7分钟速通RocketMQ的核心面试题
原视频地址:程序员必看:7分钟一次性讲透RocketMQ核心面试题,全程干货无废话,吊打面试官!_哔哩哔哩_bilibili
第一问:什么是消息队列?有什么用?
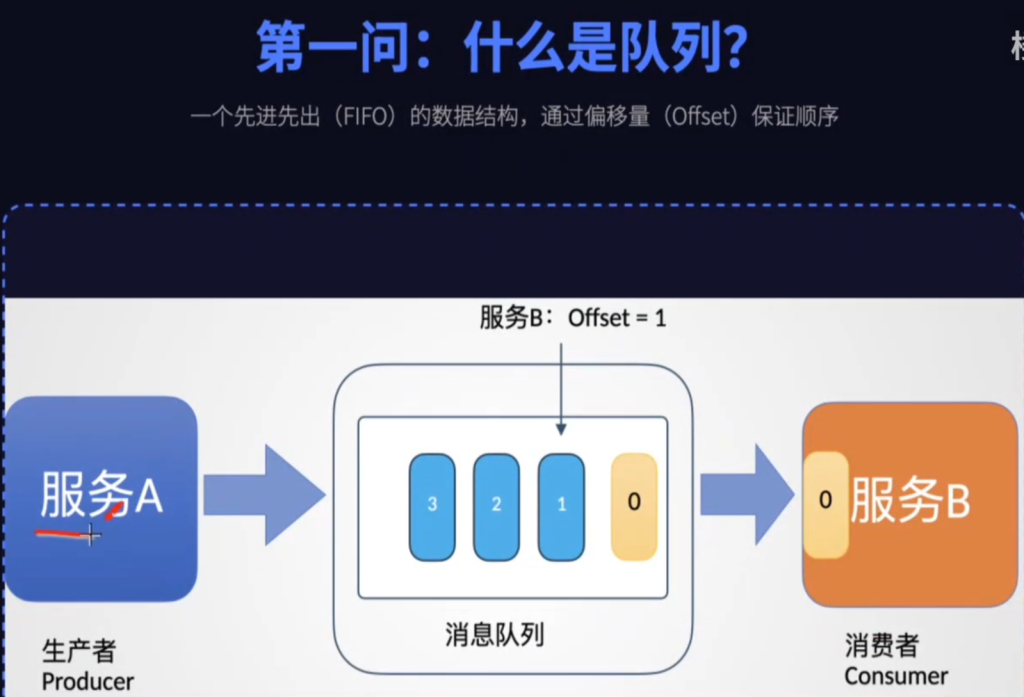
我们先从一个场景开始,服务A需要远程调用服务B的服务,但A服务每秒发送两百个请求,但B服务每秒只能处理一百个请求,那么B服务就会分分钟被压垮,怎么办呢,那就在中间加一层中间件-消息队列,A是生产者,负责发送消息,B是消费者,负责处理消息。生产者发送的消息在消息队列中排队,并且给它分配一个编号,消费者按照自己的速度从消息队列中拉取消息来进行消费,并且记录自己的处理进度,称为offset偏移量,有了中间的消息队列作为缓冲,那B服务就可以按照自己的速度来处理消息,这样一个基础的消息队列就成型了。
第二问:如何扩展性能?
但这是一个简陋的消息队列,当消费者多了,怎么提升性能,机器挂了数据丢了怎么办?
