javase+集合相关面试题
GQ八股-Java基础+集合
java基础
Java中的序列化和反序列化是什么?
序列化:指将一个对象转化为字节流的过程,通常用于存储或者通过网络传输。ObjectOutputStream用于将对象序列化。
反序列化:指将字节流还原为原始对象的过程,使用ObjectInputStream来实现。
关键要求:
- Serializable接口:类必须实现
Serializable接口,才能被序列化。 - transient关键字:标记为
transient的字段会被序列化时忽略。 - serialVersionUID:每个类应定义
serialVersionUID,用于验证序列化和反序列化版本一致性。 - 性能与安全:序列化可能导致性能下降,同时反序列化存在安全风险(例如反序列化攻击),因此需要对输入数据进行验证。
- 静态变量:静态变量不会被序列化,因为它们与实例无关。
总结:序列化和反序列化为Java对象的存储和传输提供了便利,但需要关注性能和安全性问题。
Exception 和 Error 的区别
Exception 和 Error 都是 Throwable 的子类,
区别在于:
- Exception 表示程序可以处理的异常,比如业务逻辑错误、文件找不到等。
- Error 表示系统层面的严重错误,比如内存溢出(OutOfMemoryError)或栈溢出(StackOverflowError),程序一般无法恢复。
Exception 又分为两类:
- Checked Exception(受检异常):编译期必须处理,比如 IOException;
- Unchecked Exception(运行时异常):运行期才抛出,比如 NullPointerException。
通常我们只捕获 Exception,不处理 Error。
如果面试官追问
Q:那为什么 Error 不推荐捕获?
因为 Error 通常由 JVM 抛出,代表系统层问题,程序恢复不了,捕获也没意义。比如堆内存溢出时,就算 catch 了也无法分配对象继续运行。
Q:Exception 和 RuntimeException 的关系呢?
RuntimeException 是 Exception 的子类,它代表运行时异常,不需要强制 try-catch,比如空指针、数组越界。
Java的优势
- 跨平台性
Java的“写一次,运行多平台”特性通过JVM(Java虚拟机)实现,保证了Java程序能够在不同操作系统上运行,不需要针对每个系统重新编译。 - 垃圾回收
Java提供了自动垃圾回收功能(GC),可以管理内存的分配与回收,减轻了开发者的负担,且不需要手动释放内存,避免了内存泄漏问题。 - 生态系统
Java有强大的生态支持,包括丰富的第三方库、工具、框架和资源,使开发更加高效,适用的领域广泛。 - 面向对象
Java采用面向对象的编程模型,支持继承、多态、封装等特性,代码易于维护和扩展,提升了开发效率和系统的可维护性。
这些特点使Java成为了一个高度可移植、可靠并且在企业级开发中广泛应用的语言。
java中的多态特性
Java 多态特性:
Java 的多态是指同一方法在不同的对象上执行时,表现出不同的行为。它是面向对象编程的核心特性之一,通过方法重载和方法重写来实现。主要有两种类型:
- 编译时多态(方法重载):
- 同一个类中,可以定义多个同名的方法,但是它们的参数列表(参数的数量、类型或顺序)必须不同。
- 这种多态性是在编译阶段决定的,编译器会根据方法的参数类型来决定调用哪个版本的重载方法。
- 运行时多态(方法重写):
- 子类继承父类,并可以重写父类的方法,运行时决定具体调用哪个类的方法。
- 这种多态性发生在程序运行时,当父类引用指向子类对象时,实际执行的是子类的重写方法。
多态的优点:
- 代码的可扩展性:可以编写更灵活的代码,减少重复代码。
- 解耦:通过接口或继承来解耦代码,易于修改和维护。
面试中简洁回答:
Java 多态是指同一个方法调用,在不同的对象上会产生不同的执行效果。它主要分为编译时多态(方法重载)和运行时多态(方法重写)。编译时多态通过方法的参数差异来决定调用哪个方法,而运行时多态通过子类重写父类的方法来决定实际调用的版本。
java中的参数传递是按值还是按引用
在Java中,方法参数的传递是基于“值传递”机制的,但这里有一些细节需要注意:
- 对于基本数据类型(例如
int,char,boolean),参数传递的是值的副本,因此修改副本不会影响原始变量。 - 对于引用数据类型(如类的实例),传递的是对象的引用,也就是对象的内存地址。在方法内部修改对象的属性会影响原始对象,但无法改变引用,使得引用指向另一个对象。
总结来说,Java中方法参数的传递是值传递,但对于对象引用来说,实际上是传递引用的副本,所以能修改对象的内容,但不能修改引用本身。
为什么java不支持多重继承
Java不支持多重继承的主要原因是避免“钻石问题”,即当一个类继承了多个父类,并且这些父类有相同的方法或属性时,会导致冲突。为了防止这种复杂性,Java选择了单继承模型。通过接口(interface)提供了灵活的多继承方式,允许一个类实现多个接口,从而避免了传统多继承的缺点。
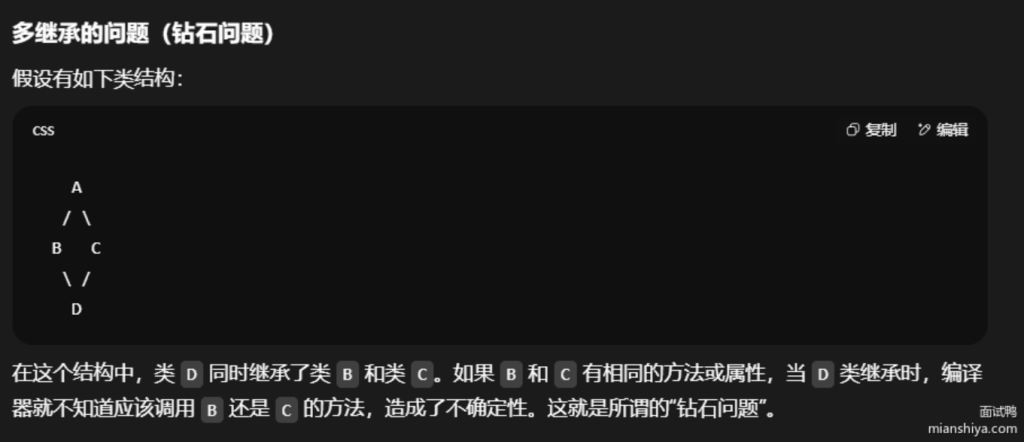
java面向对象编程与面向过程编程的区别是什么
在Java中,面向过程编程和面向对象编程的区别,主要体现在思维方式和代码组织方式上。
- 面向过程编程(Procedure-Oriented Programming)
它以“过程”为核心,把程序看作一系列顺序执行的步骤,强调“先做什么、再做什么”。程序的基本单元是函数或过程,更关注执行的流程和算法逻辑,适合用来处理结构简单、流程清晰的任务。
举个例子,我们要写一个“煮咖啡”的程序,面向过程的思路可能是:
-
打开咖啡机;
-
加水;
-
加咖啡粉;
-
煮咖啡;
-
倒出咖啡。
整个过程就像一条流水线,关注的是步骤和执行顺序。
- 面向对象编程(Object-Oriented Programming, OOP)
它以“对象”为核心,将数据和操作数据的方法封装在一起,程序的基本单元是对象。OOP更注重封装、继承、多态等特性,强调代码的复用性、可扩展性和灵活性。
如果用面向对象的方式来实现“煮咖啡”,我们会先抽象出对象,比如“人”和“咖啡机”。
-
“人”负责发出“煮咖啡”的指令;
-
“咖啡机”对象内部封装了加水、加豆、加热等方法。
-
当人调用咖啡机的 makeCoffee() 方法时,内部会自动完成一系列步骤。这样,代码更清晰、更易维护,也便于后期扩展,比如增加“加奶”“打泡”等新功能。
总结来说:
-
面向过程关注“做事的步骤”,适合小型、简单的任务;
-
面向对象关注“谁来做这件事”,更适合复杂、可扩展的系统开发。
Java作为典型的面向对象语言,正是通过“封装、继承、多态”这些特性,让开发者能够更高效地管理复杂业务逻辑。
- 一句总结:
“面向过程关注流程,面向对象关注对象。前者适合解决问题,后者适合构建系统。就像煮咖啡——面向过程一步步写流程,而面向对象则让‘咖啡机对象’自己完成整个动作。”
Java 方法重载和方法重写之间的区别是什么?
Java 里的 重载(Overload) 和 重写(Override) 最大区别在于:
- 重载 **发生在同一个类中,方法名相同但参数不同(**类型、数量或顺序不同),和返回值无关,主要用于提高代码的灵活性,比如构造函数的重载。
- 而 重写 发生在父类和子类之间,子类对父类方法进行改写或扩展以实现多态。重写要求方法名、参数列表都相同,返回值类型相同或是其子类,访问修饰符权限不能更低。
此外,private、static、final 方法不能被重写。
| 对比项 | 方法重载(Overload) | 方法重写(Override) |
|---|---|---|
| 定义 | 在同一个类中定义多个同名方法,参数列表不同 | 在子类中重写父类的方法,以实现多态 |
| 发生位置 | 同一个类中 | 父类与子类之间 |
| 参数列表 | 必须不同(类型、数量、顺序至少有一处不同) | 必须完全相同 |
| 返回值类型 | 可以不同(但仅靠返回值不同不能构成重载) | 必须相同,或是父类返回值的子类(协变返回类型) |
| 访问修饰符 | 无限制 | 子类重写方法的访问权限不能低于父类方法 |
| 异常声明 | 可随意定义 | 子类方法抛出的异常不能比父类更宽泛 |
| static / final / private 方法 | 可以被重载 | 不能被重写(static 是隐藏,final/private 无法重写) |
| 调用方式 | 由编译器在编译时确定(编译时多态) | 由 JVM 在运行时动态绑定(运行时多态) |
| 目的 | 提高代码灵活性和可读性(同一功能不同实现) | 实现多态性,让子类定制父类行为 |
| 示例 | void print(int a) vs void print(String s) |
子类重写 void eat() 改变父类默认实现 |
重载是编译时多态,同类中同名不同参;
重写是运行时多态,子类改写父类方法,方法名与参数都必须一致。
什么是 Java 内部类?它有什么作用?
