操作系统相关面试题
GQ 操作系统
操作系统在进行线程切换时需要进行哪些动作?
- 保存当前线程的上下文,比如CPU寄存器、栈指针等到线程控制块中
- 更新当前线程的状态
- 选择下一个要执行的线程
- 恢复下一个要执行的线程的上下文,恢复CPU寄存器、栈指针、程序计数器等信息
什么是用户态和内核态?
用户态和内核态是什么?
在操作系统里,其实所有程序不是随便跑的,它们分为两种“运行等级”:用户态(User Mode)和内核态(Kernel Mode)。
一句话总结
用户态负责“正常干活”,内核态负责“有权限的活”。
为了保证系统安全、稳定,CPU 给了这两种模式不同的权限。
1. 用户态和内核态分别是什么?
用户态(权限低的模式)
- 就是普通应用程序运行的地方,比如浏览器、微信、业务代码。
- 权限有限,不能直接操作硬件(比如磁盘、网络、内存管理等)。
- 如果应用要访问系统资源,必须通过系统调用让内核帮忙。
你可以把它想象成:
“只能敲前台窗口的顾客,不能自己跑到后台翻文件。”
内核态(权限最高的模式)
- 是操作系统内核运行的区域。
- 有最高权限,可以访问所有硬件和系统资源。
- 驱动、进程管理、内存管理、文件系统等关键逻辑都在这里执行。
对应比喻:
“后台管理员,可以直接接触所有资源。”
2. 为什么要区分用户态和内核态?
主要是为了 安全 和 稳定:
- 如果普通程序能直接操作硬件,一行错误代码就能让系统崩溃。
- 内核可以集中管理资源,让系统更可靠。
- 用户态崩了,只挂一个进程;内核态崩了,整个系统蓝屏/重启。
简单说:
“保护好内核,系统才能稳。”
3. 用户态和内核态如何切换?
只有三种情况能从用户态切到内核态:
① 系统调用(最常见)
比如:
- read/write 文件
- 网络操作
- 创建进程
- 分配内存
流程是这样:
- 用户态应用发起系统调用(比如 read)
- CPU 触发中断/异常机制
- 保存当前执行上下文(PC、寄存器、栈等)
- CPU 切换到内核态
- 内核执行操作
- 执行完毕再切回用户态继续运行
② 中断(如硬件中断)
比如鼠标、键盘、网卡收到数据,也会强制切到内核态处理。
③ 异常(如除零异常)
出现错误也要交给内核处理。
可以简单记:
“用户态做不了的事,内核态帮你干。”
4. 举例让你秒懂
写文件
用户态业务代码 → 发起 write 系统调用 → 内核态执行 IO → 回到用户态。
网络收包
网卡收到数据(中断)→ 内核态处理 TCP → 应用程序 read 取数据。
创建线程
业务代码调用 pthread_create → 内核创建 PCB → 返回用户态继续执行。
5. 补充
为什么需要上下文切换?
因为 CPU 要从“普通权限”切换到“超级权限”,必须保存/恢复当前状态,避免执行乱套。
内核态一定开销更大吗?
对,切换成本高,不是免费操作:
- 保存/恢复寄存器
- 模式切换
- TLB 刷新等
所以框架(如 Netty)常减少系统调用次数,就是为了减这个开销。
总结
用户态和内核态是操作系统的两种运行模式。
普通应用程序跑在用户态,权限有限,不能直接操作硬件;内核态是操作系统内核运行的区域,权限最高,可以访问全部硬件资源。
之所以要分层,是为了保证系统安全和稳定。如果用户程序可以直接操控硬件,一旦写错就可能把整个系统搞崩。
当应用程序需要执行像 IO、进程管理这类特权操作时,会通过系统调用、中断或异常切换到内核态,操作系统处理完再切回用户态继续执行。
所以可以简单理解:用户态负责“普通工作”,内核态负责“特权工作”,两者通过系统调用机制安全地切换。
进程之间的通信方式有哪些?
