AIGC 绘图的前置知识(Stable Diffusion)
1.前沿
随着AI技术的迅猛崛起,AIGC(Artificial Intelligence Generated Content,人工智能生成内容)已成为推动内容创作领域变革的强大动力,它能够智能生成涵盖文本、图像、音频、视频在内的多样化内容,深刻影响着众多行业的变革。比如:
- 媒体与广告:在媒体领域,AIGC可以自动化地生成新闻报道、广告文案、社交媒体内容等,提高内容生成的效率和品质。在广告领域,AIGC可以根据不同的受众和广告策略,自动化地生成各种形式的广告内容,从而更好地吸引目标受众的注意力。
- 设计与艺术:AIGC技术在图像和艺术作品的生成方面也展现出巨大潜力。通过深度学习算法,AIGC能够根据用户输入的关键词和样式指南,自动生成具有艺术美感的图像和创意作品。这种自动化生成技术不仅提高了设计师和艺术家的生产力,还为他们带来了更多的创作灵感。
- 娱乐产业:在娱乐领域,AIGC可以自动化地生成电影、游戏、音乐等作品的故事情节、角色设定、画面等,极大地缩短了创作周期和成本。例如,在游戏开发中,AIGC可以辅助设计师快速生成游戏场景、角色模型等,提高游戏开发效率。
- 教育领域:在教育领域,AIGC可以自动化地生成各种教学资料、试题等,帮助教师更好地备课和评估学生。此外,AIGC还可以为学生提供个性化的学习内容和推荐,提升学习效果。
- 金融与保险:在金融和保险领域,AIGC可以应用于风险评估、欺诈检测、投资决策等方面。通过分析大量数据,AIGC能够提供更准确的风险评估和投资建议,帮助金融机构更好地管理风险和提高业务效率。
- 医疗保健:在医疗保健领域,AIGC可以用于疾病预测、诊断、治疗和药物研发等方面。通过训练已知的临床数据,AIGC可以预测疾病的发生和进展情况,为医生提供辅助诊断方案。同时,AIGC还可以帮助制药公司更快、更便宜、更准确地开发新药物。
- 自动驾驶:在自动驾驶领域,AIGC技术也发挥着重要作用。它可以帮助自动驾驶汽车和无人机等设备更准确地感知周围环境、做出更好的决策和行动。
- 其他领域:此外,AIGC还可以应用于电商、社交等多个领域。在电商领域,AIGC可以用于制定精准的产品推荐策略、基于大数据深度学习的广告推荐等;在社交领域,AIGC可以用于聊天机器人、语音识别、内容审核等方面。
因此,掌握AIGC文生图开发技术,不仅是适应时代发展趋势的必然选择,更是提升自身竞争力、实现职业发展的关键一步。通过本章的学习,学员将能够站在技术前沿,引领未来内容创作的潮流,为企业与社会创造更大的价值。
