HashMap源码的put详解
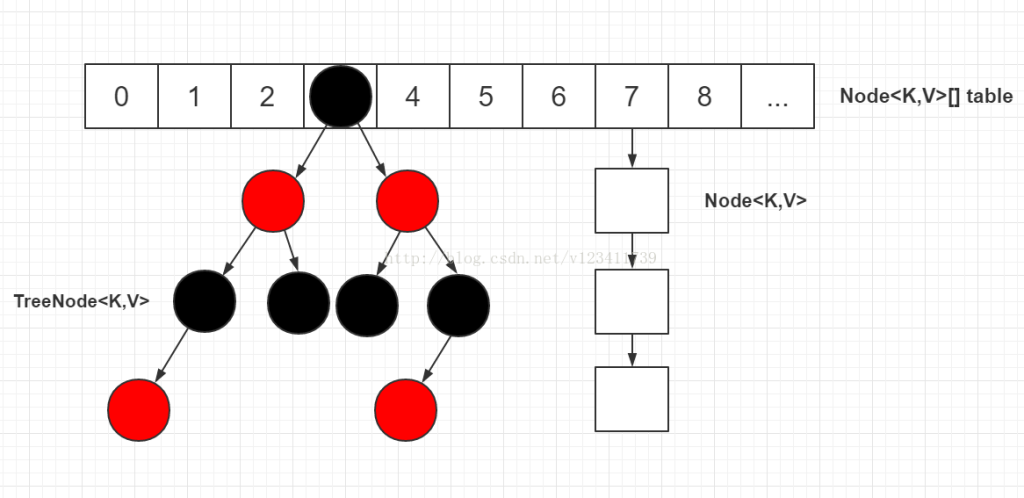
HashMap数据结构
当链表节点较少时仍然是以链表存在,当链表节点较多时(大于8)会转为红黑树
类中属性
1 | public class HashMap<K,V> extends AbstractMap<K,V> |

1 | 1.看源码之前需要了解的一些内容 |
put方法
- 1、首先看table数组,不存在(null或len=0)则初始化(扩容)。存在继续
- 2、看索引处,不存在则新增。存在继续
- 3、判断索引处的值,相等则记录。不等继续
- 4、判断是红黑树的话,走红黑树
- 5、判断是链表的话,走链表
- 6、判断超阈值,则扩容
1. 数组位置为 null
- 当我们往
HashMap中插入一个新的键值对时,首先会计算出键的哈希值,通过hash()方法来进行计算。 - 然后,
putVal()方法会根据计算得到的哈希值计算出该键值对应该插入数组的位置(用tab[i]表示)。如果该位置是null,说明该位置没有任何元素,那么新的键值对就直接插入到该位置。 - 举例:
当调用put("aaa", 111)时,"aaa"的哈希值(假设为0x0011)会计算出来,然后通过tab[0x0011]来判断当前位置。如果该位置是null,就会创建一个新的节点,将key="aaa",value=111插入到这个位置。
2. 数组位置不为 null,键不重复,挂在下面形成链表或红黑树
- 如果数组中某个位置已经有值,即
tab[i]不为null,这时会检查该位置的键是否与当前要插入的键相同。如果键不相同,则会将新的键值对挂在该位置的后面,形成一个链表或红黑树。 - 链表会在该位置后面依次插入新的节点,而红黑树会在链表长度超过阈值时转换为红黑树结构来提高查找效率。
- 举例:
当调用put("bbb", 222)时,假设tab[0x0022]位置已经被0x0011 aaa 111占用,"bbb"的哈希值不同,因此会继续寻找下一个位置,或者在该位置后面形成一个链表,依次挂载bbb的键值对。
3. 数组位置不为 null,键重复,元素覆盖
- 如果数组中该位置的键值对已经存在,而且该位置的键和当前插入的键相同,
HashMap会直接覆盖原来的值,替换成新的值。 - 这时会判断当前数组中该位置的键是否和要插入的键相同。如果相同,则会直接用新的值覆盖原来的值,而不再插入新的节点。
- 举例:
当调用put("ccc", 333)时,假设tab[0x0033]位置已经被0x0033 ccc 333占用,"ccc"的哈希值相同,且键相同,因此直接用新的值333覆盖旧的值。此时tab[0x0033]仍然是ccc,但是值会变为新的333。
总结
在 HashMap 的 put 方法中,插入数据时会经历以下几个步骤:
-
计算哈希值:使用
hash()方法计算键的哈希值。 -
检查数组位置:根据哈希值计算数组的索引
i,检查tab[i]位置。 -
插入操作
:
- 如果该位置为空(
null),直接插入新的节点。 - 如果该位置已有节点,并且键不同,则在链表或红黑树中继续查找插入。
- 如果键相同,则替换旧的值。
- 如果该位置为空(
这种方式保证了 HashMap 的查找效率,同时通过链表和红黑树的机制有效地解决了哈希冲突的问题。
更多详解参考
评论