在操作系统里,不同进程是隔离的,不能直接访问对方的数据,所以需要各种 IPC(Inter-Process Communication)机制 来交换数据、做同步、甚至协作。常用的进程间通信方式主要有下面这几类:
- 管道(Pipe)——最基础、最经典的 IPC
- 管道就是一个内存中的“单向传输带”,一端写、一端读。
- 常用于 父子进程之间的简单通信。
- 如果要跨进程通信,就要用 命名管道(FIFO),它支持不相关进程之间通过一个特殊的文件来通信。
“管道就像水管,只有前后两个进程能用,一个写,一个读;如果想让不相关的两个进程通信,就用带名字的水管,也就是 FIFO。”
- 消息队列(Message Queue)——带结构的异步通信
- 系统维护一个消息列表,进程可以往里面“投递消息”,别的进程可以从中“取消息”。
- 支持不同类型的消息、有优先级。
- 可以实现异步解耦,不需要双方同时在线。
“消息队列就像邮局,你发一封消息扔进去,收的人什么时候取都可以,是一种典型的异步通信机制。”
- 共享内存(Shared Memory)——最快的 IPC
- 多个进程直接共享同一块物理内存。
- 数据不用复制 → 速度最快。
- 但必须搭配锁(信号量、互斥锁、读写锁)来保证同步。
“共享内存就像几个人一起看同一张纸,最快,但必须约定好写的时候不能抢,要配合锁用。”
- 信号量(Semaphore)——资源访问的红绿灯
- 本质是计数器,用来控制多个进程之间的“互斥”和“同步”。
- 常与共享内存一起使用,防止并发冲突。
“信号量就是一组红绿灯,用来保证多个进程访问同一资源时不冲突。”
- 信号(Signal)——用于通知、异常处理
- 多用于异常事件通知,例如 SIGINT、SIGKILL。
- 可以看作“操作系统发给进程的中断消息”。
“信号就像操作系统给进程发的一条短信,告诉你发生异常了,比如要终止、要暂停。”
- 套接字(Socket)——支持跨主机通信
- 不只用于网络,也可用于本地 IPC(如 UNIX Domain Socket)。
- 支持跨机器、跨进程通信,应用范围最广。
“Socket 最强大,可以本地通信也可以跨网络通信,是分布式系统里最常用的方式。”
- 内存映射(MMAP / Memory-Mapped Files)
- 通过把一个文件映射到多个进程的地址空间实现共享。
- 适合进程间共享较大数据。
“内存映射就是把一个文件当成‘共享内存’,读写文件等于读写内存。”
小结
IPC 主要有 6 类:管道、消息队列、共享内存、信号量、信号、Socket。
管道最简单;消息队列支持异步;共享内存最快;信号量管互斥同步;信号做事件通知;Socket 最通用,支持跨主机。
本地大量数据用共享内存,跨进程解耦用消息队列,跨机器就用 Socket。
操作系统中的进程有哪几种状态?
5种
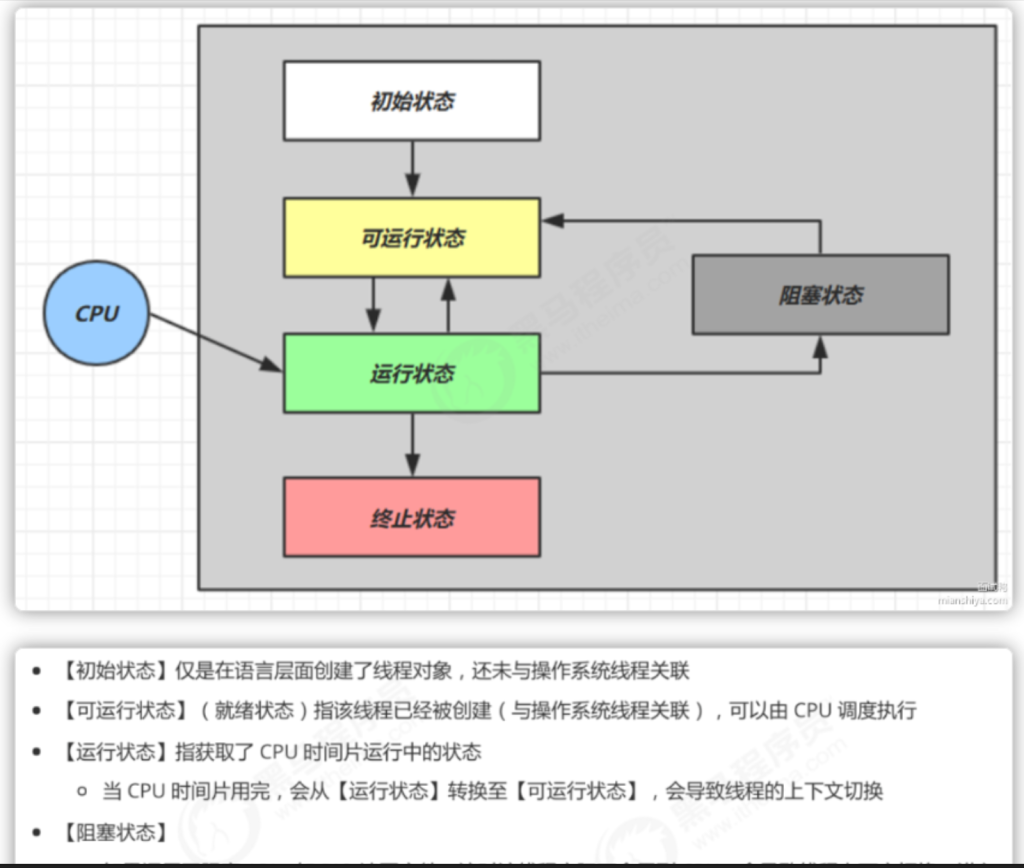
进程的调度算法你知道吗?