Java 内部类是定义在另一个类中的类,根据定义位置不同分为四种:成员内部类、静态内部类、局部内部类和匿名内部类。
- 成员内部类可以访问外部类的所有成员,包括 private;
- 静态内部类只能访问外部类的静态成员;
- 局部内部类定义在方法中,只在方法内部可见;
- 匿名内部类没有类名,常用于接口回调或事件处理。
| 类型 | 定义位置 | 可访问范围 | 是否有类名 | 常见用途 |
|---|---|---|---|---|
| 成员内部类 | 外部类中,非静态位置 | 可访问外部类所有成员(含 private) | 有 | 外部类与内部类强关联时使用 |
| 静态内部类 | 外部类中,static 修饰 | 只能访问外部类静态成员 | 有 | 辅助逻辑类,不依赖外部类实例 |
| 局部内部类 | 方法或代码块中定义 | 可访问 final 或 effectively final 的局部变量 | 有 | 临时逻辑封装 |
| 匿名内部类 | 无类名,直接定义实例 | 同局部类 | 无 | 简化接口实现或回调逻辑 |
它的主要作用是提高封装性和代码内聚性,并且在只在一个地方使用的情况下可以简化代码结构。
速答版:
Java 内部类就是定义在类内部的类,分为成员内部类、静态内部类、局部内部类和匿名内部类。
它能访问外部类的成员,提高封装性和内聚性,常用于回调、事件处理等场景。
Java8 有哪些新特性?
Java 8 是一次非常重要的版本更新,引入了很多影响后续生态的特性。
-
最核心的是 Lambda 表达式 和 函数式接口,让 Java 能以更简洁的方式实现函数式编程;
-
然后是 Stream API,可以用链式操作来处理集合,比如过滤、排序、映射这些操作,代码更优雅;
-
还新增了 接口的默认方法和静态方法,让接口在扩展时不破坏原有实现;
-
同时引入了 全新的日期时间 API(LocalDate、LocalTime、LocalDateTime),解决了老的 Date 不可变与线程安全问题;
-
在内存管理方面,用 元空间(Metaspace)替代了永久代(PermGen),解决了内存不足和 GC 效率低的问题;
-
此外还有 Optional 类 避免空指针,CompletableFuture 和 StampedLock 等并发增强类,以及 :: 方法引用语法。
可以说 Java8 的这些改进让代码更简洁、更安全,也为后续的响应式编程打下了基础。
速答版:
Java8 的主要新特性有 Lambda 表达式、Stream API、接口默认方法、新日期时间 API、Optional 类,以及用元空间替代永久代。这些特性让 Java 更简洁、更高效、更现代化。
Java 中 String、StringBuffer 和 StringBuilder 的区别是什么?
String、StringBuffer、StringBuilder用于表示一串字符,即字符序列。StringJoiner是JDK8引入的一个String拼接工具
在 Java 中,String、StringBuffer 和 StringBuilder 的主要区别在于可变性、线程安全性和性能。
首先,String 是不可变的,底层用 final char[] 修饰,每次修改都会创建新的对象,所以适合字符串内容不频繁变化的场景,比如常量池或日志输出。
而 StringBuffer 和 StringBuilder 都是可变的,修改内容不会新建对象,底层通过 append() 来操作。
不同的是,StringBuffer 是线程安全的,因为内部方法使用了 synchronized,适合多线程环境下的字符串操作;
StringBuilder 则是非线程安全的,但没有同步锁,性能更高,适合单线程环境。

总结一句话:String 用于少变内容,StringBuffer 多线程改字符串,StringBuilder 单线程拼接最快。
速答版:
- String 不可变,线程安全;
- StringBuffer 可变、线程安全、性能一般;
- StringBuilder 可变、线程不安全,但性能最好。
Java 的 StringBuilder 是怎么实现的?
StringBuilder 的底层是通过一个 可变的 char 数组 来存储字符序列的。
和 String 不同的是,String 的底层也是 char[],但被 final 修饰且是私有的,所以内容不可变;而 StringBuilder 没有这个限制。
当我们调用 append()、insert() 等方法时,StringBuilder 会 直接修改底层字符数组的内容,而不是像 String 那样创建新对象。
如果数组容量不够,会通过 Arrays.copyOf() 扩容,扩容规则是:新容量 = 旧容量 × 2 + 2,这样可以减少扩容次数、提升性能。
另外,它的所有方法没有加同步锁,所以是 线程不安全 的,但单线程下性能最好。
速答版:
StringBuilder 底层是可变的 char[],通过 append 直接修改,不会创建新对象;容量不足时会按 2 倍加 2 扩容;线程不安全但性能最好。
Java 中包装类型和基本类型的区别是什么?
在 Java 中,基本类型和包装类型的区别主要体现在 性能、存储、比较方式和默认值 这几个方面。
-
首先,基本类型 不是对象,占用内存小、效率高,适合频繁使用的简单运算;
包装类型 是对象,会涉及堆内存分配和垃圾回收,性能相对低。 -
在比较时,基本类型用 == 比较数值,而包装类型的 == 比较的是地址,若要比较内容要用 equals()。
-
默认值也不同:基本类型如 int 默认是 0,boolean 默认 false,而包装类型的默认值是 null。
-
存储上,基本类型作为局部变量存在线程栈中,若是成员变量则在堆中;包装类型一定是对象,存在堆上。
总结一句话:基本类型轻量高效,包装类型更灵活但开销更大。
速答版:
基本类型存数值、效率高、不占内存;包装类型是对象,占堆内存、支持泛型和 null。
比较上一个比值、一个比地址,默认值也不同:0 vs null。
附上对比表
| 对比项 | 基本类型(Primitive) | 包装类型(Wrapper) |
|---|---|---|
| 定义位置 | 位于 JVM 基本数据类型体系(如 int、double) | 位于 java.lang 包下的类(如 Integer、Double) |
| 是否对象 | ❌ 不是对象 | ✅ 是对象(继承自 Object) |
| 存储位置 | 局部变量在栈上,成员变量在堆上 | 永远在堆中(对象引用存于栈上) |
| 默认值 | 数值型为 0,布尔型为 false |
全部为 null |
| 比较方式 | == 比较值 |
== 比较地址,equals() 比较值 |
| 性能表现 | 占用内存小、执行快 | 占用内存大、执行慢(涉及 GC) |
| 用途场景 | 常用于数值计算、频繁运算 | 适用于集合框架(如 List |
| 初始化方式 | 直接赋值(如 int a = 1;) |
需 new 或自动装箱(如 Integer a = 1;) |
| 可空性 | ❌ 不能为 null | ✅ 可为 null |
| 泛型支持 | ❌ 不支持泛型 | ✅ 可用于泛型(例如 List<Integer>) |
接口和抽象类有什么区别?
为什么 Java 要同时存在抽象类和接口?它们在设计思想上分别解决了什么问题?
我们从语法 + 思想 + 场景 三层逻辑来回答
概念层(简述区别)
抽象类是对事物共性的抽象,可以包含属性和方法;
接口是对行为规范的抽象,更关注对象能做什么。
语法层(核心对比表)
| 对比点 | 抽象类(abstract class) | 接口(interface) |
|---|---|---|
| 继承实现 | 单继承 | 多实现 |
| 成员内容 | 可有属性、构造方法、普通方法、抽象方法 | 仅能有常量和方法(JDK8 起可有默认方法、静态方法,JDK9 可有私有方法) |
| 设计定位 | 模板:抽象出相同部分,提高复用 | 协议:定义行为规范,解耦调用方与实现方 |
| 访问修饰 | 可有各种修饰符 | 默认 public、static、final(常量) |
| 场景 | 父类通用功能扩展 | 不同类的行为统一 |
思想层
抽象类体现的是模板复用思想,
接口体现的是解耦和规范思想。
举个例子
比如我们有 Bird、Airplane、Superman 都能飞。
- 它们的“飞”是一种行为能力,应该定义在接口 Flyable 中(规定必须实现 fly())。
- 而“鸟类”有共同特征,比如翅膀、吃虫等,就应该抽象为一个抽象类 Bird,让子类继承它共享实现。
所以接口是「能做什么」,抽象类是「是什么 + 怎么做」。
一句话总结
抽象类和接口最大的区别在于“目的”。
- 抽象类是对类的共性抽象,可以包含属性和方法,强调复用;
- 接口是对行为的抽象,强调规范与解耦。
比如我们有 Bird、Airplane、Superman 都能飞。
- 它们的“飞”是一种行为能力,应该定义在接口 Flyable 中(规定必须实现 fly())。
- 而“鸟类”有共同特征,比如翅膀、吃虫等,就应该抽象为一个抽象类 Bird,让子类继承它共享实现。
所以接口只关注「能做什么」,抽象类则关注「是什么 + 怎么做」。
抽象类解决代码复用问题,接口解决多继承和行为统一问题。
一句话:抽象类是模板,接口是契约。
JDK 和 JRE 有什么区别?
