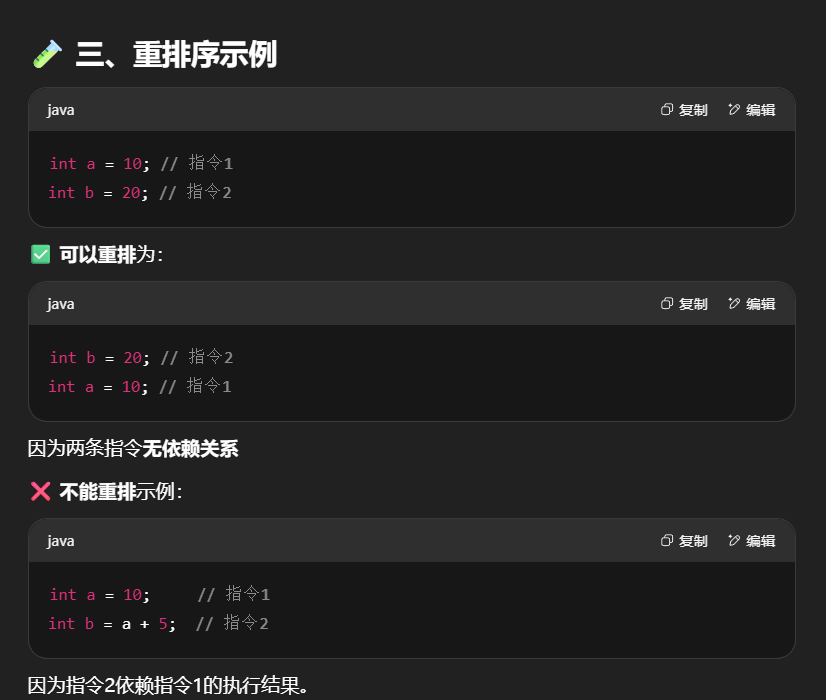
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢?从 CPU 执行指令的原理来理解一下吧
指令重排原理
为什么 CPU 要重排?
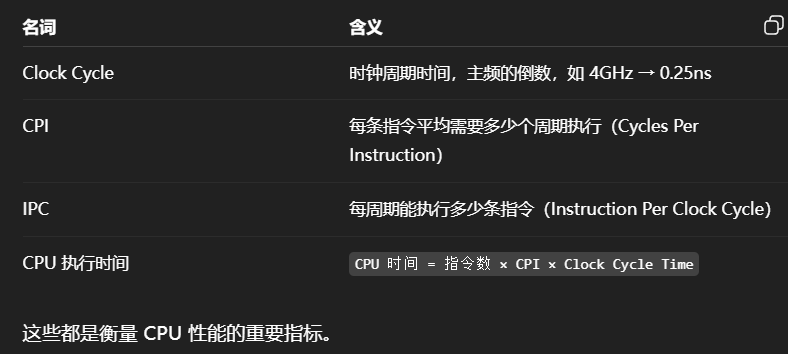
为了提高性能,现代 CPU 实现了以下机制:
- 指令流水线(Pipeline)
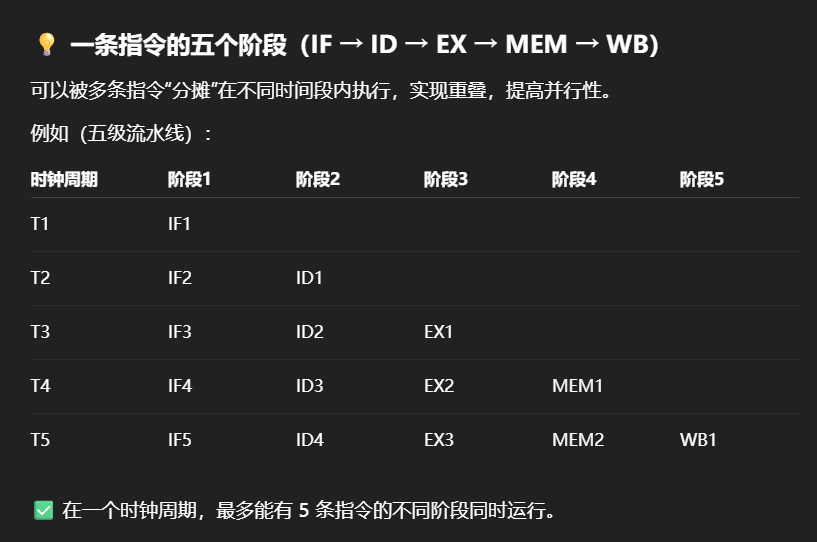
五级流水线:取指令 → 指令译码 → 执行 → 访存 → 写回
每条指令被分成多个阶段,这些阶段可以被多个指令并行执行。
这样做可以提高吞吐率(Throughput)。
- 超标量(SuperScalar)
现代 CPU 拥有多个执行单元(如整数、浮点、加载单元)
可以在一个时钟周期内执行多条指令,即 IPC > 1(Instruction per Clock)
JMM 如何应对重排?
Java 内存模型(JMM)允许重排序,但通过 Happens-Before 规则和 volatile/synchronized 等机制来屏蔽“坏的重排”。
| 工具 | 能否禁止重排 | 是否保证可见性 | 是否保证原子性 |
|---|---|---|---|
volatile |
✅ 禁止特定重排 | ✅ | ❌ |
synchronized |
✅ 完全禁止 | ✅ | ✅ |
指令重排的问题
1.诡异的结果
1 | int num = 0; |
你可能会觉得结果只有:
1:因为ready == false4:因为ready == true且num = 2
但事实上,还可能出现一个诡异的结果:
r1 == 0
2.为什么会出现 r1 == 0?
这是 指令重排(Instruction Reordering) 的锅:
actor2 看似顺序是:
1 | num = 2; |
但实际上,JIT 编译器或 CPU 为了性能可能重排序为:
1 | ready = true; |
3.线程交叉执行导致问题
设想线程切换如下:
| 时间 | 执行线程 | 执行内容 |
|---|---|---|
| T1 | actor2 | ready = true ✅ 重排了 |
| T2 | actor1 | if (ready) 进入 if 分支 |
| T3 | actor1 | 读取 num = 0,返回 0 |
| T4 | actor2 | num = 2 补上了 |
此时:
ready = truenum还没来得及变成 2- 所以
num + num = 0 + 0 = 0
这个结果非常反直觉!😵
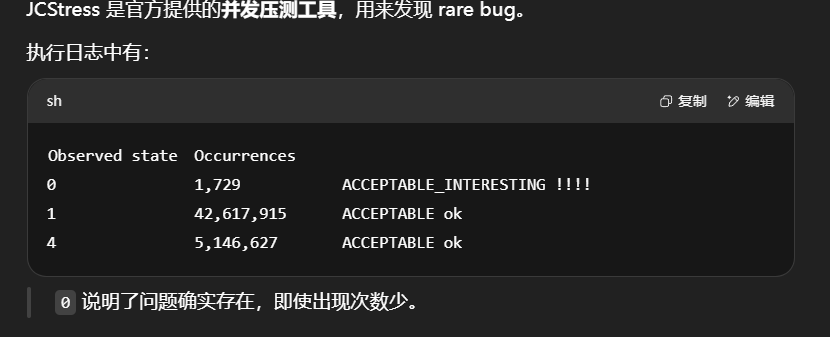
4.用 JCStress 工具验证这种微小并发问题
5.如何解决?
方法一:使用 volatile
修改代码为:
1 | volatile boolean ready = false; |
效果:
volatile具有 可见性 和 禁止重排序 的语义- 它会在
ready = true写操作前,确保之前所有写操作(包括num = 2)都已完成
执行压测后,0 就不再出现了,说明问题彻底解决。

总结:多线程环境下,不加 volatile 或同步机制,即使代码看起来顺序执行,也可能由于“重排序”导致结果诡异!
5.2原理之 volatile
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
| 类型 | 说明 |
|---|---|
| 写屏障 sfence | 保证之前的写操作会刷新到主内存 |
| 读屏障 lfence | 保证之后的读操作从主内存加载最新数据 |
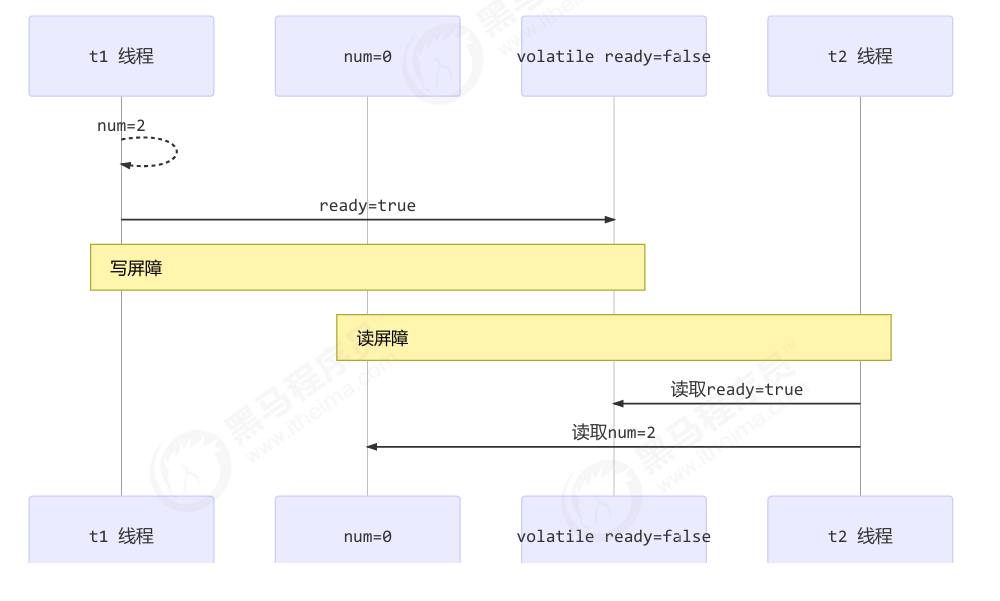
如何保证可见性
- 写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
1 | public void actor2(I_Result r) { |
- 而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
1 | public void actor1(I_Result r) { |
通过 volatile ready,确保 actor2 的 num=2 先于 ready=true 被主内存可见;actor1 会在读 ready 之后拿到 num=2。
如何保证有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
1 | public void actor2(I_Result r) { |
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
1 | public void actor1(I_Result r) { |
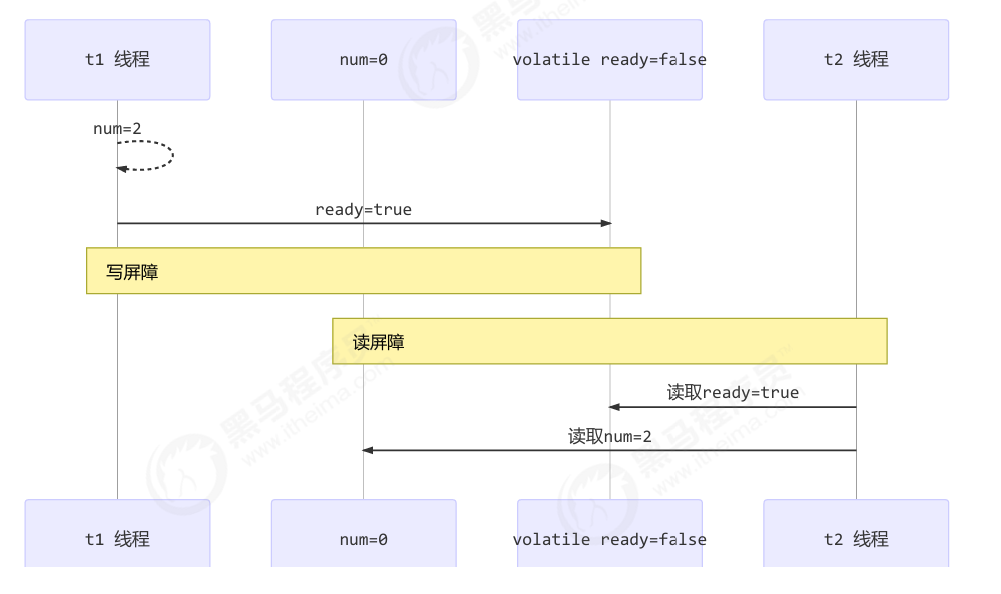
还是那句话,不能解决指令交错:
- 写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序