1.先来先服务(FCFS)
按进程到达的先后顺序调度,简单易实现,但可能让短任务被长任务“拖死”,叫做“长任务占坑”。
2.短作业优先(SJF)/ 最短剩余时间优先(SRTF)
优先让运行时间最短的任务先执行,可以显著降低平均等待时间;但缺点是必须能预估执行时间,而且不适合交互式系统。
3. 优先级调度(Priority Scheduling)
按优先级调度,高优先级先执行。适合有紧急任务的系统,但可能导致低优先级任务长期得不到运行,引发“饥饿”。
4. 时间片轮转(RR)
每个任务轮流按时间片执行,是典型的交互式系统调度方式。时间片越短响应越快,但上下文切换开销越大。
5. 最高响应比优先(HRRN)
通过“响应比 =(等待时间 + 运行时间)/ 运行时间”来决定调度谁。有效避免短作业优先导致的长任务饥饿问题。
6. 多级反馈队列(MLFQ)——最常用
结合多个队列,根据任务表现动态调整优先级:
短任务快速完成,高优先级队列跑;
长任务逐渐降级,跑到低优先级队列。
它结合了 RR、优先级、SJF 的优点,也是现代系统默认使用的算法
小结
常见调度算法有六个:
- FCFS(先来先服务),简单但容易被长任务拖慢;
- SJF 和 SRTF(短作业优先),平均等待时间最低,但需要预估执行时间;
- Priority(优先级调度),高优先级先执行,但可能导致饥饿;
- RR(时间片轮转),适合交互式系统,响应快但切换开销大;
- HRRN(最高响应比优先),解决了饥饿问题;
- 最后是最常用的 MLFQ 多级反馈队列,结合时间片和优先级,短任务跑得快,长任务逐渐降级,是现代系统常用策略。
线程和进程有什么区别?
进程、线程、协程的区别
进程负责“资源”,线程负责“执行”,协程负责“更轻量的执行方式”。
进程是什么?(资源隔离+独立内存)
- 进程就是一个程序的运行实例,比如你打开一个微信,就是一个进程。
- 每个进程有自己独立的内存空间、文件句柄等资源,是操作系统中资源分配的最小单位。
- 不同进程之间互不影响,因此稳定性高,但创建和切换成本大。
线程是什么?(执行单元+更轻量)
线程是进程内部的“执行流”,一个进程可以有多个线程。
线程之间共享同一个进程的内存,因此通信非常方便,但安全性要靠加锁保证。
线程是CPU 调度的最小单位,切换比进程轻量,但仍需要 OS 参与调度。
协程是什么?(用户态、极轻、高并发)
协程是比线程更轻量的“用户态调度”的执行方式,不会被 OS 感知。
它把切换时机交给程序自己决定,而不是让 OS 抢占式调度,因此切换开销极低。
常用于大量 I/O 任务,比如 Go 的 goroutine、Java 的虚拟线程。
- 进程:资源独立、安全但重 → “房子”
- 线程:共享资源、切换轻 → “房子里的房间”
- 协程:极轻量、用户态调度 → “房间里的小隔断,不需要 OS 管”
执行成本对比
| 对比项 | 进程 | 线程 | 协程 |
|---|---|---|---|
| 创建成本 | 高 | 中 | 很低 |
| 切换成本 | 高(OS 切换) | 中(OS 切换) | 极低(用户态切换) |
| 内存隔离 | 完全隔离 | 共享 | 共享,逻辑更轻 |
| 调度者 | OS | OS | 程序自身 |
小结
- 进程是操作系统分配资源的单位,每个进程有独立的内存,因此安全但切换成本高。
- 线程是进程里的执行单元,共享进程资源,切换比进程快但需要同步锁来保证安全。
- 协程更轻量,它在用户态调度,不需要 OS 参与,所以切换成本非常低,非常适合 I/O 密集的高并发场景,比如 Go 的 goroutine 或 Java 的虚拟线程。
什么是软中断、什么是硬中断?
什么是软中断、什么是硬中断?
简单来说,硬中断是由硬件触发的,软中断是由软件触发的。
像键盘、网卡、定时器这些外设,每当有事件发生时,会主动给 CPU 发一个“硬中断信号”。CPU 收到后会立刻暂停当前执行的程序,去处理对应的中断逻辑,所以硬中断优先级一般比较高。
硬中断就像外卖小哥敲你家门CPU 不管在干什么,都得先暂停下来去处理
而软中断是程序自己触发的,比如系统调用、int 指令,它们本质上是通过软件的方式,让 CPU 去执行一段内核服务逻辑,比如文件读写、进程调度等。软中断通常优先级低于硬中断。
软中断更像是主动打电话给客服 程序或操作系统自己发起一个“请求”
一句话总结:
硬中断来自外设,实时性强、优先级高;软中断来自软件,用来请求内核服务。
为什么要有虚拟内存?
为什么要有虚拟内存?
虚拟内存的出现,主要是为了解决三个问题:内存不够用、进程之间要隔离、安全性不好管理。我们可以把它理解成:给每个程序造一个“假的、大内存空间”,再由系统负责把“假地址”映射到真实物理内存里。
这样做的好处非常明显:
1. 内存变大了(扩容能力)
物理内存只有那么一点,但虚拟内存能把程序看到的地址空间放得很大。
比如:
- 程序觉得自己有 4GB 内存
- 实际上机器可能只有 8GB 内存同时跑十几个程序
- 系统不够用时还能把不常用的内存换到磁盘(swap)
总结一句话:虚拟内存让“内存看起来很大”,不够用就上磁盘,程序丝毫感觉不到。
2. 进程之间互不干扰(强隔离)
每个进程都看到自己独立的虚拟地址空间:
- A 程序不能直接访问 B 程序内存
- 也不能乱改系统内核的内存
- 内核能给不同区域设置访问权限(只读、可执行、不可写等)
这就像每个人住单间房,互相进不了对方房间,安全性大大提高。
3. 让内存管理更简单(系统更好调度)
虚拟内存让操作系统可以随心所欲:
- 想把程序的某个地址映射到哪块物理内存,全由系统决定
- 程序不需要关心物理内存是怎么分布的
- 更易做内存回收、页调度、统一管理
对应用来说是“假地址”,对系统是“真实物理地址”,两边都更自由了。
扩展一下(面试加分用)
1)虚拟地址怎么变成物理地址?
靠硬件 MMU + 页表。
流程大概是:
- CPU 生成虚拟地址
- MMU 查页表 → 得到物理地址
- 找不到就触发 Page Fault
- 系统把磁盘里的页面交换回来继续执行
虚拟内存底层核心:页表 + MMU
2)为什么页表要多级?
因为地址空间巨大,一个巨大页表会占用很多内存。
多级页表能做到:
- 稀疏内存不需要分配页表
- 节省内存开销
3)Copy-on-Write(写时复制)为什么重要?
比如 fork():
父进程和子进程先“共享”内存,直到某一方真正写入才复制。
大大减少内存占用。
4)TLB(快表)是什么?
TLB 是缓存页表的东西,加速地址映射。
没有命中(TLB Miss)时才去查页表。
总结
虚拟内存就是给每个进程提供一个独立、巨大的“假地址空间”,由系统把虚拟地址翻译成物理地址。这样能扩容内存、隔离进程、提高安全性,还让内存管理更灵活。真正落地是靠页表、MMU、Page Fault、TLB 等机制共同完成。
什么是分段、什么是分页?
在操作系统里,分段和分页都是用来管理内存的,但出发点完全不同。
首先说分段(Segmentation):
我自己理解分段就是按照程序的逻辑结构来切内存。
比如一个程序自然会分成 代码段、数据段、栈段 等,每一段都是独立的、大小也不一样,而且段与段之间不要求连续。
所以分段的好处是:
- 更贴近程序的逻辑结构,可读性强、好维护;
- 每段可以按需增长,比如栈往下长、堆往上长,互不干扰;
- 内存访问会带上“段号 + 段内偏移”。
但分段的问题是段的大小不固定,容易造成外部碎片。
再说分页(Paging):
分页就是把虚拟内存和物理内存都切成固定大小的“页”(比如 4KB)。固定大小让内存管理特别简单,不会有外部碎片。
分页的特点是:
- 进程看到的是虚拟地址,虚拟页通过页表映射到物理页;
- 虚拟页不存在时会触发缺页中断,把页面从磁盘换入;
- 页面大小固定,所以方便分配与回收。
分页的核心目的,就是让系统可以高效使用物理内存,并支持更大、更独立的虚拟地址空间。
一句话总结:
- 分段更关注“程序结构”(逻辑切分,大小不固定);
- 分页更关注“内存利用”(固定大小的页,更容易管理)。
很多现代系统是段页式结合使用:先按段划分,再在每段内部用分页。
小结
分段和分页都是操作系统的内存管理方式。
分段是按程序的逻辑结构切内存,比如代码段、数据段、栈段等,每段大小都不一样,更贴近程序的真实结构,好理解、好维护,但容易产生外部碎片。
分页则是把虚拟内存和物理内存都切成固定大小的页,通过页表做映射,不会有外部碎片,内存利用率更高,也方便换页和内存回收。
一句话总结就是:
分段关注“程序结构”,分页关注“内存管理与效率”。
现代系统一般是两者结合使用。
说下你常用的 Linux 命令?
一般分为文件操作、系统管理、网络调试、日志查看这几个维度
文件和目录相关的基本操作
日常开发中最常用的就是这些:
- ls / ll:查看目录内容,ll 会显示详细信息;ls -a 会显示隐藏文件。
- cd / pwd:切换目录、查看当前路径。
- mkdir / rm / cp / mv:创建目录、删除、复制、移动文件。
- find:查找文件很常用,比如查找最近 7 天的日志:
1 | find . -name "*.log" -mtime -7 |
这些命令主要用来定位文件、管理项目目录。
文件内容查看(排查 bug 必备)
- cat:看小文件。
- more / less:看大文件,less 可以翻页。
- head / tail:看文件开头和结尾,尤其 tail -f 实时看日志非常常用:
1 | tail -f app.log | grep ERROR |
- grep:文本搜索神器,排查问题最常用。
系统管理相关(定位线上问题最常用)
- top/htop:查看 CPU、内存占用,一般线上性能问题都从 top 先看。
- ps aux | grep:看指向的 java 进程、服务有没有启动:
1 | ps aux | grep java |
- kill / kill -9:杀进程(线上谨慎使用 -9)。
- df -h:看磁盘空间。
- du -sh:看某个目录大小,比如排查日志占满磁盘:
1 | du -sh /var/log/ |
这些主要用来看资源、查进程、排查线上故障。
用户、权限相关
- chmod:改权限,比如给脚本加执行权限:
1 | chmod 755 start.sh |
- chown:改文件所属用户。
- passwd:改密码。
网络相关(排查联通问题)
- ping:是否能 ping 通机房、目标服务。
- curl / wget:发 HTTP 请求、下载文件,curl 更适合调接口。
- netstat / ss:查看端口是否被占用、服务连通状态。
- ifconfig / ip addr:查看服务器 IP 信息。
- telnet:测试端口是否能访问。
线上连通性问题基本都靠这些来定位。
压缩与解压
- tar -xvf / tar -cvf:解压 / 压缩
- zip / unzip
- gzip / gunzip
Git、Maven 这些我也会用
因为开发环境也在 Linux 上,所以 Git 和 Maven 也算常用命令。
- git pull / git push / git checkout
- mvn clean install -Dmaven.test.skip=true
其他性能分析命令(生产排查很有用)
- vmstat:内存、CPU 细节
- iostat:IO 负载
- dmesg:查看系统级错误(比如 OOM)
常用的 Linux 命令基本覆盖了文件管理、系统监控、网络调试、日志排查几个维度,像 ls/ps/top/grep/tail/curl/df/du 这些几乎每天都在用;线上排查问题时主要依赖 top + ps + grep + tail -f 这一套组合拳,处理高 CPU、磁盘满、进程挂掉等典型问题。
小结
我平时在开发和排查问题时,其实 Linux 命令用得很频繁。
首先是文件和目录操作,ls、ll、cd、mkdir、rm 这些是最基本的;比如我经常用 ls -l 看文件权限和大小,用 find 去查最近生成的日志。
在查看文件内容上,我最常用的是 cat、less、grep、tail -f 这些组合,尤其 tail -f app.log | grep ERROR,基本是我线上排查日志的常用招式。
系统监控和进程管理方面,我会用 top 或 htop 看 CPU、内存;用 ps aux | grep java 查看某个服务的进程状态,必要的时候会用 kill 杀掉异常进程。磁盘占满时我通常用 df -h 和 du -sh * 查哪块目录空间过大。
网络相关我会用 ping、curl、telnet、ss -lntp 来排查端口和网络连通性。例如接口不通,我一般会先 curl 一下看响应,再用 ss 确认端口有没有被正常监听。
权限管理方面,chmod 755 给脚本加执行权限,chown 修改文件所属用户,这些在部署服务时非常常用。
整体来说,我用 Linux 命令主要是围绕 文件管理、日志排查、系统监控、网络调试这几个核心场景,特别是排查线上问题时,top + ps + grep + tail -f 是我最常用的一套组合拳。
I/O是什么?