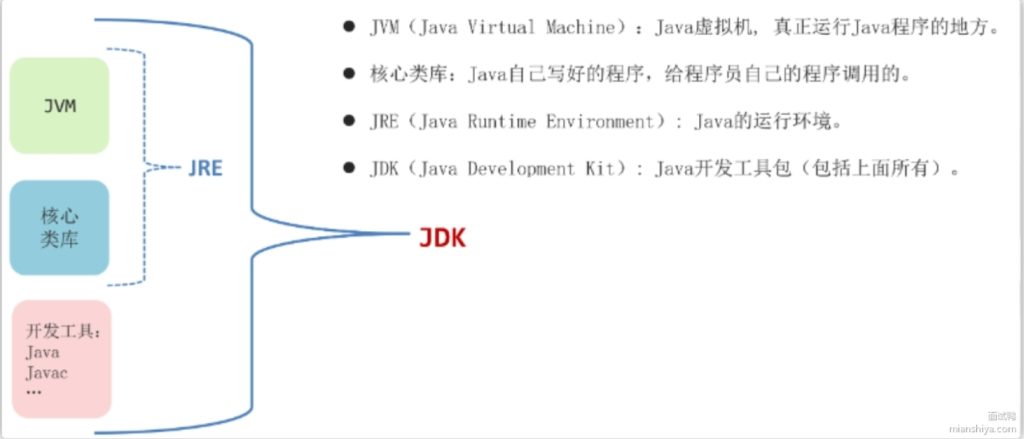
你使用过哪些 JDK 提供的工具?
| 分类 | 工具 | 功能简述 |
|---|---|---|
| 基础开发工具 | javac |
Java 编译器,将 .java 源码编译为 .class 字节码 |
java |
运行 Java 应用的命令,启动 JVM | |
javadoc |
根据注释生成 API 文档 | |
jar |
打包/解压 JAR 文件 | |
jdb |
Java 调试工具,命令行调试、断点、变量查看 | |
| 性能监控与分析工具 | jps |
查看当前正在运行的 Java 进程 |
jstack |
查看线程堆栈,用于分析死锁和卡顿 | |
jmap |
导出内存映射(heap dump)文件,分析内存泄漏 | |
jhat |
堆分析工具,配合 jmap 使用 |
|
jstat |
JVM 统计监控工具(GC 次数、加载类数等) | |
jconsole |
图形化 JVM 监控工具 | |
jvisualvm |
综合性能分析工具(线程、GC、CPU 等) | |
| 诊断与远程工具 | jinfo |
查看和调整 JVM 参数 |
jstatd |
远程 JVM 监控守护进程 |
但面试官想听到的不是“你会背”,而是“你会用”
所以不要机械背诵工具清单,而要讲出你真的用过、解决过问题的场景。
我平时在开发和排查问题时用过一些 JDK 自带的工具。
- 首先是开发类工具,比如 javac、java、jar、javadoc 这些是日常必用的。
- 其次是性能排查类工具:
- 我常用 jps 查看运行中的 Java 进程;
- 遇到线程死锁或 CPU 占用高时,会用 jstack 导出线程堆栈排查问题;
- 如果怀疑内存泄漏,会通过 jmap -dump 导出堆文件,然后用 jvisualvm 或 Eclipse MAT 分析;
- GC 频繁或 Full GC 慢的时候,我会用 jstat -gc 实时观察垃圾回收情况。
- 最后是调优与监控类:
我也用过 jconsole 和 jvisualvm 做 JVM 性能监控,比如查看线程数量、内存占用、GC 情况等。
补充
如果被问:“那你更喜欢哪个工具?”
- 可以说:jvisualvm 因为它图形化、集成度高、可以远程连接。
如果被问:“这些工具和 Arthas、SkyWalking 有什么区别?”
- 可以说:JDK 工具偏底层调试,而 Arthas / SkyWalking 更适合线上系统监控和诊断。
Java 中 hashCode 和 equals 方法是什么?它们与 == 操作符有什么区别?
在 Java 中:
- == 比较的是两个引用是否指向同一个对象;
- equals() 用于比较对象的内容是否相等,很多类(比如 String、Integer)都重写了它;
- hashCode() 用于计算对象的哈希值,在 HashMap、HashSet 等集合中定位元素。
实际上,equals() 与 hashCode() 有一致性要求——如果两个对象相等,它们的哈希码必须相同,否则会导致哈希集合中无法正确识别重复元素。
一句话总结:
== 比“是不是同一个对象”,equals 比“内容”,hashCode 用来“快速查找”。
Java 中的 hashCode 和 equals 方法之间有什么关系?
- 概念简述
在 Java 中,equals() 和 hashCode() 是判断对象相等性的重要方法,
它们在基于哈希的数据结构(如 HashMap、HashSet)中共同决定了对象的存取行为。
2. 关系规则(必须背熟)
它们之间遵循一致性约定(Contract):
- 如果两个对象通过 equals() 相等,那么它们的 hashCode() 必须相等。
- 但如果 hashCode() 相等,equals() 不一定相等(可能是哈希冲突)。
- 同一个对象多次调用 hashCode(),在程序运行期间必须返回同一个值。
一句话总结:equals 决定“逻辑相等”,hashCode 决定“存储位置”。
- 为什么要重写 hashCode()
如果我们只重写了 equals() 而没有重写 hashCode(),
那么即使两个对象在逻辑上相等,哈希集合(HashSet/HashMap)也会认为它们是两个不同对象。
这会导致:
- HashSet 出现重复数据;
- HashMap 的 key 无法正确覆盖旧值;
- contains()、remove() 等操作失败。

4. 总结一句话
- equals() 决定对象“是否相等”,
- hashCode() 决定对象“放在哪”。
两者必须一起重写,才能保证基于哈希的集合正确工作。
面试时口语答题版
在 Java 中,equals() 和 hashCode() 是判断对象相等性的两个核心方法。
equals() 判断两个对象的内容是否相等,hashCode() 用于计算对象在哈希结构中的位置。
它们之间有一致性约定:如果两个对象 equals() 相等,它们的 hashCode() 必须相等,否则在 HashMap 或 HashSet 中会出现定位错误。
比如我们定义了自定义类做 HashSet 的 key,只重写 equals() 不重写 hashCode(),会导致集合中出现重复数据。
因此,重写 equals() 时必须同时重写 hashCode(),保证逻辑相等和哈希一致。
什么是 Java 中的动态代理?
动态代理是 Java 提供的一种在运行时动态创建代理对象的机制。
它允许我们在不修改目标对象代码的情况下,对方法调用进行增强,比如添加日志、权限验证或事务控制。
Java 中主要有两种实现方式:一种是基于接口的 JDK 动态代理,另一种是基于继承的 CGLIB 动态代理。
JDK 代理通过 InvocationHandler 拦截方法调用;CGLIB 通过生成目标类的子类实现。
它的核心作用是让代码更灵活、更解耦,也是 Spring AOP 的基础。
延伸
问1:动态代理底层是怎么生成类的?
答:JDK 动态代理会在运行时使用 ProxyGenerator 生成 $Proxy0.class 字节码文件,然后由 ClassLoader 加载到内存中。
问2:Spring 是用哪种?
答:Spring AOP 优先使用 JDK 动态代理;如果目标类没有接口,则自动切换到 CGLIB。
JDK 动态代理和 CGLIB 动态代理有什么区别?
JDK 动态代理是基于接口的实现,通过反射机制在运行时生成代理类,并通过 InvocationHandler 调用目标对象的方法。
它只能代理实现了接口的类。
CGLIB 动态代理是基于继承机制的,通过 ASM 字节码生成技术创建目标类的子类来实现代理,
因此可以代理没有接口的普通类,但不能代理被 final 修饰的类或方法。
在 Spring AOP 中,如果目标类实现了接口,会优先使用 JDK 动态代理,否则自动切换到 CGLIB。
性能上 JDK8 后两者几乎没有差别。
总结口诀
| 口诀 | 含义 |
|---|---|
| “接口用 JDK,类用 CGLIB” | 代理对象类型区分 |
| “继承受限 final,接口灵活无限” | 限制区别 |
| “JDK 反射调,CGLIB 生成类” | 实现原理 |
| “AOP 双轮驱动,版本无性能坑” | 框架应用 |
Java 中的注解原理是什么?
注解是 Java 提供的一种元数据机制,用于在代码中添加结构化信息。
它本质上是继承自 Annotation 接口的特殊接口,编译器会将注解信息写入字节码文件中。
在运行时,可以通过反射机制读取这些元数据,完成如依赖注入、配置映射等逻辑。
根据保留策略不同,注解分为编译期(SOURCE、CLASS)和运行期(RUNTIME)。
运行期注解是框架如 Spring、MyBatis 的核心机制。
总结口诀
| 口诀 | 含义 |
|---|---|
| “注解是标记,反射是钥匙” | 反射是读取注解的关键 |
| “保留到运行期,反射能识别” | 只有 RUNTIME 才能反射读取 |
| “编译做检查,运行做增强” | 区分注解用途 |
| “框架靠注解,灵魂是反射” | 框架底层实现原理 |
你使用过 Java 的反射机制吗?如何应用反射?
Java 的反射机制是指在运行时动态获取类的结构信息(包括属性、方法、构造器等),并能对对象进行动态创建、访问和修改的机制。
它的核心类包括 Class、Method、Field、Constructor。
-
反射的最大优点是灵活性强,不需编译期确定类型,很多框架如 Spring、MyBatis、Junit 都依赖它实现依赖注入和动态代理。(框架三件套 = 反射 + 动态代理 + 注解。)
-
缺点是性能较低、安全性降低,但可以通过缓存 Method 对象或使用 MethodHandle 来优化性能。
小结:
Java 的反射机制是一种在运行时动态获取类信息并操作对象的机制,是 Spring、MyBatis 等框架的核心基础,但要注意性能与安全性问题。
补充: 反射常用操作代码示例:
1 | // 1. 获取类对象的三种方式 |
什么是 Java 中的不可变类?
不可变类(Immutable Class)是指对象一旦被创建,其状态(成员变量)就不能被修改的类。
一旦初始化完成,对象的属性在整个生命周期中都保持不变,例如 String、Integer、BigDecimal 等。
不可变类的核心特征:
| 特征 | 说明 |
|---|---|
1️⃣ 类必须用 final 修饰 |
防止被继承后修改行为 |
2️⃣ 所有字段必须是 private 且 final |
防止外部直接修改属性 |
| 3️⃣ 不提供任何 setter 方法 | 确保状态一经初始化无法改变 |
| 4️⃣ 所有可变对象字段必须防御性复制 | Getter 返回副本,防止外部修改原对象 |
| 5️⃣ 通过构造函数初始化全部属性 | 保证对象在创建时即处于完整状态 |
面试回答:
不可变类是指对象在创建后,其状态就不能再被修改的类。
类通常被声明为 final,所有成员变量是 private final,并且没有 setter 方法。
如果类包含可变对象字段,需要通过防御性复制来保护内部状态不被外部修改。
不可变类的典型例子有 String、Integer、BigDecimal 等。
它们的优点是线程安全、可缓存、调试简单;
缺点是频繁修改会产生大量中间对象,浪费内存。
什么是 Java 的 SPI(Service Provider Interface)机制?