double-checked locking 问题
以著名的 double-checked locking 单例模式为例
1 | public final class Singleton { |
以上的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
- 有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外(不安全)
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
1 | 0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; |
其中
- 17 表示创建对象,将对象引用入栈 // new Singleton
- 20 表示复制一份对象引用 // 引用地址
- 21 表示利用一个对象引用,调用构造方法
- 24 表示利用一个对象引用,赋值给 static INSTANCE
也许 jvm 会优化为:先执行 24,再执行 21。
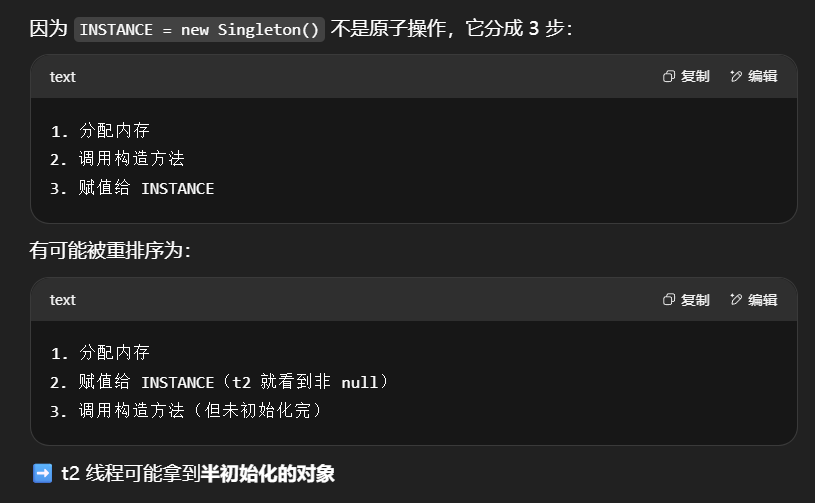
如果两个线程 t1,t2 按如下时间序列执行:
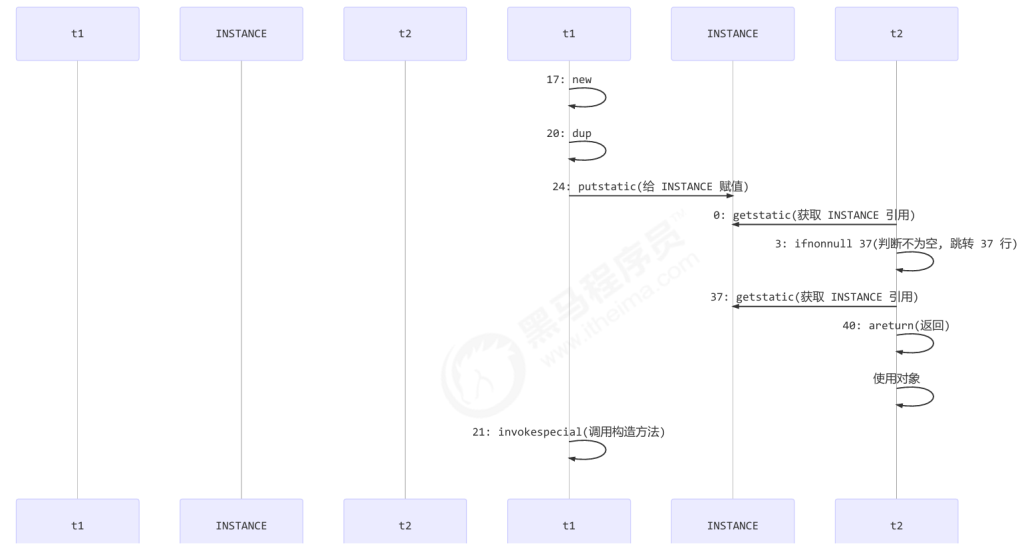
关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取 INSTANCE 变量的值
这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初 始化完毕的单例(没等t1完成构造方法的调用,t2发现已有对象直接返回对象使用,发生错误。)
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
double-checked locking 解决(加 volatile)
1 | public final class Singleton { |
字节码上看不出来 volatile 指令的效果
1 | // -------------------------------------> 加入对 INSTANCE 变量的读屏障 |
如上面的注释内容所示,读写 volatile 变量时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面 两点:
- 可见性
- 写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
- 而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据

- 有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
- 更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性
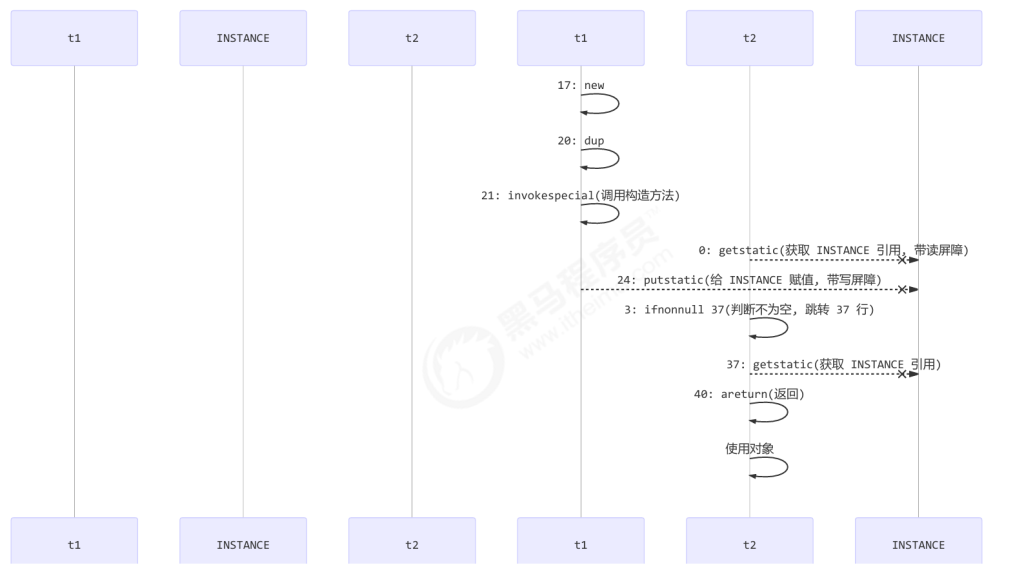
字节码角度理解 volatile 的作用
虽然 volatile 在源码中不可见,但从字节码和底层机器码中可以看出:
- 编译器会插入
lock,mfence,sfence,lfence等指令(平台相关) - 保证写入顺序 + 可见性 + 多核之间一致性
| volatile 特性 | 是否具备 | 说明 |
|---|---|---|
| 可见性 | ✅ | 保证共享变量修改立即对其他线程可见 |
| 有序性 | ✅ | 防止重排序(内存屏障) |
| 原子性 | ❌ | 不具备,需配合锁等机制 |
对以下两句话的理解(是否矛盾?):
不矛盾

| 层面 | 代表术语 | volatile 的作用 |
|---|---|---|
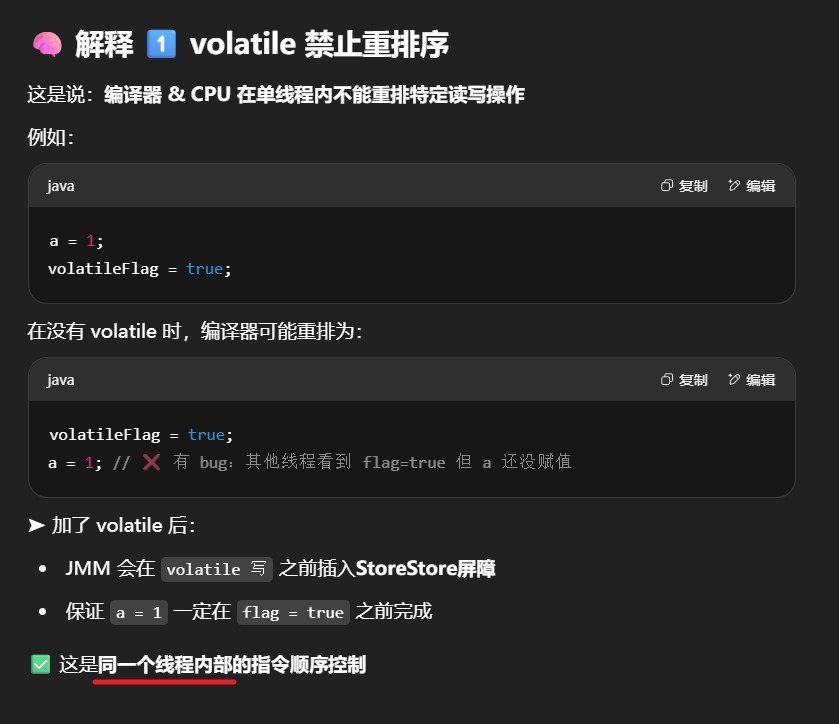
| ✅ 当前线程内部顺序 | 指令重排序(reordering) | 禁止特定重排序 ✔️ |
| ❌ 多线程之间交叉执行 | 并发交叉 / 非同步执行 | 无法阻止 ❌ |
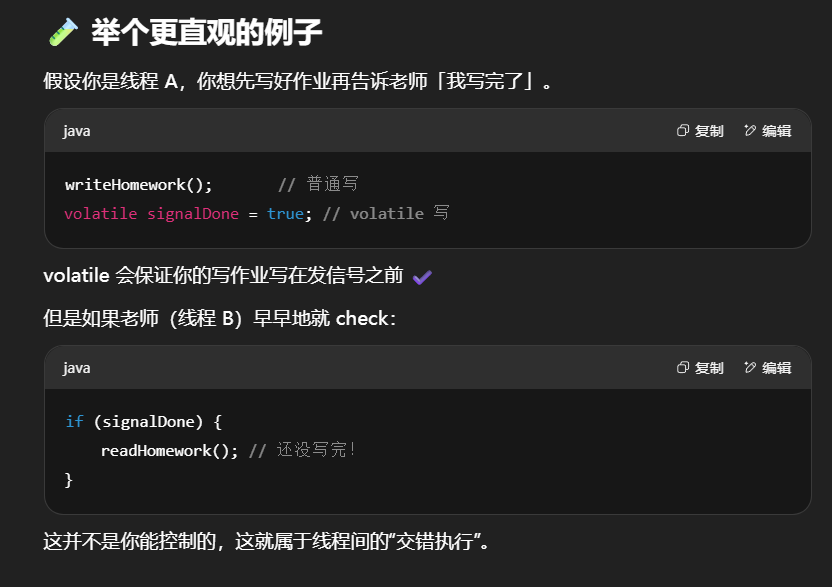
总结一句话
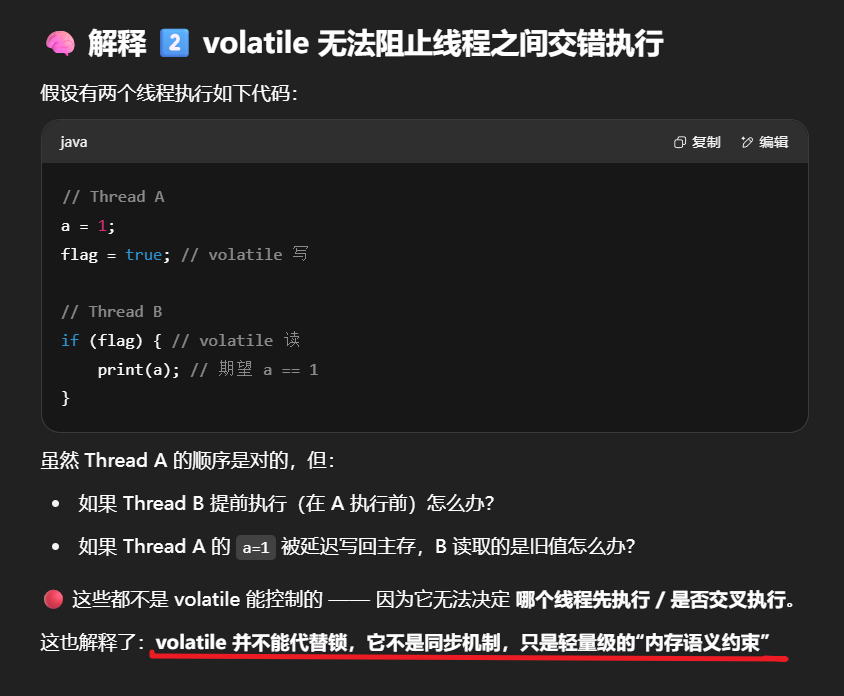
volatile 禁止 自身线程内的指令重排序,保证“我写完作业再发信号”
volatile 无法阻止 线程之间的交错执行,不能保证“别人不抢先读取信号”
两句话不矛盾,分别针对:
- ✅ 内部顺序保障(禁止重排)
- ❌ 外部同步保障(需要锁)
happens-before
happens-before 是 JMM 中用于规定“内存可见性与执行顺序”的逻辑关系。
简单理解:
如果 A happens-before B,那么:
✅ A 的执行结果对 B 是可见的
✅ A 一定发生在 B 之前(逻辑上)
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
- 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见(synchronized关键字的可见性、监视器规则)
① synchronized 可见性
1 | static int x; |
因为:t1 解锁 m → happens-before → t2 加锁 m
👉 所以 x = 10 对 t2 可见
- 线程对 volatile 变量的写,对接下来其它线程对该变量的读可见(volatile关键字的可见性、volatile规则)
② volatile 可见性
1 | volatile static int x; |
因为:对 x 的 volatile 写 → happens-before → 随后的 volatile 读
👉 确保 t2 能看到最新值
- 线程 start 前对变量的写,对该线程开始后对该变量的读可见(程序顺序规则+线程启动规则)
③ start 规则
1 | static int x; |
因为 start() happens-before 线程执行体
👉 子线程可以看到主线程写入的 x
- 线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待 它结束)(线程终止规则)
④ join 规则
1 | static int x; |
因为 t1的所有操作 → happens-before → join 返回
👉 主线程看到 x=10 是有保障的
- 线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过 t2.interrupted 或 t2.isInterrupted)(线程中断机制)
⑤ 中断规则
1 | static int x; |
因为 t2.interrupt() happens-before isInterrupted() == true
👉 能保证 x = 10 对 t2 可见
- 具有传递性,如果
x hb-> y并且y hb-> z那么有x hb-> z,配合 volatile 的防指令重排,有下面的例子
⑥ 传递性示例
1 | volatile static int x; |
因为:
y = 10在x = 20之前执行x = 20是 volatile 写 → happens-before 另一个线程的读- 所以通过 volatile 的传递性,
y=10对另一个线程也可见
变量默认值的可见性?
变量的默认值(如 0, false, null)对所有线程天然可见,不需要显式同步,这是 JVM 的初始化语义保证的。
变量都是指成员变量或静态成员变量
参考: 第17页
那什么是happens-before呢?在JSR-133中,happens-before关系定义如下:
1.如果一个操作happens-before另一个操作,那么意味着第一个操作的结果对第二个操作可见,而且第一个操作的执行顺序将排在第二个操作的前面。
2.两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须按照happens-before关系指定的顺序来执行。如果重排序之后的结果,与按照happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)
happens-before 的 8 条规则(JSR-133 规定)
| 规则编号 | 描述 | 举例代码 |
|---|---|---|
| ① | 程序顺序规则:一个线程中语句按写的顺序执行 | int x=1; int y=x+1; |
| ② | 监视器规则:解锁 happens-before 随后的加锁(同一锁对象) | synchronized(obj) 块之间 |
| ③ | volatile 规则:volatile 写 happens-before 随后的读 | volatile boolean flag |
| ④ | 线程启动规则:start() happens-before 线程内任何操作 | main线程调用 t.start() |
| ⑤ | 线程终止规则:线程内操作 happens-before 其他线程检测它结束 | t.join() 或 !t.isAlive() |
| ⑥ | 线程中断规则:interrupt() happens-before 被检测到中断 | t.interrupt() 后用 isInterrupted() 检测 |
| ⑦ | 对象终结规则:构造完成 happens-before finalize() | Java GC 自动触发 |
| ⑧ | 传递性:A hb→B,B hb→C,则 A hb→C | A 设置值 → B 发信号 → C 读取所有结果 |
5.3习题
习题
balking 模式习题
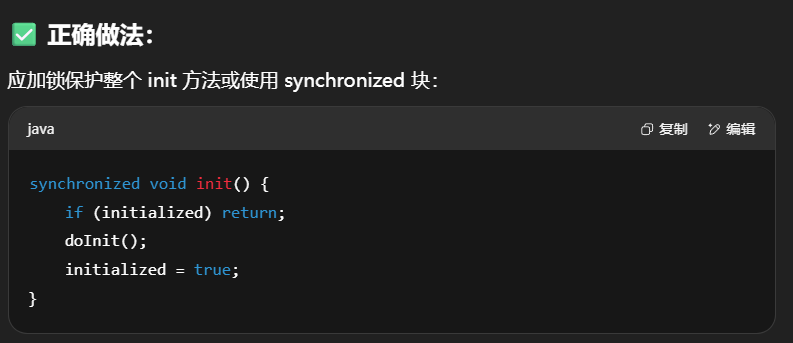
希望 doInit() 方法仅被调用一次,下面的实现是否有问题,为什么?
1 | public class TestVolatile { |
问题分析:
有问题!这是典型的 线程不安全的 lazy 初始化。
假设线程 t1 和 t2 并发执行:
- t1 进入
init()方法,initialized == false - t1 执行
doInit()过程 - 在 t1 还未执行
initialized = true之前,t2 也进入了init(),发现initialized == false - t2 也执行了一次
doInit()❌
线程安全单例习题
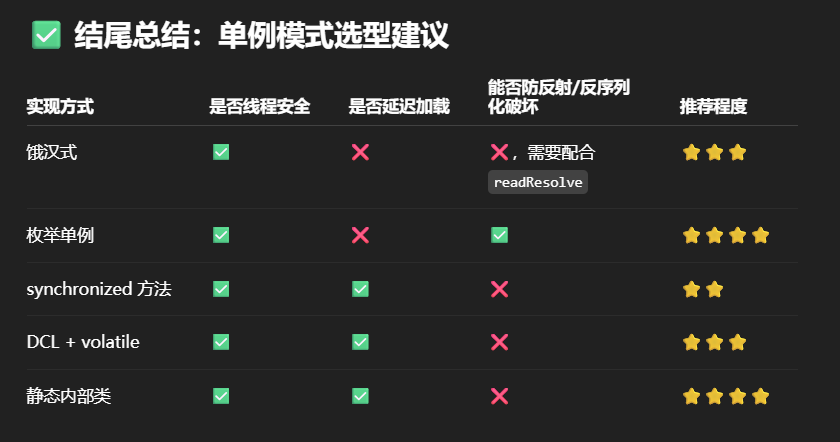
单例模式有很多实现方法,饿汉、懒汉、静态内部类、枚举类,试分析每种实现下获取单例对象(即调用 getInstance)时的线程安全,并思考注释中的问题
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
实现1(饿汉式):
1 | // 问题1:为什么加 final(防止被子类继承从而重写方法改写单例) |
1.单例类加final原因:怕将来有子类,子类不适当覆盖父类方法,破坏单例
2.序列化接口反序列化的时候也会生成新的对象。
采用指定的对象返回,而不会把真正反序列字节码生成的对象当作结果。
3.设为非private的别的类能无限创建对象。不能防止反射创建新的实例。
4.可以保证线程安全,静态成员变量初始化是在类加载阶段完成。
5.这里的理由有很多,比如使用public的好处:在返回结果前,对其做一些自定义的处理
| 问题 | 解答 |
|---|---|
为什么加 final? |
防止被继承,避免子类覆盖方法破坏单例语义 |
| 如何防止反序列化破坏单例? | 实现 readResolve() 返回唯一实例 |
构造器为何设为 private? |
防止外部创建多个实例;但不能防止反射 |
| 是否线程安全? | ✅ 是的,JVM 类加载阶段天然线程安全 |
| 为什么不用 public 实例? | 通过方法封装可加入懒加载、权限控制、异常处理等逻辑 |
实现2(枚举类):
1 | // 问题1:枚举单例是如何限制实例个数的 (枚举类会按照声明的个数在类加载时实例化对象) |
| 问题 | 解答 |
|---|---|
| 如何限制实例数量? | 枚举类在加载时自动创建所有枚举实例,个数固定 |
| 是否线程安全? | ✅ 是的,JVM 保证枚举的线程安全 |
| 能否反射破坏? | ❌ 不可破坏,反射访问枚举构造器会抛异常 |
| 是否能被反序列化破坏? | ❌ 不会,JVM 自动保证枚举反序列化回原始对象 |
| 属于懒汉还是饿汉? | 饿汉式 |
| 如何加入初始化逻辑? | 加构造器即可,如 INSTANCE { Singleton() { ... } } |
实现3(synchronized方法):
1 | public final class Singleton { |
| 优点 | 简单实现线程安全 |
|---|---|
| 缺点 | 每次调用都加锁,性能差 |
实现4:DCL+volatile
1 | public final class Singleton { |
| 问题 | 解答 |
|---|---|
为什么加 volatile? |
防止 new Singleton() 重排序导致提前赋值(半初始化对象) |
| 相比实现3的优势? | 减少加锁次数,性能更好 |
| 为什么第二次还要判空? | 防止两个线程同时通过第一次判断进入锁内,保证单例只创建一次 |
实现5(内部类初始化)静态内部类:
1 | public final class Singleton { |
| 问题 | 解答 |
|---|---|
| 属于懒汉还是饿汉? | ✅ 懒汉式(调用 getInstance() 才加载 LazyHolder 类) |
| 是否线程安全? | ✅ 是的,类加载天然线程安全 |
| 是否推荐? | ✅ 推荐,写法简洁,性能好 |
5.4本章小结
本章重点讲解了 JMM 中的
- 可见性 - 由 JVM 缓存优化引起
- 有序性 - 由 JVM 指令重排序优化引起
- happens-before 规则
- 原理方面
- CPU 指令并行
- volatile
- 模式方面
- 两阶段终止模式的 volatile 改进
- 同步模式之 balking
6.共享模型之无锁
本章内容