2.Stable Diffusion入门
1.Diffusion Model 扩展模型
回顾在第一天学习过程中,我们了解到,当下市场常见的大模型分类有:
- 大语言模型:用于文生文,典型的使用场景是:对话聊天—仅文字对话Qwen、ChatGLM3、Baichuan、Mistral、LLaMA3、YI、InternLM2、DeepSeek、Gemma、Grok 等等
- 文本嵌入模型:用于内容的向量化,典型的使用场景是:模型微调text2vec、openai-text embedding、m3e、bge、nomic-embed-text、snowflake-arctic-embed
- 重排模型:用于向量化数据的优化增强,典型的使用场景是:模型微调bce-reranker-base_v1、bge-reranker-large、bge-reranker-v2-gemma、bge-reranker-v2-m3
- 多模态模型:用于上传文本或图片等信息,然后生成文本或图片,典型的使用场景是:对话聊天—拍照批改作业Qwen-VL 、Qwen-Audio、YI-VL、DeepSeek-VL、Llava、MiniCPM-V、InternVL
- 语音识别语音播报:用于文生音频、音频转文字等,典型的使用场景是:语音合成Whisper 、VoiceCraft、StyleTTS 2 、Parler-TTS、XTTS、Genny
- 扩散模型:用于文生图、文生视频,典型的使用场景是:文生图AnimateDiff、StabilityAI系列扩散模型
而接下来我们将学习如果利用大模型进行图片的创作,这就要用到扩散模型的相关知识,因此先来看看什么是扩散模型。
谈及扩散模型,需要先理解扩散这一核心概念,扩散这个词源自物理学中的现象,指物质由高浓度区域向低浓度区域移动的过程,是一个自然趋向于平衡状态的过程。
而在人工智能(AI)领域,“扩散”并不指物质在空间中的移动,而是指数据样本点的分布向标准正态分布不断靠拢的过程。这个解释从专业的角度非常难以理解,因此我们在此只需要把人工智能的扩散理解成是高浓度的马赛克(也称为噪声)向低浓度区域移动的过程。
扩散模型(Diffusion Models)就是基于扩散思想的深度学习生成模型,它们在多个领域,尤其是图像生成任务中展现出了强大的能力。