I/O(Input/Output,输入/输出)是计算机系统中用于数据传输的机制,指的是在计算机和外部设备(如键盘、显示器、磁盘等)之间,或在计算机内部组件(如内存和CPU)之间的数据传输过程
为什么网络 I/O 会被阻塞?
网络 I/O 会被阻塞的主要原因有几个。
- 首先是 等待数据发送或接收完成,例如,当程序试图从网络套接字中读取数据时,如果数据还没有到达,它就会阻塞,直到数据传输完成;
- 其次是 系统资源限制,当系统的资源(如网络带宽、连接数等)达到最大限制时,进程会被迫等待资源可用,导致阻塞;
- 第三是 默认的阻塞行为,大多数网络 API(如
recv、send、accept)默认是阻塞模式,即在没有数据可以处理时,它们会一直等待。- 另外,还有 异步 I/O 模型可以用来解决这些问题。通过这种方式,可以在 I/O 操作时不阻塞程序,继续执行其他任务,直到数据准备好。这种方式通常使用事件驱动模型(如 Node.js、libevent)来实现高效的非阻塞 I/O 操作。
I/O模型有哪些?
I/O模型通常有以下几种:
-
阻塞I/O(Blocking I/O):在执行I/O操作时,进程会被阻塞,直到数据准备好或操作完成才能继续执行。就像在银行排队办理业务,只有等到轮到你时才能办。
-
非阻塞I/O(Non-blocking I/O):I/O操作不会阻塞进程,如果数据没有准备好,立刻返回错误或状态,进程可以继续执行其他任务。像去银行办理业务,如果柜台忙,离开后稍候再来。
-
I/O多路复用(I/O Multiplexing):通过
select、poll、epoll等系统调用,可以同时处理多个I/O操作。当数据准备好时,进程才会处理。类似银行大堂经理告知你哪个柜台有空,你再去办理。 -
信号驱动I/O(Signal-driven I/O):内核通过信号通知进程,数据准备好了,进程就可以去处理数据。像银行通知VIP会员可以直接去专属柜台办理业务。
-
异步I/O(Asynchronous I/O):发起I/O请求后,进程继续做其他事,直到数据准备好后,内核通知进程去处理数据。就像让银行工作人员办理好业务后通知你来取结果,你可以做其他事。
这些模型各有优缺点,适用于不同的场景。
同步和异步的区别?
同步操作需要等待任务完成后才能继续执行;异步操作则不需要等待任务完成,可以继续执行其他任务,提高系统的效率
到底什么是 Reactor?
到底什么是 Reactor?
简单说,Reactor 就是一种“事件驱动 + I/O 多路复用”的服务器处理模型。
它的核心目标是:让一个线程就能高效处理大量并发连接。
如果用一句话总结:
Reactor 就是“一个线程等事件、多个处理器处理事件”的模式。
Reactor 解决的本质问题是什么?