6.1 问题提出 (应用之互斥)
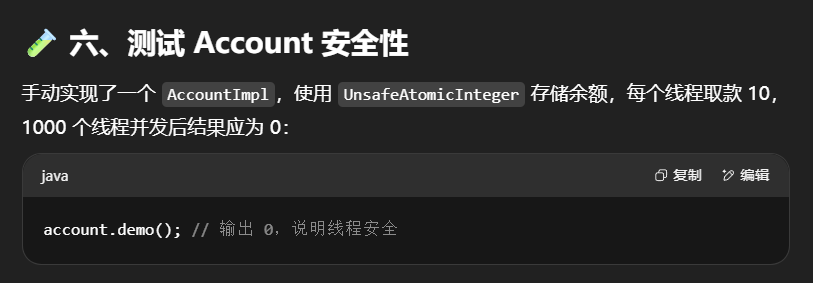
你有一个银行账户 Account,初始余额 10000,然后使用 1000 个线程,每个线程执行 account.withdraw(10),理论上最后余额应为 0。
1 | package cn.itcast; |
原有实现并不是线程安全的
1 | class AccountUnsafe implements Account { |
执行测试代码
1 | public static void main(String[] args) { |
某次的执行结果
1 | 330 cost: 306 ms |
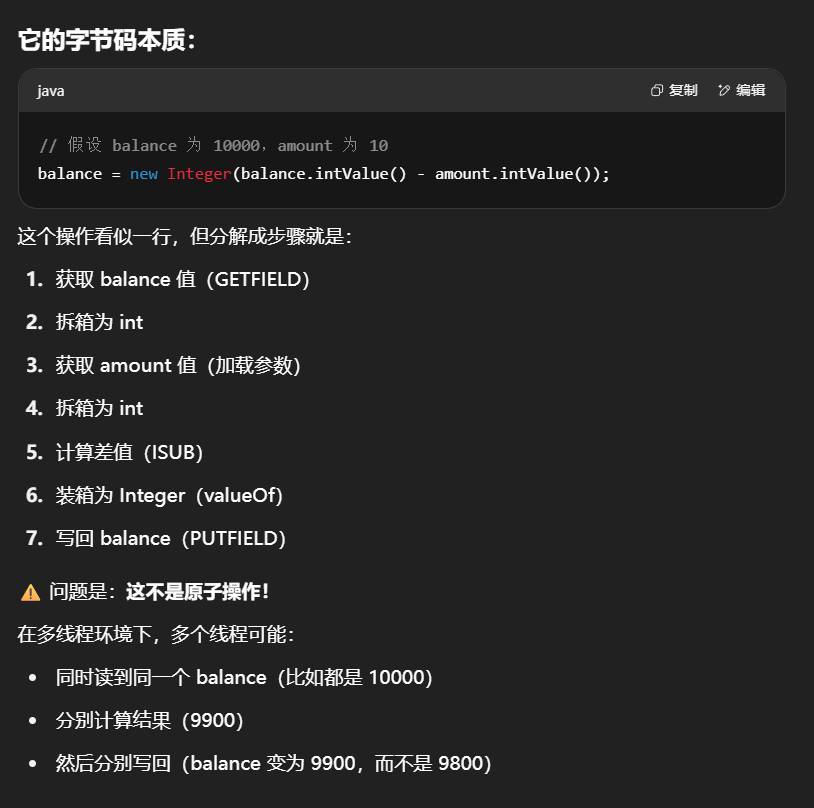
为什么不安全
withdraw 方法
1 | public void withdraw(Integer amount) { |
解决思路-锁(悲观互斥)
首先想到的是给 Account 对象加锁
1 | class AccountUnsafe implements Account { |
结果为
1 | 0 cost: 399 ms |
分析:
- 保证每次只有一个线程能执行 withdraw
- 操作过程变为“串行”
- ✅ 保证了正确性
- ⚠️ 但性能会因频繁加锁而下降
解决思路-无锁(乐观重试)(CAS 重试)
使用 AtomicInteger 实现非阻塞线程安全:
1 | class AccountSafe implements Account { |
执行测试代码
1 | public static void main(String[] args) { |
某次的执行结果
1 | 0 cost: 302 ms |
分析:
- 利用原子类的
compareAndSet实现无锁更新 - 如果失败会自动重试(循环)
- ✅ 在低冲突场景下性能好于锁
- ⚠️ 高并发下可能重试多次,性能不一定稳定
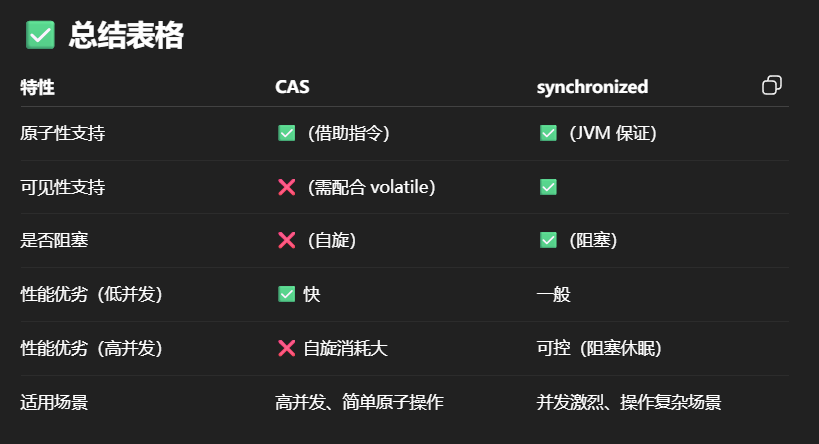
| 特性 | synchronized(悲观锁) | AtomicInteger(乐观锁) |
|---|---|---|
| 原理 | 阻塞式互斥 | 非阻塞 CAS 重试 |
| 是否加锁 | ✅ 是 | ❌ 否 |
| 是否线程安全 | ✅ | ✅ |
| 性能 | 中等偏低(锁竞争高) | 较优(低竞争下) |
| 编程复杂度 | 低 | 中(需要手动处理重试) |
| 适合场景 | 高安全要求场景 | 频繁并发但冲突低的场景 |
6.2 CAS 与 volatile
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
答:它并没有使用传统的锁(如 synchronized),而是用一种原子操作机制:
1 | public void withdraw(Integer amount) { |
其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
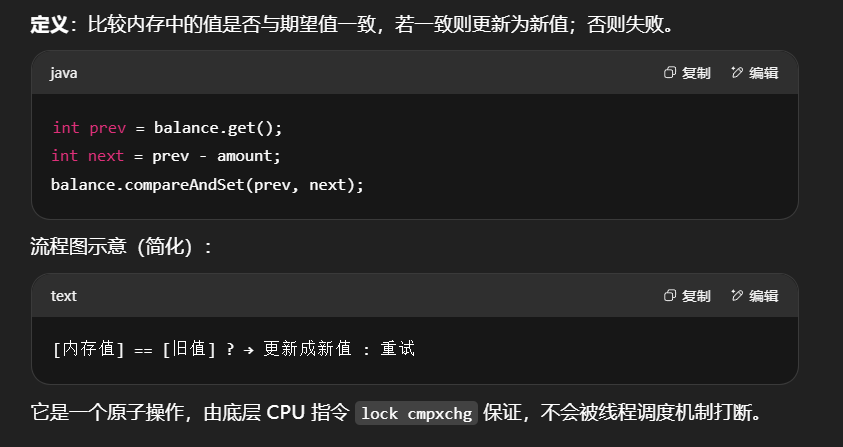
注意
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交 换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再 开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
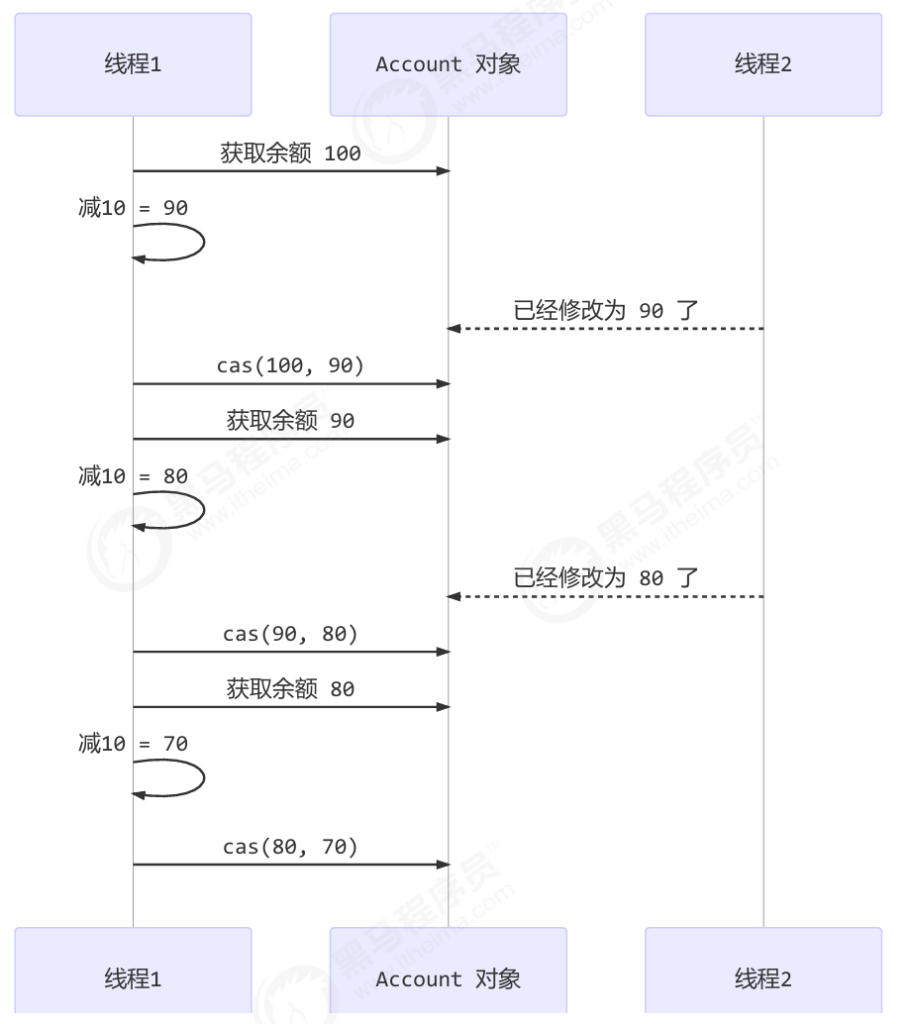
慢动作分析
1 | @Slf4j |
输出结果
1 | 2019-10-13 11:28:37.134 [main] try get 10000 |
CAS 与 volatile 的关系
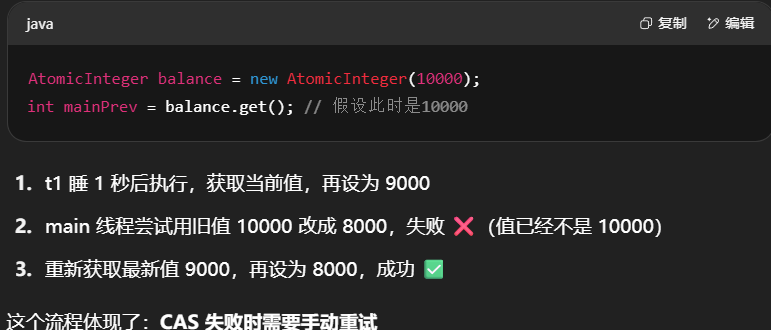
虽然 CAS 是原子操作,但它要操作的那个变量必须是最新的。
compareAndSet必须用到主内存中的最新值- 所以这个变量通常需要用
volatile修饰,以保证内存可见性
| 能力 | CAS | volatile |
|---|---|---|
| 保证原子性 | ✅ | ❌ |
| 保证可见性 | ❌(本身不保证) | ✅ |
| 防止重排序 | ❌(本身不保证) | ✅ |
两者搭配:CAS + volatile → 实现无锁的并发安全操作
为什么无锁效率高