在前些年,生成式图片领域使用的技术主要是GAN【全称是生成对抗网络(Generative Adversarial Network)】,是一种由Ian Goodfellow等人在2014年提出的机器学习模型。直到 2020 年,提出的 DDPM【去噪扩散概率模型(Denoising Diffusion Probabilistic Model)】模型向世界展示了扩散模型的能力,在图像合成方面击败了 GAN,所以后续很多图像生成领域开始转向 DDPM 领域扩散模型的研究。就当下市面上生成式图模型OpenAI 的 DALL·E 2 和 Google 的 Imagen,都是基于扩散模型来完成的。
扩散模型也细分文前向扩散和反向扩散,通过模拟一个前向扩散过程将图片数据逐渐转换为噪声,并随后通过一个反向扩散过程将噪声逐渐还原为原始图片数据。
前向扩散:图片转为马赛克—用于扩散模型的训练

反向扩散:马赛克转为图像—用于图像的生成

2.Stable Diffusion 稳定扩散模型
Stable Diffusion(全称稳定扩散模型,简称SD)是一种先进的深度学习模型,也是主流的用于高质量图像生成的模型,根据文本描述生成图像(text-to-image)。

stable Diffusion的代码和模型也是开源免费使用,可以在大多数配置了至少8GB VRAM的普通GPU的消费级硬件上运行,甚至在CPU上运行,这标志着Stable Diffusion和以往只能通过云服务访问的专有文本到图像模型(如DALL-E和Midjourney)完全不同。
Stable Diffusion也被称为稳定扩散模型,相比扩散模型的区别主要表现为:
- 开源免费
- 高质量输出:通过引入稳定性指数,显著提高了模型的稳定性,使得生成的图像质量更加一致,更符合输入需求;
- 高效率输出:通过优化模型结构和算法,提高了计算效率(可以使用常规显卡运算),能够在较短时间内生成高质量的图像;
3.Stable Diffusion 基本结构与原理
虽然Stable Diffusion作为扩散模型的变体模型,但在实现图片生成的思想上依然和扩散模型一致,且通过反向扩散过程的思想来完成图片生成。

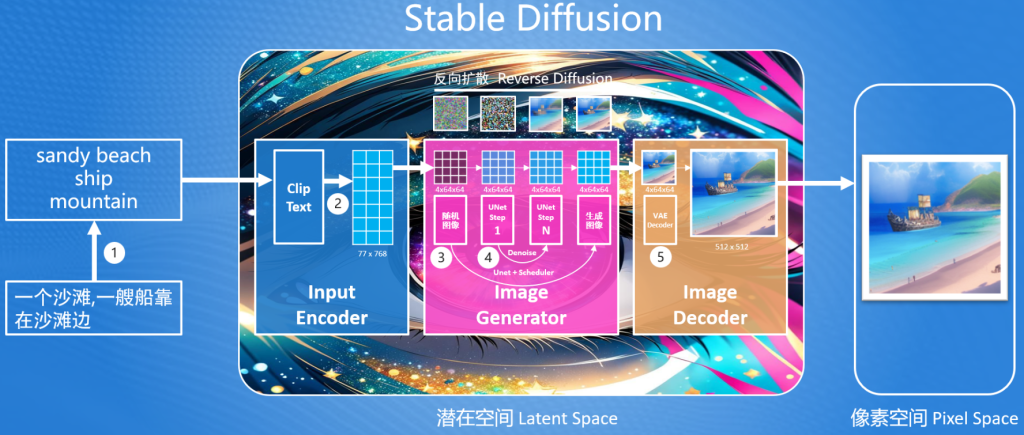
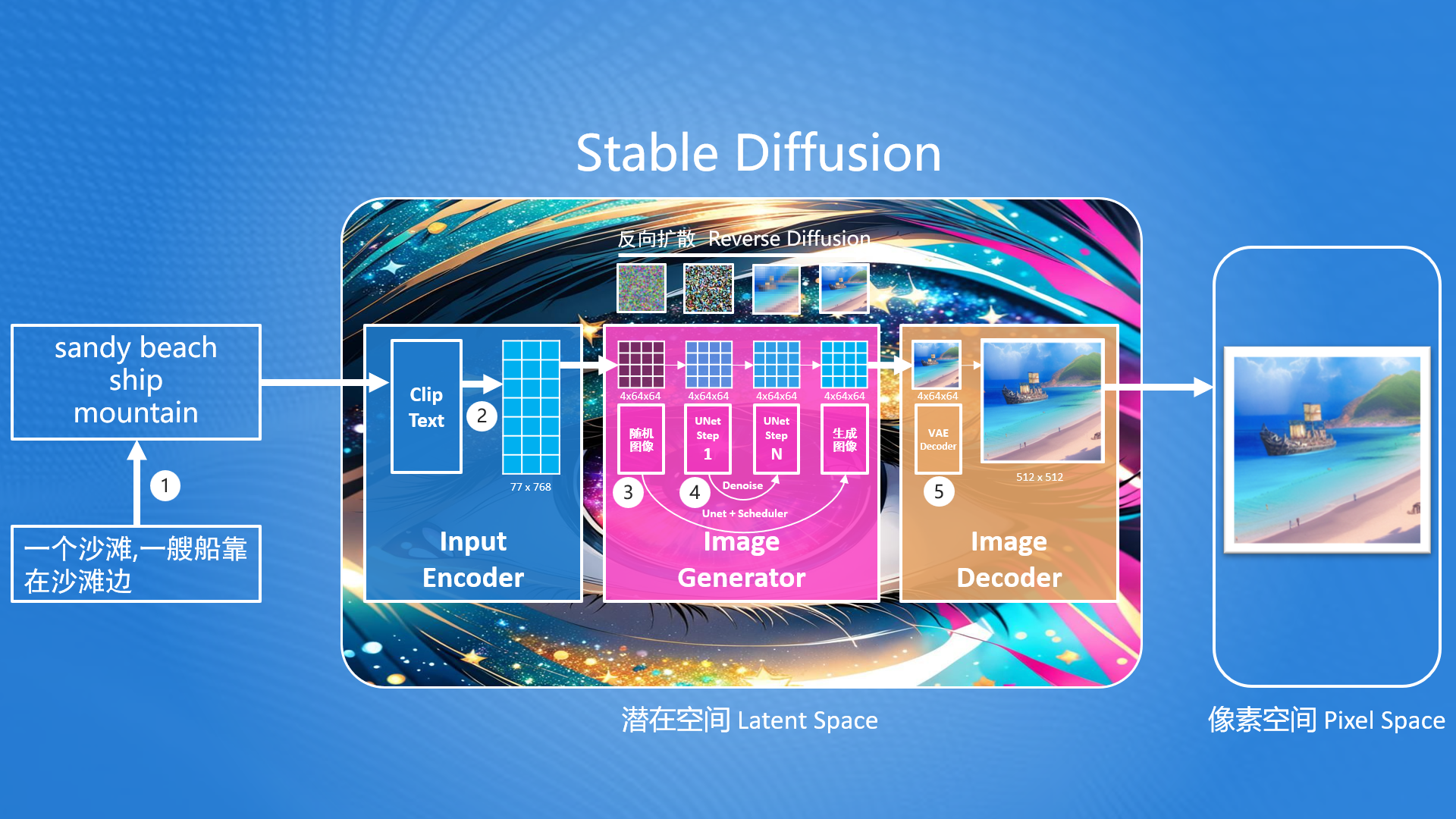
在Stable Diffusion的核心思想中,首先生成一张噪声图(最左边—马赛克图),然后按照用户输入的提示词,去除噪声图中的部分信息,就生成一张跟文本信息匹配的图片。整个生图流程如下:

Stable Diffusion首先要解决的问题就是:如何把提示词转换成能够计算机理解的信息?