传统 BIO 是一连接一线程,几万连接就死定了。
Reactor 让你做到:
- 一个或少量线程统一监听所有 I/O 事件(连接、读、写)
- 一旦有事件发生,就分发给对应的处理器去处理
也就是:监听事件和处理事件彻底解耦了。
Reactor 的 3 大核心角色
Reactor 架构里永远是下面三个角色:
① Reactor(事件反应器)
- 负责监听所有事件(通过 select/epoll)
- 一旦有事件发生,就分发给对应 Handler
(就像一个总调度 / 事件分发器)
② Handler(事件处理器)
- 和某个 I/O 事件绑定,比如“连接事件”“可读事件”“可写事件”
- 事件来了就负责真正的业务逻辑(读、写、处理、回包)
③ Acceptor(连接处理器)
- 专门处理新连接
- 给新连接分配一个 Handler(让后续的读写事件有人负责)
一句话记住:
Reactor 负责“盯着事件”,Handler 负责“干活”。
Reactor 的工作流程
你可以这样讲,非常顺:
- Reactor 用一个 selector 一直等事件发生(连接、可读、可写)
- 事件来了,Reactor 会判断这是哪个连接、什么事件
- 把事件分发给对应的 Handler
- Handler 进行处理,比如读消息→业务逻辑→写回客户端
- 处理完继续返回 Reactor,继续等下一个事件
和 GUI 程序的“按钮点击触发事件”其实是一个思想。
Reactor vs Proactor
| 模式 | 谁负责处理 I/O? | 应用程序什么时候被调用? | 典型场景 |
|---|---|---|---|
| Reactor(同步非阻塞) | 应用程序自己完成读写 | 事件就绪时被通知,然后自己做 I/O | Linux(epoll)常用 |
| Proactor(异步 I/O) | 内核帮你完成读写 | I/O 完成后通知应用程序处理结果 | Windows IOCP |
一句话总结:
Reactor 是“事件来了我去读”
Proactor 是“你帮我读好了再通知我”
单 Reactor / 多 Reactor 怎么选?
单 Reactor 单线程
- 结构简单,但性能有限
- 适合低并发场景
单 Reactor 多线程
- Reactor 负责分发
- 具体读写交给线程池
- 常用,性能还不错
多 Reactor 多线程(Nginx / Netty)
- 主 Reactor 管理连接(Acceptor)
- 多个子 Reactor 管理读写
- 吞吐量最高,面试最喜欢问
最容易理解的类比
你可以这样比喻:
想象有一家银行。
- 大堂经理 = Reactor(等客户、把客户分配给窗口)
- 每个窗口 = Handler(真正办业务)
- 迎宾人员 = Acceptor(处理新客户)
Reactor 本质就是:
让一个线程(大堂经理)处理大量连接,而不是一个客户一个窗口。
总结
Reactor 是一种典型的事件驱动模型,广泛用于高并发的网络服务器。
它的核心思想是:用一个或少量线程统一监听所有 I/O 事件(通过 select/epoll),一旦有事件发生,就把事件分发给对应的 Handler 处理,从而实现高并发、非阻塞的事件处理。它包含三个核心角色:Reactor 负责事件监听与分发、Handler 负责处理读写逻辑、Acceptor 专门处理新连接。
在实现上,Reactor 有单线程、单 Reactor 多线程、多 Reactor 多线程等模式,像 Netty、Nginx、Node.js 都使用了多 Reactor 模型。
总结来说,Reactor 让服务器能用少量线程就支撑高并发连接,适合所有基于非阻塞 I/O 的场景。
Select、Poll、Epoll 之间有什么区别?
Select、Poll 和 Epoll 都是操作系统中用于多路复用 I/O 的方法,它们各有优缺点,主要区别在于它们如何处理文件描述符(fd)。
-
Select:
- 优点:广泛支持,几乎所有平台都支持。
- 缺点:最多只能监听 1024 个文件描述符,文件描述符多了效率会低;每次调用时需要复制整个文件描述符数组,在大量文件描述符时效率下降。
-
Poll:
- 优点:没有文件描述符的最大数量限制,支持更多文件描述符。
- 缺点:每次调用时仍需遍历所有的文件描述符,效率随着文件描述符数量增多而降低。
-
Epoll:
- 优点:Linux 系统中的最优解,支持更多文件描述符,且效率更高。它通过内核和用户空间之间的高效数据交换避免了 select 和 poll 的效率问题。
- 工作原理:Epoll 使用事件通知的方式,当文件描述符就绪时通知应用程序,而不是每次都遍历所有 fd,这使得它在处理大量文件描述符时性能更好。
- 模式:Epoll 支持两种模式,LT(Level Triggered) 和 ET(Edge Triggered),其中 ET 模式效率更高,但需要配合非阻塞 I/O 使用。
总结来说,Select 更基础但限制多,Poll 解决了 Select 的数量问题,Epoll 则是处理大量 I/O 操作时最高效的选择,尤其是在处理大量并发连接时。
OSI 七层模型是什么?


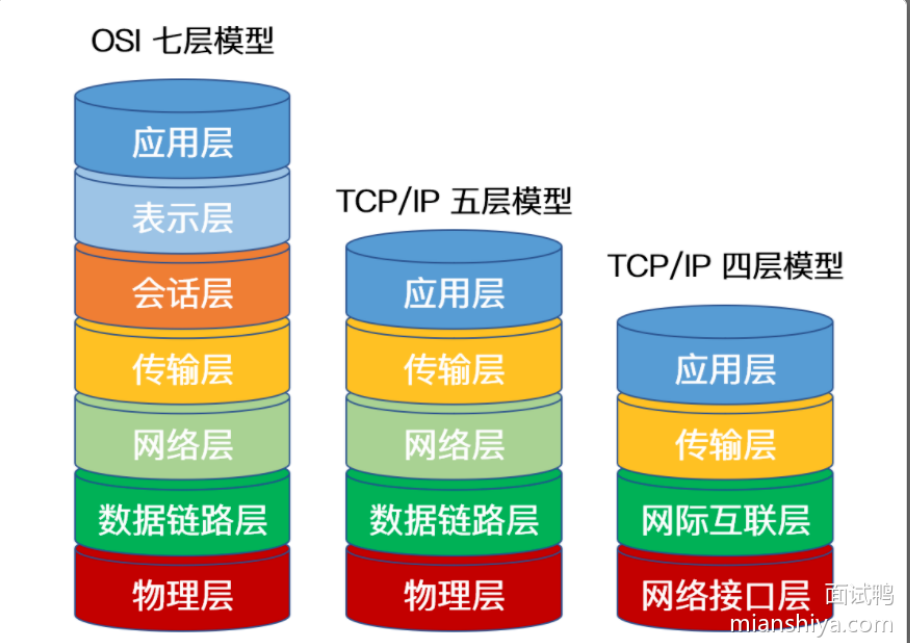
一、OSI 七层模型
OSI 模型是一个标准化的网络通信参考模型,共七层,从下到上分别为:
1. 物理层(Physical)
- 传输电信号、光信号、比特流
- 设备:网线、光纤、网卡
- 协议:RS232、V.35、以太网物理标准
2. 数据链路层(Data Link)
- 负责成帧、差错检测
- 协议:PPP、HDLC、交换机、以太网帧格式
3. 网络层(Network)
- 负责寻址、路由
- 协议:IP、ARP、RIP、OSPF、BGP
4. 传输层(Transport)
- 端到端通信、流量控制
- 协议:TCP、UDP
5. 会话层(Session)
- 建立、管理和终止会话
-协议:NetBIOS
6. 表示层(Presentation)
- 数据格式转换、加密解密
- 协议:JPEG、MPEG
7. 应用层(Application)
- 各种应用服务
- 协议:HTTP、FTP、SMTP、DNS、TELNET、SNMP
二、TCP/IP 五层模型
五层模型实际上是:
物理层 + 数据链路层 + 网络层 + 运输层 + 应用层
对应关系如下:
| TCP/IP 五层 | 作用 | 对应 OSI |
|---|---|---|
| 物理层 | 传输比特流 | OSI 物理层 |
| 数据链路层 | 成帧、MAC 地址传输 | OSI 数据链路层 |
| 网络层 | IP、路由 | OSI 网络层 |
| 传输层 | TCP、UDP | OSI 传输层 |
| 应用层 | HTTP/FTP/SMTP 等 | OSI 会话 + 表示 + 应用 |
记忆口诀
上三合一,下两拆分
三、TCP/IP 四层模型(最常见、最实用)
四层模型是从五层模型简化而来
四层为:
-
网络接口层(Network Interface Layer)
= 物理层 + 数据链路层
- 负责比特传输、成帧
-
网络层(Internet Layer)
- 包括 IP、ICMP、ARP
- 路由选择
-
传输层(Transport Layer)
- TCP、UDP
-
应用层(Application Layer)
- HTTP、FTP、DNS、SMTP
- = OSI 的应用 + 表示 + 会话
一张表搞定三种模型的区别
| 模型 | 层数 | 特点 | 是否实际使用 |
|---|---|---|---|
| OSI 七层 | 7 层 | 理论模型,层次最细 | ❌ 理论为主 |
| TCP/IP 五层 | 5 层 | 教学 & 面试常用 | ✔️ 常见 |
| TCP/IP 四层 | 4 层 | 实际互联网标准 | ✔️ 真正使用 |
什么是物理地址,什么是逻辑地址?
物理地址 vs 逻辑地址
- 物理地址就是内存条上的真实存储位置,是硬件实际访问的地址;
- 逻辑地址(虚拟地址)是程序运行时看到的地址,由 CPU 生成,需要通过操作系统的页表映射成物理地址。
逻辑地址让每个进程都有自己的独立地址空间,更安全,也更容易管理;最终 CPU 访问内存时,一定会转换成物理地址。