- 不会导致线程阻塞(这就是为什么比synchronized效率高的原因),也就避免了上下文切换的开销
- 类似“一直试直到成功”的策略(自旋),只要竞争不是很激烈,成功率就高
| 特性 | synchronized(悲观锁) | CAS + volatile(乐观锁) |
|---|---|---|
| 原理 | 阻塞、上下文切换 | 自旋 + 原子指令 |
| 是否阻塞线程 | ✅ 会阻塞 | ❌ 不阻塞 |
| 适用场景 | 高安全性、操作复杂 | 高并发、冲突较低 |
| CPU 消耗 | 少(阻塞休眠) | 高(自旋消耗 CPU) |
CAS 的特点
CAS 的缺点(不能一味乐观)
- 自旋消耗 CPU:当失败率高时,会导致 CPU 占用率暴涨
- ABA 问题:如果另一个线程修改V值假设原来是A,先修改成B,再修改回成A。当前线程的CAS操作无法分辨当前V值是否发生过变化,CAS 检查通过,但数据已被篡改。ABA:解决办法是加版本号(如
AtomicStampedReference) - 只能操作单个变量:无法处理多个共享变量的复合操作(可用
AtomicReference+ 自定义封装)
CAS 是无锁,不等于无同步
虽然它不使用显式锁(synchronized),但:
- 底层使用
volatile保证可见性 - 使用 CPU 指令
lock cmpxchg保证原子性 - 实际上是“硬件级别的同步”
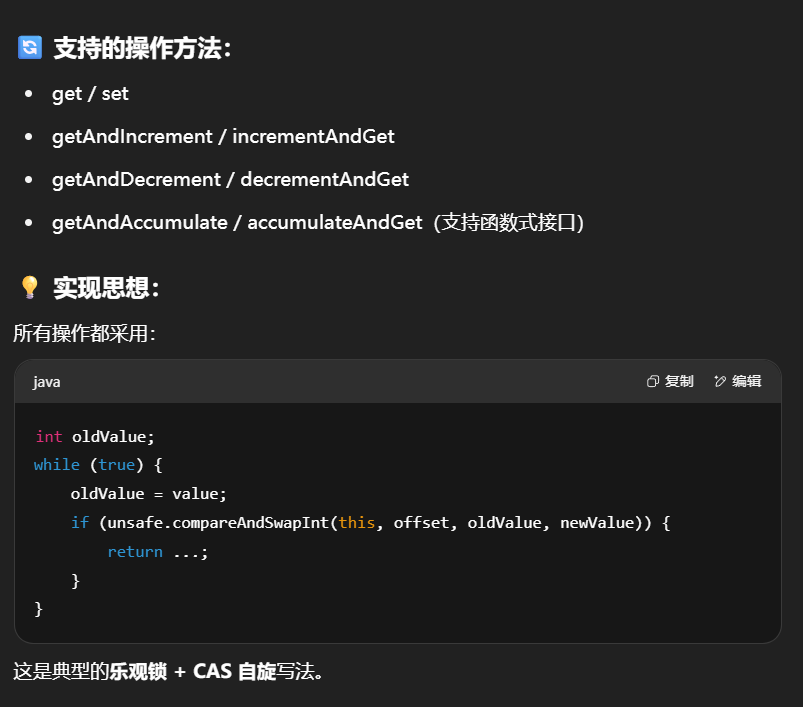
6.3原子整数

J.U.C 并发包提供了几种常见的原子类:
| 类型 | 描述 |
|---|---|
AtomicBoolean |
原子布尔类型 |
AtomicInteger |
原子整型(最常用) |
AtomicLong |
原子长整型 |
构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型 Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型 Integer
1 | AtomicInteger i1 = new AtomicInteger(); // 初始值为 0 |
常用API:
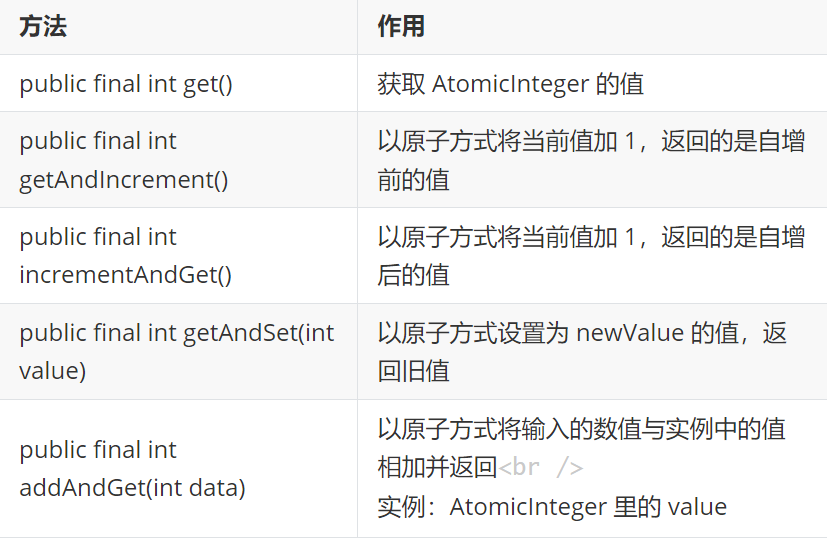
| 方法名 | 类比 | 返回值 | 操作后值 | 说明 |
|---|---|---|---|---|
getAndIncrement() |
i++ | 返回旧值 | +1 后新值 | 先取值再加一(后 ++) |
incrementAndGet() |
++i | 返回新值 | +1 后新值 | 加一后返回(前 ++) |
getAndDecrement() |
i– | 返回旧值 | -1 后新值 | |
decrementAndGet() |
–i | 返回新值 | -1 后新值 | |
getAndAdd(int x) |
i += x | 返回旧值 | +x 后新值 | |
addAndGet(int x) |
i += x | 返回新值 | +x 后新值 | |
getAndUpdate(f) |
函数式更新 | 返回旧值 | 更新后新值 | 函数需无副作用,使用 lambda 表达式 |
updateAndGet(f) |
函数式更新 | 返回新值 | 更新后新值 | |
getAndAccumulate(x, f) |
二元操作 | 返回旧值 | 计算后新值 | 可用于与外部值合并 |
accumulateAndGet(x, f) |
二元操作 | 返回新值 | 计算后新值 |
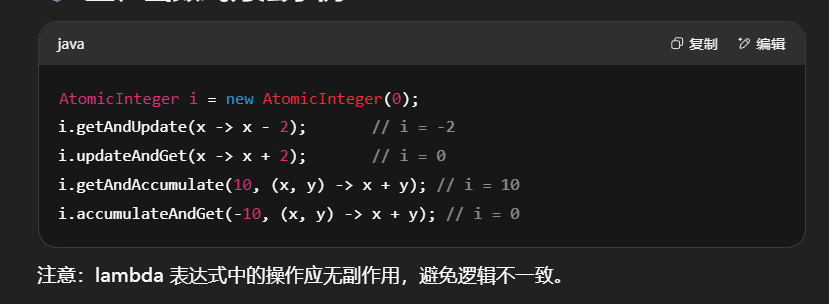
以 AtomicInteger 为例
1 | AtomicInteger i = new AtomicInteger(0); |
原理分析
AtomicInteger 原理:自旋锁 + CAS 算法
CAS 算法:有 3 个操作数(内存值 V, 旧的预期值 A,要修改的值 B)
- 当旧的预期值 A == 内存值 V 此时可以修改,将 V 改为 B
- 当旧的预期值 A != 内存值 V 此时不能修改,并重新获取现在的最新值,重新获取的动作就是自旋
分析 getAndSet 方法:
- AtomicInteger:
1 | public final int getAndSet(int newValue) { |
valueOffset:偏移量表示该变量值相对于当前对象地址的偏移,Unsafe 就是根据内存偏移地址获取数据
1 | valueOffset = unsafe.objectFieldOffset |
- unsafe 类:
1 | // val1: AtomicInteger对象本身,var2: 该对象值得引用地址,var4: 需要变动的数 |
var5:从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到本地内存),然后执行 compareAndSwapInt() 再和主内存的值进行比较,假设方法返回 false,那么就一直执行 while 方法,直到期望的值和真实值一样,修改数据
变量 value 用 volatile 修饰,保证了多线程之间的内存可见性,避免线程从工作缓存中获取失效的变量
1 | private volatile int value |
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较并交换的效果
分析 getAndUpdate 方法:
- getAndUpdate:
1 | public final int getAndUpdate(IntUnaryOperator updateFunction) { |
函数式接口:可以自定义操作逻辑
1 | AtomicInteger a = new AtomicInteger(); |
- compareAndSet:
1 | public final boolean compareAndSet(int expect, int update) { |
- updataAndGet
比如value初始是5,调用i.updateAndGet(value->value*10)会得到的修改后的值50。
如果调用i.getAndUpdate()会得到的是修改前的值。
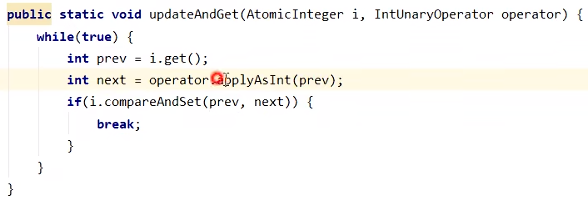
updataAndGet原理