要解决问题的方案我们需要先掌握基本的Stable Diffusion流程,后续再进行该问题的详解。在Stable Diffusion中提供了一个文本编码器(Text Encoder),可以把输入的提示词转化成计算机大模型能理解和识别的数字(专业称为语义向量)。有了这个语义向量,就可以使用图片生成器(Image Generator)生成目标图像,这里生成目标图像就使用到了反向扩散模型的思路,但是注意这里生成的图像并不是最终的图片,而是一个低像素的图片,因此Stable Diffusion最终还需要通过一个图片解码器(Image Decoder)把生成的图片转成我们最终的图片。

从上图还不难发现,Stable Diffusion是在潜在空间中(Latent Space,也称潜空间)中生成的,而我们最终需要一张可以看得见图片,我们都知道在计算机中,所见到的图片是有像素组成的,因此称这张图片为像素空间(Pixel Space)的图片。而潜在空间中的图片不能直接在像素空间中使用,因此Stable Diffusion提供了图片解码器(Image Decoder)可以把潜在空间中的图片转为像素空间中的图片。
潜在空间(Latent Space): 一种比像素空间更小空间,在Stable Diffusion中,潜在空间比像素空间小48倍,这样设计可以减少计算机算力,并提高生成速度。
综上所述,Stable Diffusion由3部分组成:
- 输入编码器(Input Encoder):把用户输入的内容转换提示词为语义向量(很长的一串数字);
- 图片生成器(Image Generator):结合语义向量,生成潜在空间图片;
- 图片解码器(Image Decoder):转换潜在空间的图片为像素空间中的图片;
4.Stable Diffusion 深度原理
在SD相关软件或开发过程中,需要经常用到涉及底层的基本概念,因此我们还需要进一步对其底层进行分析和了解,便于后面的学习。
在这里我们进一步放大SD内部结构,可以发现更多的内容细节暴露出来,其中包括:
- ①、SD模型只支持英文输入,因此用户输入的中文,需要先转出英文;(后续解释为什么只能是英文?)
- ②、输入编码器(Input Encoder)在内部时通过一个叫ClipText的组件把用户输入的文本内容转成语义向量的;
- ③、图片生成器(Image Generator)在内部时通过UNet+Scheduler来进行图片生成的,同时生成的过程是反向扩散的实现过程;
- ④、而在图片生成过程主要依据Denoise这个过程来重复迭代生成图片;
- ⑤、图片解码器(Image Decoder)在内部会通过VAE解码器把生成的潜空间图片,放大成像素空间的大小需求;
要充分理解上述的5个关键步骤,这里必须先理解什么是Clip、UNet和VAE。
Clip是什么?
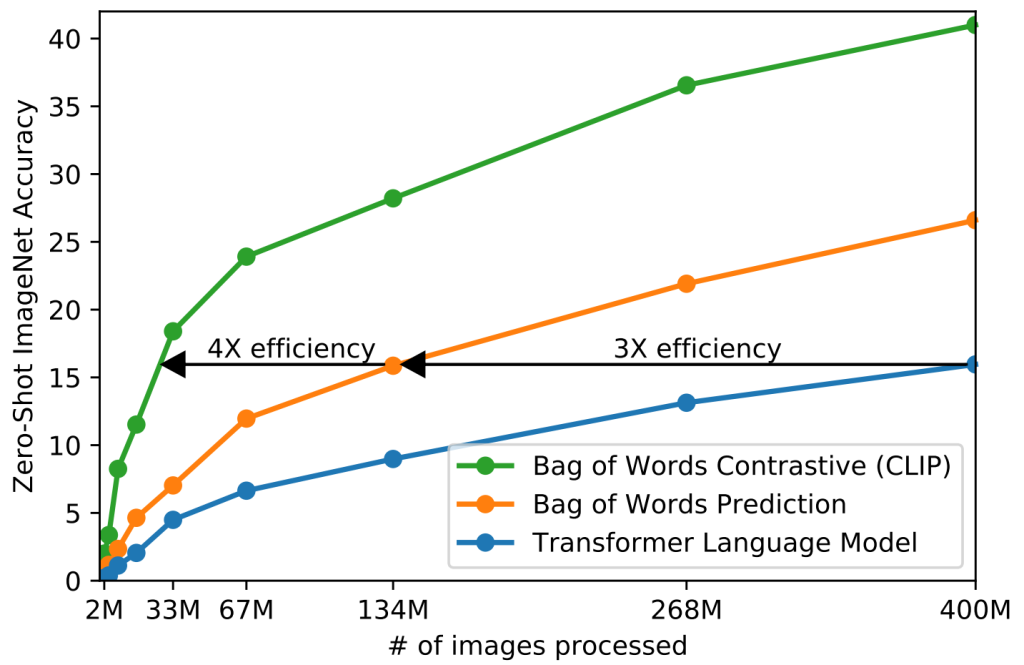
CLIP(Contrastive Language–Image Pre-training)对比语言预训练模型,由 OpenAI在2021年 提出,它能够理解并处理图像和文本,通过对它们进行对比学习(contrastive learning)来建立图像和文本之间的关联。简单来说Clip模型能把用户输入的文字需求,正确的理解成生成图片的需求。
CLIP的不仅训练数据多,大约有4亿多个(文本和图像),而且训练出的模型执行效率高,高出同类型模型的4到10倍,可以简单理解Clip目前是顶尖的文本与图像关联的模型。
Clip架构中主要有两大核心部分组成:
- 文本编码器(Text Encoder):把文本编码成向量;长度不超过77,如果超过会自动截断;
- 图片编码器(Image Encoder):把图片编码成向量;尽量是正方形;
这两大核心在Clip模型训练的过程中,在3个关键步骤中有被使用到:
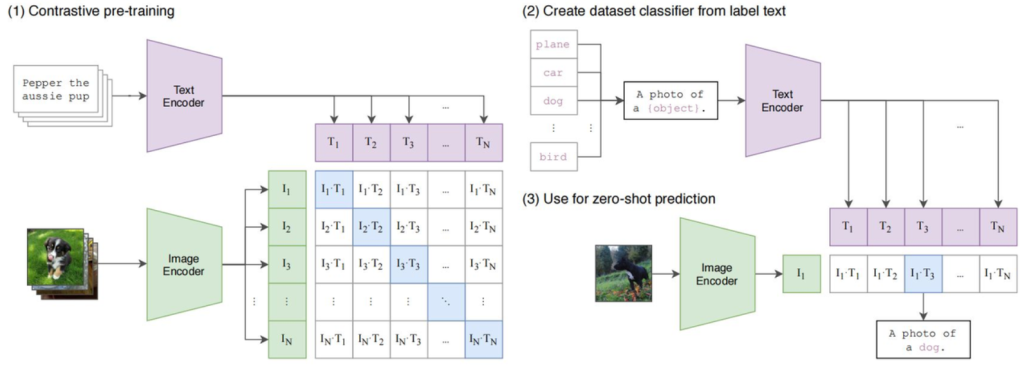
- 1、对比训练:将一批配对好的图像和**(英文)**文本数据集(最开始数据集大小是32768对),分别通过文本和图片编码器分别生成对应的向量,再通过算法(余弦相似度、对称交叉熵损失等)来计算出文本和图片关联度最大的向量数据。
- 2、依据标注文本创建数据集分类器:使用文本编码器对大量图像及相关的**(英文)**文本描述生成向量,以此来训练出一个分类器,使得模型能够依据图像的特征来预测其所属的分类。
- 3、使用零样本预测:输入一张没有在训练数据集中的图片,通过图片编辑器转成向量,然后利用第2步的分类器,对向量进行分类处理,通过得到的分类,我们即可知悉图片中的信息是什么。这意味着即使模型在训练过程中没有见过这些新图像,通过使用零样本预测Clip模型也可知悉图片中的内容。
通过上述了解的内容,可以了解到Clip的训练过程中使用的文本都是英文的,因此就解释了为什么SD需要把中文转出英文后处理。
UNet是什么?
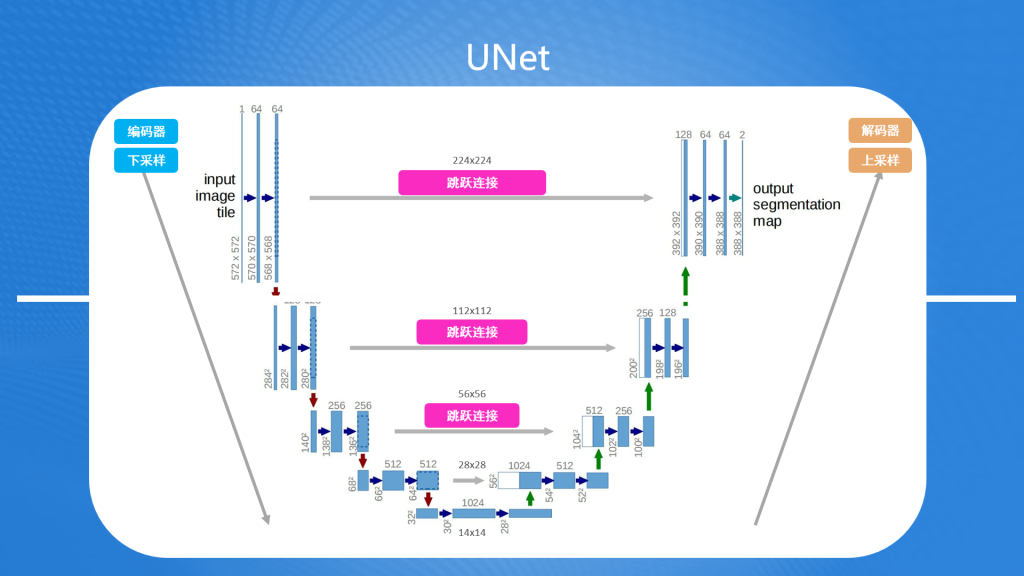
UNet是一种用于图像分割的卷积神经网络架构。可以把输入的图片分割成具有一定语义含义的区域块,识别出每个区域块语义类别,最终得到与原图像等大小具有逐像素语义标注的分割图像。

随着UNet的发展,人们很快就发现UNet架构的设计非常巧妙,不仅能用于图片分割,还能用于提升图片的细节和质量。
UNet的结构主要包括编码器和解码器两部分,提升图片质量主要通过这两部分来完成:
- 编码器:主要用来提取出图片中的特征信息,并逐渐降低图像的空间维度,这个过程也称下采样过程。比如一张224x224的图像,首先下采样变为112x112,然后变为56x56,28x28,最后图像大小缩至14x14。每次下采样尺寸的缩小都是为了捕获图像的细节特征,同时减少计算量。
- 解码器:主要用把低维度空间的图片还原成原来尺寸,并在过程中融合图片的细节,这个过程也称为上采样过程。上采样和下采样相反,首先通过14x14生成28x28的尺寸,然后再把生成的图片与之前下采样过程中的28x28图片进行融合,接着再用融合的图片生成56x56的图片,再融合,以此类推,直到复原原有尺寸为止。在这个过程中上采样生成的图片与下采样生成的图片融合,被称为跳跃连接(Skip Connection),它能在融合过程不仅保留了图像的全局信息,也精确地恢复了局部细节。
UNet框架最开始由Olaf Ronneberger等人在2015年提出,主要用于解决医学图像分割的问题。但随着AI技术的发展,UNet能提高图片质量的特性很快就被应用于Stable Diffusion框架,用UNet来提升一张质量不高(带有很多噪声)的图片,并重复数十次这个过程,最终得到一张高质量的结果。
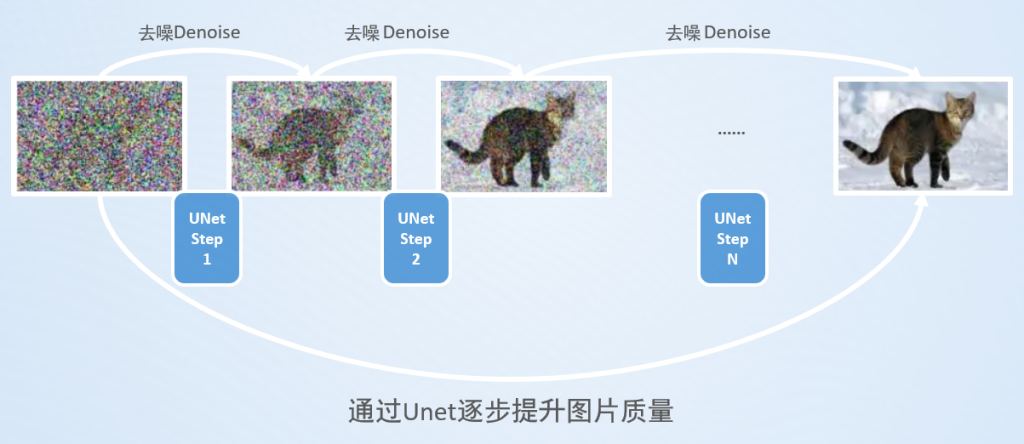
除此之外U-Net在Stable Diffusion中的应用还表现在:
- 细节的捕捉与增强:Stable Diffusion利用U-Net的跳跃连接来维持和增强图像的细节。这些连接允许在生成过程中直接使用来自编码器的高分辨率特征,从而在解码器阶段细化图像的细节。
- 多尺度特征融合:通过U-Net的编码器-解码器结构,Stable Diffusion能够融合不同尺度的特征,这对于生成与文本描述相匹配的复杂图像至关重要。这种结构使模型能够在保持全局一致性的同时,精确控制图像的局部细节。
- 迭代细化:Stable Diffusion在图像生成过程中采用迭代细化的策略,每一步都利用U-Net架构对图像进行进一步的优化和细化。这种方式使得最终生成的图像不仅细节丰富,而且与输入的文本描述高度一致。
VAE是什么?
AE(auto-encoders)自编码器,是一种数据维度压缩算法,能够把高维度的数据通过AE编码(Encoder)将数据压缩成低维空间,比如把3维空间的数据压缩成2为空间的数据。维度下降之后,数据量更小,进行数据计算更加的高效。计算完成之后还可以通过AE解码(Decoder)将低维度数据提升为高维数据。
而VAE(Variational AutoEncoder 变分自编码器)和AE类似,但比AE的更加的先进和复杂。在Stable Diffusion中对于输入的图片,会先用VAE编码器(VAE Encoder)把像素空间中的图片,压缩为潜空间数据,比如下图中通过VAE编码器把512x512的图片压缩后变成了64x64的大小,最后再通过VAE解码器(VAE Decoder)把潜空间中的图片返回成像素空间的大小。
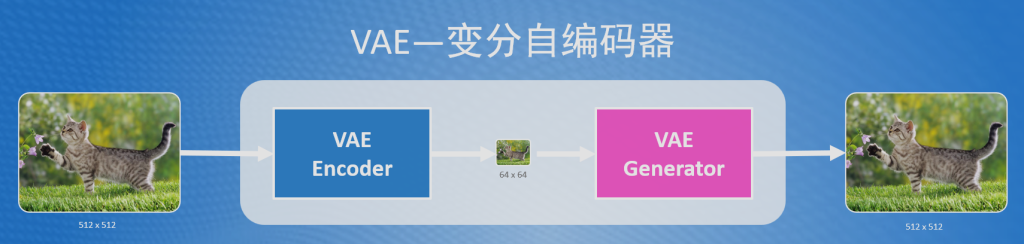
小知识点:
- 在SD中,像素空间中的图片,每个像素点使用RGB3通道(可简单理解成3个数字)来存储其值,因此512x512大小的图片,在SD中存储的大小为512x512x3
- 在SD中,潜空间图片,每个像素点使用RGBA4通道(可以简单理解成4个数字)来存储其值,因此64x64大小的图片,在SD潜空间中实际大小为64x64x4
- 综合上述两点,通过VAE压缩图片后,计算的数据降低了48(512x512x3/64x64x4=48)倍。
深度剖析原理
了解完Clip和UNet之后,我们再来理解Stable Diffusion的底层原理:
- ①、由于SD的输入编码器(InputEncoder)中使用的是OpenAI的Clip模型来理解用户输入的文本,而Clip模型的底层是使用英文进行训练的,所以Clip模型只接收英文文本,即Stable Diffusion只接收英文输入。如果我们想输入中文,那么可以先通过翻译软件进行翻译成英文之后,再输入到SD中。
- ②、输入编码器(InputEncoder)在接收到用户输入的文本之后,会通过ClipText来理解用户输入的信息,并把理解的信息转换为大小为77 x 768的向量。
- Clip模型限制了最多可以输入77个token,可以简单理解成77个单词。Clip模型训练时会把大图片切成16x16大小的小图片,然后在提取小图片中的RGB3个颜色通道的数据,并最终把小图片表示成一个16x16x3=768的向量。同时Clip为了让文本Token能更好的与图片信息关联,因此也把token的向量长度设计为768。

-
- 综上所述,ClipText会把用户输入的文本为77x768大小的向量。
- Clip除了文本(Text)编码器,还有图像(Image)编码器,因此Stable Diffusion除了用文本来创建图之外,还可以使用图片生图片。
- ③、图片生成器(Image Generator)在内部会首先会在潜空间中生成一张随机的图片,这个图片用的4x64x64大小的向量表示,然后接下来就使用UNet来提升这张随机图片的质量,而这个提升图片质量的过程可能需要数十步,因此就引入了Scheduler调度器,来循环提高质量的这个过程,直到设定步数执行完成,则得到一张按文本生成好的潜空间图片。
- ⑤、通过上述对于VAE的了解,我们应该知悉Stable Diffusion为了降低图像生成的数据量,提升图片生成的效率,而选择在潜空间来生成。那个在这个方式下,生成的图片不满足像素空间的大小要求,因此就借助VAE来进行图片的压缩或放大。
Denoise去噪流程
通过上述的了解,不难发现Stable Diffusion在图片生成器中最关键步骤就是Denoise去噪,因此接下来再来了解Denoise去噪的内部流程。
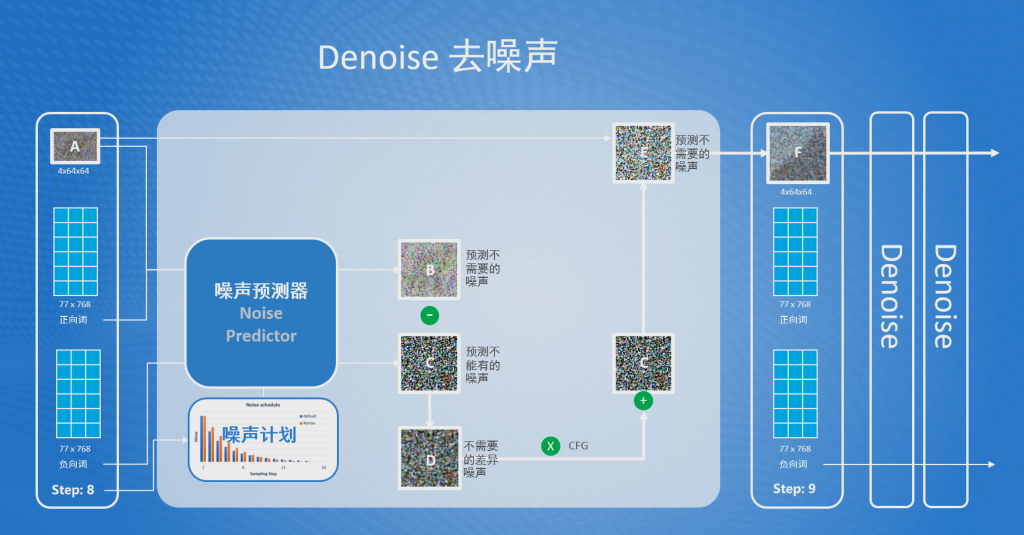
首选在Denoise中有一个核心组件叫Noise Predictor(噪声预测器),Denoise就是通过这个组件来完成降噪的。
-
①、噪声预测器会依据用户输入的正向词和上一步噪声图(A),预测出在噪声图(A)中不需要的噪声图(B);
-
此步注意点:
- 正向词,就是用户输入的文本信息,描述了图片中应该包含哪些内容
- 噪声预测器在预测图片时需要确定噪声强度,这个值是依据依据外部输入的Step(步骤)参数,去噪声计划中获取噪声强度
- 噪声强度:指噪声的数量,越强表示噪声的数量越多。在Stable Diffusion中每次Denoise的噪声强度都不同;
- Step(步骤):就是表示当前是第几次Denoise的数字,主要的作用是通过步骤去噪声计划中获取对应的噪声强度;
- 噪声计划:在生图之前,Stable Diffusion在每次Denoise中设定的噪声强度计划,即为噪声计划,这个计划可以通过不同的算法来设定;
-
②、噪声预测器会依据用户输入的
负向词
,预测出在结果中不能有的噪声图(C);此步注意点:
- 负向词,也是用户输入的文本信息,描述了图片中不能包含的内容
-
③、噪声预测器会把预测的不需要的噪声图(B)减去预测的不能有的噪声图(C),得到不需要的差异噪声图(D);
-
④、噪声预测器接着会把不需要的差异噪声图(D)乘以一个放大系数CFG,以放大差异噪声图的细节。然后再把放大的噪声图与预测不能有的噪声图(C)进行相加,就得到了最终不需要的噪声图(E);CFG: (Classifier Free Guidance)称为无分类引导法,是一种用来让最终生成图像更符合提示词的方法。
-
⑤、最后使用输入的噪声图(A)减去不需要的噪声图(E),即得到一个更高质量的噪声图(F);
通过上述了解之后,我们应该能发现Stable Diffusion生图过程复杂,但幸好这个实现过程只需要我们了解即可,我们重点关注这个过程中涉及的相关术语和参数,比如这小节提到的Step步骤和CFG参数,对其掌握,有助于快速去设置参数,生成高质量的图片。
- Step步骤,值越大生成的图片越细节,但是消耗的计算资源越多;
- CFG,当CFG的值增加时,模型会更多地依赖于条件信息(如文本提示),这通常会导致生成的图像更加紧密地匹配给定的文本描述,从而元素更丰富,风格更一致。然而,过高的CFG值也可能导致图像过度依赖于条件信息,从而失去一些自然性和多样性;
2.Stable Diffusion 客户端
Stable Diffusion主流的客户端有2款,Stable Diffusion WebUI和Comfyui,这两款客户端的功能类似,但是操作方式有所不同。
Comfyui
这两个客户端都可以在低配置的CPU上运行,但是由于Comfyui的配置方式更加简洁,且配置可以重用等特性,我们直接选择使用Comfyui作为我们学习的客户端。