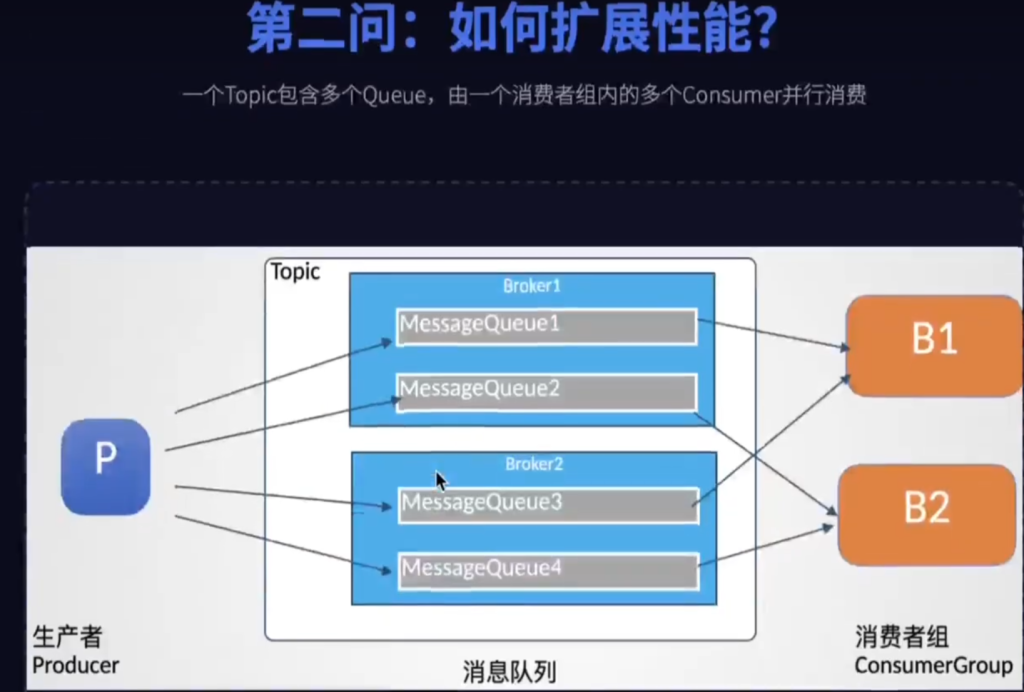
第一步处理性能瓶颈,B处理不过来,消息会产生堆积。我们就找多个业务逻辑相同的B组成一个消费者组ConsumerGroup大家一起干,那问题来了,所有人都在抢一个队列,还是会有性能瓶颈,解决分案就是给消息进行分类,就是Topic,一个Topic再分成多个实际存储消息的message queue,生产者指定Topic发送消息,消息会尽量均匀地写入到不同的message queue队列中,每个队列再去分配给消费者组当中的某一个消费者进行消费,这样呢每个message queue的消费进度互不干涉,自然就能分工协作了,就好比超市结账原本一个收银台,现在开了多个,效率就快很多了
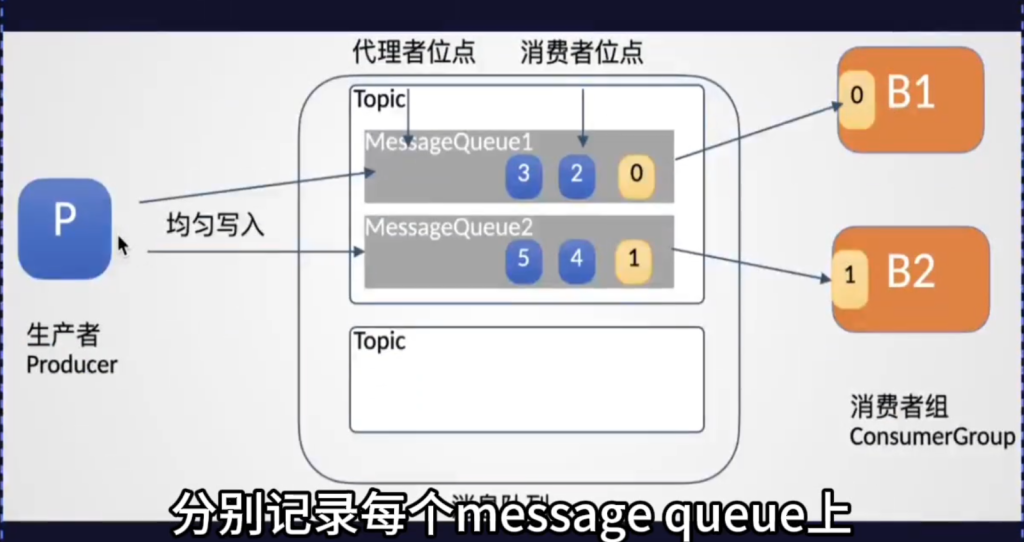
然后在消息队列的服务端分别记录每个message queue上消息写入的进度,称为代理者位点,还有每个消费者组的消费进度,称为消费者位点,这样就能够有效的监控每个message queue上的消息的消费进度了,RocketMQ就是通过这些位点来监控消息的处理进度,如果发现了消息的堆积,也可以通过这些位点数据快速的分析出来
第三问:如果所有的message queue队列都在一台机器上,那消息一多磁盘不就爆了吗
没错!所以我们要搞broker集群实现水平扩展,由于每个message queue都是在单独管理自己的数据和位点,我们可以把一个Topic下的多个message queue尽量均匀的分配到不同的broker上,这样就可以减少每一个服务端的读写压力。
第四问:如何保证高可用?