调用operator的applyAsInt方法只需要传入数值参数,具体的操作(加法,减法,乘法,除法)会由applyAsInt的实现决定。
6.4原子引用
为什么需要原子引用类型?
实际开发中,我们的共享变量不总是 int 或 long,而可能是像 BigDecimal 这样:
- 不可变对象(每次操作都会返回新对象)
- 非线程安全(并发读写存在竞态)
这时使用普通 synchronized 会有性能瓶颈,所以我们考虑:
用
AtomicReference<T>来代替锁,实现 无锁线程安全。
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference

三种实现对比:模拟银行账户减钱
1 | public interface DecimalAccount { |
试着提供不同的 DecimalAccount 实现,实现安全的取款操作
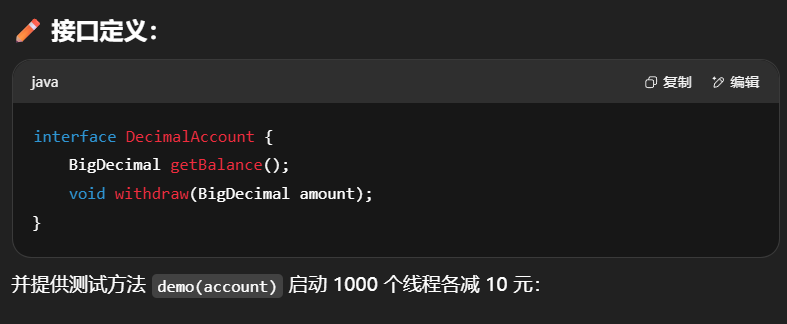
不安全实现(无同步)
1 | class DecimalAccountUnsafe implements DecimalAccount { |
- 多个线程读取 balance 是同一个值 → 并发写入导致丢失更新
- 最终余额不为 0,错误结果如:
4310
安全实现-使用锁
1 | class DecimalAccountSafeLock implements DecimalAccount { |
- 线程串行进入临界区,保证了每次减法不会被打断
- 结果正确(余额为 0),但性能稍差(如耗时 285 ms)
安全实现-使用 CAS(推荐)
1 | class DecimalAccountSafeCas implements DecimalAccount { |
测试代码
1 | DecimalAccount.demo(new DecimalAccountUnsafe(new BigDecimal("10000"))); |
运行结果
1 | 4310 cost: 425 ms |
- 使用
AtomicReference<BigDecimal>持有余额 - 使用
CAS方式尝试更新,如果失败就重试
线程安全且无阻塞,性能优(如耗时 274 ms)
总结:
| 实现方式 | 线程安全 | 最终结果 | 耗时 | 是否推荐 |
|---|---|---|---|---|
| 不安全(普通减法) | ❌ | 错误 | ~425 ms | ❌ |
| synchronized 锁 | ✅ | 正确 | ~285 ms | ✅(适中) |
| CAS + 原子引用 | ✅ | 正确 | ~274 ms | ✅✅(推荐) |
其他原子引用类型
| 类型 | 描述 |
|---|---|
AtomicReference<T> |
最常用,对引用对象进行 CAS 操作 |
AtomicStampedReference |
解决 ABA 问题,带版本号(如修改记录) |
AtomicMarkableReference |
带布尔标记位的引用,常用于逻辑删除标记等 |
ABA 问题及解决
ABA 问题
问题背景:使用 AtomicReference 做原子更新时,仅比较了对象的值(或引用),而无法得知该值是否被修改过后又还原。
1 | static AtomicReference<String> ref = new AtomicReference<>("A"); |
输出
1 | 11:29:52.325 c.Test36 [main] - main start... |
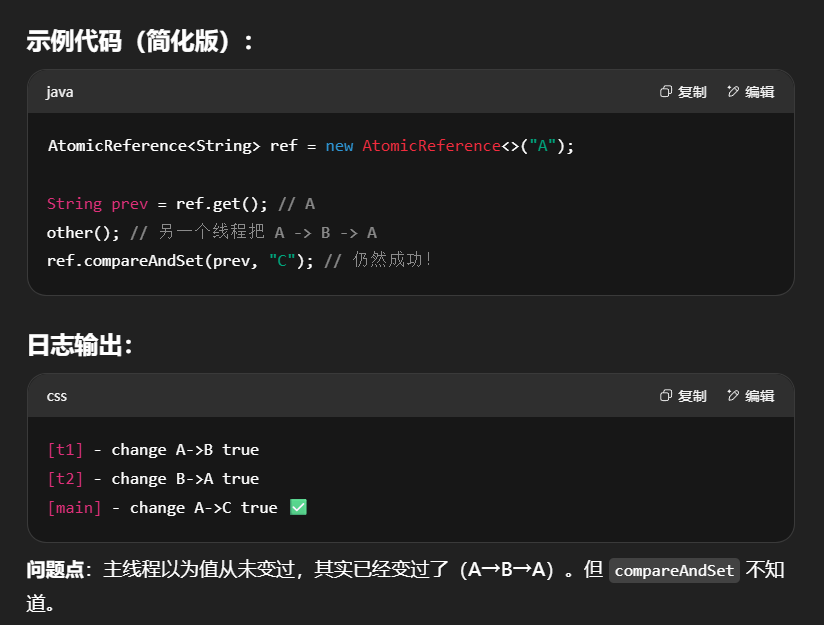
如何解决ABA问题-版本号机制
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
1.AtomicStampedReference
给每次更新操作附上版本号 stamp,即使值没变,只要 stamp 变了,就算更新失败。
1 | static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0); |
对比过程:
| 操作线程 | 值变化 | stamp 变化 | ref.compareAndSet 是否成功 |
|---|---|---|---|
| t1 | A → B | 0 → 1 | ✅ |
| t2 | B → A | 1 → 2 | ✅ |
| main | A → C | 0 → 1 | ❌(因为 stamp = 2 了) |
输出为
1 | 15:41:34.891 c.Test36 [main] - main start... |
结论:
AtomicStampedReference适合用于你关心“值有没有改过”的情况,哪怕最终值是一样的。
2.AtomicMarkableReference
适用场景:
- 不关心修改多少次,只关心“是否修改过”
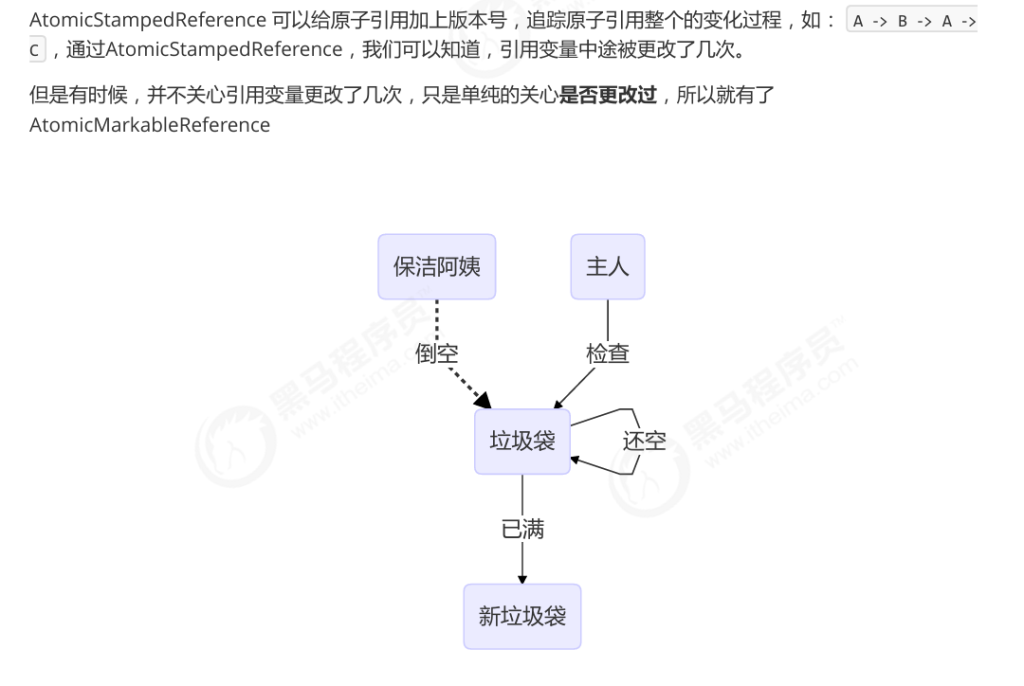
- 使用一个
boolean mark来作为“是否被动过”的标记
1 | class GarbageBag { |
输出
1 | 2019-10-13 15:30:09.264 [main] 主线程 start... |
可以注释掉打扫卫生线程代码,再观察输出
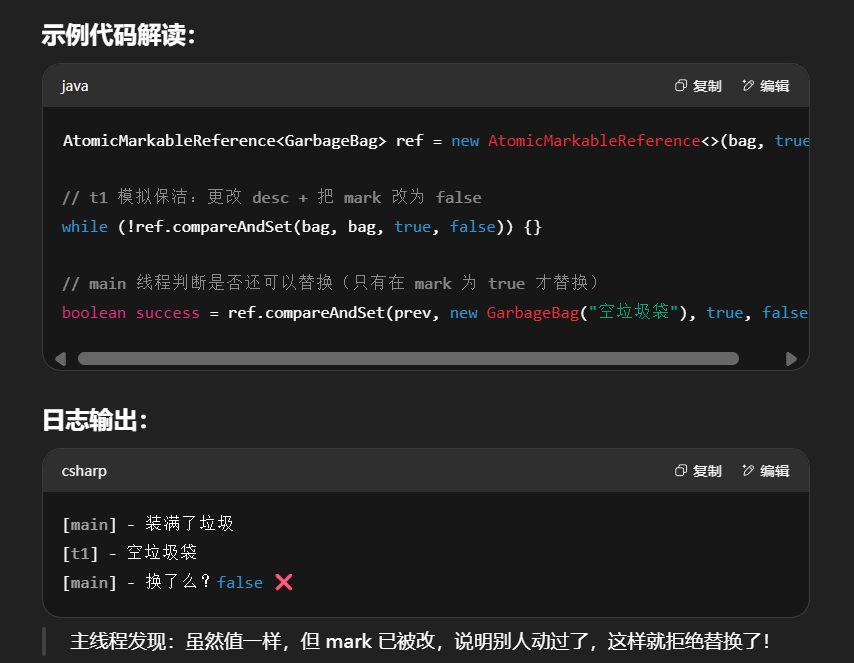
总结:
| 类型 | 能力 | 适用场景 | 状态标识 |
|---|---|---|---|
AtomicReference |
只比较引用值 | 简单并发更新(可能出现 ABA 问题) | 无 |
AtomicStampedReference |
比较值 + 版本号(stamp) | 精确控制值是否变过(如 CAS 计数器) | int 版本号 |
AtomicMarkableReference |
比较值 + 标记(mark) | 判断值是否被更改过一次 | boolean 标记 |
6.5 原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
这类工具的核心作用是:在并发环境下,对数组中的元素进行线程安全的原子操作,而不需要对整个数组加锁。
背景问题:普通数组线程不安全
假设我们让多个线程同时操作一个 int[] 数组,每个线程对每个元素执行 ++ 操作,那么最终数组的值应为线程数 × 每个线程操作次数。
但是实际上并不会如此——因为 array[index]++ 不是原子操作,它本质包括:
- 读取 index 位置的值
- 自增
- 写回数组
多个线程交错执行这些步骤时,会发生竞态,导致结果错误。
有如下方法
1 | /** |
不安全的数组
1 | demo( |
期望每个位置为 10000,但输出结果可能是:
结果
1 | [9870, 9862, 9774, 9697, 9683, 9678, 9679, 9668, 9680, 9698] |
说明:多个线程的 ++ 操作发生了丢失更新,最终数据小于理论值。
安全的数组
1 | demo( |
结果
1 | [10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000] |
说明使用了 原子操作 getAndIncrement(),每次对数组元素的操作都不会发生线程干扰。
demo 方法逻辑解析
泛型方法封装了一次通用测试流程:
1 | <T> void demo(Supplier<T> 创建数组, Function 取长度, BiConsumer 操作元素, Consumer 打印数组) |
- 支持任意类型(int[] 或 AtomicIntegerArray)
- 使用多个线程,每个线程对数组循环执行 10000 次指定操作
- 所有线程完成后,打印最终数组结果
这是一种非常通用、结构清晰的测试模式。
适用原子数组场景
| 类型 | 用于保护的数组类型 | 典型用途 |
|---|---|---|
AtomicIntegerArray |
int[] |
并发计数、热点统计等 |
AtomicLongArray |
long[] |
并发日志编号、时间戳等 |
AtomicReferenceArray |
引用类型数组(如对象) | 并发队列、缓存引用替换等 |
6.6 字段更新器
字段更新器是 JDK 提供的三类工具,它们允许你对某个*对象字段*(而不是整个对象)进行原子操作:
- AtomicReferenceFieldUpdater // 域 字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
使用字段更新器的前提条件
- 字段必须是
**public/protected/default-access**可访问 - 字段必须是
**volatile**修饰 - 字段不能是
static(即必须是实例字段)
否则你会遇到如下异常:
1 | Exception in thread "main" java.lang.IllegalArgumentException: Must be volatile type |
输出
1 | 10 // 第一次更新成功 |
字段更新器的优点
| 优点 | 说明 |
|---|---|
不需要将字段封装为 AtomicXXX 类型 |
保留原来的字段结构,减少对象开销 |
| 高效、无锁 | 基于底层 Unsafe 的 CAS 实现,性能好 |
| 灵活作用于多个实例 | 可以对不同对象的相同字段进行统一原子操作 |
6.7 原子累加器
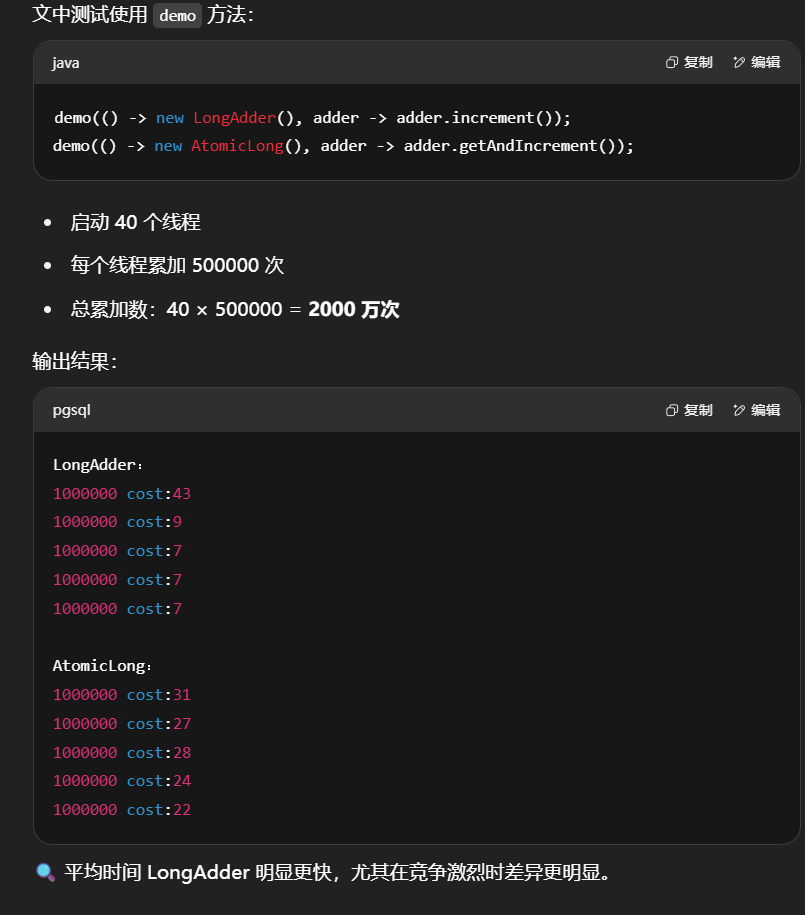
介绍了 LongAdder 与 AtomicLong 的性能差异,并解释了为什么在高并发场景下 LongAdder 明显优于 AtomicLong。
背景问题:AtomicLong 在高并发下性能瓶颈
AtomicLong 内部通过 CAS(Compare-And-Swap) 实现原子操作。但当多个线程同时竞争更新同一个值时,会频繁失败重试,导致性能下降。
累加器性能比较
1 | private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) { |
比较 AtomicLong 与 LongAdder
1 | for (int i = 0; i < 5; i++) { |
输出
1 | 1000000 cost:43 |
LongAdder 的底层原理:分段累加(striped)
基本思路:
将一个热点变量
value拆分成多个变量Cell[],每个线程操作自己的 Cell,最后合并求和。
| 特性 | AtomicLong | LongAdder |
|---|---|---|
| 结构 | 单个变量 CAS | 多个 Cell 分段累加 |
| 并发冲突 | 高 | 低(各线程操作不同 Cell) |
| 性能(高并发) | 差 | 优秀 |
| 汇总值 | 直接读 value | sum() 汇总所有 Cell 的值 |
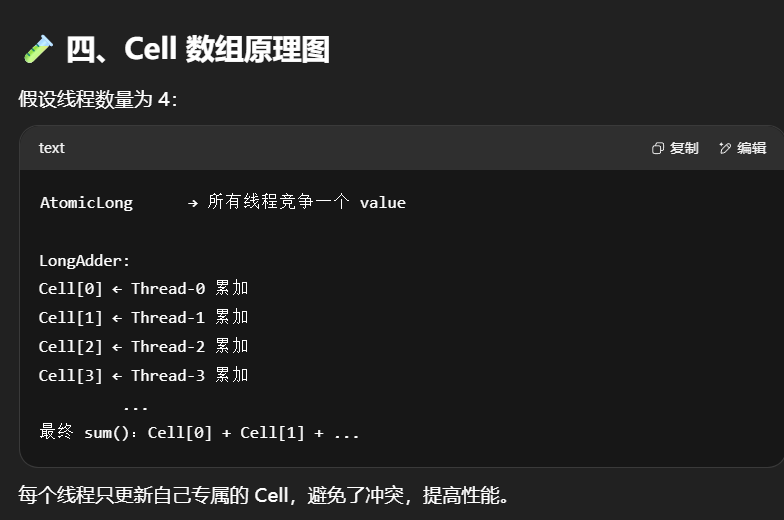


LongAdder原理
volatile是为了保证可见性,transient是序列化时不会把变量进行序列化

缓存行伪共享
多核并发性能优化中的一个重要底层细节:当多个线程修改不同变量,但这些变量恰好处于同一缓存行中,会导致性能急剧下降,这种现象就叫作 伪共享(False Sharing)。
背景:为什么有缓存?
CPU 运算速度远远快于主内存,所以现代计算机使用多级缓存(L1、L2、L3)来提升内存访问效率。
为了预读效率,CPU 是按缓存行为单位来读取内存的。
一个缓存行(Cache Line)通常是 64 字节
相当于一个缓存行可以容纳:
- 8 个
long(每个 8 字节) - 16 个
int(每个 4 字节)
CPU要保证数据的一致性,如果某个CPU核心更改了数据,其它CPU核心对应的整个缓存行必须失效。
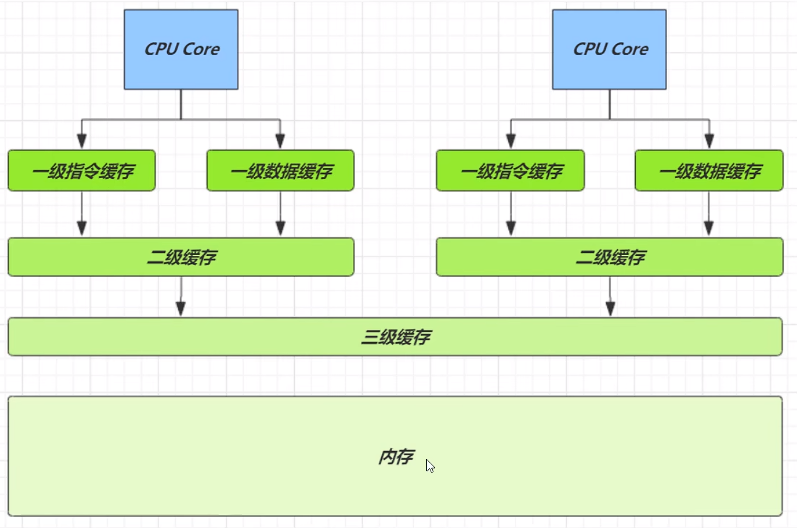
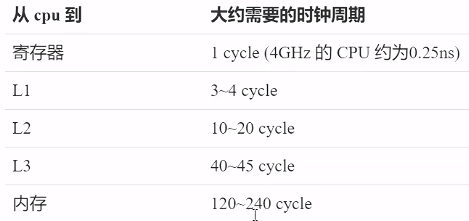
假如CPU核心占用的是同一个缓存行,其中一个核心对该行中的cell进行修改,都会使得另一个核心该缓存行中的数据失效,降低了效率。(当多个线程操作的变量不同,但它们共享了同一缓存行时,就会产生伪共享。)
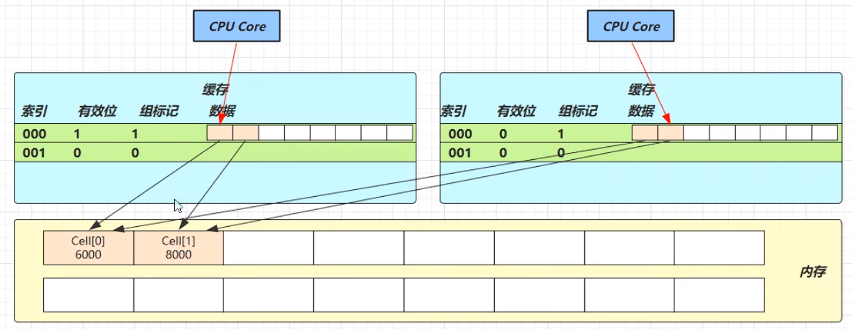
- 缓存行中有多个
cell - 当一个核心修改
cell[0],另一个核心尝试访问cell[1],但两者处在同一缓存行 ➜ 缓存冲突 ➜ CPU 不断刷新缓存 ➜ 性能下降
解决方法是用@sun.misc.Contended注解来让对象预读至缓存行时占用不同的缓存行,从而避免缓存行失效的问题。该注解原理是在使用该注解的对象或字段的前后增加128字节大小的padding,使得占用不同缓存行。
这部分可以参考JVM原理篇问题2补充缓存失效(Cache Line Miss)和伪共享(False Sharing)
| 术语 | 说明 |
|---|---|
| 缓存行(64B) | CPU 缓存预读的最小单位 |
| False Sharing | 多线程写入不同变量,却共享缓存行,互相干扰 |
| Contended | JDK8+ 提供的避免伪共享注解 |
| Padding | 内存对齐补齐字节,使字段落在不同缓存行中 |
LongAdder源码
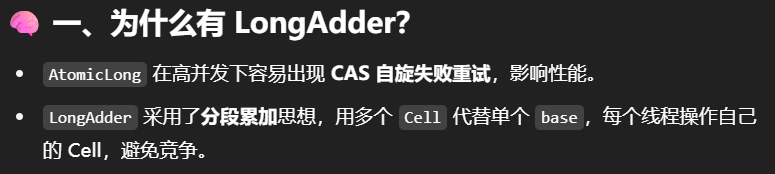
add 流程图
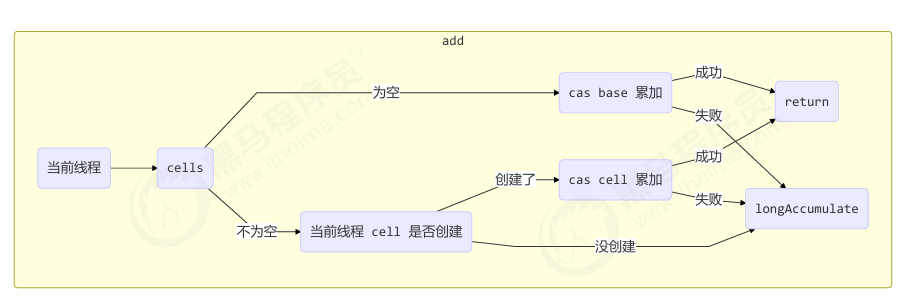
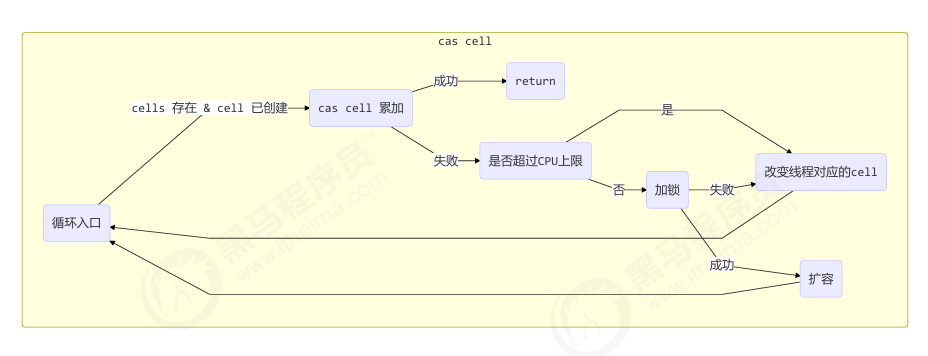
先看 Cell,有就用;没有就初始化;实在不行用 base。
1 | final void longAccumulate(long x, LongBinaryOperator fn, |
总结:
- 先判断当前线程有没有对应的Cell
- 如果没有,随机生成一个值,这个值与当前线程绑定,通过这个值的取模运算定位当前线程Cell的位置。
- 进入for循环
- if 有Cells累加数组且长度大于0
- if 如果当前线程没有cell
- 准备扩容,如果前累加数组不繁忙(正在扩容之类)
- 将新建的cell放入对应的槽位中,新建Cell成功,进入下一次循环,尝试cas累加。
- 将collide置为false,表示无需扩容。
- 准备扩容,如果前累加数组不繁忙(正在扩容之类)
- else if 有竞争
- 将wasUncontended置为tue,进入分支底部,改变线程对应的cell来cas重试
- else if cas重试累加成功
- 退出循环。
- else if cells 长度已经超过了最大长度, 或者已经扩容,
- collide置为false,进入分支底部,改变线程对应的 cell 来重试 cas
- else if collide为false
- 将collide置为true(确保 collide 为 false 进入此分支, 就不会进入下面的 else if 进行扩容了)
- else if 累加数组不繁忙且加锁成功
- 退出本次循环,进入下一次循环(扩容)
- 改变线程对应的 cell 来重试 cas
- if 如果当前线程没有cell
- else if 数组不繁忙且数组为null且加锁成功
- 新建数组,在槽位处新建cell,释放锁,退出循环。
- else if 尝试给base累加成功
- 退出循环
- if 有Cells累加数组且长度大于0