Java 的 SPI(Service Provider Interface)是一种服务发现机制,
用于在运行时动态加载接口的不同实现类,实现系统解耦与模块化扩展。
它的核心是通过接口定义规范,第三方在 META-INF/services 目录下注册实现类,
由 ServiceLoader 在运行时自动发现并加载这些类。
SPI 的典型应用是 JDBC、Dubbo、SLF4J 等。
优点是扩展性强、解耦好;缺点是性能较低且无法动态刷新。
-
一句话总结:
Java SPI 是一种运行时加载第三方实现类的机制,
通过接口 + 配置文件 + ServiceLoader 实现解耦与可插拔扩展,
是 Java 框架(如 JDBC、Dubbo、Spring Boot Starter)底层的重要基础。 -
一句话概括了 SPI 和 API 的区别:
“API 是我提供接口和实现,SPI 是我提供接口,别人实现。”
Java 泛型的作用是什么?
Java 泛型的作用主要有三点:
第一,类型安全,它可以在编译阶段检查类型,避免运行时 ClassCastException(类型转换异常);
第二,代码重用,通过泛型类和泛型方法,可以让同一份代码适用于多种数据类型;
第三,消除显式类型转换,取出集合元素时不需要再手动强制类型转换,代码更简洁安全。
泛型只在编译期有效,编译后会进行“类型擦除/泛型擦除”,JVM 实际运行时使用的是原始类型(如 Object),所以泛型不会影响程序运行效率,只是提供编译期的安全检查。
Java 泛型擦除是什么?
定义:
泛型擦除(Type Erasure)是 Java 编译器在编译阶段执行的一种机制,
它会在生成字节码时移除所有泛型类型信息,
将类型参数替换为其限定类型(上界),
若无上界则替换为 Object,以保证运行时与非泛型代码的兼容性。
作用:
- 保持向下兼容(与 Java 5 之前版本兼容);
- 减少 JVM 的复杂性(运行时不需要泛型类型检查);
影响:
- 运行时无法获取泛型实际类型(List
和 List 在运行时完全相同); - 无法直接创建泛型数组或进行泛型类型判断;
- 反射只能获取泛型声明信息,不能获取运行时真实类型。
什么是 Java 泛型的上下界限定符?
Java 泛型的上下界限定符用于约束泛型参数的取值范围。
- ? extends T 表示泛型类型必须是 T 或 T 的子类,常用于“只读”场景,保证读取时类型安全。
- ? super T 表示泛型类型必须是 T 或 T 的父类,常用于“只写”场景,保证插入时类型安全。
它们遵循 PECS 原则(Producer Extends, Consumer Super):
- 生产者用 extends,消费者用 super。
1 | List<? extends Number> list1 = new ArrayList<Integer>(); // 只能读 |
Java 中的深拷贝和浅拷贝有什么区别?
在 Java 中,拷贝分为浅拷贝和深拷贝:
- 浅拷贝 只复制对象的基本类型字段,对于引用类型字段只复制引用地址,新旧对象共享同一堆内实例,因此修改一个对象会影响另一个。
- 深拷贝 不仅复制对象本身,还会递归复制其引用对象,两个对象完全独立,互不影响。
Java 默认的 clone() 方法是浅拷贝,如需深拷贝可通过手动实现 clone()、对象序列化或工具类来完成。
用一个例子可以更好的理解-身份证复印件 vs 克隆人 :
| 类型 | 说明 |
|---|---|
| 浅拷贝 | 复印了身份证。看起来信息一样(名字、地址相同),但你拿复印件去办事,所有操作其实都还是对“原人”生效。 |
| 深拷贝 | 造了一个“克隆人”,这个人和你一模一样(数据完全复制),但独立存在。他改发型、搬家都不会影响你。 |
浅拷贝:两个人共用一个脑袋。
深拷贝:每个人有自己的脑袋。
什么是 Java 的 Integer 缓存池?
Java 的 Integer 缓存池是为了节省内存和提升性能而设计的。
在 -128 ~ 127 范围内的 Integer 对象会被缓存并复用,
当自动装箱或调用 Integer.valueOf() 时,若值在此范围内,会直接返回缓存对象,而不是新建。
若使用 new Integer() 或超出该范围,则会创建新对象。
缓存池通过静态内部类 IntegerCache 实现,范围可通过 JVM 参数调整。
补充:
面试陷阱题
1 | Integer a = 127; |
原因:
- 127 在缓存范围内 → a、b 引用同一对象
- 128 超出缓存范围 → c、d 各自新建对象
Java 的类加载过程是怎样的?
Java 类加载分为三个主要阶段:加载、链接和初始化。
其中“链接”又分为 验证、准备、解析 三个子阶段。
- 加载阶段:把类字节码加载进内存,生成 Class 对象;
- 验证阶段:确保字节码符合 JVM 规范;
- 准备阶段:为静态变量分配内存并赋默认值;
- 解析阶段:把符号引用替换为直接引用;
- 初始化阶段:执行静态变量赋值与静态代码块逻辑。
最终类就可以被 JVM 使用。
总结口诀(方便背诵)
加载 → 验证 → 准备 → 解析 → 初始化
简称:“加 验 准 解 初”
口诀记法:
加载类进内存,验证格式真;
准备分配值,解析换引用;
初始化执行码,一切都齐全。
什么是 Java 的 BigDecimal?
BigDecimal 是 Java 提供的用于高精度小数计算的类,属于 java.math 包。
它能避免 float 和 double 的精度误差,常用于金融、结算等高精度场景。
BigDecimal 是不可变类,每次运算都会生成新的对象,提供加减乘除、比较、取整等方法,
并支持多种舍入模式(如四舍五入 HALF_UP)。
建议使用字符串构造方法以避免精度丢失。
BigDecimal 为什么能保证精度不丢失?
BigDecimal 之所以能保证精度不丢失,是因为它采用了 任意精度的整数表示法,
BigDecimal 通过将数值部分(intVal)和小数位数(scale)分开存储,
在计算时进行整数运算,最后通过 scale 调整小数点位置,避免了二进制浮点表示导致的精度丢失。
使用 new String(“abc”) 语句在 Java 中会创建多少个对象?
答:其实啊,new String(“abc”) 这句代码最多会创建两个对象,最少创建一个对象。
我这么解释你就懂了:
首先,Java 里有个字符串常量池(String Pool),JVM 在看到 “abc” 这个字面量的时候,会先去常量池里看看有没有 “abc” 这个字符串。
- 如果已经有了,那就直接用,不再创建;
- 如果还没有,那 JVM 就会在常量池里先放一个 “abc”。
接着呢,new String(“abc”) 这个操作,
一定会在堆内存(Heap)里再创建一个新的对象,这个新对象的内容就是拷贝常量池里的 “abc”。
所以最后的情况是:
- 如果 “abc” 在常量池里早就存在了 → 只在堆中创建 1 个对象;
- 如果 “abc” 在常量池里是第一次出现 → 会创建 2 个对象(常量池 1 个 + 堆里 1 个)。
一句话总结:
new String(“abc”) 至少创建一个对象,最多两个。
常量池管字面量,堆内存管 new 出来的对象。
Java 中 final、finally 和 finalize 各有什么区别?
final ->修饰符(防修改):final 可以修饰类、方法、变量,意思是“不能再改了”。
finally ->异常处理语句块(保证执行):finally 一定会和 try-catch 一起出现,无论是否发生异常,finally 块里的代码都会执行。
finalize() -> 对象回收前的“遗言方法”(已过时):finalize() 是 Object 类的一个方法,当垃圾回收器(GC)准备回收对象时,会调用它来让对象“临终清理”。(不推荐使用,因为 JVM 不保证它什么时候执行,甚至可能根本不执行。)
为什么在 Java 中编写代码时会遇到乱码问题?
其实 Java 出现乱码,最根本的原因就是——编码和解码方式不一致。
比如写文件的时候用 UTF-8,但读的时候用 GBK,那 JVM 就会把字节解释错,原本的中文就变成了乱码。
常见的情况有三种:
- 默认编码不同(Windows 是 GBK,Linux 是 UTF-8);
- 文件流读写没指定编码;
- 数据库字符集不统一。
只要统一用 UTF-8 就行,编码、解码、数据库都保持一致就不会乱。
为什么 JDK 9 中将 String 的 char 数组改为 byte 数组?
JDK 9 把 String 的底层从 char[] 换成了 byte[]
- 因为char数组,每个字符占用2个字节,但实际上,大量字符串(比如英文、数字、符号)只需要 1 个字节。这就造成空间浪费。
- 改用了byte数组后,通过一个 coder 字段来标记编码方式(0 → LATIN1(单字节),1 → UTF-16(双字节)),JVM 会根据字符串内容自动选择合适的编码。
这样英文只占 1 字节,中文用 2 字节,不但省了一半内存,还提升了性能
如果一个线程在 Java 中被两次调用 start() 方法,会发生什么?
- 一个线程在 Java 中只能启动一次。调用 start() 后,线程状态会从“新建”(NEW)变成“就绪”(RUNNABLE),再由 JVM 调度执行。
- 如果再次调用 start(),线程已经不是新建状态了,JVM 就会抛出IllegalThreadStateException,因为线程生命周期是单向的,不能重复启动。
栈和队列在 Java 中的区别是什么?
栈和队列的主要区别在于数据的进出顺序。
栈是后进先出(LIFO),像叠盘子,最后放上去的先拿走;
队列是先进先出(FIFO),像排队买票,先来的人先走。
在 Java 里,Stack 类实现了栈结构,现在更推荐用 Deque。
队列则由 Queue 接口实现,比如 LinkedList、PriorityQueue。
栈常用于函数调用、递归、表达式求值;
队列常用于任务调度、消息队列或广度优先搜索(BFS)。
| 数据结构 | 特点 | 常见场景 |
|---|---|---|
| 栈(Stack) | 后进先出 LIFO | 函数调用栈、表达式求值、括号匹配、深度优先搜索(DFS) |
| 队列(Queue) | 先进先出 FIFO | 任务调度、消息队列、数据流处理、广度优先搜索(BFS) |
Java 的 Optional 类是什么?它有什么用?
Optional 是 Java 8 引入的一个容器类,用来表示一个可能为空的值。
它的主要作用是防止空指针异常,通过像 isPresent()、orElse()、ifPresent() 这样的 API,
让我们不用到处写 if (obj != null),代码更清晰、更安全。
你可以理解成它是一个“带状态的盒子”,
盒子里可能有值,也可能是空的,但我们不用再直接碰 null。
Java 的 I/O 流是什么?