第二步,来解决高可用问题
如果一个broker挂了,那么上面的数据就全都没了,高可用怎么谈呢?
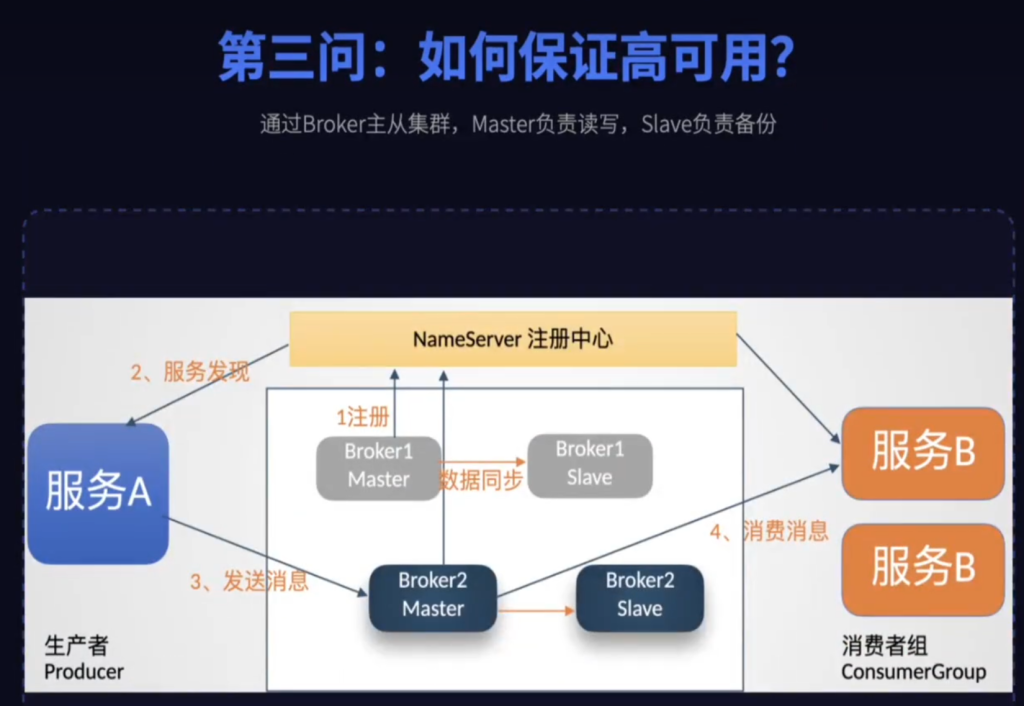
这就涉及到RocketMQ的主从架构了,在RocketMQ中每个主的broker称为master,从的broker称为slave,master节点负责干活,实际处理客户端读写消息的请求,slave只负责一件事,拼命同步master的数据,当master挂了之后,slave立刻顶上变成新的master,这样就保证了服务不中断
第五问:那生产者怎么知道我的消息要发送到哪个broker呢?消费者又从哪里去拉取消息呢?如果broker挂了主从发生了切换它们怎么知道呢?