longAccumulate 流程图
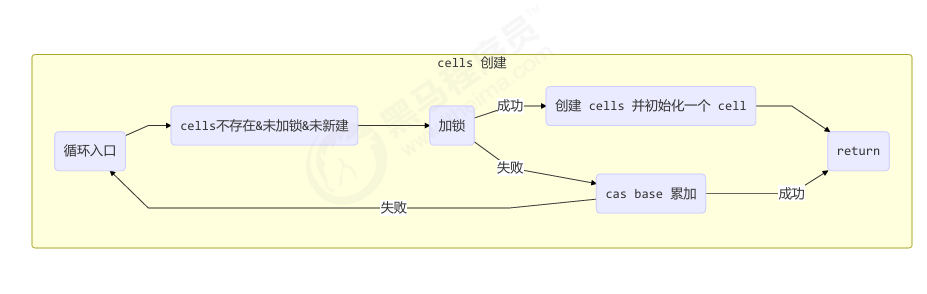
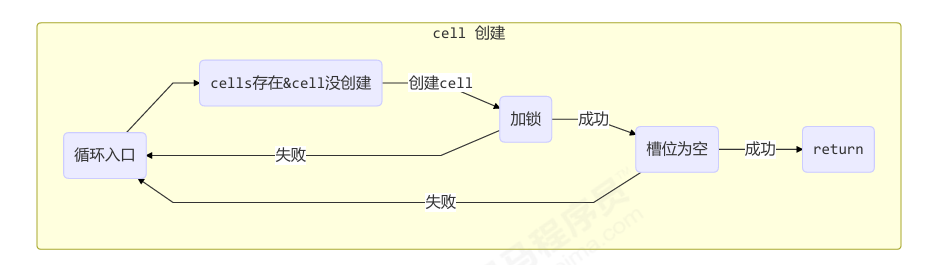
展示方法内部的各分支走向:
- 是否有 cell?
- cell CAS 是否成功?
- 是否需要扩容?
- 是否 fallback 用 base?
每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)
一个类似“线程分片”的过程
- 每个线程有个 probe 值(用来定位数组槽位)
- 如果位置已有 Cell,就尝试累加;否则创建一个新的
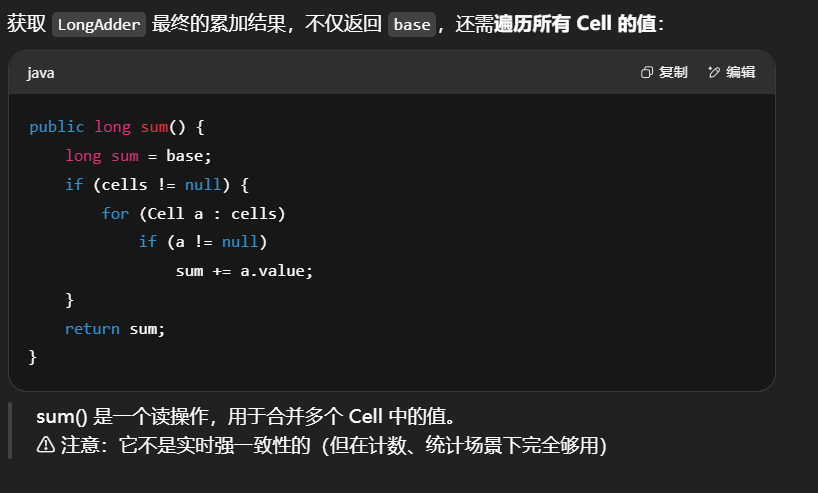
获取最终结果通过 sum 方法
1 | public long sum() { |
| 概念 | 含义说明 |
|---|---|
cellsBusy |
加锁标志,标识是否正在扩容 Cell 数组 |
probe |
当前线程的“地址值”,用于定位其 Cell 的索引 |
casCellsBusy() |
低成本尝试加锁操作,用于防止多个线程同时扩容 |
advanceProbe(h) |
如果失败或冲突,就重新计算线程的 probe,换个槽位重试 |

6.8 Unsafe
深入讲解了 JDK 提供的底层类 Unsafe,并通过手动实现原子操作(如 AtomicInteger 的替代方案)说明了它的强大能力。
概述
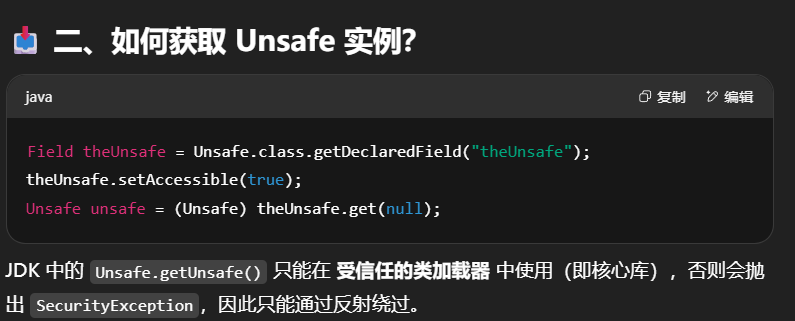
sun.misc.Unsafe 是 Java 中提供的一个非常底层的工具类,能直接操作内存、对象字段、线程等,绕开 Java 安全限制和封装保护。
❗它不对普通用户开放,只能通过反射获取。
1 | public class UnsafeAccessor { |
核心方法解析
方法:
1 | //以下三个方法只执行一次,成功返回true,不成功返回false |
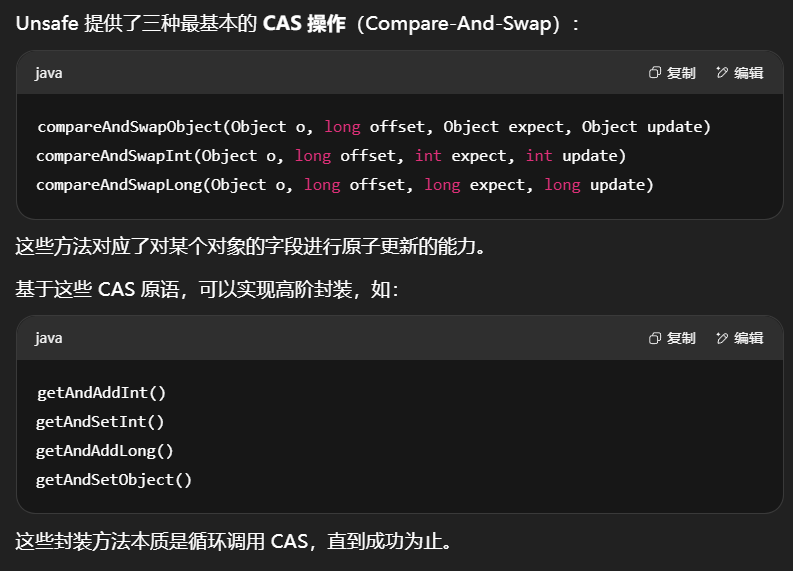
Unsafe CAS 操作
unsafe实现字段原子更新
1 | @Data |
输出
1 | Student(id=20, name=张三) |
不用借助 Atomic 类,只用 offset + CAS 就能实现原子性操作!
unsafe实现原子整数
1 | class AtomicData { |
Account 实现
1 | Account.demo(new Account() { |
手动实现原子整数完整版+测试
1 |
|
| 成员 | 含义 |
|---|---|
value |
volatile 修饰的目标变量 |
offset |
value 在对象内存结构中的偏移量 |
compareAndSwapInt() |
实现乐观锁的原子操作 |
总结:
| 工具类 | 实现原理 | 是否封装 | 使用复杂度 | 性能 | 是否推荐 |
|---|---|---|---|---|---|
AtomicInteger |
基于 Unsafe + CAS | ✅ 封装好 | 简单 | 高 | ✅ 推荐 |
自定义 UnsafeAtomicInteger |
自己封装 Unsafe | ❌ 手写代码 | 复杂 | 高 | ❌ 学习用 |
Unsafe |
原始底层类 | ❌ 无封装 | 很复杂 | 高 | ❌ 风险高 |
6.9本章小结

7.共享模型之不可变

7.1 日期转换的问题
问题提出SimpleDateFormat 非线程安全
下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); |
有很大几率出现 java.lang.NumberFormatException 或者出现不正确的日期解析结果

问题结果:
- 有时会报错
NumberFormatException - 有时会解析出“错误日期”或返回 null
- 有时正常
原因:
SimpleDateFormat内部维护了共享的状态变量(如Calendar、ParsePosition等)- 多线程并发访问时,会导致状态互相覆盖,产生线程安全问题
思路 - 同步锁
这样虽能解决问题,但带来的是性能上的损失,并不算很好:
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); |
虽然加锁能保证线程安全,但 每次调用都要进入同步块,性能开销大,特别是在高并发环境下不推荐。
思路 - 不可变类 DateTimeFormatter
如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改啊!这样的对象在 Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类:
1 | DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd"); |
可以看 DateTimeFormatter 的文档:
1 |
|
因为它是不可变对象,没有共享可变状态,所以多线程下使用非常安全。
不可变对象,实际是另一种避免竞争的方式。
不可变对象的优势
| 优点 | 说明 |
|---|---|
| 天然线程安全 | 不存在状态变化,多个线程可并发使用 |
| 避免加锁开销 | 不需额外同步机制,性能高 |
| 代码更简洁稳定 | 避免各种竞争条件和复杂并发 bug |
7.2 不可变设计
如何通过 Java 的语法特性和设计方式,使一个类设计成不可变的(Immutable)。不可变对象在并发编程中尤其重要,因为它们天然线程安全,不需要加锁。我们通过 String 类作为案例来分析不可变设计的核心思想与技巧。

String类的设计
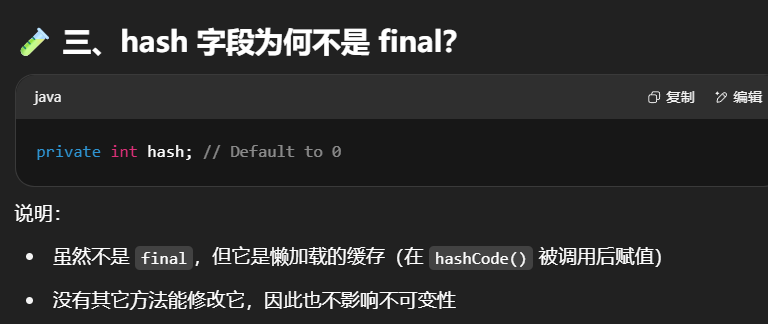
另一个大家更为熟悉的 String 类也是不可变的,以它为例,说明一下不可变设计的要素
1 | public final class String |
说明:
- 将类声明为final,
final class不可被继承,防止子类通过覆盖方法破坏不可变性。 value是字符数组,作为String的存储容器。被final修饰表示引用不能被修改,也不能指向新的数组。- hash虽然不是final的,但是其只有在调用
hash()方法的时候才被赋值(懒加载),除此之外再无别的方法修改。
final 的使用
发现该类、类中所有属性都是 final 的
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
保护性拷贝(带“修改行为”的方法如何保证不可变性?)
以 substring 为例:
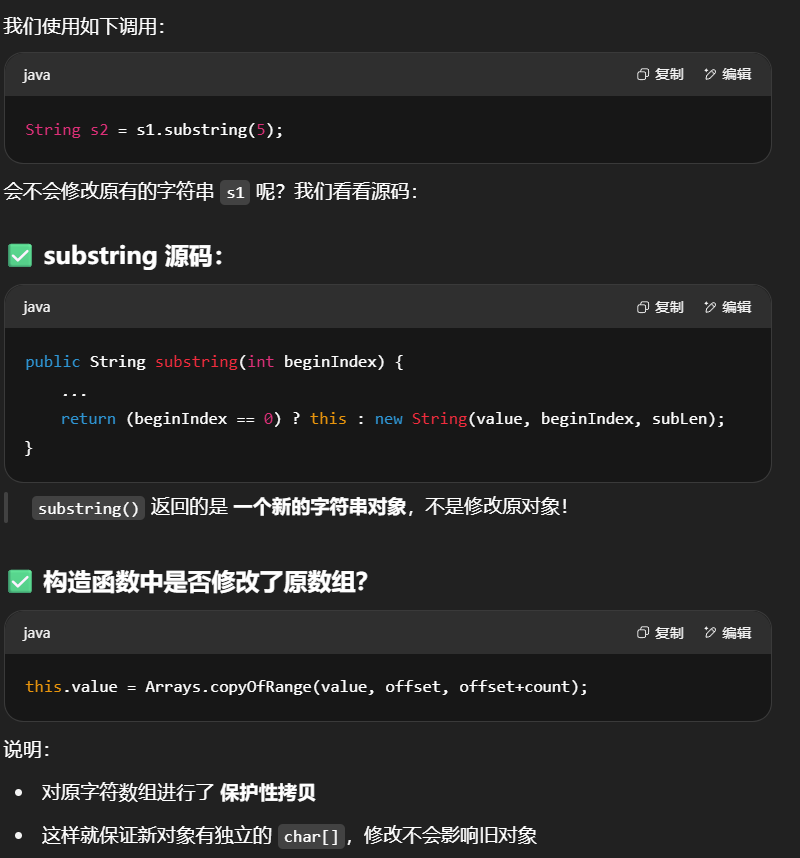
不可变设计要点总结
| 技术点 | 含义与作用 |
|---|---|
类用 final |
防止被继承后破坏不可变性 |
属性用 final |
保证字段引用不变 |
| 不提供 set 方法 | 保证属性值不可修改 |
| 方法返回新对象 | 类似 substring(),返回新副本而非修改原对象 |
| 拷贝构造 | 使用 Arrays.copyOfRange 做保护性复制 |

7.3模式之享元
简介
享元模式的核心思想是:通过共享减少内存使用,提高性能。

在 JDK 中的体现
1.包装类缓存(valueOf)
在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法,例如 Long 的 valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对 象:
1 | public static Long valueOf(long l) { |
注意:
- Byte, Short, Long 缓存的范围都是 -128~127
- Character 缓存的范围是 0~127
- Integer的默认范围是 -128~127
- 最小值不能变
- 但最大值可以通过调整虚拟机参数
-Djava.lang.Integer.IntegerCache.high来改变- Boolean 缓存了 TRUE 和 FALSE
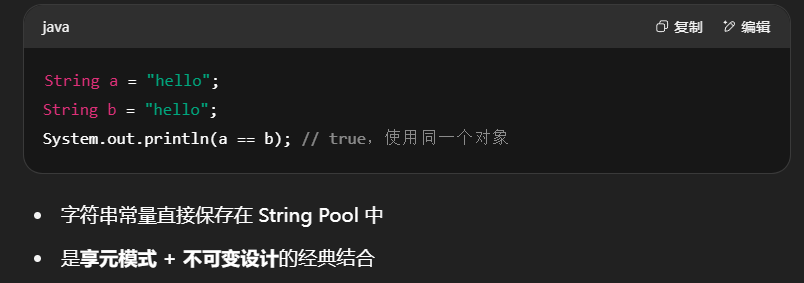
2.String 常量池(String Pool)(不可变、线程安全)
3.BigDecimal BigInteger(不可变、线程安全)
一部分数字使用了享元模式进行了缓存。
常用的值(如 0、1、10)是预先创建好并缓存的
避免重复创建大量相同常量对象
手动实现一个连接池
连接对象是有限的、可以重用的资源
例如:一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。 这时 预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。
1 | class Pool { |
使用连接池:
1 | Pool pool = new Pool(2); |


测试:
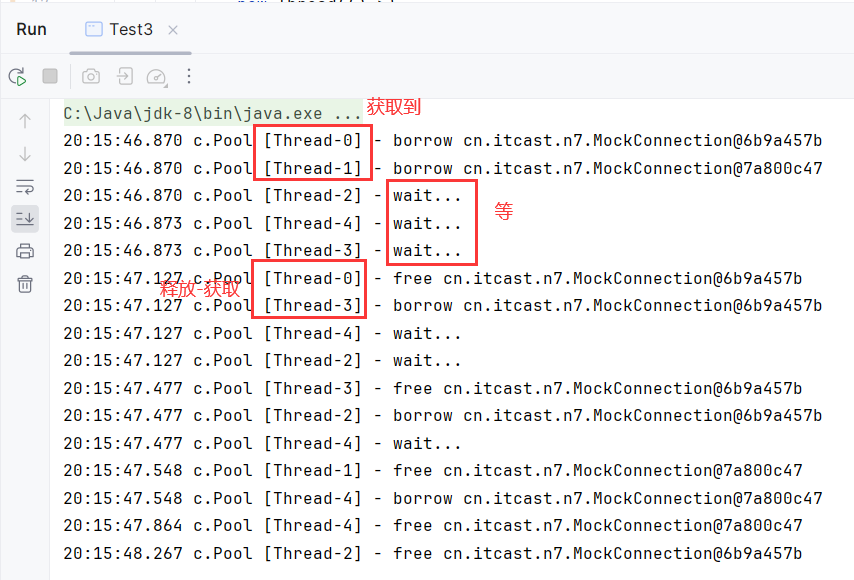
之所以要加下面连接是为了避免CPU空转,让线程获取不到资源就放弃对资源的抢占:

以上实现没有考虑:
| 问题 | 改进方向 |
|---|---|
| 固定连接数量 | 动态扩容/收缩 |
| 没有可用性检测 | 定期心跳 / ping 数据库 |
| 没有超时控制 | borrow 设置 max wait time |
| 没有分布式支持 | 可加入 hash 分布、Sharding |
实际中更推荐使用:
Redis:JedisPool(Apache Commons Pool)
JDBC:Druid, C3P0, HikariCP
7.4原理之 final
设置 final 变量的原理
理解了 volatile 原理,再对比 final 的实现就比较简单了
在 Java 中,将变量声明为 final 会触发特殊的编译器和 JVM 优化机制。
1 | public class TestFinal { |
字节码分析
1 | 0: aload_0 |
重点在于:JVM 会在 putfield(写字段)之后加入写屏障(Write Barrier),从而确保:
final变量写入在构造方法完成前可见- 不会发生指令重排序
这保证了:一旦对象构造完成,其他线程访问该对象时,final 字段的值一定是正确的,不会是默认值(如 0)。
读取final变量原理
有以下代码:
1 | public class TestFinal { |
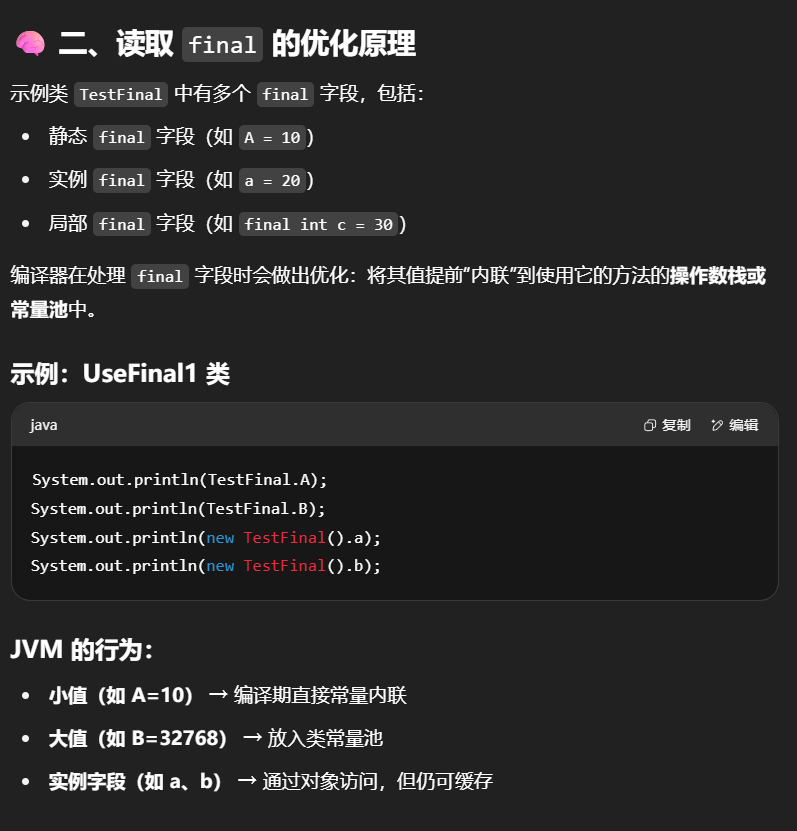
可以看见,jvm对final变量的访问做出了优化:另一个类中的方法调用final变量,不是从final变量所在类中获取(共享内存),而是直接复制一份到方法栈栈帧中的操作数栈中(工作内存),这样可以提升效率,是一种优化。
总结:
- 对于较小的static final变量:复制一份到操作数栈中
- 对于较大的static final变量:复制一份到当前类的常量池中
- 对于非静态final变量,优化同上。
final与线程安全

final总结
final关键字的好处:
(1)final关键字提高了性能。JVM和Java应用都会缓存final变量。
(2)final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销。
(3)使用final关键字,JVM会对方法、变量及类进行优化。
| 好处 | 说明 |
|---|---|
| 性能优化 | 编译器/JVM 会做常量折叠与内联 |
| 线程安全 | 构造完成后保证字段可见性 |
| 可读性强 | 表达“只读”语义 |
关于final的重要知识点
1、final关键字可以用于成员变量、本地变量、方法以及类。
2、final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。
3、你不能够对final变量再次赋值。
4、本地变量必须在声明时赋值。
5、在匿名类中所有变量都必须是final变量。
6、final方法不能被重写。
7、final类不能被继承。
8、final关键字不同于finally关键字,后者用于异常处理。
9、final关键字容易与finalize()方法搞混,后者是在Object类中定义的方法,是在垃圾回收之前被JVM调用的方法。
10、接口中声明的所有变量本身是final的。
11、final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
12、final方法在编译阶段绑定,称为静态绑定(static binding)。
13、没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”。
14、将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
15、按照Java代码惯例,final变量就是常量,而且通常常量名要大写。
16、对于集合对象声明为final指的是引用不能被更改,但是你可以向其中增加,删除或者改变内容。

final vs volatile 对比
| 特性 | final | volatile |
|---|---|---|
| 可见性 | ✅(构造完成后立即可见) | ✅(任何修改都立即对其他线程可见) |
| 重排序限制 | ✅(构造器内部禁止写重排) | ✅(读写禁止重排) |
| 是否可修改 | ❌ 赋值一次即定值 | ✅ 可多次修改 |
| 线程安全性 | ✅ 初始化后线程安全 | ✅ 需要搭配其他机制(如 CAS) |
7.5无状态

不要为 Servlet 设置成员变量,这种没有任何成员变量的类就是线程安全的。
换句话说:
- 成员变量 = 状态信息
- 如果一个类没有成员变量,那它就是**无状态(stateless)**的
- 无状态类在多线程环境下不会发生数据竞争,所以天然是线程安全的

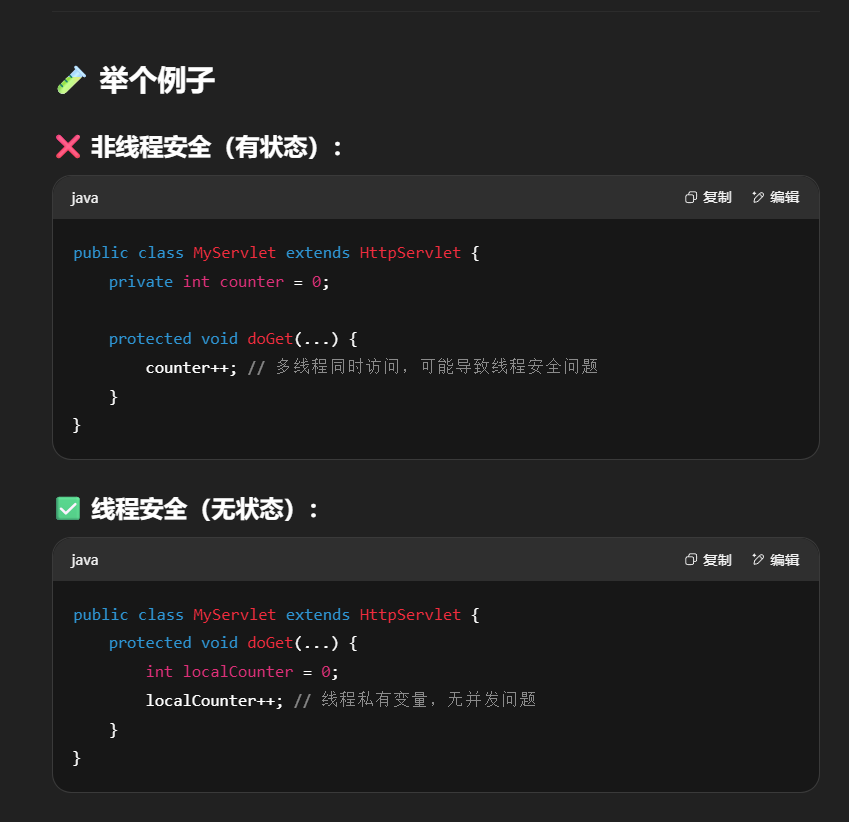
| 术语 | 含义 |
|---|---|
| 有状态对象 | 拥有成员变量,可能被多个线程同时访问 |
| 无状态对象 | 没有成员变量,或仅使用方法内的局部变量,线程安全 |
因为成员变量保存的就是状态信息,所以没有成员变量的类被称为无状态类(Stateless Object),天然线程安全。
7.6本章总结