Java 的 I/O 流其实就是用来读写数据的“通道”,
程序可以通过它从文件、网络等地方读取数据,或者把数据输出到文件、控制台。
它分为两大类:
- 字节流(InputStream / OutputStream),处理二进制数据;
- 字符流(Reader / Writer),处理文本数据。
举个例子:读图片就用字节流,读写文本就用字符流。
这样设计是为了让程序更灵活、更高效地操作不同类型的数据。
Java 中的基本数据类型有哪些?
Java 一共有 8 种基本数据类型,用来存放最基础的数据,
它们不属于对象类型,也不存放在堆里,而是在栈中。
整数类型有 4 个:byte、short、int、long;
浮点类型 2 个:float、double;
字符类型是 char;
布尔类型是 boolean。
这些类型的设计是为了性能更高,不需要对象包装。
什么是 Java 中的自动装箱和拆箱?
自动装箱和拆箱是 Java 编译器帮我们做的类型转换。
比如,当我们把 int 放进 List
当我们从 List 取出来再参与运算时,它又会自动变回 int —— 这就是拆箱。
它是在 Java 5 引入的,主要是为了让代码更简洁。
底层其实就是调用 valueOf() 和 xxxValue() 方法。
不过要注意两点:
一是频繁装拆箱会影响性能,二是拆箱时如果是 null 会直接抛 NullPointerException。
什么是 Java 中的迭代器(Iterator)?
Iterator 是什么?
Iterator 是 Java 集合框架中的一个接口,用于顺序遍历集合中的元素。
它提供了一种统一访问集合元素的方式,开发者不需要关心集合的底层实现。
常与 Collection 接口及其子类(如 List、Set)配合使用。
核心方法
- boolean hasNext():判断集合中是否还有下一个元素;
- E next():返回下一个元素,若没有则抛出 NoSuchElementException;
- void remove():删除最近一次通过 next() 返回的元素,仅在调用 next() 之后使用,否则抛出 IllegalStateException。
主要作用
- 提供统一、简洁、安全的遍历方式,避免直接使用索引;
- 支持在遍历过程中删除元素;
- for-each 语法实际上是基于 Iterator 实现的语法糖。
Java 运行时异常和编译时异常之间的区别是什么?
Java 的异常分两类:编译时异常和运行时异常。
举例:
- 编译时异常->FileNotFoundException、IOException
- 运行时异常->算数异常 (ArithmeticException)、空指针异常 (NullPointerException)、数组越界 (ArrayIndexOutOfBoundsException)
二者的区别:
- 编译时异常在编译阶段就会被检查,比如文件读写错误,必须用 try-catch 或 throws 处理,否则编译不过;
- 而运行时异常是程序运行时才抛出的,比如空指针或数组越界,编译器不会强制你处理。
设计上是因为编译时异常多来自外部环境,而运行时异常多是代码逻辑错误。
什么是 Java 中的继承机制?
Java 的继承是面向对象的三大特性之一,
它允许子类通过 extends 关键字继承父类的属性和方法,从而实现代码复用和功能扩展。
Java 只支持单继承,但支持接口的多继承。
优点是结构清晰、便于维护,缺点是耦合性高、灵活性差。
什么是 Java 的封装特性?
封装就是把对象的属性和方法包装在类里面,对外只提供访问接口,比如通过 getter/setter 控制访问权限。
这样做可以隐藏内部实现细节,保护数据安全,也让代码更容易维护和扩展。
Java 中的访问修饰符有哪些?
Java 有四种访问修饰符:public、protected、default、private。
它们控制类和成员的访问范围。
private 最严格,只能在当前类访问;default 是包级访问;
protected 可以被同包或不同包的子类访问;public 最开放,任何地方都能访问。
代码示例:
1 | public class Person { |
Java 中静态方法和实例方法的区别是什么?
- 静态方法用 static 定义,属于类本身,不需要创建对象就能调用,只能访问静态成员,常用于工具类或工厂方法。
- 实例方法属于对象,必须通过对象调用,可以访问类中所有成员,常用于操作对象属性或实现对象行为。
总结一句话:
静态方法属于类,实例方法属于对象;
静态方法不依赖对象,只能访问静态成员;
实例方法依赖对象,可以访问一切成员。
Java 中 for 循环与 foreach 循环的区别是什么?
for 循环比较灵活,可以通过索引访问、修改、删除元素,适合需要控制循环逻辑的场景;
foreach 是语法糖,用起来更简洁,但不能访问索引,也不能在遍历时修改集合内容,否则会报错。
总结一句话:
for 灵活、能控制;foreach 简洁、安全但不能改。
什么是 Java 中的双亲委派模型?
什么是双亲委派机制?
Java 的双亲委派机制是类加载的一种设计模式。
当类加载器收到加载请求时,它不会自己立刻加载,而是把请求交给父加载器,一层层向上委派,直到 Bootstrap 尝试加载。
如果上层加载器都加载不了,才由当前加载器执行加载。
这样做可以防止同一个类被重复加载,同时保证核心类的安全性,比如 java.lang.Object 永远由启动类加载器加载。
- 一句话记忆:先找爸爸,爸爸找不到我再上!
工作流程:
1️ 当前类加载器接收到一个类加载请求;
2️ 它不会立刻加载,而是将请求交给父类加载器;
3️ 父类加载器再交给更上层的父类加载器;
4️ 一直到最顶层的 Bootstrap ClassLoader(启动类加载器);
5️ 如果父加载器都无法完成加载,才由当前加载器执行加载。
即:自下而上委派,自上而下加载
三种主要类加载器
| 类加载器 | 实现方式 | 加载内容 | 加载路径 |
|---|---|---|---|
| Bootstrap ClassLoader | C++ 实现(JVM 内部) | JRE 核心类库 | <JAVA_HOME>/lib |
| Extension ClassLoader | Java 实现 | 扩展类库 | <JAVA_HOME>/lib/ext |
| Application ClassLoader | Java 实现 | 用户类(classpath) | classpath 路径 |
启动类加载器(Bootstrap ClassLoader)
↑
扩展类加载器(ExtClassLoader)
↑
应用类加载器(AppClassLoader)
一般加载顺序是:应用类加载器 → 扩展类加载器 → 启动类加载器
子类 → 父类 → Bootstrap → 父类返回 → 子类加载
设计目的
“为什么要设计双亲委派机制?”
1️ 防止类被重复加载
→ 同一个类只会被一个加载器加载,避免内存中出现多个副本。
2️ 保证核心类安全
→ 比如 java.lang.Object 永远由 Bootstrap 加载,
即使用户自定义同名类也不会被替代。
3️ 实现类隔离
→ 不同类加载器加载的类互相独立,互不干扰,方便模块化和沙箱机制。
破坏双亲委派的场景
实际开发中,有些框架“故意”打破双亲委派。
| 场景 | 说明 |
|---|---|
| SPI 机制(Service Provider Interface) | 典型如 JDBC 的 DriverManager,需要由子加载器加载厂商实现类。 |
| Web 容器热加载机制(热部署) | 如 Tomcat / Spring Boot,为实现模块热替换,需要自定义类加载器。 |
| 插件化框架 | 比如 OSGi、Dubbo 插件系统,为实现模块隔离也会自定义加载逻辑。 |
面试简答
双亲委派机制是 Java 类加载器的一种设计模式。
当类加载器加载类时,不会自己先去加载,而是把请求交给父类加载器,
父类加载器再向上委派,直到最顶层的 Bootstrap ClassLoader。
如果父类无法加载,才由当前加载器执行加载。
这样可以避免类重复加载、保证核心类安全、实现类加载隔离。
常见的类加载器包括 Bootstrap、Extension 和 Application 三种。
在 SPI 或 Tomcat 热加载中,出于扩展性考虑会打破这一机制。
Java 中 wait() 和 sleep() 的区别?
在 Java 中,wait() 和 sleep() 都能让线程暂停,但它们的作用和机制不同。
- wait() 属于 Object 类,必须在同步块中使用,会释放锁,通常配合 notify() 或 notifyAll() 实现线程通信。
- sleep() 属于 Thread 类,不需要同步块,不会释放锁,只是让线程休眠指定时间后自动恢复。
简单来说:wait 用于线程通信,sleep 用于线程延时;wait 放锁,sleep 不放锁。
Java Object 类中有什么方法,有什么作用?
Java 的 Object 类是所有类的父类,它定义了一组通用方法,
主要包括对象比较(equals、hashCode)、对象拷贝(clone)、
对象字符串表示(toString)、反射(getClass)、
多线程协调(wait、notify、notifyAll)以及垃圾回收钩子(finalize)。
这些方法几乎构成了所有 Java 对象的基本行为。
Java 中的字节码是什么?
- Java 字节码(Bytecode)是 Java 编译器将 .java 源文件编译后生成的中间表示形式,它位于 Java 源代码与 JVM 执行的机器码之间。
- 存储在 .class 文件中。
- 它是平台无关的指令集,由JVM 解释器或 JIT 编译器将其翻译为机器码运行。
- 字节码是 Java 实现 “一次编译,到处运行” 的核心机制。
什么是 BIO、NIO、AIO?
在 Java 中:
- BIO(Blocking I/O):是传统的同步阻塞模型,一个请求一个线程,调用方在 I/O 操作完成前会一直被阻塞。适合连接数少、逻辑简单的场景。
- NIO(Non-blocking I/O):是同步非阻塞模型,I/O 操作立即返回,通过轮询(Selector)检查状态,一个线程可处理多个连接,提高并发性能。
- AIO(Asynchronous I/O):是异步非阻塞模型,I/O 请求发出后由操作系统完成,完成后通过回调或事件通知应用层。适用于高并发高响应场景。
🔹 用比喻:
BIO 是“自己一直盯着水烧开”;
NIO 是“自己时不时来看看水开没”;
AIO 是“请别人帮忙看,水开了他会通知你”。
什么是 Channel?
在 Java NIO 中,Channel 是一个数据通道(Data Channel), 用于在程序与 I/O 设备(文件、网络套接字等)之间进行数据的读写。 与传统的 I/O 流不同,Channel 是双向的、可读可写,并且支持非阻塞模式。
它通常与 Buffer 和 Selector 配合使用:
- Buffer 用于临时存储数据;
- Selector 用于实现多路复用,从而用一个线程同时处理多个连接。
常见的实现类包括:
- FileChannel(文件 I/O)
- SocketChannel(TCP 客户端)
- ServerSocketChannel(TCP 服务端)
- DatagramChannel(UDP 通信)
一句话总结:
Channel 就是 NIO 的“管道”,负责在程序与外部资源之间传输数据,是高效非阻塞 I/O 的核心。
什么是 Selector?
Selector 是 Java NIO(New I/O) 中用于实现 I/O 多路复用(Multiplexing) 的核心组件。
它允许一个线程同时监听多个 Channel(通道)上的事件(如可读、可写、连接就绪等),
从而实现一个线程管理多个网络连接,大幅减少线程开销,提高系统并发性能。
工作原理:
Channel 向 Selector 注册感兴趣的事件(如 OP_READ、OP_WRITE 等),
Selector 通过 select() 方法检测哪些 Channel 就绪,然后再由程序去处理这些就绪事件。
类比理解
可以把 Selector 理解成一个“监控中心”:
它不停地查看哪些连接(Channel)有事要处理(比如有数据可读、有新连接等),
然后把这些“有事的连接”交给程序去处理。
所以 Selector 的核心优势就是——一个线程就能看管成百上千个连接,
不再像传统 BIO 一样一个连接就要一个线程。
Float 经过一系列的操作后(加减乘除),如何判断是否和另一个数相等呢?
在 Java 中,浮点数(float、double)不能直接用 == 比较是否相等,
因为二进制浮点数无法精确表示所有十进制小数,会产生精度误差。
常见解决方案有三种:
1.容差比较法:
Math.abs(a - b) < epsilon,通过设置精度范围判断是否相等。
2.使用 BigDecimal:
用于高精度计算场景(如金融),比较时用 compareTo() 而不是 equals()。
3.整数化处理:
若业务允许(如金额以“分”为单位),可转为整数后再比较。
一句话总结:
不能直接用 == 比较浮点数,推荐使用“误差范围法”或 BigDecimal.compareTo()。
PO、VO、BO、DTO、DAO、POJO 有什么区别?
PO、VO、BO、DTO、DAO、POJO 到底怎么区分?
让我一句话概括它们:
PO 放数据库、VO 给前端看、DTO 用来传数据、BO 干业务逻辑、DAO 操作数据库、POJO 是最普通的 Java 类。
——简单记:存储→PO、展示→VO、传输→DTO、业务→BO、访问数据库→DAO
① PO(持久化对象)——和数据库最贴近的对象
PO 就是和数据库表一一对应的类。字段基本等于表字段。
- 主要目的是“读库/写库”
- 字段一般不会删减(不展示也得存)
- 不会加展示用字段(如 createTimeStr)
什么时候用?
Service / Mapper 在与数据库交互时,取出来的就是 PO;最终转成其它对象再返回。
② VO(视图对象)——返回给前端/页面用的
你可以把 VO 理解为:
“为了让前端更好用而设计的对象”
- 字段是展示友好的(如格式化时间、状态文案)
- 可以组合多个来源的数据
- 不带数据库字段,不暴露敏感信息
项目里的 VO 例子
ResponseVO:统一响应结构PaginationResultVO:分页数据包装- 有时会自定义业务 VO,例如组合多个来源的展示字段
也就是说:
Controller 返回值永远是 VO 或分页 VO,不直接给前端 PO。
③ DTO(数据传输对象)——用来传输数据的“契约”
DTO 的核心点是:
”我不是给前端看的,也不是用来存数据库的,我就是用来传数据的。”
- 可能作为 Controller 的入参(CreateDTO/UpdateDTO)
- 也可能作为 Service 之间的传输载体
- 字段按业务含义组织,不按展示/数据库组织
项目中 的 DTO 例子
TokenUserInfoDto:用户登录态,会发到 RedisUserCountInfoDto:统计粉丝数/点赞数VideoInfoEsDto:搜索时传给 ESVideoPlayInfoDto:跨层使用的数据结构
也就是说:
DTO 是中立的数据模型,既不是前端展示,也不绑定表结构。
④ BO(业务对象)——处理业务逻辑用的
BO 属于业务域内的模型:
- 用来封装业务逻辑(如“订单结算结果”“视频发布结果”)
- 可以包含多个 PO/DTO/外部数据的组合
- 业务层专用,不对外暴露
很多项目不显式写 BO,但概念上它就是“业务处理阶段的对象”。
⑤ DAO(数据访问对象)——操作数据库
DAO 就是:
- 提供
save/get/update/delete的接口 - Service 层不会直接操作数据库,而是调 DAO
在 MyBatis/Spring 项目里你看到的:
1 | UserMapper.java |
其实就是 DAO,只不过现在大家叫 Mapper。
⑥ POJO(普通 Java 对象)——最基础的类
POJO 不是一个“职责角色”,只是指:
- 最普通的 Java 类
- 没继承、没实现特殊接口
PO/VO/DTO/BO 这些其实都是 POJO 的“变种”。
把它们串起来
在我们后端分层里,几个对象的职责非常明确:
PO 是和数据库表对应的,用来持久化存储;
DTO 是输入输出的契约,是服务之间或前后端之间的数据载体;
VO 是返回给前端展示的对象,会做格式化/文案等处理;
BO 是业务处理阶段的对象,可以组合多个来源的数据;
DAO/Mapper 则负责具体的数据库 CRUD。
而它们本质上都是 POJO,只是职责不同。
结合你的 项目 来讲
你可以这样讲(非常推荐):
在我的 项目里,这些对象分得更明确:
- VO:比如
ResponseVO、PaginationResultVO,都是返回给前端的展示类;有些接口会拼组多个来源的数据再封装成自定义 VO。- DTO:比如
TokenUserInfoDto、VideoInfoEsDto,用于服务之间、缓存、搜索层的传输,不会直接暴露给前端。- Query 对象:像
VideoInfoPostQuery、UserInfoQuery,用于分页/条件查询,是输入专用。- PO:例如
UserInfo这种实体类,只负责映射数据库,不直接返回给前端。因为分层清晰,所以 Controller 只处理 DTO/Query,Service 处理 PO 和业务逻辑,最终用 VO 返回前端,整个系统观察性和扩展性都很好。
面试官最爱的问题:
为什么要搞这么多对象?不能用一个对象走天下吗?
不能,因为不同阶段关心点不一样:
- PO:字段多、和数据库强绑定,不适合暴露
- VO:展示字段往往需要组合/格式化
- DTO:输入输出的契约要稳定、可校验
- BO:业务逻辑可能需要多个数据源的组合
如果混在一起,就会出现“数据丢了没人发现、数据库字段改动导致前端挂掉”等问题,项目越大越混乱。
分成多个对象其实是“职责隔离”,保证系统稳定可维护。
Java 集合面试题
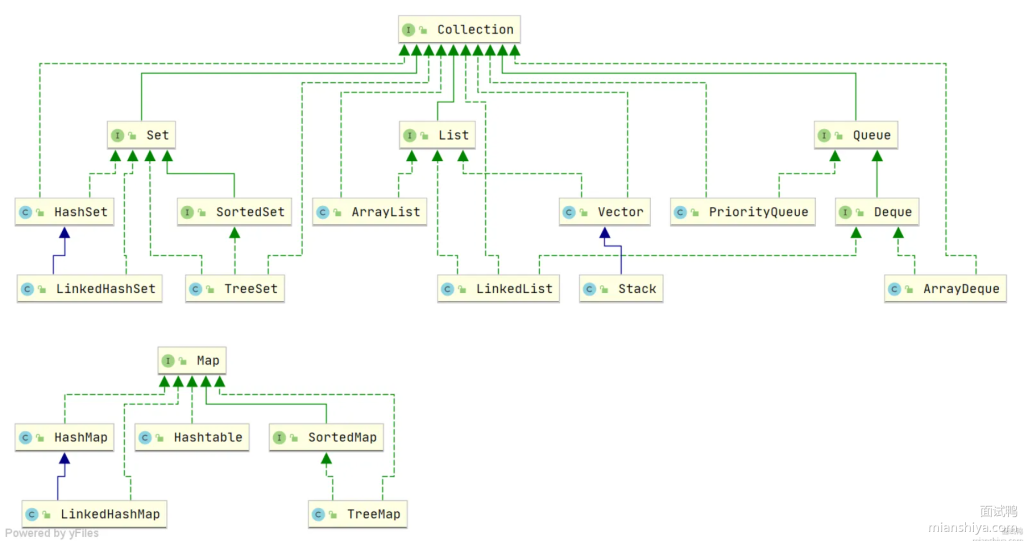
Java 中有哪些集合类?请简单介绍
Java 集合主要分为两大体系:
-
Collection单列集合(存单值)包括:
-
List(有序可重复,如 ArrayList、LinkedList)
-
Set(无序不重复,如 HashSet、TreeSet)
-
Queue(队列,如 PriorityQueue)
-
-
Map双列集合(键值对存储)包括:
- HashMap、LinkedHashMap、TreeMap、Hashtable。
各集合底层一般是数组、链表、哈希表或红黑树,根据应用场景选择即可。
数组和链表在 Java 中的区别是什么?
数组和链表的主要区别在于存储方式、访问效率、插入删除性能和空间利用率。
- 数组在内存中是连续存储的,支持 O(1) 时间的随机访问,但插入删除需要移动元素,效率较低。
- 链表在内存中是非连续存储的,每个节点包含数据和指针,插入删除效率高 O(1),但访问需要遍历 O(n)。
- 数组空间利用率高,但扩容麻烦;链表空间开销大,但结构灵活。
适用场景:
- 数组适合数据量固定、频繁访问的场景;
- 链表适合数据量不固定、频繁插入删除的场景。
一句话总结:
“数组快在访问,慢在插删;链表快在插删,慢在访问。”
Java 中的 List 接口有哪些实现类?
Java 中常见的 List 实现类有:ArrayList、LinkedList、Vector、Stack 和 CopyOnWriteArrayList。
- ArrayList:基于动态数组实现,随机访问快,插入删除慢,线程不安全。
- LinkedList:基于双向链表实现,插入删除快,随机访问慢,也不是线程安全的。
- Vector:早期线程安全版本的 ArrayList,方法同步,性能较低。
- Stack:继承自 Vector,实现了先进后出(LIFO)的栈结构。
- CopyOnWriteArrayList:线程安全,读操作无锁,写操作会复制一份新数组,适合读多写少的并发场景。
一句话总结:
“ArrayList 访问快,LinkedList 增删快,Vector 是同步老版本,CopyOnWriteArrayList 适合并发读多写少。”
Java 中 ArrayList 和 LinkedList 有什么区别?
ArrayList 和 LinkedList 都实现了 List 接口,区别主要在底层结构和性能上:
- ArrayList 基于动态数组实现,内存连续,随机访问快(O(1)),但插入删除慢(O(n)),适合读多写少场景;
- LinkedList 基于双向链表实现,内存不连续,插入删除快(O(1)),访问慢(O(n)),适合频繁插删的场景;
- 二者都线程不安全,如需线程安全可用 CopyOnWriteArrayList。
一句话总结:
“ArrayList 快在访问,慢在增删;LinkedList 快在增删,慢在访问。”
Java ArrayList 的扩容机制是什么?
在 Java 中,ArrayList 是基于动态数组实现的。
当元素数量超过当前数组的容量时,就会触发扩容机制。
默认情况下,ArrayList 的初始容量是 10。当发生扩容时,会创建一个新的数组,容量大约是旧容量的** 1.5 倍**,也就是通过 oldCapacity + (oldCapacity >> 1) 这个计算式来得到的。
然后,会把原来数组中的元素通过 Arrays.copyOf() 方法复制到新数组里。
扩容的过程是比较耗时的,因为涉及到内存分配和数据复制,
所以如果能提前指定容量,性能会更好。
此外,ArrayList 没有负载因子(loadFactor),这是和 HashMap 不同的地方。
另外在 JDK 1.7 和 1.8 版本之间有个小区别:
- 在 JDK 1.7 中,调用无参构造方法时会直接创建一个长度为 10 的数组;
- 而在 JDK 1.8 中,采用了懒加载机制,只有在第一次调用 add() 方法时才真正分配空间。
一句话总结:
“ArrayList 的扩容机制就是——当容量不够时,自动按 1.5 倍增长,并复制旧数据到新数组中。”
面试回答:
ArrayList 底层是动态数组实现的,当元素数量超过当前容量时就会触发扩容。默认初始容量是 10,扩容时新容量是旧容量的 1.5 倍,实际上是通过 oldCapacity + (oldCapacity >> 1) 计算出来的。然后用 Arrays.copyOf() 把旧数组的内容复制到新数组里。
扩容过程会涉及内存分配和数据复制,性能相对较低,
所以在预知元素数量时最好在构造时指定初始容量。
ArrayList 没有负载因子,和 HashMap 不一样。
在 JDK 1.7 中是构造时分配数组,1.8 以后是懒加载,只有第一次 add() 才真正分配空间。
总结:
“ArrayList 的扩容机制 = 触发时自动按 1.5 倍新建数组 + 拷贝旧数据。”
说说 Java 中 HashMap 的原理?
HashMap 的底层是 数组 + 链表 + 红黑树 的结构。
1.当我们向 HashMap 中存入一个键值对时,会先根据 key 的 hashCode 计算哈希值,再定位到数组下标。
2.如果该位置为空,就直接插入;如果已有元素,就会比较 key:
- 相同则覆盖 value;
- 不同则判断是链表还是红黑树结构。
- 若为链表 → 遍历插入尾部
- 若为TreeNode → 插入红黑树;
3.插入后判断
- 链表长度 > 8 且 table 大小 ≥ 64 → 转红黑树;(在 JDK 1.8 以后,为了避免链表过长导致性能下降,当链表长度超过 8 且数组容量 ≥ 64 时,会自动转换为 红黑树 提升查询效率。)
- 若红黑树节点数小于6->转回链表
- 若 size 超过 threshold(阈值) → 扩容。(HashMap 默认初始容量是 16,负载因子是 0.75,当元素数量超过 capacity × loadFactor 时会触发扩容(容量 ×2)。
不过要注意的是:HashMap 不是线程安全的,多线程环境下建议使用 ConcurrentHashMap。
Java 中 HashMap 的扩容机制是怎样的?
HashMap的扩容机制
HashMap 在存储元素超过一定数量时会触发扩容,具体机制如下:
1.触发扩容
当 HashMap 中的元素数量超过 负载因子(默认是 0.75)与当前容量的乘积时,扩容操作就会触发。
2.扩容规则
扩容时,HashMap 的容量会 翻倍。例如,从 16 扩容到 32。
扩容后,新的数组大小为原来的一倍,因此元素将重新分配到新的数组中。
3.扩容时jdk7会重新计算每个元素的哈希值,jdk8时不会重新计算哈希值,jdk8是通过hash值与上老数组的容量 (hash & oldCapacity )来判断hash值的最高位是不是1,如果是1,则扩容后元素存放的位置为旧数组下标+老数组的容量,如果是0,说明元素还是存放在原来的下标位置。
为什么 HashMap 在 Java 中扩容时采用 2 的 n 次方倍?
HashMap 采用 2 的 n 次方作为容量,是为了让哈希值分布更均匀、减少冲突,并通过位运算代替取模运算来提升索引效率。
同时在扩容时,只需判断哈希值新增一位的 0/1,即可快速确定新位置,避免重新计算哈希,提高扩容性能。
为什么 Java 中 HashMap 的默认负载因子是 0.75?
HashMap 的默认负载因子是 0.75,这个值是为了在时间复杂度和空间利用率之间取得一个合理的平衡。
- 如果负载因子太小,比如 0.5,虽然哈希冲突少,查询快,
- 但会导致频繁扩容,浪费空间;
- 如果负载因子太大,比如 0.9,虽然空间利用率高,
- 但冲突多,查找效率会下降。
所以 0.75 是经过大量实践验证的经验值,既能保证较低的冲突概率,又能减少扩容次数。
总结:
“0.75 是 HashMap 在空间利用率与查找效率之间的最优平衡点。”
为什么 JDK 1.8 对 HashMap 进行了红黑树的改动?
在 JDK1.8 之前,HashMap 使用链表来解决哈希冲突。
当冲突比较严重时,链表会变得很长,查找、插入、删除的时间复杂度从 O(1) 退化为 O(n)。
为了避免性能急剧下降,从 JDK1.8 开始,当桶中元素数量超过 8 时,
并且数组长度大于 64,HashMap 会将链表转换为红黑树。
红黑树是一种自平衡二叉查找树,操作复杂度是 O(log n),可以显著提升性能。
当元素数量减少到 6 以下时,红黑树又会退化回链表,以节省内存。
另外,之所以不直接使用红黑树,是因为树节点体积更大,占用更多内存。
因此,只有在冲突严重时才树化,是在性能与内存之间的平衡设计。
一句话总结:
“JDK1.8 引入红黑树是为了解决哈希冲突导致的性能退化问题,
将最坏时间复杂度从 O(n) 优化为 O(log n),实现时间与空间的最佳折中。”
JDK 1.8 对 HashMap 除了红黑树还进行了哪些改动?
除了引入红黑树以外,JDK1.8 对 HashMap 还做了三项关键优化:
第一,优化了哈希函数。
通过 (h = key.hashCode() ^ (h >>> 16)) 通过高 16 位与低 16 位异或,使高位信息参与索引计算,让哈希值分布更均匀,减少冲突。
第二,改进了扩容机制。
JDK1.7 每次扩容都要重新计算 hash 值,而 JDK1.8 直接通过 (hash & oldCap) 旧容量(oldCap)的高位判断节点的新位置,无需重新计算 hash。
第三,插入方式从头插法改为尾插法。
头插法在多线程扩容时可能造成链表反转和死循环,改为尾插法后可以有效避免这一问题。
一句话总结:
“JDK1.8 的 HashMap 通过优化哈希函数、改进扩容机制、改为尾插法,在性能、稳定性和安全性上都比 JDK1.7 有显著提升。”
使用 HashMap 时,有哪些提升性能的技巧?
在使用 HashMap 时,主要可以从以下几个方面提升性能:
① 预估初始容量,避免频繁扩容
HashMap 扩容会触发 rehash,代价高;可以通过 new HashMap(expectedSize / 0.75f) 预设容量。
② 合理调整负载因子(LoadFactor)
默认 0.75 是空间与时间的平衡点,数据密集或读多写少的场景可略调低。
③确保 hashCode 分布均匀
设计良好的 hashCode 可避免冲突,减少链表/红黑树退化,提高访问效率。
④ 根据场景选用合适 Map 实现类
- LinkedHashMap:保持插入顺序;
- ConcurrentHashMap:高并发场景;
- TreeMap:需要排序的场景。
一句话总结:
提前规划容量、优化哈希函数、合理配置负载因子,才是 HashMap 高性能的关键。
什么是 Hash 碰撞?怎么解决哈希碰撞?
Hash 碰撞是指不同的 key 通过哈希函数计算后得到相同的哈希值,从而映射到哈希表中的同一个槽位。
常见的解决方式包括:
① 拉链法(链地址法):
每个槽位对应一个链表或红黑树,所有哈希值相同的元素存在该链表中。
(Java 的 HashMap 就是采用这种方式)
② 开放寻址法:
当发生碰撞时,继续在数组中寻找下一个空闲槽位(如线性探测、二次探测)。
③ 再哈希法(双重哈希):
使用多个哈希函数,在发生碰撞时重新计算新的索引位置。
🔹总结一句话:
“Hash 碰撞是不可避免的,关键在于通过合理的冲突解决策略(如拉链法+红黑树)保持高效性能。”
Java 的 CopyOnWriteArrayList 和 Collections.synchronizedList 有什么区别?分别有什么优缺点?
CopyOnWriteArrayList 和 Collections.synchronizedList 都是线程安全的 List 实现,但机制完全不同。
- CopyOnWriteArrayList 采用“写时复制”策略,写操作会复制一个新数组再修改,读操作无锁,适合读多写少的并发场景。优点是读性能极高、迭代安全;缺点是写操作慢且内存占用高。
- Collections.synchronizedList 通过 synchronized 关键字为所有操作加锁,实现线程安全。优点是实现简单,写操作无额外内存开销;缺点是读写都加锁,性能较差,且迭代需手动同步。
一句话总结:
读多写少用 CopyOnWriteArrayList,读写频繁用 Collections.synchronizedList(或直接用 ConcurrentHashMap、CopyOnWriteArraySet 等 JUC 类更优)。
Java 中的 HashMap 和 Hashtable 有什么区别?
在 Java 中,HashMap 和 Hashtable 的区别主要有四点:
第一,线程安全性不同:
HashMap 是非线程安全的,多线程环境下可能出现数据不一致;
而 Hashtable 是线程安全的,因为内部所有方法都加了 synchronized。
第二,性能不同:
由于没有同步锁,HashMap 在单线程环境下性能更好。
而 Hashtable 因为锁粒度太粗,性能偏低。
第三,对 null 的支持不同:
HashMap 允许一个 null 键和多个 null 值;
Hashtable 不允许任何 null 键或 null 值。
第四,迭代器机制不同:
HashMap 使用 fail-fast 的 Iterator,迭代时修改会抛出ConcurrentModificationException(并发修改异常);
Hashtable 使用旧的 Enumeration,不会抛异常,但已经过时。
另外,HashMap 继承自 AbstractMap,Hashtable 继承自过时的 Dictionary 类。
一句话总结:
“HashMap 非线程安全、性能高;Hashtable 线程安全但过时,建议用 ConcurrentHashMap 替代。”
ConcurrentHashMap 和 Hashtable 的区别是什么?
在 Java 中,ConcurrentHashMap 和 Hashtable 都是线程安全的哈希表实现,但它们在实现线程安全的方式上完全不同。
Hashtable 使用的是整表锁,即每次读写都要竞争同一把锁,所以并发性能比较低。
而 ConcurrentHashMap 在 JDK7 采用分段锁机制,
在 JDK8 之后采用了 CAS + synchronized 的方式:
CAS 用于无锁写入,如果冲突严重再退化为锁定特定桶的头结点。
这样锁的粒度更细,可以让多个线程同时访问不同桶,从而大幅提高并发性能。
此外,ConcurrentHashMap 的底层结构也更优化,
它在高冲突时会将链表转换为红黑树,进一步提升查询效率。
一句话总结:
“Hashtable 锁整张表,而 ConcurrentHashMap 只锁冲突桶 + 使用 CAS,无锁读写,并发性能更高。”
Java 中的 HashSet 和 HashMap 有什么区别?
-
HashSet 不允许重复元素,只存储一个元素
HashSet 是一个不允许重复元素的集合。在 HashSet 中,存储的每个元素都是唯一的。当你尝试插入一个已经存在的元素时,插入操作会失败。 -
HashMap 存储键值对,键必须唯一,值可以重复
HashMap 是一个由键值对组成的集合。它的键(key)必须是唯一的,但值(value)可以重复。如果你尝试将一个已经存在的键对应的值更新为一个新的值,它会替换掉旧的值。 -
HashSet 底层基于 HashMap 实现,HashSet 存储的元素是存储在 HashMap 的键中,value 就是一个 Object 对象
HashSet 的底层是通过 HashMap 来实现的。在 HashSet 中,元素被存储为 HashMap 的键,而每个键的值(value)在 HashMap 中其实并不关心,它是一个常量对象,通常使用 Object 类型。
Java 中的 LinkedHashMap 是什么?
LinkedHashMap 是 HashMap 的子类,它在 HashMap 的基础上通过维护一个 双向链表,来记录键值对的 插入顺序或访问顺序。
默认情况下按插入顺序排序,如果在构造时将 accessOrder 设为 true,
则按最近访问顺序(LRU)排序。
它的查找、插入、删除操作依然是 O(1) 时间复杂度,并且允许键和值为 null。
常用于实现LRU 缓存 或需要保持插入顺序的场景。
Java 中的 TreeMap 是什么?
TreeMap 是 Java 中实现 Map 接口的一种数据结构,它是基于红黑树的。红黑树是一种平衡的二叉查找树,它能确保在执行插入、删除和查找操作时,时间复杂度都能保持在 O(log n)。在 TreeMap 中,所有的键都会根据自然顺序或者我们提供的 Comparator 进行排序。
另外,TreeMap 不允许 null 作为键,因为 null 不能进行比较排序,但它允许存储 null 值。TreeMap 的一个特点是,它在实现上是一个有序的集合,能保证键值对始终按照升序排列。
Java 中的 IdentityHashMap 是什么?
IdentityHashMap 主要用在那些需要根据对象的内存地址来判断是否相等的场景,而不是判断两个对象的内容是否相同。简单来说,IdentityHashMap 会使用 == 来判断两个键是否相同,而不是像 HashMap 使用 equals() 方法来判断。它通常在一些特殊的情况下使用,比如缓存管理或者需要进行对象唯一性的场景。
此外,IdentityHashMap 和 HashMap 的存储方式也有所不同,它存储键的方式更注重引用而不是对象内容,因此它适用于某些特定的使用场景。
Java 中的 WeakHashMap 是什么 ?
- WeakHashMap 是一种使用弱引用(Weak Reference)作为键(key)的哈希表实现。与普通的 HashMap 不同,WeakHashMap 会允许垃圾回收器去回收不再被其他对象引用的键。也就是说,当 WeakHashMap 中的键对象不再被其他任何地方引用时,该键值对会自动从 WeakHashMap 中移除。
- 通过这种机制,WeakHashMap 能够避免因对象持续存在于内存中而导致的内存泄漏问题。
- WeakHashMap适用于需要对缓存对象进行动态管理的场景,它通过弱引用机制,确保对象可以在没有强引用时自动被垃圾回收。
Java 中 ConcurrentHashMap 1.7 和 1.8 之间有哪些区别?
1.数据结构
JDK 1.7 :ConcurrentHashMap 采用了Segment(分段锁)+ HashEntry(哈希表)来组成数据结构。
JDK 1.8 : ConcurrentHashMap 去掉了 Segment,使用数组+链表和红黑树的结构(与HashMap类似)。
2.锁的类型与粒度
JDK 1.7: 分段锁(Segment)继承了 ReentrantLock,每个 Segment 是独立的,因此可以支持更多的并发线程,默认情况下有 16 个 Segment。
JDK 1.8: 使用 synchronized 和 CAS 来保证线程安全,相比于 1.7 更细粒度的锁。
3. 扩容机制:
JDK 1.7: 每个segment里单独进行自己的扩容。
JDK 1.8: JDK 1.8 的扩容机制引入了渐进式扩容,当我们的元素个数达到扩容阈值时,首先创建一个 2 倍大小的数组,然后后续每次有线程对当前数据结构进行操作(新增、修改等),都会帮忙迁移部分的数组槽位上的数据(使用tranferIndex进行标记),直到旧数组的数据完全迁移到新数组为止。扩容过程更加高效,减少了锁的竞争。
Java 中 ConcurrentHashMap 的 get 方法是否需要加锁?
在 Java 中的 ConcurrentHashMap 中,get() 方法不需要加锁。这个设计是为了提升性能,并减少锁的开销。
-
get方法是读取数据操作,不对资源做处理,所以只要使用 volatile 关键字来确保每次读取操作都能获取到最新的数据即可。
-
具体来说,get() 方法是在数组节点上执行的,它通过 Unsafe 类的 getObjectVolatile() 方法来保证线程可见性,确保每次读取到的值是最新的。
为什么 Java 的 ConcurrentHashMap 不支持 key 或 value 为 null?
Java 中的 ConcurrentHashMap 不支持 key 或 value 为 null 主要是为了避免并发操作时出现不可预知的行为。比如,在多线程环境下执行 get(key) 时,如果 key 对应的值是 null,就无法判断这是因为 key 不存在,还是它的 value 就是 null。如果允许 null,那么就需要额外的代码来区分这些情况,增加了复杂度。
此外,ConcurrentHashMap 的设计是为了避免歧义和并发问题。如果允许 null 作为 key 或 value,就会使得例如 get、put、containsKey 等操作更加复杂,可能导致频繁的状态检查或异常情况。
hahsmap为什么可以?
hashmap设计的初衷是单线程,它有containsKey方法可以判断key是否存在。
ConcurrentHashMap不能用containsKey, 因为多线程环境下也会有歧义。
Java 中的 CopyOnWriteArrayList 是什么?
CopyOnWriteArrayList 是 Java 提供的线程安全的动态数组实现。这个类通过“写时复制”(Copy on Write)机制来保证线程安全,在进行写操作时,会先复制一份数组副本,写操作仅在新的副本上进行,而不对原始数组进行修改。
基本特性:
- 线程安全:使用 CopyOnWrite 机制,读操作不会加锁,写操作在写副本时加锁,保证线程安全。
- 写操作开销大:每次写操作都需要复制整个数组,有一定的性能消耗,而且消耗内存。
- 读操作无锁:由于数组是每次写时才被复制,所以对于大量的读操作是无锁的,性能较高。
适合场景:
适合读多写少的情况。常用于事件通知、事件监停器等场景,能有效减少同步开销,确保线程安全。
你遇到过 ConcurrentModificationException 错误吗?它是如何产生的?
ConcurrentModificationException 它通常出现在多线程环境中,当我们在遍历集合(如 ArrayList)时,如果在遍历的过程中修改了集合的结构(比如添加或删除元素),就会抛出这个异常。这个异常的产生是因为 Java 使用了 fail-fast 机制,它会在检测到结构性修改时立即抛出异常,防止继续执行后续操作,避免不一致的状态。
举例:
比如,如果你在使用 for-each 遍历 ArrayList 时,同时修改了集合的内容,就会触发这个异常。Java 集合类会在 next() 方法调用时检查是否有结构性修改,如果检测到有修改,它会抛出 ConcurrentModificationException。
如何避免:
“为了避免这个异常,通常我们可以使用 Iterator 来遍历集合,因为 Iterator 提供了 remove() 方法来安全地删除元素。此外,在多线程环境下,可以使用像 CopyOnWriteArrayList 这样的线程安全集合,或者使用 synchronized 来同步操作。”