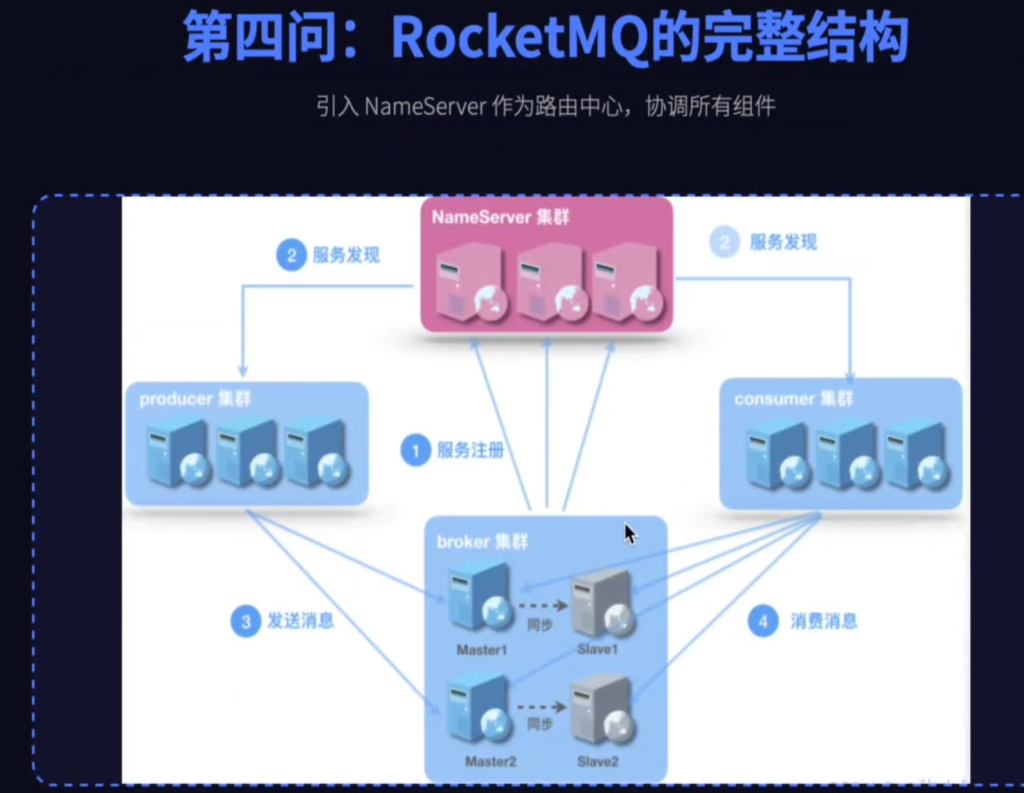
这个问题涉及到了集群的大脑,在RocketMQ中这个大脑就是自主设计的NameServer,NameServer就是RocketMQ的注册中心,它极其轻量但干着非常重要的工作,第一管户口,所有的broker都需要向NameServer报到,并且通过心跳告诉NameServer,它是不是还活着。第二管地图,NameServer手中有张完美的路由信息表,就知道每个topic的队列在哪些机器上。第三当向导,生产者和消费者都要问它要地图,然后才能找到正确的broker通道,接下来进行后续的消息通讯。为了保证向导自己不出事,NameServer自己也是得做集群部署的
第六问:RocketMQ为什么要自主设计一个NameServer,而不用其他现成的注册中心zookeeper,nacos?
这个问题直击RocketMQ的设计核心,因为RocketMQ的核心是金融,电商这类非常灵活的业务场景服务的,这使得RocketMQ的整个设计思想和Kafka这样追求极致的吞吐的消息中间件有根本的区别,在保证高性能的同时,对于服务的可靠性也要做到极致。一方面NameServer采用一种极为轻量级的集群方案,每个NameServer节点之间不需要和集群当中的其他节点发生任何的数据交互,这样可以保证NameServer集群当中只要有任何一个节点正常工作,那么整个NameServer集群就能够保持正常。另一方面,业务的频繁更迭,使得RocketMQ也需要及时进行升级,自主研发的NameServer可以更灵活的应对新的业务场景
其他面试题

例如面试官常问,RocketMQ为什么要设计生产者组呢?而Kafka中却不需要呢
这本质上还是因为RocketMQ的核心是为金融,电商这类严肃的业务场景服务的,而Kafka的核心则是为了分布式日志这一类对吞吐量要求极高的业务场景服务的,在RocketMQ的业务场景下,事务消息是刚需,比如下单这个操作就要保证生产者本地的创建订单和基于RocketMQ发送的扣减库存的消息要么都处理成功要么都失败,不允许有中间状态。RocketMQ中的broker在处理这类事务时就需要反向来检查生产者的状态,这时生产者组的作用就来了,它会告诉broker我们是同一个业务的,你随便向我们组里的任何一个人问,都能知道这个事务最终是成功还是失败,如果某一个生产者实例挂了,broker可以通过回查同一个生产者组内的其他实例,来确定事务的最终状态,这就是RocketMQ为了保证业务万无一失做的独特设计
其他常见的高阶面试题:


